
商务语篇翻译抄袭鉴定研究——以语篇信息为视角
2015-06-15 07:15:50孙波
周口师范学院学报 2015年6期
孙 波
(合肥师范学院 外国语学院,安徽 合肥230601)
近年来,随着版权意识的提高,翻译抄袭现象已经得到了国内翻译界的高度重视[1]。翻译抄袭可以分为两类:一是抄袭者抄袭现有的译语文本,导致多个译语文本的产生;一是抄袭者将源语文本译成译语文本而不加说明,让读者误以为该译语文本的内容具有独创性。就研究者掌握的资料来看,国内有关翻译抄袭案件的报道均属于前一种情形。而对于后一种情形,严格地说,其准确名称应当是跨语言抄袭而非翻译抄袭[2]。
Rodríguez分析了不同文体译文之间相似度的差异,认为专业文本(如科技文本、法律文本)翻译的相似性要明显高于文学文本翻译,因为前者存在译名固定的专业术语,译者的自由度较低,而对于后者,译者则拥有相对较多的自由和独作空间[3]。因此,本研究着重探讨前者,探索商务语篇翻译抄袭的鉴定方法,旨在为译者维权提供相应的语言证据,从而有助于保护译者的版权。
一、相关研究述评
(一)翻译抄袭研究
当前学界对于翻译抄袭鉴定的研究尚处于初始阶段,直接相关的研究成果并不多见。原因可能在于翻译抄袭的鉴定存在较大难度。一方面,由于所有的译文都试图重现原文的内容与形式,因此译文和原文存在相似性;而另一方面,译文越忠实于原文,译文之间的相似度就越高,就越难以判定是否存在抄袭[4]。此外,法庭往往倾向于采信量化证据,而翻译抄袭鉴定中很难回避的一个问题是两个译文之间必须达到多大程度的相似性才足以判定存在抄袭。为此,Turell建议对鉴定标准进行量化,认为语言学分析有助于确立鉴定抄袭的相似度标准,对于同一主题的不同文本,如果词汇重叠率达到50%以上,就有理由认为这些文本之间存在抄袭,但对于译文来说,这个标准要适当提高一些,她认为应当设置为70%[5],但并没有做相应的实证研究验证此标准的合理性。
然而,以上的鉴定方法都是以词汇或词组重叠率为基础,而据中国翻译协会网站报道,当前一些抄袭者往往采用次序颠倒的手段,改变原译文的句法结构;或采用移花接木的手段,对两个或三个以上的版本同时进行抄袭,抄一段再改写一段;抑或是采用文字解构手段,变动词汇,进行同义词替换。由此可见,由于这些手段会降低译文间的词汇重叠率,传统的鉴定方法已经不足以应对这些抄袭方法,因此,新的鉴定方法亟待探索。
(二)语篇信息理论
语篇信息理论将语篇中的所有信息看成一个树状层级系统,认为每个语篇具有且只具有一个核心命题,该核心命题由一系列信息逐级发展而成,各层信息单位都是对其上层信息单位的某一方面的发展,所有信息单位可以用15个疑问词表示[6]。信息单位由信息成分构成,信息成分根据性质,可划分为过程、个体、环境三大类,每一大类又可细分为若干小类[7]20,如表1所示。
当前,语篇信息理论已经应用到文本鉴别领域[8],取得的鉴别效果良好。尽管由于译者的主体性及其制约因素贯穿整个翻译过程,导致了译语文本的不同形式,但不可否认,翻译离不开信息表达,译文的产生是译者信息表达的结果。因此,以语篇信息理论为视角,构造基于N元信息序列的个人言语特征,可能会有助于翻译抄袭的鉴定。
二、研究设计
(一)研究假设
由于二元语法序列的判别效果要优于更长的语法序列[9],本研究提出以下两点假设:
1.不同译者二元信息成分序列组合方式存在不同,即译者间差异性。
2.同一译者二元信息成分序列组合方式具有相似性,即译者内稳定性。
(二)语料选取
本研究选取了In Search of Excellence一书,该书在2002年9月30日被《福布斯》杂志评为20世纪20本最佳商业书籍之一。该书的中文译本是胡玮珊2012年所译,名为《追求卓越》,由中信出版社出版。
采用案件模拟的形式,邀请某高校1名英语专业在读研究生参与本研究。被试在通读完英文本第二章4个小节之后,自由选择对每小节中约一半原文进行独立翻译,其余部分则采用变动句法顺序、变动词汇等手段对胡玮珊译本的相关内容进行抄袭。
因此,本研究涉及的语料可以分为三组:被试独立翻译的译文(以下简称A语料),按小节编号成A1、A2、A3和A4;胡玮珊的译文(以下简称B语料),按小节编号成B1、B2、B3和B4;被试抄袭的译文(以下简称C语料),按小节编号成C1、C2、C3和C4。
三、分析与讨论
(一)定性描述
经仔细观察各组语料,发现涉嫌抄袭的语料基本采用了同义词替换、变动句法顺序以及增加无实质意义表达这三种手法。试举例如下:
例1:
(注:黑体加下划线处表示同义词替换,着重号处表示变动句法顺序,波浪线处表示增加无实质意义表达)
