
基于方法集的企业数据治理综合评价
2015-06-27 05:55赵梦翔
郑州航空工业管理学院学报 2015年5期
汪 杨,赵梦翔,王 刚,2
(1.合肥工业大学 管理学院,安徽 合肥 230009; 2. 过程优化与智能决策教育部重点实验室,安徽 合肥 230009)
基于方法集的企业数据治理综合评价
汪 杨1,赵梦翔1,王 刚1,2
(1.合肥工业大学 管理学院,安徽 合肥 230009; 2. 过程优化与智能决策教育部重点实验室,安徽 合肥 230009)
随着大数据时代的到来,数据及其治理受到企业的高度重视,但是,目前对于数据治理的关键环节之一数据治理评价问题的关注相对较少。为此,考虑到企业数据治理评价问题的自身特点,文章提出了一种基于方法集的企业数据治理综合评价模型。首先,文章构建了企业数据治理评价指标体系并确定其权重。其次,综合应用ELECTRE模型、PROMETHEE模型、TOPSIS模型、灰色评价模型和集对分析评价模型构成方法集对企业数据治理进行评价。然后,应用改进的证据合成方法对方法集中不同模型的评价结果进行合成,得到最终的综合评价结果。最后,以安徽省金融行业的10家企业为例进行实证分析,实验结果验证了基于方法集的企业数据治理综合评价模型的有效性。
数据治理;综合评价;方法集;证据合成
一、引 言
随着互联网技术和通信技术的飞速发展,一个属于大数据的时代正在开启[1]。目前,数据已经成为重要的生产要素之一,正在逐渐向每一个行业和业务职能领域渗透。一方面,大数据为企业洞察市场行为提供了更充分的依据;另一方面也在考验现代企业数据治理能力的多样性和高增速性等[2]。
尽管大多数企业已经认识到企业数据治理的重要性,但是目前各个企业的数据治理水平参差不齐,不尽人意。因此,为了及时掌握企业数据治理现状,数据治理评价应运而生。随着对数据治理评价重要性认识的加深,目前已有学者在研究数据治理面临的问题和探讨数据治理构建思路的基础上,构建出企业数据治理评价指标体系,综合各指标定性给出评价结果[3];也有学者根据企业数据治理基础理论,建立企业数据治理评价指标体系,通过基于熵权和AHP的方法模型对企业数据治理进行评价[4]。但是,目前对于企业数据治理评价的研究还处在比较初步的阶段,研究数量相对较少。并且数据治理评价作为企业数据治理过程中一个关键环节,是开展与完善数据治理工作的基础与前提。因此,企业数据治理评价问题是一个值得进一步深入研究的新问题。
