
农产品供需对接系统中主题网络爬虫的设计与实现
2015-05-15 10:22李慧胡辉庄冬梅
现代计算机 2015年4期
李慧,胡辉,庄冬梅
(惠州学院计算机科学系,惠州 516007)
农产品供需对接系统中主题网络爬虫的设计与实现
李慧,胡辉,庄冬梅
(惠州学院计算机科学系,惠州 516007)
介绍主题网络爬虫的工作原理,结合其功能,提出农产品供需对接系统中主题网络爬虫的设计模块,并对各个模块的设计及功能进行分析,对该系统的主题网络爬虫进行具体实现。当该系统的有效帖子数量低于某个阈值时,主题网络爬虫可以从其他同类网站抓取相关的信息,并建立索引,使该系统能更好地向用户进行推荐,让用户获得有用的信息。
农产品供需对接系统;主题网络爬虫;信息采集
0 引言
农产品供需对接系统是一款专门针对农民和农产品设计开发的系统平台,与其他在线交易平台不同的是,该系统能实现供需关系的自动连接,以及对供需用户的推荐功能,让需要卖商品的用户找到对应的卖家信息,需要买商品的用户获得供应信息。该系统主要分三部分实现:用户以及管理者与数据库的交互、数据库与索引器的交互、网络爬虫与数据库的交互。在网络爬虫与数据库交互的实现过程中,本文针对农产品供需对接系统的特点,结合网络爬虫工作原理,设计出适合该系统的主题网络爬虫。当该系统的有效帖子数量低于某个阈值时,主题网络爬虫可以从其他同类网站抓取相关的信息,并建立索引,使该系统能更好地向用户进行推荐,让用户获得有用的信息。
1 主题网络爬虫工作原理
1999年Chakrabarti首先提出主题网络爬虫这个概念[1],随着人们对信息搜索需求的增加,以及主题网络爬虫在信息采集和数据挖掘方面的突出优势,使得越来越多的人来研究主题网络爬虫[2]。主题网络爬虫是基于HTTP协议自动获取和主题相关网页的应用程序,该程序启动前,先要确定爬取的主题内容,启动程序后,对爬取到的网页内容进行分析,如果该网页内容与已设定的主题内容相关就进行爬取,否则就丢弃该网页。
主题网络爬虫与通用网络爬虫不一样,它在爬取网页时,并不是爬取所有网页,而是针对设定好的主题对网页内容进行有选择地爬取,这样不仅降低信息采集的难度,而且还提高了网页的质量。
主题网络爬虫程序具体工作流程如图1所示。首先从初始化种子网页开始,通过这个网页的链接去获取其他页面,提取其中的链接插入到URL队列中进行分析,同时分析网页文本信息,根据主题相关性计算出要访问的页面内容和主题的相关度,得出的结果与设定阈值相比较,小于阈值则丢弃,大于阈值则继续爬取,并将符合条件的网页存储到网页库中[3]。
2 主题网络爬虫模块设计
主题网络爬虫是农产品供需对接系统的重要部分,它可以高效、快捷地爬取农产品供需信息,方便系统快速推荐给用户,其结构设计如图2所示。
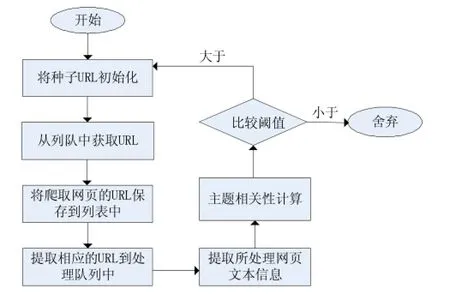
图1 主题网络爬虫流程图
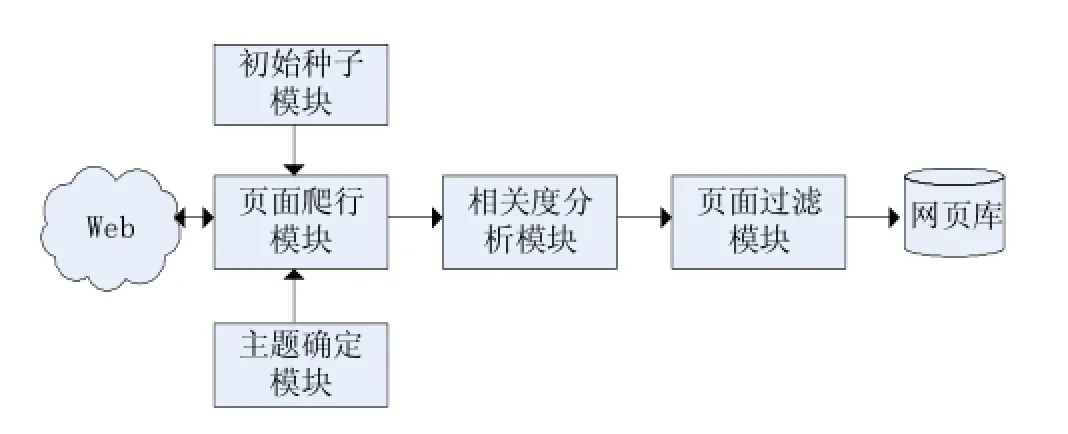
图2 主题网络爬虫模块结构图
2.1 初始种子模块
主题网络爬虫是根据某一特定主题进行网页自动爬取的程序,所以在初始种子模块中,要选择与设定主题内容一致的网页作为初始页面,以该网页的URL作为页面爬行模块的入口地址,这样可以提高爬取网页的准确性。例如,符合该系统选择的主题是农产品供需信息,那么初始种子就选择农产品交易网站首页。
2.2 主题确定模块
主题网络爬虫模块结构中,主题确定模块是工作基础,因为程序启动后,爬取的网页是与主题密切相关的。
