
基于调度的P2P流媒体点播系统模型
2015-05-30 10:48:04陈园园朱欣颖
智能计算机与应用 2015年6期
陈园园 朱欣颖
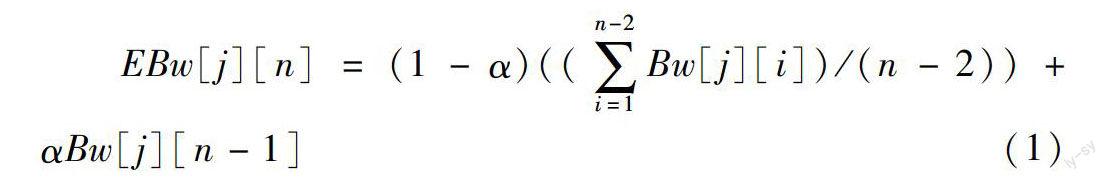

摘 要:在深入研究现有的P2P网络拓扑结构的基础上,构建了一个新的P2P流媒体点播系统模型,该系统模型包含跟踪服务器、资源服务器、超级节点和普通节点四个部分。它能快速定位到资源,减少路由查询次数,增加系统的扩展性、鲁棒性和数据吞吐量,能够很好的满足点播服务的要求。
关键词:P2P;流媒体点播;网络拓扑结构
中图分类号:TP393 文献标识码:A 文章编号:2095-2163(2015)06-
Abstract: In-depth study of existing P2P network topology, the paper constructs a new P2P streaming media on-demand system model, which includes four parts tracking server, resource servers, super nodes and ordinary nodes. It can quickly locate the resources, reduce routing queries, increase system scalability, robustness and data throughput, therefore can well meet the requirements of on-demand services.
Keywords: P2P; Streaming Media On-demand; Network Topology
0 引 言
近年來,随着P2P技术的发展,许多P2P流媒体点播系统进入了人们的生活,为广大的用户提供了丰富的媒体服务。然而,由于用户节点的动态性、节点性能的差异性以及用户操作的随意性,导致P2P流媒体点播系统无法保证用户获得高质量的流媒体点播服务。因此,为了提高P2P流媒体点播系统的服务质量和用户观感,设计一种新的P2P流媒体点播系统模型具有十分重要的意义。
1 数据调度问题的模型
1.1 节点可利用带宽的评估
在实际的系统中,某一个数据块会被多个对等节点拥有,那么选择哪个节点进行传输即是一个亟需解决的重要问题。在本文中,以节点的网络带宽为主要依据选择节点进行数据的传输,不同节点的带宽是不同的,同一节点在不同时期的带宽也是不同的,因此需要研发一特定算法去估计每个节点的带宽。
要评估一个节点的带宽,可以根据其历史带宽来进行识读估计。最先想到的方法是取其历史带宽记录的平均值作为下一个调度周期的估计带宽,具体方法是,通过记录这个节点最近 个周期的实际带宽,再把这 个带宽记录求和,由此获得平均值。但是使用这种方法估计下一个调度周期的网络带宽却不准确,因为可能出现如下情况,即 个周期的前几个周期,节点提供的网络带宽很大,而最近几个调度周期,相应的网络带宽却很小,那么如果用历史带宽记录平均值的方式做出的带宽估计肯定也很大,就会导致请求节点将继续向这个资源节点发出传输数据块请求,为此可能导致传输时间过长,甚至直接导致失败。
