
基于在线重建的遥操作预测显示系统
2015-06-09 20:18孙汉旭贾庆轩
东南大学学报(自然科学版) 2015年3期
胡 欢 孙汉旭 贾庆轩
(北京邮电大学自动化学院,北京100876)
基于在线重建的遥操作预测显示系统
胡 欢 孙汉旭 贾庆轩
(北京邮电大学自动化学院,北京100876)
为了提高遥操作的操作效率,采用一种基于单目视觉的预测显示方法来解决时延导致的视觉反馈滞后问题.该方法通过基于地图的相机位姿估计算法来实时跟踪机器人的状态,在线构建机器人工作环境的三维几何结构模型,并结合多纹理映射技术进行渲染,将模型重投影到预测视点下,得到逼真的预测图像.搭建了一个基于客户端-服务器端模式的系统平台,用于未知环境下的遥操作.结果表明,在总长为7.112 m的摄像机运动轨迹中,位姿跟踪的平均误差约为0.015 m.该系统不仅能提供预测图像,而且支持生成任意视点的图像,有利于操作者从各个角度观察机器人工作场景.
预测显示;遥操作;同步定位与地图构建;机器视觉
机器人已被广泛应用于远程环境(如太空、外星球、远程手术、水下、灾后救援等)中,研究对远程机器人的高效鲁棒控制是一项重要任务.其控制方法包括自主控制和遥操作两大类.在目前智能技术尚未完全成熟的情况下,遥操作仍是一种不可或缺的操作控制方式.机器人实际运动和遥操作控制命令之间存在的时延会导致操作性能下降.预测显示被认为是一种有效解决遥操作时延的方法,通过将时延排除在本地控制回路之外,消除时延对系统稳定性的影响,能够大幅提升遥操作的成功率和执行效率[1-2].
传统的预测显示技术中,首先利用先验知识构建环境及机器人虚拟模型,然后根据远端反馈回来的各种传感器信息在线修正虚拟模型,操作者通过仿真的虚拟环境来感知真实机器人工作环境.然而,有时机器人的操作环境是无法事先预知的.Xie等[3]提出了一种基于增强现实的遥操作方法,通过叠加虚拟机器人模型到延时视频流上,操作者可以实时了解虚拟机器人和真实机器人的匹配程度,从而进行在线修正,这在很大程度上提高了操作者的作业能力;然而,该方法仅对机器人的状态进行了预测,大多应用于摄像机固定的情形,且环境是静态的.如果摄像机是受操作者控制而运动的,仍需对摄像机视野中环境的改变进行预测.Jägersand[4]提出了一种基于图像插值的快速预测显示方法,将其与基于增强现实的遥操作方法有效结合,从而达到同时预测机器人状态和工作环境的目的.然而,基于图像插值方法生成的预测图像逼真度较差.
随着近年来3D重建技术的飞速发展,在线实时重建逐渐成为可能,将该技术引入到预测显示遥操作系统中是一种发展趋势.Kelly等[5]搭建了一个遥操作系统平台,通过融合深度数据和双目彩色图像构建出一个逼真的3D场景模型,从而使操作者能够高效地遥操作远程移动车辆;然而,多传感器的融合所产生的传感器间标定误差会影响系统的鲁棒性.Rachmielowski等[6]提出了一种基于单目视觉的预测显示方法,通过对视频图像进行同步定位与地图构建,重建场景的3D模型,并将其重投影到预测视点下,得到预测图像;然而,这种3D模型是离线构建的,无法实时更新.
本文提出了一种基于在线模型构建的预测显示方法,在进行跟踪与地图构建的同时能够增量式扩展3D模型.
1 预测显示系统架构
预测显示的目标是处理时延带来的视觉反馈滞后问题,通过在操作端根据已接收到的延时视频流来构建远程机器人及其工作环境模型,以预测基于操作者控制输入的即时视觉反馈,使操作者可以进行连续的遥操作控制,无需等待远程机器人端反馈的视觉信息.预测显示遥操作系统是一种典型的客户端-服务器系统,其架构如图1所示.
图1上半框图中的软件模块位于机器人端(客户端).跟踪与地图构建模块根据视频图像估计机器人的当前位姿,同时构建环境地图.地图是指基于视觉特征检测方法获取的场景3D特征点云模型.将模块置于机器人端是考虑到遥操作通信链路带宽的限制.传输完整视频会占用大量带宽,且视频含有大量冗余信息,将部分关键帧图像传输到操作端是一种有效的解决带宽限制的方法.传输关键帧图像来代替完整视频流,可较大程度地减少数据传输量.