该模块首先统计初始种子网页的关键词,通过人工设置给各关键词赋予相应的权值,用来确定主题。然后,根据这些权值搜索出与之相应的网页[4]。最后,把符合要求的网页组成网页集合,由机器进行再次提取,这样爬取出的网页与主题内容更加吻合,准确性更高。
2.3 相关度分析模块
主题网络爬虫模块结构中,相关度分析模块是最主要的模块。该模块把网页的主题相关度作为筛选页面的一个重要的衡量标准,利用爬虫程序处理掉不相关的网页,避免进行无用爬取,降低准确率[5]。该模块在进行分析前,先要设定一个阈值,再把爬取到的网页进行相关度分析计算,然后把计算出的结果与已设定的阈值进行比较,如果结果值大于阈值,表示爬取的网页与主题相关,如果结果值小于阈值,表示爬取的网页与主题无关[6]。
2.4 页面过滤模块
爬取的网页经过相关度计算后,进入页面过滤模块进行过滤。主题相关度大于阈值的网页就会被保存到网页库中,小于阈值的网页被丢弃,使得网页库有足够的存储空间存放与主题相关度较高的网页[7]。
3 主题网络爬虫的具体实现
农产品供需对接系统中主题网络爬虫爬取网页的流程图如图3所示。
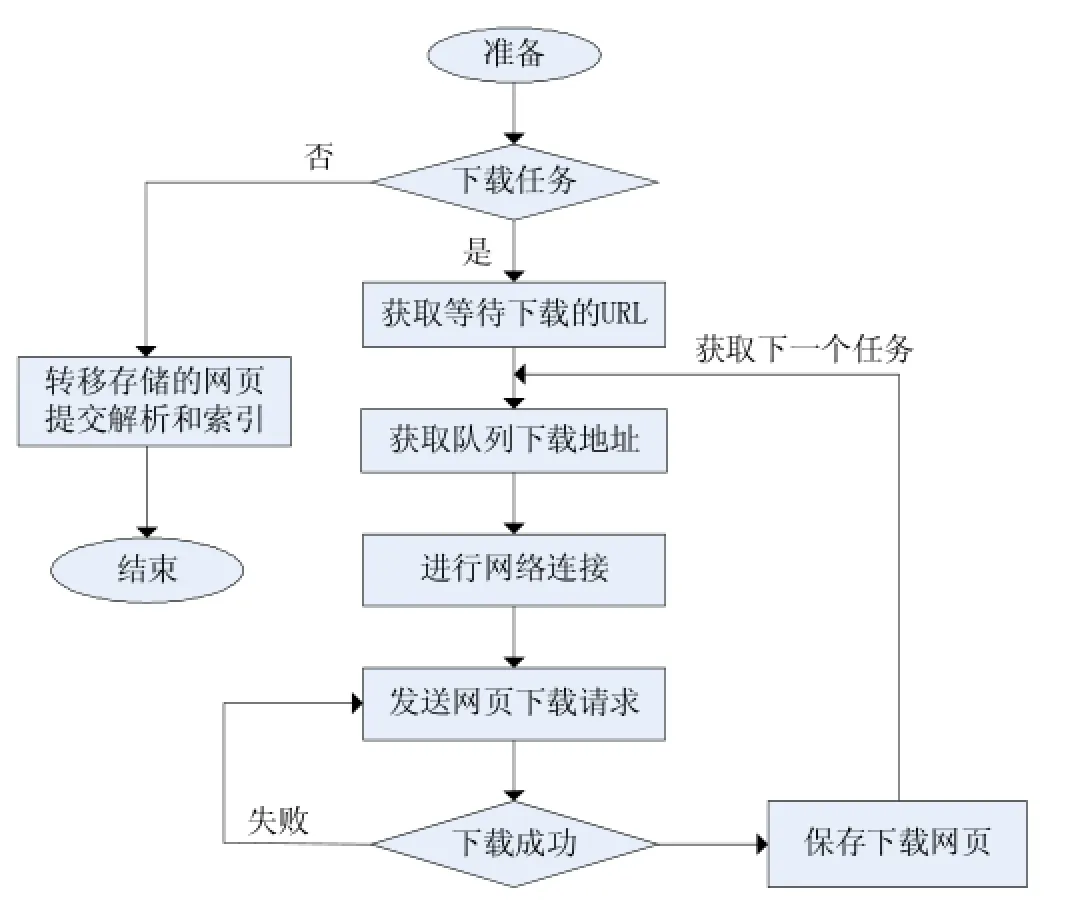
图3 爬取网页流程图
该系统中的主题网络爬虫采用宽度优先的方法,网页抓取过程从一系列的种子节点开始,把这些网页中的“子节点”(超链接)提取出来,放入队列中依次顺序进行抓取,被处理过的链接需要放入一个表内(通常为visited表)。每次新处理一个链接之前,需要查看这个链接是否已经在了这个visited表内,如果存在,则证明链接已经处理过,跳过不做处理,否则进行下一步处理。
对不同的网页,要抽取其中的有用的信息,需要编写特定的内容抽取器,如图4所示。抽取正文在网络爬虫程序中具有重要意义,如果不能很好地提取文章网页的有效内容,那么抓下来的网页就根本没有利用价值。抽取的方法有很多种,如配置模板、视觉匹配、关键字识别等。在本系统中,由于是定向抓取几个网站的信息,因此采用了基于配置模板的内容解析方法,为每个网站配置一个模板来抽取其中的供给和需求信息,然后写入数据库,再由索引器构建索引。
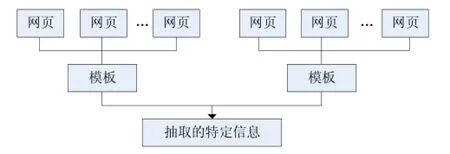
图4 抽取器抽取网页特定信息示意图
图5为中国农产品交易网的一个供应信息,该网页的URL和框出的部分是主题网络爬虫要抽取的内容,然后包装成一条记录,插入到数据库中,由索引器构建索引。解析HTML文档的工作量相当大,本系统采用JTidy解析器。JTidy是由Andy Quick编写的Tidy解析器的Java版本,能较好地解决本系统HTML提取问题。
图5 供应信息
4 结语
本文结合农产品供需对接系统中对主题网络爬虫的功能需求,提出设计模块,并指出在整个主题网络爬虫设计中最关键的部分是计算网页文本与主题的相关度。最后对该系统的主题网络爬虫进行具体实现,反映效果良好,可为同类应用提供借鉴。
[1] Chakrabarti S,Van den Berg M,Dom B.Focused Crawling:a New Approach to Topic-Specific Web Resource Discovery[J].Computer Networks,1999,31(11):1623~1640
[2] 王贤明.主题爬出研究进展[J].现代计算机,2014(1):33~36
[3] 魏晶晶,杨定达,廖祥文.基于网页内容相似度改进算法的主题网络爬虫[J].计算机与现代化,2011(9):1~4
[4] 林子皓.主题爬虫的设计与实现[J].计算机技术与发展,2014(8):99~102,107
[5] 邓岳贵.启发式搜索在网络爬虫中应用的分析[J].软件导报,2008,7(2):80~82