考虑到企业数据治理评价问题的重要性和复杂性,本文提出了基于方法集的企业数据治理综合评价模型。首先,该评价模型以AHP法为基础,进行多轮的专家意见调研,从而得到系统化和科学化的企业数据治理评价指标体系及其权重,避免了在确定指标体系及其权重过程中的主观性问题。其次,该评价模型综合应用ELECTRE、PROMETHEE、TOPSIS、灰色评价和集对分析评价模型构成方法集来对企业数据治理进行综合评价,消除使用单一的评价模型所具有的不稳定和非一致性问题[5]。然后,考虑到证据理论在解决不确定信息问题中的有效性,本文引入证据理论来对不同方法的评价结果进行合成。但由于目前证据理论在评价方面的应用存在对识别框架的理解不全面等问题[6],与此同时由于传统的证据理论还存在证据冲突等问题,在应用中受到限制,因此本文提出了一种应用改进的证据合成方法来整合独立评价模型结果的方法。最后,本文以安徽省金融行业的10家企业为例进行企业数据治理综合评价实证研究,评价结果验证了本文方法的有效性。
二、基于方法集的企业数据治理综合评价模型
(一)基于方法集的企业数据治理综合评价模型总体结构
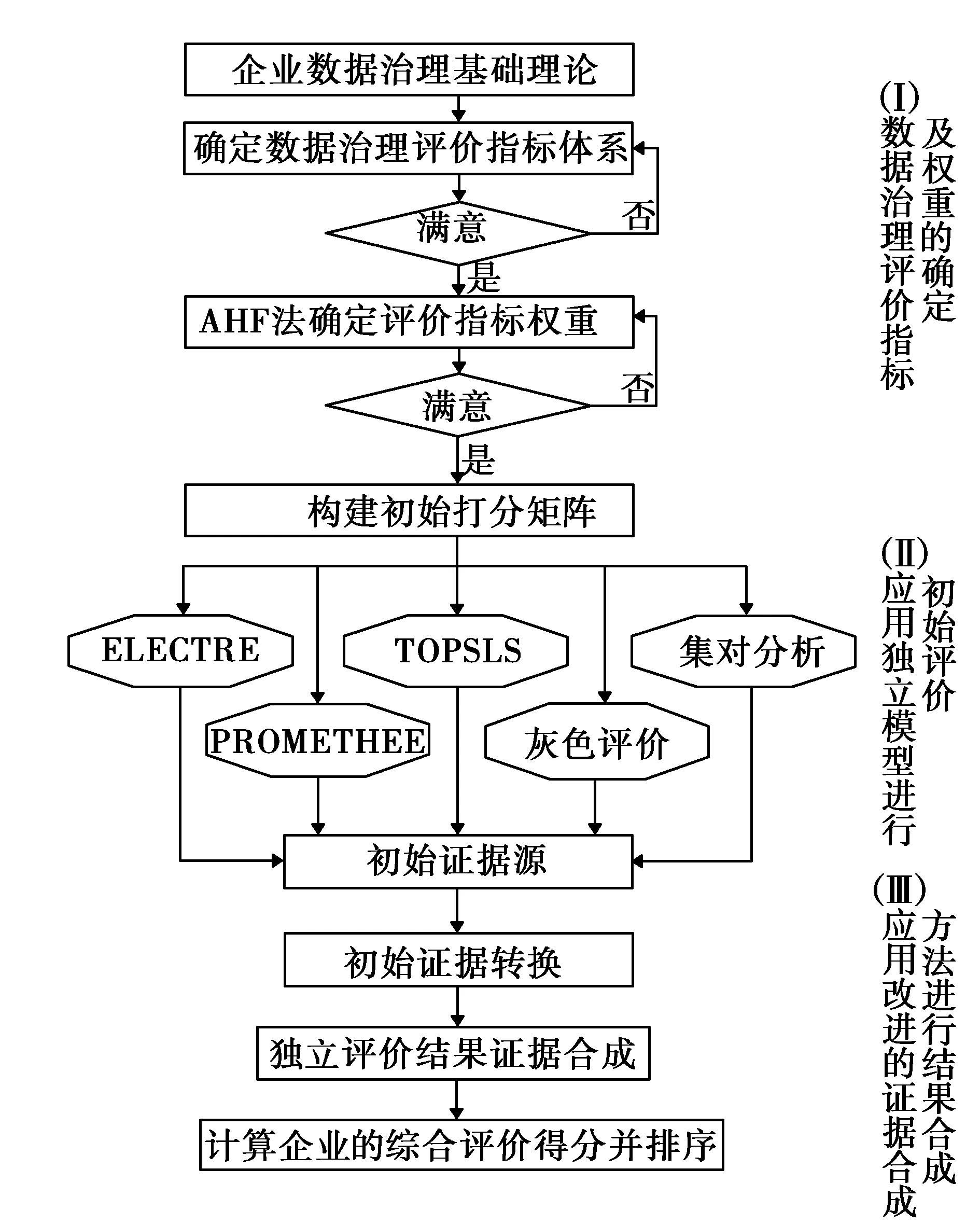
图1 基于方法集的企业数据治理综合评价模型
有效的企业数据治理旨在将数据转变成支持业务决策和风险管理的信息,帮助企业洞察客户需求,从而提高客户忠诚度,增加市场份额,提升其竞争优势。企业数据治理对企业运营有着重大影响,因此,企业需要开展数据治理工作并对其自身的数据治理工作做出正确的评价。考虑到企业数据治理综合评价涉及数据治理的各个环节,评价起来复杂多变,并且使用单一评价模型进行评价容易产生误差,因此,本文提出了基于方法集的企业数据治理综合评价模型[7][8][9]。该评价模型总体上分为三个部分,第一部分以AHP法为基础,进行多轮的专家意见调研,从而确定企业数据治理评价指标体系及其权重;第二部分应用ELECTRE、PROMETHEE、TOPSIS、灰色评价和集对分析评价模型分别进行初始评价,获得初始证据源;第三部分提出了一种改进的证据合成方法,该方法通过对初始证据源进行转换后,利用改进的证据合成方法将不同评价模型的评价结果进行合成,从而得到最终的企业数据治理综合评价结果。综上所述,基于方法集的企业数据治理综合评价模型的整体处理流程如图1所示。
(二)数据治理评价指标及权重的确定