例1的涉嫌抄袭译文中有6处采用了同义词替换的手段,将原译文中的“加强”“进而”“项目”“很类似”等词语替换成意思基本相同的“加深”“进一步”“范畴”和“非常相似”。抄袭者还2次采用了变动句法顺序的手法,将原译文中“联想不同的职业”以及“要和其他人互动的职业”改为“对不同职业展开联想”和“职业往往需要和其他人互动”。此外,抄袭译文中还有1处采用了增加无实质意义表达的方法,将原译文中“其理性取向”变为了“其在理性取向方面”。
然而,仅仅依靠定性描述的方法,无法说明涉嫌抄袭的译文是否来自于胡玮珊译本,因此,有必要对其进行定量分析,从而得出一个量化的判断。
(二)定量分析
1.分析单位
本研究中的语料切分以小句为基本单位,根据信息成分的所属类型,对小句内的信息成分进行逐一标注。标注时,如果一个小句由2个或2个以上信息成分组成,则按先后顺序构成1个或多个二元信息成分序列。需要指出的是,二元信息成分序列存在于同一小句内部,即前句最后1个信息成分不与后句第1个成分构成二元信息成分序列。如下例所示:
例2中,第1个小句中的“老是”与“变来变去”构成一对二元信息成分序列ce-pt,第2个小句中的“今年”与“强调”构成一对二元信息成分序列ct-pb,而“变来变去”与“今年”由于分属两个不同的小句,不构成二元信息成分序列。
为确定标注标准,研究者随机选取了全部语料中的10%,由两位标注者(包括研究者本人和另一位熟悉语篇信息理论的英语专业教师)对其中的信息成分分别进行标注。经反复讨论统一标准,标注的Kappa值提高到0.82,从而满足了标注者信度要求[10]。之后,研究者根据统一后的标注标准对剩余语料进行了标注。最后再分别检索、统计出语料中各种二元信息成分序列的出现频次。
2.判别分析
判别分析可以根据已知样本的分类情况判断未知样本的类别归属问题,其在文本鉴别领域已经得到应用[8]。因此,本研究将采用此种统计方法判断翻译抄袭的可能性大小。
由于低频次的二元信息成分序列在各组语料之间可能不存在统计学差异,从而影响判别分析的效果,因此研究者选取了出现频率最高的10组二元信息成分序列作为统计量。此外,由于各语篇长短不同,语篇中的信息成分总数也有差别,若将二元信息成分序列的频数作为分析变量直接进行比较,则不具有可比性,故而研究者采用二元信息成分序列的频率值,即每一种二元信息成分序列频数与其所在语篇中所有信息成分频数的比值。
得出数据之后,利用SPSS对三组语料进行判别分析,结果如图1所示:
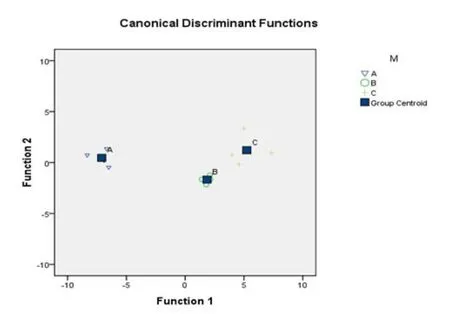
图1 语料分析结果
首先讨论译者间差异性。从图1可以看出,A组与C组之间的距离最大,A组与B组之间的距离次之,B组与C组之间的距离最小,但三组之间的距离都较为明显,较好地说明了三组语料之间具有差异性。其中,A组和B组之间的差异可能是译者不同而导致的,而C组和A组之间的距离大于其和B组之间的距离,意味着C组与B组更为相似。此外,C组之所以没有落在B组的范围内,原因可能是被试抄袭胡玮珊译本并有所改动,导致该组语料的二元信息成分序列特征出现一定的差异。
其次是译者内稳定性方面。每组内部的语篇样本较为紧密地集中在一起,特别是A组和B组聚合度较高,表明二元信息成分序列特征在同一译者译文内部差异较小。C组的聚合效果并不十分理想,可能是因为C组语料混合了被试和胡玮珊译本的相关语言特征,而并非由一位译者独立翻译完成。
3.词汇重叠率分析
为与基于词汇重叠率的分析方法进行对比,本小节将两种方法的鉴定结果进行比较。由于较高的词汇重叠率是不同译文之间普遍存在的现象[4],因此,为更好地比较被试译本和胡玮珊译本的相似程度,研究者引入了另一译本(龙向东等译)作为对比语料,将三者进行两两配对,计算词汇重叠率,计算过程由研究者自行编写的软件程序完成。经计算,胡—龙译本的词汇重叠率最低,仅为24.7%。被试—龙译本的词汇重叠率略高,为37.12%,其原因可能在于同义词的个数有限,而被试进行同义词替换之后,与龙译本中的词汇重叠的概率增加。被试-胡译本的词汇重叠率最高,达到55.95%。可见,尽管对译文做了改动,抄袭译文与原译文的词汇重叠率仍然很高。
(三)讨论
虽然语言的表层形式多种多样,难以把握规律,而深层的认知规则又难以直接观察,但二者之间存在的信息层则相对稳定[7]115。对于翻译抄袭来说,固然抄袭者可以使用同义词替换等手段,使得语言的表达形式看起来似乎存在差异,但同义词之间表达的信息是相对稳定的。如例1中,原译文的“为了学生对此的理解”被被试译本改成“为了学生对此的理解”,尽管用词有差异,但“加强”和“加深”都与后面的“学生”形成了一个pbed二元信息成分序列。相比之下,龙向东等人的译本中对此处的翻译是“为了加深理解,莱维特要学生……”,“加深”和“理解”构成的则是pb-ef的二元信息成分序列。可见,同义词替换很难影响二元信息成分序列的稳定性。