本文对上述的方式进行了改进,使用公式(1)来估计每个资源节点的带宽。在本算法中,记录了节点n-1个周期的实际带宽,调度周期 的估计带宽包括2部分,一部分是节点前n-2个周期的实际带宽平均后的加权值,另一部分是节点最近一次(n-1周期)网络带宽加权后的结果值。这种设计既考虑了节点的历史带宽,也顾及了节点最近一次的带宽。
其中, 表示资源节点 在第 个周期能够提供带宽的估计值, 表示资源节点 在第 个周期实际提供的带宽大小。而且,n是一个正整数,表示要估计的调度周期。n是一个常量(01.2 数据分片
在P2P点播系统中,一般的资源都是体积可观的,为了方便数据的调度,一个至关重要的操作就是如何对资源数据进行合理分片[1]。
为了能够实现合理的分片,需要讨论如下三个方面的因素:
(1)从数据调度的方面考虑,系统希望把资源文件分得越小越好,节点可以选择从不同的邻居节点调度某一片数据,这样就增加了数据调度的灵活性。
(2)从调度开销方面考虑,希望数据片的容量越大越好。主要的调度开销有:
每一片数据都需要一个头文件来描述其详情,包括数据片的序列号、时间戳等信息,因此数据片越大,头文件的开销就越小;
每一个对等节点都需要使其邻居节点知道该节点中缓存了哪些数据片,节点一般使用位图来表示这些信息,如果数据片分得过小,那么位图必然很长,并且位图还是所有开销中最大的;
数据片是从其它节点获取的,如此势必导致额外开销,如请求数据片信息等。
(3)从流媒体点播对数据实时性方面考虑,一般播放器多需要数据片在播放之前即已到达,而数据片在网络中传输经常是拆分成多个数据包,如果这个数据片过于庞大,就必然增加传输失败的概率,从而导致数据片将无法及时在播放之前到达。
综合考虑上述因素,本文采用先分块,再分片的方式。具体的方式是:先把资源文件分成大小相同的数据块(除文件的最后一块数据可能小于其它块的大小外),每一块的大小均为512KB,而后再把数据块分成64片,每一片数据的大小则为8KB(同样是除最后一块数据的最后一片数据大小外)。资源分片的原理示意图如1所示。
如果媒体资源文件的大小为 ,记最后一个独立数据块的大小为 ,而此后一个但愿数据片的大小记为 ,则其各自大小均可由下面的公式得到。
如上方式中,系统传输数据的时候以数据片为单位传输,而资源表示时以数据块为单位,这样既减小了系统的额外开销,又满足了数据调度的实时性要求,还增加了数据调度的灵活性。
1.3 缓存数据表示与交换
流媒体在点播的时候,需要缓存一定数量的数据块进行播放和提供给其它对等节点使用,本节将具体研究节点是如何标识缓存的数据块以及如何进行标识信息的交换。
在系统模型中,每一个完整的媒体文件都被分为同等大小的数据块,为了表示数据块的位置,利于数据调度,根据数据块的位置分配一个唯一序列号,从0开始分配。当节点需要点播某一部资源时,该节点就开始缓存数据内容,并通过维护一个位图BM来表示数据块的存在情况。
位图信息用来表示数据块的可用信息。一个位图由很多位组成,每一位代表对应序号的一块数据,位图的长度表示了点播资源文件所拥有的数据块数量。如果 表示节点缓存了数据块 ;反之, 就表示节点没有缓存数据块 。播放节点通过与邻居交换缓存位图,根据位图信息可以知道哪些节点拥有哪些数据块,作为自身数据调度的依据。另外,在交换位图时,每一个邻居节点还将自己的播放位置通知给相互交换位图的节点,而通过位图信息和播放位置,就可以预测哪些数据块也是其它节点需要的。