图1 预测显示系统架构
图1下半部分位于操作端(服务器端),是操作者操纵远程机器人的软件平台.交互输入模块接收控制输入,并转化为机器人控制命令,发送给客户端的机器人控制器模块,同时还发送控制指令到预测显示模块,以得到预测图像.此外,该模块也包含了一些远程模块交互控制命令,如选择指定图像构建地图、保存地图等操作.模型构建模块接收到远程地图数据,构建出机器人工作环境下的3D几何结构模型.3D模型可视化模块根据接收到的关键帧图像,负责对几何结构模型进行纹理渲染,实现逼真可视化.预测显示模块根据控制命令解算相机当前位姿,渲染3D模型,得到预测图像,补偿视觉反馈滞后,是操作者高效地进行下步决策的重要依据.
2 跟踪与地图构建
跟踪与地图构建模块可实现基于单目视觉的相机位姿跟踪与地图构建2个核心功能.目前主流的视觉跟踪方法有帧间跟踪方法和基于地图的跟踪方法.帧间跟踪方法是指对连续2帧图像进行匹配并计算相对位姿,累加后便可得到全局位姿;该方法会造成误差累积,通常还需要通过路径闭合的方法以优化位姿,但前提是必须能够检测到闭合,这在很大程度上限制了其应用范围.基于地图的跟踪方法首先通过2帧图像构建初始3D地图,然后根据已有的相机位姿估算相机运动模型,预测下一时刻相机的可能位姿,将所有地图点重投影到该预测视点下,在当前待跟踪图像中查找匹配点,并根据匹配误差修正预测相机位姿,从而得到最终的位姿估计;该方法建立在一个全局的地图模型下,通过不断优化全局地图来减少误差,从而有效缩小了误差的累积.本文采用基于地图的跟踪算法,同步实现了跟踪和地图构建的功能.
2.1 初始地图
本文采用立体匹配原理构建初始地图.在初始阶段需要人为选择2帧图像作为立体匹配的首要条件.具体过程如下:① 针对这2帧图像,利用自适应通用加速分割算法(AGAST)[7]来检测特征点,并采用基于块的零均值像素灰度差平方和算法查找匹配点对;② 采用五点算法[8]结合随机抽样一致算法(RANSAC)来估计基础矩阵;③ 进行匹配点对的三角化,得到初始地图.
使用AGAST算法代替FAST特征检测算法,对并行跟踪与地图构建算法(PTAM)[9]进行改进,可使检测速度提高将近2倍.
2.2 在线跟踪
在线跟踪的目标是实时估计机器人的位姿.首先,基于上一时刻相机运动速度来预测当前的相机位姿.利用刚体变换群SE(3)来表示相机位姿,指数和对数运算可实现3×4维位姿变换矩阵和六自由度参数间的转换.利用六自由度参数向量来表示位姿变换矩阵,可提高计算效率.相机运动速度的计算公式为
(1)
式中,Vt为第t帧图像的相机速度;Pt为第t帧图像的相机位姿;dt为第t帧图像的时间间隔.
预测位姿的计算公式为
(2)
根据重投影误差更新相机位姿.首先,根据相机的透视投影模型将已有的3D地图点投影到预测视点下,得到预测投影位置;然后,在预测投影位置邻域范围内寻找对应的匹配位置;最后,采用Levenberg-Marquardt算法[10]对重投影误差进行最小化处理,更新相机的位姿.
2.3 地图扩展
随着机器人的不断探索,初始地图可能已经在机器人摄像头视域之外,因此需要不断地对地图进行扩展.地图扩展是指,通过对2个已跟踪的关键帧图像执行极线搜索匹配点对,进行三角化处理得到3D点,将其加入到已有地图点云模型中.
关键帧的选取标准如下:
1) 时间间隔性.连续帧往往存在大量的冗余信息,因此在算法初始阶段,假定2个关键帧的时间间隔大于20帧,并基于已有关键帧图像间重合度来修正该间隔值,如果重合度小于30%,则适当减小该值;如果重合度大于80%,则适当增大该值.
2) 空间间隔性.在空间上,2个关键帧之间应该保留一定的间隔距离,确保极线搜索有足够的基线.这样一方面可尽量减少冗余信息,节省存储空间;另一方面也减少了在极线匹配和后续的地图优化过程中执行关键帧搜索的用时.关键帧的数目在很大程度上影响了算法的速率.间隔距离由当前场景的平均深度决定.间隔距离的计算公式为
(3)
式中,sini为手动选择的2个关键帧间的距离;dref_depth为初始化时得到的场景平均深度;davg_depth为当前帧的平均深度.
3) 位姿准确性.只有跟踪质量好的图像帧,才可能成为关键帧.首先把所有地图点投影到当前视点下,得到m个投影点;然后,在当前图像中搜寻对应的匹配点,假设有n个点匹配成功,则跟踪质量定义为成功匹配点数占总投影点数的比例,即s=n/m.如果s<0.3,则认为跟踪质量较差;否则认为跟踪质量较好.
2.4 地图优化
地图优化是指不断根据新测量数据校准已有数据的过程,是提高系统精度和鲁棒性的主要步骤.集束调整是一种鲁棒的地图优化方法,通过最小化重投影误差迭代修正关键帧位姿及地图点位置,模型化为求解如下目标函数的非线性最小二乘问题:
(4)
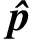
本文采用Levenberg-Marquardt算法求解非线性最小二乘问题.其核心问题是求解雅克比矩阵.首先,引入3D点的透视投影变换公式,即

