
用BP神经网络实现中文文本分类
2015-04-29 06:04:46火善栋
计算机时代 2015年11期
关键词:BP神经网络
火善栋
摘 要: 文本分类是文本挖掘的一个重要内容,在很多领域都有广泛的应用。为了实现中文文本分类问题,先采用分词技术和TF-IDF算法得到每一篇中文文档的特征向量,然后采用PB神经网络构造一个中文文本分类器。实验证明,采用BP神经网络进行中文文本分类时,虽然存在学习周期长,收敛速度慢等问题,但其分类速度和分类的正确率还是很高的。因此,采用BP神经网络进行中文分类是一个比较好的方法。
关键词: 中文文本分类; BP神经网络; 中文分词; 文档特征向量
中图分类号:TP391 文献标志码:A 文章编号:1006-8228(2015)11-58-04
Abstract: Text classification is an important part of text mining, and it has been widely used in many fields. In order to realize the Chinese text classification, the feature vector of each document is obtained by using the word segmentation technique and TF-IDF algorithm, and then a Chinese text classifier is constructed by BP neural network. Experiment results show that using BP neural network to Chinese text categorization, although there are problems such as a long learning period, slow convergence and so on, the classification speed and classification accuracy rate is quite high. Therefore, using BP neural network to classify Chinese is a good way.
Key words: Chinese text classification; BP neural network; Chinese word segmentation; document feature vector
0 引言
文本分类是指按照预先定义的主题类别,为文档集合中的每个文档确定一个类别,文本分类是文本挖掘的一个重要内容。目前,在国内已经对中文文本分类进行了广泛研究,并在信息检索、Web文档自动分类、数字图书馆、自动文摘、分类新闻组、文本过滤、单词语义辨析以及文档的组织和管理等多个领域得到了初步应用。
BP(Back Propagation)神经网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,BP神经网络在分类问题上有着非常广泛的应用,是目前应用最广泛的神经网络模型之一。BP神经网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。其学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。