基于方法集的企业数据治理综合评价模型的第一步是确定企业数据治理评价指标及其权重,为后面的综合评价打下基础。本文通过对企业数据治理的理论研究,结合专家意见和建议,构建出包括数据战略规划、数据支撑管理、数据质量管理和数据服务能力等四个方面的企业数据治理评价指标体系[10]。按照系统性、可行性、定量和定性相结合的特点,以及全面性、独立性相结合的原则,本文将企业数据治理评价指标体系进行分级评定。具体指标体系如表1所示。得到企业数据治理评价指标体系后,邀请多位专家对评价指标进行九分度法打分,然后使用AHP法确定指标权重[11]。

表1 企业数据治理评价指标体系
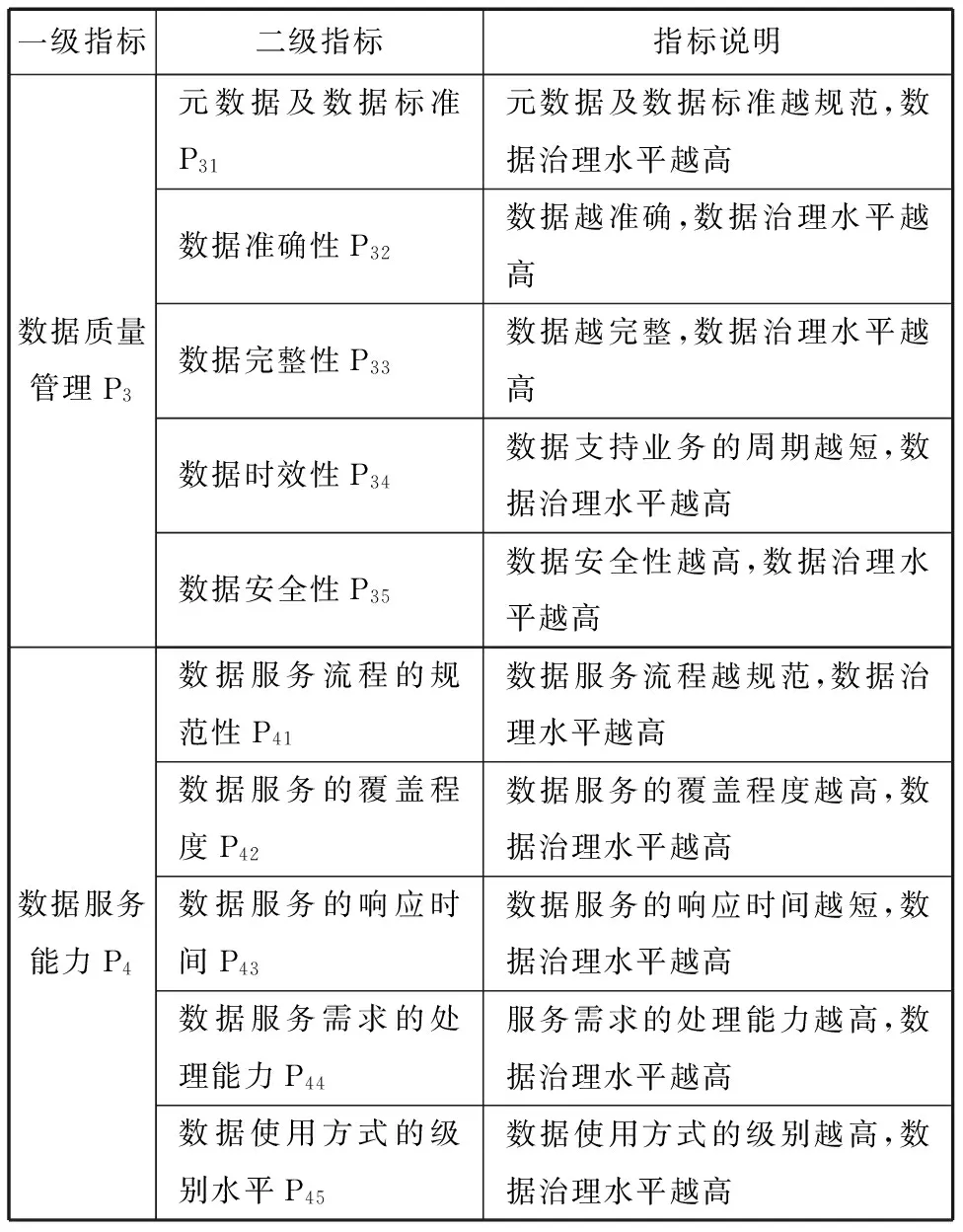
续表1 企业数据治理评价指标体系
(三)应用独立模型进行初始评价
在确定了数据治理评价指标体系和指标权重的基础上,第二步是邀请专家打分构建初始打分矩阵,并分别使用独立的评价模型对企业数据治理进行初始评价,得到初始证据源[12]。
1.构建初始打分矩阵
设z位专家分别对m个企业E1,E2,…,Em进行数据治理评价,每个待评价企业有n个评价指标。考虑到数据治理评价问题的特征,这里我们对于不确定性指标采用区间数的形式给出。其中第1到第p个指标的指标值以区间数的形式给出,第p+1到第n个指标的指标值以具体数值形式给出。其中专家k对待评价企业做出的打分结果如下所示:
(1)

因此,z位专家对待评价企业的打分结果为:
(2)
2.独立模型评价
在获得初始打分矩阵后,接下来以专家为单位,分别采用f种独立评价模型对m个企业进行评价,其中专家k的评价结果为:
(3)

因此,z位专家对待评价企业的评价结果排序为:
(4)
针对企业数据治理评价问题,考虑到各种主观和客观因素,我们选取了ELECTRE、PROMETHEE、TOPSIS、灰色评价以及集对分析评价模型作为方法集的5个基础评价方法。具体简介如下:
(1)ELECTRE评价模型
ELECTRE(Elimination Et Choice Translation Reality)方法首先由Benayoun、Roy与Sussman 3人于20世纪60年代提出,而后由Roy、Nijkamp、Van Delft等人将此方法应用在决策方面。ELECTRE评价模型的基本框架是通过先行比较每个评价准则下各个方案的优劣关系,从而便于剔除部分明显较差的待选方案[13]。本文采用的算法详见参考文献[14]。
(2)PROMETHEE评价模型