(5)
式中,Pw,Pc分别为点P在世界坐标系和相机坐标系下的三维坐标,且Pc={xc,yc,zc}T;K为相机的内参矩阵;M为估计相机位姿相对于世界坐标系的变换矩阵,依据刚体变换群SE(3)的特性,M=eεA,其中A为相机的真实位姿变换矩阵;⨁运算表示点相对于相机的投影变换[11].

式中,Rc为相机位姿变换矩阵M中的3×3旋转子矩阵.
3 模型重建与预测显示
模型重建的目标是根据散乱点云构建场景的几何网格模型,采用基于3D Delaunay三角化的自由空间雕刻方法[12],增量式扩展构建网格模型,其输入来源于跟踪与地图构建模块中不断更新的地图数据.本文采用事件关联机制来实现地图构建与模型构建的同步,即在地图事件发生的同时,触发模型构建模块的相关事件,其关联如图2所示.
当添加关键帧到地图时,触发以下3个模型构建事件:添加新网格点、记录新关键帧、插入可见视线.添加新网格点的过程为:首先找到该点所在的3D网格,并将其删除;然后针对所有和删除网格相关联的3D点及新插入点,执行3D Delaunay三角化,重新构建新网格.记录新关键帧事件是指添加新关键帧到关键帧队列中,其数据包含了图像(用于可视化模块的纹理渲染).插入可见视线事件记录点和关键帧的关联关系,同时判断此可见视线是否违背自由空间约束(即相交于某已存在的网格面),如果违背则删除相交的网格面.