另一方面,虽然被试还采用了变动句法顺序和增加无实质意义表达,但是这些抄袭手段的频次没有同义词替换的频次高。如例1中,同义词替换的频次为6次,而变动句法顺序和增加无实质意义表达的频次总计也只有3次,其原因可能在于词汇手段相对于句法手段需要抄袭者做出更多的语言努力。由于这两种抄袭手段的频次相对较低,其对二元信息成分序列的稳定性影响有限。
相比之下,利用词汇重叠率进行翻译抄袭的判断,最大的问题是译文之间本身就高度相似,而重叠率究竟达到多少才能认定为抄袭尚存争议[5]。本研究中,由于被试采取了同义词替换等手段,尽管被试译文与胡玮珊译文的词汇重叠率为三组中最高,达到55.95%,但没有达到Turell所主张的70%的基准线,无法得出存在抄袭的判断。相比之下,利用判别分析的结果图,可以看出抄袭译文与胡玮珊译文更接近,而与被试独立翻译的译文差别明显。
本研究以语篇信息理论为视角,通过判别分析,探讨了二元信息成分序列在翻译抄袭中的鉴别作用,并将其与词汇重叠率分析法进行了对比。结果发现,二元信息成分序列在不同译者内具有差异性,而在相同译者内具有较好的稳定性。相对于词汇重叠率分析法,二元信息成分能较好避开词汇重叠率中的基准线问题。但是,本研究的样本量较少,得出的结论还有待进一步增加被试扩大样本量进行验证。此外,本研究中的语料为专业文本,研究结论在文学文本中是否成立还需另行研究。
[1]楚至大,张华华.试论我国当前翻译界的抄袭现象[J].外国语,1998(2):23-28.
[3]Rodríguez Tapia,J.M.Traduttore,traditore:Plagio y originalidad de una traducción[C]//Comentario a la sentencia del Tribunal Supremo(Sala 1a)de 29de diciembre de 1993[].Revista General de Derecho,1995:771-779.
[4]Coulthard,M,Johnson,A,Kredens,K,Woolls,D.Four forensic linguists’responses to suspected plagiarism[C]// M.Coulthard & A.Johnson (eds)The Routledge Handbook of Forensic Linguistics.New York:Routledge,2010:523-538.
[5]Turell,M T.Textual Kidnapping Revisited:the Case of Plagarism in Literary Translation[J].International Journal of Speech Language and the Law,2004(1):1-26.
[6]杜金榜.法律语篇树状信息结构研究[J].现代外语,2007(1):40-50.
[7]杜金榜.法律语篇信息研究[M].北京:人民出版社,2015.
[8]孙波.二元语篇信息序列在作者归属分析中的应用研究[M]//郭万群.中国法律语言学研究:理论与实践.上海:上海交通大学出版社,2013:104-111.
[9]Turell,M T.The use of textual,grammatical and sociolinguistic evidence in forensic text comparison[J].The International Journal of Speech,Language and the Law,2010(2):211-250.
[10]Van Someren,M W,Barnard,Y F,Sandberg,J A.The think aloud method:A practical guide to modelling cognitive processes:Vol.2[M].London:Academic Press,1994.
猜你喜欢
天津外国语大学学报(2021年1期)2021-03-29 03:07:20
西夏研究(2019年1期)2019-03-12 00:58:16
疯狂英语(双语世界)(2017年4期)2017-04-28 09:10:28
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
当代修辞学(2014年1期)2014-01-21 02:30:16
当代修辞学(2014年1期)2014-01-21 02:30:12
中学教学参考·语英版(2008年8期)2008-11-26 10:42:12