PROMETHEE(Preference Ranking Organization Method for Enrichment Evaluations)法是Brans于1984年提出的一种级别高于关系的排序法。它是基于方案的两两比较的一种多属性决策分析方法。该方法是根据每一方案在各准则的满足程度上的差异来刻画每一方案之间的差异。该方法利用优先关系定义每一方案的“正流量”和“负流量”,并提出一组可行方案以供决策者参考,其中,通过PROMETHEE-I法得到的是部分优先关系,通过PROMETHEE-II法得到的是完全优先关系[15]。本文将PROMETHEE评价模型引入本文的方法集中,具体采用参考文献[16]的方法根据净流值的大小直观的表明企业数据治理水平的高低。
(3)TOPSIS评价模型
TOPSIS(Technique for Order Preference by Similarity to Ideal Solution)法是经济决策分析中常用的一种排序方法,它是逼近理想解的排序方法的简称,其原理是借助于多目标决策问题的“理想解”和“负理想解”去排序。该方法的基本思想是在确定了一个实际不存在的最佳方案(理想解)和最差方案(负理想解)之后,计算现实中的每个方案距离最佳方案和最差方案的距离,最后利用理想解的相对接近度作为综合评估的标准,进而得到各方案的排序关系[17]。本文采用的算法详见参考文献[18]。
(4)灰色评价模型
灰色系统理论是我国学者邓聚龙教授首先提出的,包括灰关联度评价方法、灰色聚类分析方法等。灰色评价的基本思想是根据待分析系统的各特征参量序列曲线间的几何相似或变化态势的接近程度,判断其关联程度的大小,其优点在于能够处理信息部分明确、部分不明确的灰色系统。由于企业数据治理是一个复杂系统,涉及因素众多、相互关系错综复杂,并且有的因素不是很明确,使用灰色关联评估模型可以很方便地进行比较。本文采用的算法详见文献[19]。
(5)集对分析评价模型
集对分析是我国学者赵克勤在1989年提出的一种新的系统分析方法。近年来在管理、决策、系统控制等多方面得到应用,其特点是对客观存在的种种不确定性基于客观承认,并把不确定性与确定性作为一个既确定又不确定的同异反系统进行辩证分析和数学处理。企业数据治理评价过程中同样存在多种不确定性,因此我们把集对分析评价引入到我们的方法集中。本文采用的算法详见参考文献[20]。
(四)应用改进的证据合成方法进行结果合成
由于不同评价模型对数据处理和计算方式不同,得到的评价结果具有不稳定和非一致性,因此本文提出了一种改进的证据合成方法对单独评价模型的评价结果进行合成[21][22]。证据理论是由美国学者Dempster于1967年首先提出并由他的学生Shafer改进的一套基于“证据”和“组合”的不确定性推理方法,该方法近年来已在不确定信息决策等领域得到了广泛的应用[23]。本文提出的改进证据合成方法首先对上一小节中得到的初始证据源进行证据转换得到可直接进行合成的证据。然后,应用改进的证据合成方法对证据进行合成。最后,计算企业数据治理水平的综合评价得分并排序。具体合成过程如下:
1.初始证据转换
以企业为单位,根据初始证据源进行统计转换,计算出每个企业在各种独立评价方法下取得每个排名的概率为:
(5)

(6)
其中,Count(r)为排名累计函数,定义如下:
令A为企业在不同专家打分结果下的排名向量,r表示企业具体排名数值,则Count(r)等于企业排名为r的排名累计次数。
因此,m个企业在f种独立评价模型方法下获得每个排名的概率为:
(7)
2.独立评价结果证据合成
考虑到单个方法的不稳定性以及各个结果间存在不一致的情况,本文选用参考文献[12]中提出的合成方法将不同独立方法的评价结果进行证据合成。以企业为单位,分别将f种方法下的排序结果进行合成,得到所有待评价企业取得每个排名的概率如下所示:
(8)
其中dri表示i企业获得第r名的概率,r=1,2,…,m;i=1,2,…,m。
3.计算企业的综合评价得分并排序
首先,为各排名赋对应的分值:
Sr=(s1s2… sm)
(9)
其中r=1,2,…,m。
然后,计算企业的综合评价得分,计算公式如下所示:
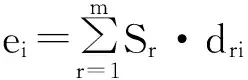
(10)
其中r=1,2,…,m;i=1,2,…,m。
最后,根据企业数据治理的综合评价得分对企业数据治理水平进行排序。
三、实证分析
企业数据治理水平对企业运营有着重要的影响,有效的数据治理是企业获得竞争优势的重要方式。特别是作为数据密集的金融行业,有着海量的数据,并且需要对这些数据进行分析与处理,从而对相关业务进行支撑,因此,完善的数据治理体系是其发展的重要基础[24]。为此,本文选取了安徽省金融行业具有代表性的10家企业为例,利用本文提出的基于方法集的数据治理综合评价模型,对其数据治理水平进行综合评价。
(一)具体评价过程
根据前文对基于方法集的企业数据治理综合评价模型的研究,以下分为三个步骤对10家企业的数据治理水平进行综合评价。
1.第1步,数据治理评价指标权重的确定
结合金融行业的具体情况,邀请数据治理专家通过九分度法对指标重要程度进行打分,并运用AHP法进行指标权重的计算,得到如图2所示的数据治理评价指标体系的权重。

图2 金融行业数据治理评价指标体系的权重
2.第2步,应用独立模型进行初始评价
(1)构建初始打分矩阵