图2 地图更新与模型更新的关联
对地图进行集束调整优化时,模型构建模块需执行以下几个事件:点位置调整、关键帧位置调整、可见视线删除、坏点删除.点位置调整等同于先执行坏点删除事件,然后执行添加新网格点事件.关键帧位置调整是指从关键帧队列中找到该关键帧,修改其位姿,如果位姿有较大变化,则遍历所有关联的可见视线,执行可见视线插入事件.可见视线删除是指去除与其相关的点和关键帧的关联属性.坏点删除是指先删除所有相关的关键帧关联属性,然后删除所有相关网格,最后对其邻域内所有点重新执行3D Delaunay三角化,生成新网格.
网格模型的可视化能够带给操作者逼真的临场感.逼真可视化算法是通过将关键帧图像投影到网格模型上来实现的.本文选择空间上最近的4帧关键帧图像进行多纹理融合映射.纹理融合是通过加权合并来实现的.针对渲染点p,第i(i∈{1,2,3,4})帧图像对应的权值计算公式为
式中,Vi,Ni分别为根据视线夹角和法线向量计算的权重分量;Si为深度测试值;Pi为第i帧图像对应的相机位置;Pcr为渲染视点位置;Pn为渲染点p的法线向量;Zr,Zb分别为渲染点p在渲染视点下和深度缓冲区中存储的深度值,且当Zr>Zb时,渲染点p在第i帧图像中不可见,故权值为0.当Vi>0时,表示渲染视线与当前相机的观察视线夹角小于90°,且夹角越大,此值越小;当Vi<0时,表示夹角大于90°,直接设置Wi=0,表示第i帧图像对当前渲染效果无影响.当Ni>0时,表示点p在第i帧图像中可见;反之不可见,设置Wi=0.
考虑到高效性的需求,纹理融合是通过OpenGL软件中的着色语言实现的.预测视点的计算是根据操作者的控制输入来解算的.预测显示能够及时为操作者的下一步决策提供实时依据,无需等待延时的反馈图像,从而实现高效的遥操作.
4 实验验证
搭建了一个用于机器人预测显示遥操作的客户端-服务器端系统,通过真实场景数据来验证预测显示效果.机器人端平台运行在一个轻量级的笔记本电脑上,其型号为联想Thinkpad X230t,处理器为2.4 GHz Intel Core(TM) i3-2370M.操作端运行在一个组装的台式电脑上,其处理器型号为3.50 GHz Intel Core(TM) i7-3770K,同时配有NVIDIA GeForce 7800 GT图形卡.2个电脑上均运行ubuntu 12.04系统.软件平台搭建在一个通用机器人软件开发平台ROS[13]上,每个子模块封装为一个节点,节点和节点之间通过消息进行通信.这种模块化程序设计有利于应用程序的扩展.
本文将从数据传输量、位姿跟踪的精确度和验证预测显示3个方面来验证系统的可行性.
4.1 数据传输量
考虑到遥操作通信链路带宽的限制,大量数据的传输会降低系统的效率.实验中采集了3个室外场景视频,其分辨率分别为 640×320,640×480,752×480像素,记录软件运行过程中传输不同类型数据的平均数据传输量,结果见表1.平均传输数据量等于总数据量除以视频总帧数;图像视频数据的平均传输数据量即为每帧图像大小;关键帧数据包括了关键帧图像及位姿数据;地图数据包括三维点云及相应的地图事件数据.由表1可知,与传输图像视频数据相比,仅传输关键帧数据和地图数据时的平均数据传输量明显减少.
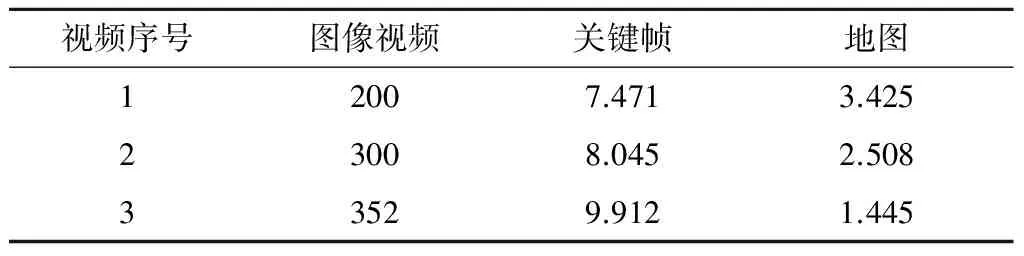
表1 网络平均传输数据量对比 kB
4.2 位姿跟踪的精确度
根据操作者的控制输入及机器人的运动学和动力学理论,可以估算出机器人的位姿.但由于存在传感器及机构误差,随着时间的推移误差将不断累积,造成较大位姿偏移.因此,基于视觉对机器人位姿进行估计是必要的,这可在一定程度上补偿上述偏移.
在本文实验中,选用了RGB-D数据集[14]中的一组30 s视频数据freiburg1_xyz作为实验数据集,其分辨率为640×480像素,摄像机的运动轨迹总长为7.112 m,工作空间为0.46 m×0.70 m×0.44 m.通过比较绝对轨迹误差来验证跟踪的精确度.如图3所示,实验中共计算了736帧图像对应的相机位姿误差.由图可知,本文算法与RGB-D SLAM算法[14]具有相似的精确度.两者的平均误差分别约为0.015和0.012 m,误差中值分别约为0.013和0.011 m,最小误差分别约为0.001和0.001 m,最大误差分别约为0.115和0.034 m.本文算法的最大误差较大的原因在于,图像模糊有时会造成特征检测与匹配失败,从而导致跟踪失败;RGB-D SLAM算法通过引入深度测量,避免了跟踪失败.然而,本文算法的优势在于对平台要求较低,可运行在通用的CPU平台上,仅需单一摄像机;而RGB-D SLAM算法则必须运行在GPU平台上,并且需要使用深度测量传感器.
图3 2种算法的相机位姿误差比较
4.3 验证预测显示
本实验通过安装在无人机底端的一个俯视相机来采集场景视频,在操作端人为引入4 s时延,即每当接收到关键帧数据和地图事件数据时先将其存储在等待队列中,经过4 s时延后再传送给模型构建模块进行处理.预测显示是由3D模型重投影得到的,结果见图4.由图可知,延时图像明显滞后,而预测图像则较为接近真实图像.在实验中,预测位姿为跟踪算法估算的实时图像位姿,预测图像和真实图像的差异正是由于位姿估计误差所造成的.利用本文算法获取的3D几何结构模型见图4(d),该模型是对稀疏的3D点云进行3D Delaunay三角化处理得到的,在程序运行过程中进行在线更新.