[6] 方星星,鲁磊纪,徐洋等.网络舆情监控系统中主题网络爬虫的研究与实现[J].舰船电子工程,2014(9):104~107
[7] 史宝明,贺元香,吴崇正等.主题搜索引擎中爬虫搜索策略的研究[J].计算机工程与应用,2014(9):116~128
Design and Implementation of Topic Crawler in the Agricultural Products Supply System
LI Hui,HU Hui,ZHUANG Dong-mei
(Computer Science Department,Huizhou University,Huizhou 516007)
Introduces the working principle of topic crawler and with the function of it,puts forward the design of topic crawler in the agricultural product supply and demand docking system module and analyzes the design and function of each module.Achieves the concrete implementation of the topic Web crawler in the system.When the number of effective post topic in the system is below to a certain threshold, Web crawler can crawl other similar sites and fetch relevant information and establish index at the aim of making the system better recommended to the user and allowing the user obtain useful information.
Agricultural Products Supply System;Topic Crawler;Information Collection
1007-1423(2015)04-0062-04
10.3969/j.issn.1007-1423.2015.04.017
李慧(1978-),女,浙江台州人,硕士研究生,讲师,研究方向为计算机应用、信息安全
胡辉(1979-),女,江苏盐城人,硕士研究生,讲师,研究方向为计算机应用、计算机软件
2014-12-23
2015-01-07
2013年惠州市科技计划项目(No.2013w12、No.2013w20、No.2013w22)、2012年惠州学院校级项目(No.2012QN10)
庄冬梅(1977-),女,江西吉安人,本科,工程师,研究方向为计算机应用与网络技术
猜你喜欢
房地产导刊(2022年10期)2022-10-18
煤气与热力(2021年11期)2021-12-21
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
今日农业(2020年20期)2020-12-15
中国外汇(2019年9期)2019-07-13
中国化肥信息(2019年5期)2019-06-25
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2018年2期)2018-04-18