邀请10位数据治理专家根据设定的评价指标体系对10家金融企业的数据治理水平进行打分,获得初始打分矩阵。20个指标中包括10个区间数表示的指标和10个具体数值表示的指标,其中学习与成长、数据治理的组织结构、数据质量管理制度、数据治理的基础设施、数据服务的应急处理能力、数据治理的技术支撑能力、数据治理人员的素质、元数据及数据标准、数据安全性和数据服务流程的规范性为区间数指标,其余指标为实数指标。
(2)独立模型评价
以专家为单位,对得到的10张企业评分表分别应用ELECTRE评价模型、PROMETHEE评价模型、TOPSIS评价模型、灰色评价模型和集对分析评价模型对10家金融企业的数据治理水平进行评价排序,将排名结果以企业为单位进行统计得到初始证据源,如图3所示。
3.第3步,应用改进的证据合成方法进行结果合成
(1)初始证据转换
以企业为单位进行初始证据转换,分别统计计算出每家金融企业在5种方法下获得的评价结果中每个排名的概率,如图4所示。
(2)独立评价结果证据合成
考虑到对同一个企业在同样的打分结果下,各个独立方法的评价结果间仍存在证据不稳定和非一致性问题,因此,本文应用提出的一种改进的证据合成方法对上述评价结果进行合成,得出每个企业不同排名的概率。10家企业的合成结果汇成企业数据治理排名概率表,具体数值如表2所示。

图3 企业独立模型评价排名结果
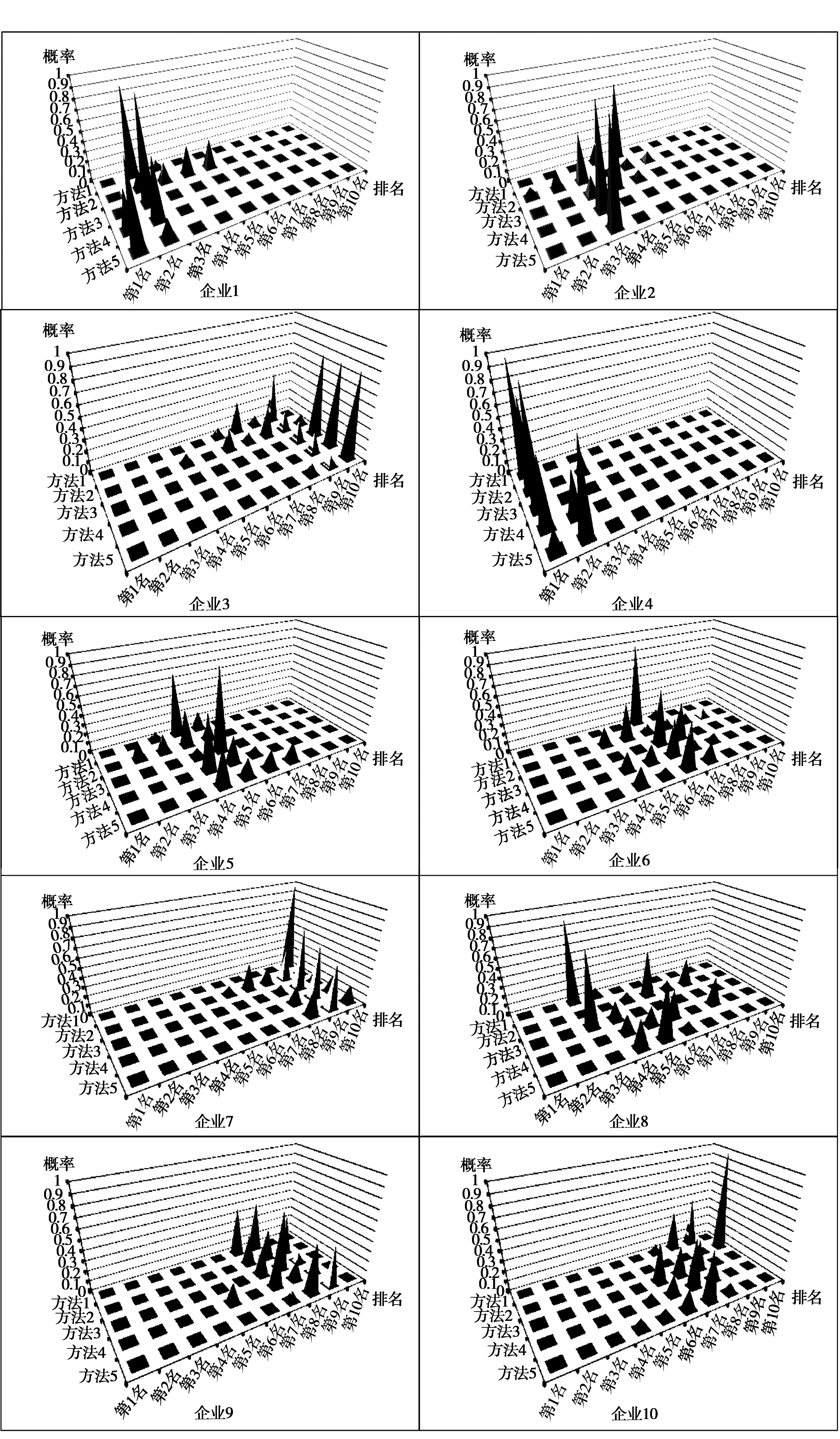
图4 企业评价排名概率统计
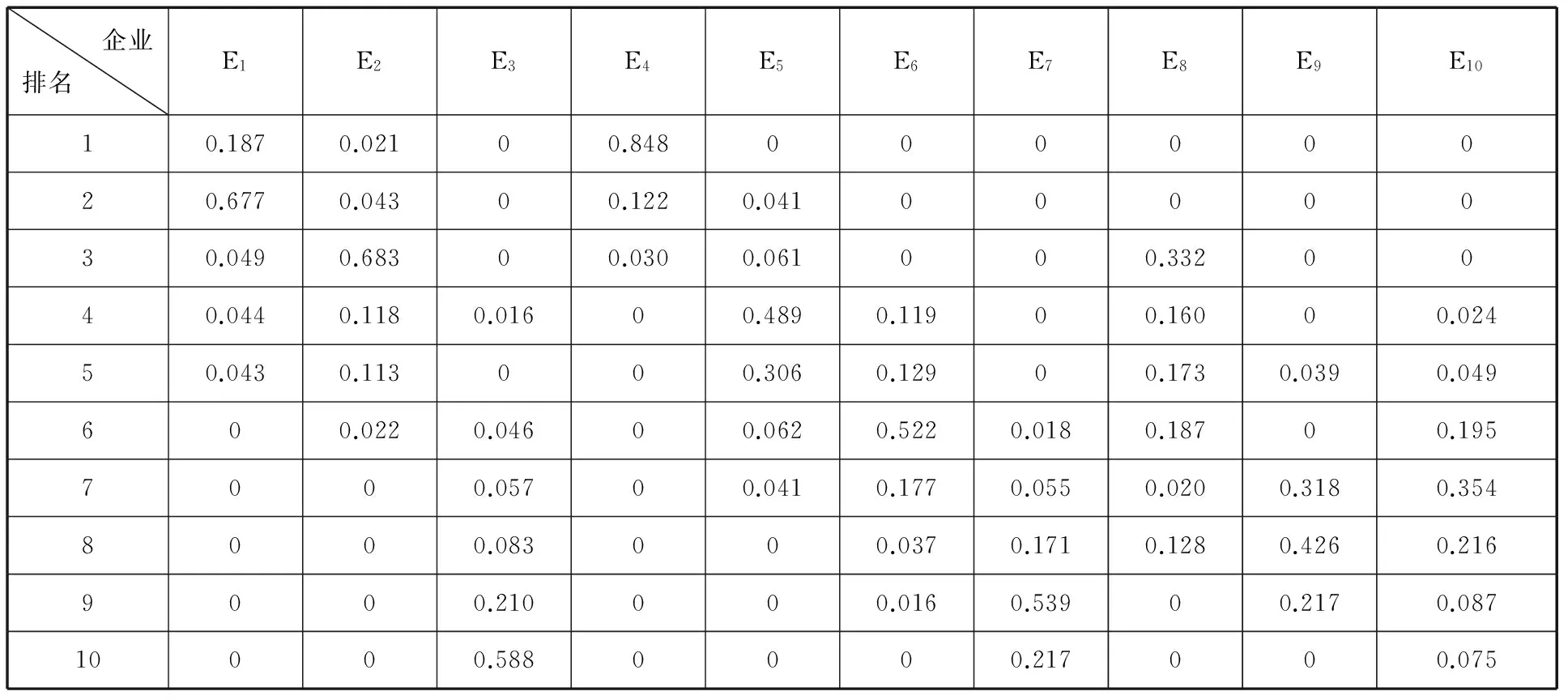
企业排名 E1E2E3E4E5E6E7E8E9E1010.1870.02100.84800000020.6770.04300.1220.0410000030.0490.68300.0300.061000.3320040.0440.1180.01600.4890.11900.16000.02450.0430.113000.3060.12900.1730.0390.049600.0220.04600.0620.5220.0180.18700.1957000.05700.0410.1770.0550.0200.3180.3548000.083000.0370.1710.1280.4260.2169000.210000.0160.53900.2170.08710000.5880000.217000.075
(3)计算企业的综合评价得分并排序