(a) 实时图像

(b) 预测图像

(c) 延时图像

(d) 3D模型
为了进一步验证三维重建的效果,选取了具有丰富纹理的实验室书架作为对象,重建结果见图5.图5(a)和(b)为任意视点渲染的图像,图5(c)为场景几何结构模型,它们分别代表了局部视域和全局视域.操作者可以从任意角度、任意距离观察场景来高效地遥控机器人.模型的可视化是通过融合距离当前渲染视点最近的4幅纹理图像来实现的.使用单幅纹理图像和多幅纹理图像的模型可视化结果见图6.由图可知,多幅纹理图像更有助于增加可视化区域.

(a) 远视点

(b) 近视点

(c) 全局几何结构模型

(a) 单纹理(近视点)

(b) 单纹理(远视点)

(c) 多纹理(近视点)
5 结语
本文搭建了一个客户端-服务器端模式的预测显示系统.该系统能够对操作者的控制输入提供即时的视觉反馈,将时延排除在本地控制回路之外.早期的预测显示系统大多针对结构化环境,需要事先构建场景模型,本文则将其扩展到未知环境下的预测显示遥操作中,利用单目视频在线重建方法对3D环境进行构建.在线重建包括了2个核心内容:跟踪与地图构建和模型重建与预测显示.通过多纹理融合映射技术,构建出一个逼真的模型可视化平台,既可以提供预测图像,又可以给操作者一个全方位的观测.实验结果表明,该预测显示系统能够逼真地预测延时图像,解决了时延造成的视觉反馈滞后的问题.配套软件平台可用于遥操作无人机、火星车、移动车辆、机械臂等各种远程机器人.
References)
[1]王永, 谢圆, 周建亮. 空间机器人大时延遥操作技术研究综述[J]. 宇航学报, 2010, 31(2): 299-306. Wang Yong, Xie Yuan, Zhou Jianliang. A research survey on teleoperation of space robot through time delay[J].JournalofAstronautics, 2010, 31(2): 299-306. (in Chinese)
[2]孙汉旭, 胡欢, 贾庆轩,等. 遥操作系统中预测显示技术研究[J]. 宇航学报, 2013, 34(11): 1502-1508. Sun Hanxu, Hu Huan, Jia Qingxuan, et al. Research on predictive display in teleoperation system[J].JournalofAstronautics, 2013, 34(11): 1502-1508. (in Chinese)
[3]Xie T, Xie L J, He L S, et al. A general framework of augmented reality aided teleoperation guidance[J].JournalofInformationandComputationalScience, 2013, 10(5): 1325-1335.
[4]Jägersand M. Image-based predictive display for high d.o.f. uncalibrated tele-manipulation using affine and intensity subspace models[J].AdvancedRobotics, 2001, 14(8): 683-701.
[5]Kelly A, Chan N, Herman H, et al. Real-time photorealistic virtualized reality interface for remote mobile robot control[J].TheInternationalJournalofRoboticsResearch, 2011, 30(3): 384-404.
[6]Rachmielowski A, Birkbeck N, Jagersand M. Performance evaluation of monocular predictive display[C]//IEEEInternationalConferenceonRoboticsandAutomation. Anchorage, Alaska, USA, 2010: 5309-5314.
[7]Mair E, Hager G D, Burschka D, et al. Adaptive and generic corner detection based on the accelerated segment test[C]//11thEuropeanConferenceonComputerVision. Heraklion, Greece, 2010: 183-196.
[8]Wu F C, Hu Z Y. 5-point and 4-point algorithm to determine of the fundamental matrix[J].ActaAutomaticaSinica, 2003, 29(2): 175-180.
[9]Klein G, Murray D. Parallel tracking and mapping for small AR workspaces[C]//6thIEEEandACMInternationalSymposiumonMixedandAugmentedReality. Nara, Japan, 2007: 225-234.
[10]Szeliski R. 计算机视觉——算法与应用[M]. 艾海舟,等译. 北京:清华大学出版社, 2012: 575-581.
[11]Blanco J L. A tutorial on SE(3) transformations and on-manifold optimization[R]. Seville, Spain: University of Malaga, 2010.