1.4 邻居节点的选择
在模型中,当用户点播某一部资源时,超级节点会选择某些个拥有这部资源的节点返回给点播用户。在选择这些节点的过程中,超级节点会考虑这些资源节点与点播节点的位置关系,优先返回位于点播节点同一或者附近区域位置的资源节点,如此即可减少网络传输延时,降低主干网的压力,提高服务质量。另外,本文提出的调度策略中,计算数据片的优先级时也考虑了位置因素。
2 P2P流媒体点播系统模型
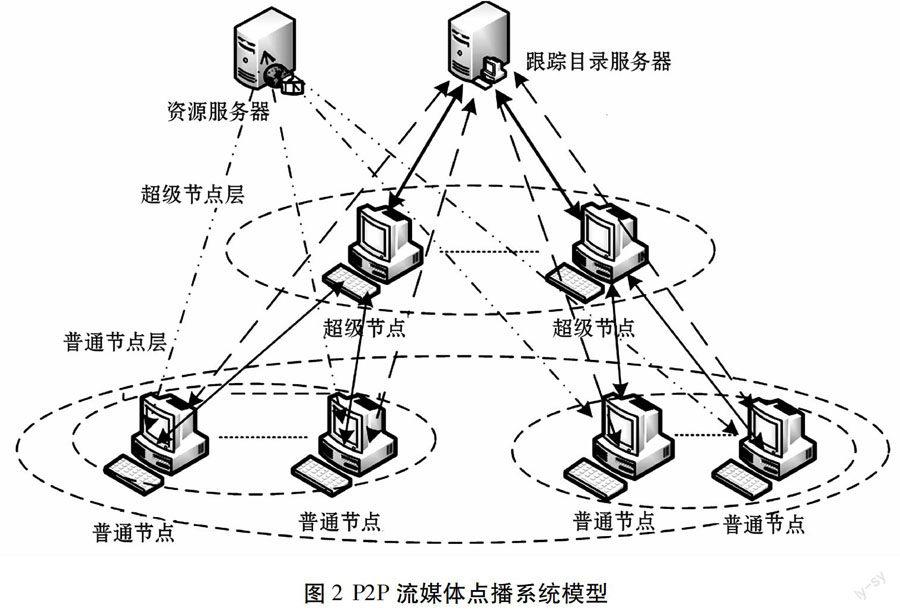
基于上述调度模型,通过研究现有的几种P2P网络拓扑结构及系统模型,本文设计了如图2所示的P2P流媒体点播系统模型。
从图2中可以看出,系统中包括跟踪服务器、资源服务器、超级节点和普通节点。这样的结构设计,主要是为了快速定位到资源,减少路由查询次数,增加网络中数据的吞吐量,同时系统的扩展性和鲁棒性,满足点播的服务质量。下面将详细介绍系统的每一个组成部分。
2.1 跟踪服务器
这个服务器保存着系统所有资源的目录信息,这些资源来自资源服务器和普通节点,普通用户可以根據给定的信息点播系统中的资源。服务器还管理着普通节点的加入、退出、资源点播和发布等操作,以及普通节点相关信息(包括IP地址、端口号、会话号)的实时记录,再根据不同的资源内容选择和管理超级节点。
2.2 资源服务器
这个服务器的主要作用是存储了系统中供用户点播的原始资源,如果系统中的节点要点播某一资源时,且其它节点都没有保存,此时节点就会从资源服务器上实现下载,并进行欣赏。
2.3 超级节点
超级节点拥有良好性能(包括计算处理能力、存储能力、网络带宽、I/O端口)和公共IP地址,而且表现出在线时间长的实际优势。超级节点不仅具备普通节点的所有功能,还进一步提供了管理资源分布信息的功能。普通节点在点播资源的同时把自己缓存资源的情况告知于超级节点,超级节点统计这些信息,供其它普通节点查询资源的分布信息,作为节点调度数据的重要基础。超级节点和普通节点还组成一个簇,形成一个逻辑子网,子网中的所有普通节点都成为邻居节点。
2.4 普通节点
普通节点可以点播网络中的资源进行欣赏,同时也为其它的普通节点提供资源,加速数据的传输,并且普通节点还可以向网络中的其它节点发布自己的整部资源,供其它普通节点选择使用。性能好且在线时间长,具有公共IP地址的普通节点可以被服务器选择升级为超级节点。
3 结束语
本文通过对影响P2P流媒体点播系统拓扑结构的分析,搭建了一个P2P流媒体点播系统模型,该系统模型包含跟踪服务器、资源服务器、超级节点和普通节点。系统能快速地定位资源,减少路由查询次数,增加系统的扩展性、鲁棒性和数据的吞吐量,较好地利用带宽资源,满足用户的点播服务要求。
参考文献:
[1] 赵惠.P2P流媒体点播系统的算法研究[D].成都:西华大学,2008.
[2] 管磊.P2P技术揭秘---P2P网络技术原理与典型系统开发[M].北京:清华大学出版社,2011:89-103.
[3] 石志磊.流媒体技术及其系统设计与实现[D].北京:北京邮电大学,2011.