研究文本自动分类的核心问题是如何构造分类函数(分类器),分类函数需要通过某种算法进行学习获得。现在比较流行的分类算法有Rocchio算法、朴素贝叶斯分类算法、K-近邻算法、决策树算法、神经网络算法和支持向量机算法等,这些算法各有千秋。当然,这些分类算法同样适用于中文文本分类算法。出于对中文文本分类算法的兴趣,本文采用PB神经网络算法完整地实现了中文文本的分类。实验证明,采用该算法进行中文文本分类时,虽然存在学习周期长,收敛速度慢等问题,但其分类结果具有分类速度快、分类正确率高等特点。
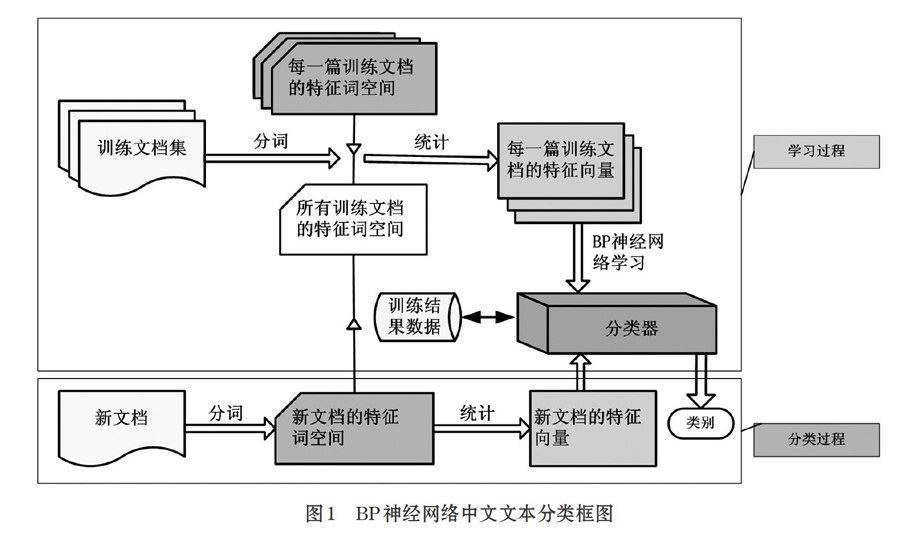
用BP神经网络实现中文文本分类,其过程如图1所示。该方法主要包括学习和分类两大部分,所涉及到的主要技术包括中文词典构建和查找算法、中文文档分词算法、TFIDF特征向量权值计算算法和BP神经网络算法。
1 采用BP神经网络构建中文文本分类器
1.1 分词和去掉停用词
采用最大逆向分词算法对训练文档集中的每一个文档进行分词,并根据停用词表去掉一些常用的停用词,通过分词得到所有训练文档集的特征词表Dt(每个特征词条都不相同)和每个文档的特征词空间Dk(每个特征词可以有多个,k为文档编号);
1.2 得到BP神经网络的训练集(神经元网络的输入向量和对应的输出向量)
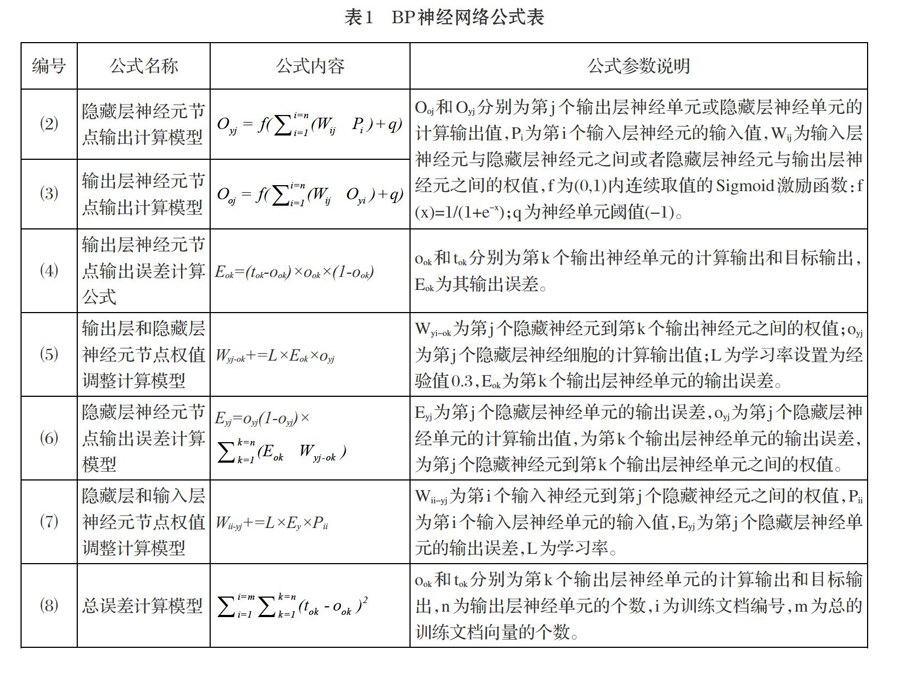
根据1.1中的特征词表Dt和每篇文档的特征词空间Dk得到每一篇文档的文档特征向量Vk(vk1,vk2,vk3,…,vkn)。该特征向量是一个二维空间向量,k为文档编号,n为所有训练文档特征词的个数。特征向量中的每一个分量vki的值用其所对应的特征词在该文档中出现的次数(词项频率tf[3])和所有训练集文档中包含该特征词的文档数(文档频率df[3])来得到,其计算公式为tf*itf,其中itf为逆文档频率,由公式itf=log(N/df)计算得出,公式中N为训练文档的总篇数;tf采用公式⑴计算得到:
其中的log都是以10为底的对数。
当得到每一个中文文档的特征词向量时,再根据该文档的类型得到其相应的输出向量Ok(ok1,ok2,ok3……okn)该输出向量也是一个二维空间向量,k为训练文档编号、n为训练文档的类别数,该二维向量将对应类别的输出分量设置为1,其余的分量设置为0。
1.3 训练BP神经网络
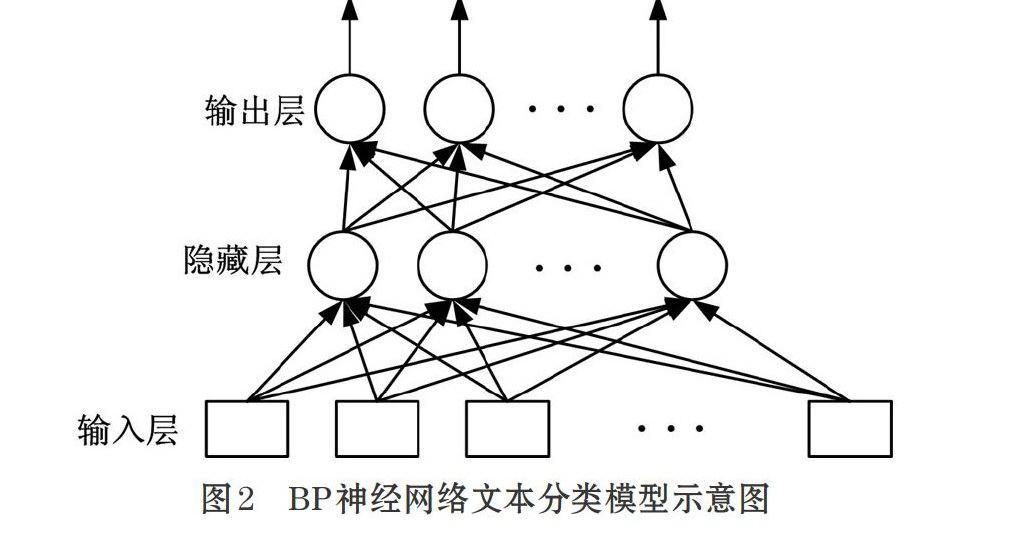
采用BP神经网络[1]构建文本分类的神经网络模型如图2所示。该神经网络模型包括三层:一个输入层,其神经元的个数和训练文档特征向量分量的个数相同;一个输出层,其神经元的个数与训练文档的类别数相同;一个隐藏层,其神经元的个数根据经验和实验进行选定。
2 BP神经网络中文文本分类测试
BP神经网络技术参数:隐藏层神经单元的个数为10个(经验值),输出层神经单元的个数为训练文本的种类个数9,输入层神经单元的个数为训练文档向量的长度59898,学习率为0.3(经验值),神经网络神经单元之间的权值为小于0.00001的正的随机数(本实验发现,当权值比较大时,其学习的效率非常低,收敛速度非常慢)。