[12]Miller G L, Pav S E, Walkington N. Fully incremental 3D delaunay refinement mesh generation[C]//ProceedingsoftheInternationalMeshingRoundtable(IMR). Ithaca, NY, USA, 2002: 75-86.
[13]Cousins S. Exponential growth of ROS [ROS topics][J].IEEERobotics&AutomationMagazine, 2011, 18(1): 19-20.
[14]Sturm J, Engelhard N, Endres F, et al. A benchmark for the evaluation of RGB-D SLAM systems[C]//2012IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems. Vilamoura, Portugal, 2012: 573-580.
On-line reconstruction-based predictive display system for teleoperation
Hu Huan Sun Hanxu Jia Qingxuan
(Automation School, Beijing University of Posts and Telecommunications, Beijing 100876, China)
To improve the operation efficiency of teleoperation, a predictive display method based on monocular vision is proposed for solving the visual feedback delay problem caused by time delay. In this method, the robot’s poses are tracked in real-time by the map-based camera pose estimation algorithm. The three-dimensional geometry model under robot working environments is reconstructed on-line with rendering by multiple texture mapping technology. Finally, the realistic predicted image is obtained by projecting the model into the predicted view. The system platform based on the client-server architecture is constructed which is suitable for teleoperation under unknown environments. The experimental results show that the average error of pose tracking is about 0.015 m over a camera journey of 7.112 m. The proposed system can not only supply the predicted images, but also support to generate the images of arbitrary views, which benefits the operator observing the working environments of the robot from all angles.
predictive display; teleoperation; simultaneous localization and mapping(SLAM); robot vision
10.3969/j.issn.1001-0505.2015.03.007
2014-12-19. 作者简介: 胡欢(1986—),女,博士生;孙汉旭(联系人),男,博士,教授,博士生导师,hxsun@bupt.edu.cn.
国家自然科学基金资助项目(61175080)、国家重点基础研究发展计划(973计划)资助项目(2013CB733000).
胡欢,孙汉旭,贾庆轩.基于在线重建的遥操作预测显示系统[J].东南大学学报:自然科学版,2015,45(3):448-454.
10.3969/j.issn.1001-0505.2015.03.007
TP242
A
1001-0505(2015)03-0448-07
猜你喜欢
微型电脑应用(2020年12期)2020-12-25
无线互联科技(2018年20期)2018-12-27
大连理工大学学报(2017年4期)2017-08-07
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
温州医科大学学报(2016年9期)2016-10-31
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25
湖北工业大学学报(2016年5期)2016-02-27
西北工业大学学报(2015年3期)2015-12-14
哈尔滨医药(2015年4期)2015-12-01