首先分别对每个排名进行赋值,Sr=(s1,s2,s3,s4,s5,s6,s7,s8,s9,s10)=(10,9,8,7,6,5,4,3,2,1)。然后,针对每个企业利用排名对应的分值乘以排名的概率,再累计求和得到每个企业的数据治理综合评价得分,并据其进行排序。企业数据治理综合评价得分和排序结果如表3所示。

表3 企业数据治理综合评价结果
(二)结果分析与讨论
通过基于方法集的综合评价模型对安徽省10家金融企业的数据治理现状进行综合评价,克服了传统独立评价方法的局限性。例如企业2在ELECTREE评价模型下,评价结果偏向于排在第5名,而在其余4种方法下都偏向于排在第3名。ELECTREE评价模型下的评价结果与其余模型的评价结果存在明显的不一致。本文引入证据理论,通过改进的证据合成方法对不同评价结果进行综合,得到企业2排在第3名的结果。如图5所示,我们可以看出合成后的评价结果比较符合实际情况,证明了该综合评价模型的有效性。

图5 企业2评价排名概率统计
又如企业4在PROMETHEE评价模型下,评价结果偏向于排在第2名,而在其余4种方法下都偏向于排在第1名。PROMETHEE评价模型下的评价结果与其余模型的评价结果存在明显的不一致。本文引入证据理论,通过改进的证据合成方法对不同评价结果进行综合,得到企业4排在第1名的结果。如图6所示,我们可以看出合成后的评价结果比较符合实际情况,再次证明了该综合评价模型的有效性。
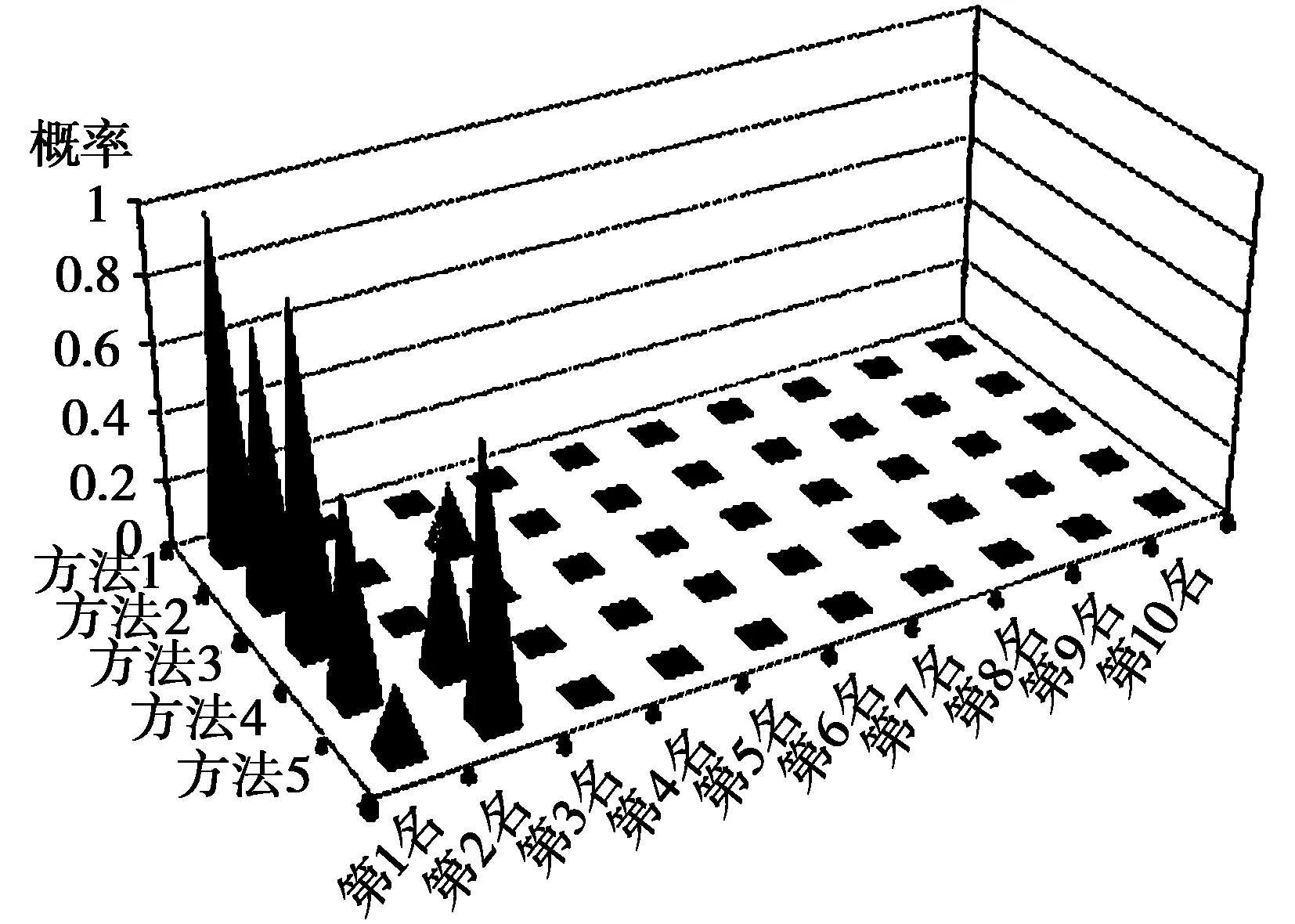
图6 企业4评价排名概率统计
本文基于方法集的综合评价思想,应用改进的证据合成方法对企业数据治理进行了评价,得到了较贴近实际的评价结果,为企业及时正确的了解数据治理水平提供了新方法,并为企业提升核心竞争力提供了新途径。
四、结 语
在大数据时代,数据成为企业发展的关键性生产要素,随之而来的数据治理也成为日趋重要的新兴研究领域。因此,对数据治理及其评价进行深入研究有着重要的理论和现实价值。考虑到企业数据治理评价的复杂性和单一评价方法具有的不稳定性和非一致性等问题,本文提出了基于方法集的企业数据治理综合评价模型。
通过本文研究,一方面将基于方法集的综合评价模型与证据理论相结合,并将该新评价模型应用于企业数据治理评价领域,为企业数据治理评价提供了一个新的评价思路,同时也开辟了解决多方法下评价结果不稳定和非一致性问题的新途径。但是另一方面,我们也应该看到,对企业数据治理评价问题的研究才刚刚开始起步,对其机理分析还存在很多不足。但随着对企业数据治理的研究不断深入,相信会构建出更为有效的企业数据治理评价模型。
[1]维克托·迈尔·舍恩伯格. 大数据时代[M].杭州:浙江人民出版社,2012.