本文选用1744篇共9类(如表2)已分类中文文档对已经构建好的BP神经网络进行训练学习。
测试采用了JAVA。实验电脑的基本配置为AMD 4核,内存大小为4G;JAVA虚拟机内存大小为1G。在实验过程中发现,采用BP神经网络构建中文文本分类器,训练周期比较漫长,而且占用内存比较大,所以很难对神经网络的各个参数进行适当的调整。另外,随着迭代次数的增加,其收敛性速度变得非常缓慢,有时还会出现一些小小的波动。所以本实验只是将输出误差作为结束训练的一个参考,而是将迭代次数作为最后的训练结果。图4是累计迭代次数为5000次,迭代时间为22小时32分,输出误差为11.143444的输出结果示意图。
采用上述训练所得的数据,对166个中文文档(不同于训练文档)进行了分类测试,其总的分类时间为45秒,平均正确率为95.5%,分类结果如表3。
3 结束语
从本文给出的实验数据可以看出,由于没有采用相关的降维技术对文档的特征词进行进一步的筛选,所以训练文档向量的长度比较大(59898),这也导致在BP神经网络的学习阶段,训练周期比较长,占用内存比较大,从而很难采用适当的输出误差来结束训练过程,但是,可以采用迭代次数来结束训练过程。当选用适当的迭代次数时,采用该分类器进行中文文本分类时,该分类器具有分类速度快,分类正确率高的特点,因此,采用BP神经网络实现中文文本分类是一个比较好的方法。为了进一步提高BP神经网络的学习效率和分类结果的正确率,下一步的主要工作是:①优化分词算法;②优化特征向量的提取和降低特征向量的长度;③对BP神经网络进行改善和优化。
参考文献(References):
[1] [美]Mat Buckland著,吴祖增,沙鹰翻译.游戏编程中的人工智
能技术[M].清华大学出版社,2006.
[2] [美]George E Luger著,郭茂祖等翻译.人工智能复杂问题求
解的结果和策略(第一版)[J].机械工业出版社,2010.
[3] [美]Christopher D. Manning Prabhakar Raghavan,[德]Hinrich
Schütze著,王斌译.信息检索导论(第一版)[M].人民邮电出版社,2010.
[4] 高一凡著.《数据结构》算法实现及其解析[M].西安电子科技
大学出版社,2002.
[5] 程杰著.大话数据结构[M].清华大学出版社,2011.
[6] 叶核亚著.Java程序设计实用教程(第二版)[M].电子工业出版
社,2014.
猜你喜欢
商情(2016年43期)2016-12-23 14:23:13
软件导刊(2016年11期)2016-12-22 22:01:20
软件导刊(2016年11期)2016-12-22 21:53:59
电子技术与软件工程(2016年20期)2016-12-21 10:42:59
科技视界(2016年26期)2016-12-17 17:57:49
考试周刊(2016年21期)2016-12-16 11:02:03
现代经济信息(2016年27期)2016-12-16 01:26:55
价值工程(2016年30期)2016-11-24 13:17:31
商情(2016年39期)2016-11-21 09:30:36
数字技术与应用(2016年9期)2016-11-09 22:37:01