[2]许继楠,郭 涛.大数据时代更需要数据治理[N].中国计算机报,2011.
[3]杨 洁.构建企业级数据治理体系——访中国光大银行股份有限公司信息科技部总经理杨兵兵[J].中国金融电脑,2012,12(2):28-30.
[4]陈 超.基于熵权和AHP的数据综合治理评价模型研究[J].福建电脑,2013,29(9):87-90.
[5][7]王 刚,黄丽华,高 阳.基于方法集的农业产业化综合评价模型[J].系统工程理论与实践,2009,29(4):161-168.
[6][8]秦庭荣,陈伟炯,葛育英,等.证据理论在港口航行环境安全组合评价中的应用[J].中国安全科学学报,2007,17(9):119-123.
[9]陈国宏,李美娟.基于方法集的综合评价方法集化研究[J].中国管理科学,2004,12(1):102-106.[10]柳玉鹏,李一军.组合评价方法在银行信用风险评价中的应用[J].中国管理科学,2008,16(专辑):215-218.
[11]闫 昆,刘国生,张园远,等.基于层次分析法构建巢湖北部矿区环境评价体系[J].合肥工业大学学报:自然科学版,2012,35(8):1106-1112.
[12]李文立,郭凯红.D-S证据理论合成规则及冲突问题[J].系统工程理论与实践,2010,30(8):1422-1432.
[13][16]王 刚,张成洪,黄丽华.基于方法集的企业知识管理评价研究[J].科技进步与对策,2009,26(7):115-119.
[14]VINCENT MOUSSEAU, LUIS DIAS. Valued outranking relations in ELECTRE providing manageable disaggregation procedures[J].European Journal of Operational Research,2004,152(6):467-482.
[15]王荫樑.基于PRCMETHEE理论的海上风险管理决策评价方法研究[D].大连:大连海事大学,2012.
[17]Fernandez-Castro, Jimenez M. PROMETHEE: An extension through fuzzy mathematical programming[J].Journal of the Operational Research Society, 2005, 56(1): 119-122.
[18]吕 强.TOPSIS在供应商评价中的应用[J].价值工程,2004,22(1):66-68.
[19]李顺才,常 荔,邹珊刚.企业知识存量的多层次灰关联评价[J].科研管理,2001,22(3):73-78.
[20]赵克勤.集对分析及其初步应用[J].大自然探索,1994,13(47):67-72.
[21]陈圣群,王应明,施海柳.多属性匹配决策的等级置信度融合法[J].系统工程学报,2015,30(1):25-33.
[22]周 谧,刘心报,杨剑波.基于改进的证据推理方法的企业R&D成果验收评估[J].合肥工业大学学报:自然科学版,2009,32(8):1183-1188.
[23]Jousselme A L, Grenier D, Bosse E. A New Distance between Two Bodies of Evidence[J].Information Fusion,2001,2(2):91-101.
[24]荆 浩.大数据时代商业模式创新研究[J].科技进步与对策,2014,31(7):15-19.
责任编校:陈 强,王彩红
2015-08-10
国家自然科学基金(71101042,71471054);高等学校博士学科点专项科研基金(20110111120014);中国博士后科学基金(2011M501041,2013T60611)
汪 杨,女,四川邛崃人,硕士研究生,研究方向为数据治理和信息管理。 王 刚,男,江苏连云港人,博士,副研究员,研究方向为商务智能和数据挖掘。
F270
A
1007-9734(2015)05-0093-09
猜你喜欢
第一财经(2022年6期)2022-06-15
石油沥青(2021年4期)2021-10-14
世界科学技术-中医药现代化(2021年10期)2021-03-02
军事运筹与系统工程(2019年1期)2019-11-16
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
领导决策信息(2017年11期)2017-05-17
幼儿智力世界(2016年6期)2016-05-14
小雪花·初中高分作文(2015年10期)2015-10-24
俄罗斯问题研究(2012年1期)2012-03-25
体育师友(2012年4期)2012-03-20
