
拓展的LCS算法展开的网页关键词挖掘研究*
2015-04-28 03:59徐国华
湘潭大学自然科学学报 2015年1期
徐国华
(太原大学 计算机中心,山西 太原 030032)
拓展的LCS算法展开的网页关键词挖掘研究*
徐国华*
(太原大学 计算机中心,山西 太原 030032)
以经典的LCS算法为基础,通过对其进行分析,确定其不足之处,从而对其进行适度拓展,使其协同运算能力得到提升.在此基础上,利用拓展的LCS算法对网页关键词快速挖掘展开分析,通过具体实例确定其有效性.
LCS;拓展;网页;关键词;挖掘
网页信息的挖掘在互联网时代的重要性越来越重要,实现网页信息挖掘的快速、高效仍然是目前需要很好解决的一大问题[1~4].本文利用LCS算法,尝试进行网页关键词的挖掘研究.对LCS算法进行了拓展,以此对网页关键词快速挖掘展开具体分析,通过具体实例确定其有效性.
1 LCS算法论述与问题描述
1.1 LCS算法论述
LCS是英文单词Longest Common Subsequence的缩写,其意是指最长的公共子序列.举例而言,对于两个序列x1x2…xi…xn和y1y2…yj…ym而言,如果存在序列z1z2…zl…zq,使得序列z1z2…zl…zq中的每一个元素zl不仅包含在序列x1x2…xi…xn中,而且还包含在序列y1y2…yj…ym中.另外,不仅有z1=xi1,z2=xi2,…,zl=xi,l,…,zq=xi,q成立,还有z1=yj1,z2=yj2,…,zl=yj,l,…,zq=yj,q成立(其中,xis∈x1x2…xi…xn,yjt∈y1y2…yj…ym),则称序列z1z2…zl…zq为序列x1x2…xi…xn和y1y2…yj…ym的公共子序列.如果不存在长度超过序列z1z2…zl…zq长度的序列,则称序列z1z2…zl…zq为序列x1x2…xi…xn和y1y2…yj…ym的最长公共子序列,即我们所说的LCS.
1.2 研究问题描述
本文的主要问题是如何利用LCS的特性进行网页关键词的挖掘.具体说来,就是在不同的网页内容中寻找到最适合其特色的关键词.对于该问题,我们可以将其转换为两个字符序列的最长公共子序列问题,即LCS问题.以字符序列w1w2…wi…wn代表长度为n的网页内容,以字符序列k1k2…kl…kv代表长度为n的备选关键词.如果字符序列k1k2…kl…kv为字符序列w1w2…wi…wn的真正关键词,那么字符序列k1k2…kl…kv必为字符序列w1w2…wi…wn的LCS.同时,字符序列k1k2…kl…kv在字符序列w1w2…wi…wn中重复的次数必须达到阀值要求.通过此方法就可将一个备选关键词最终确定为真正的关键词.
下面,我们就采用LCS相关原理来进行网页关键词的挖掘工作.
2 LCS算法的拓展及其在网页关键词挖掘中的具体应用
2.1 LCS算法的拓展
在1.1中我们对LCS算法进行了论述,对于该算法的具体实现以及对应的优缺点还缺乏认识,现在我们就此问题进行研究,并针对其不足给予改进或者说是拓展.
LCS算法的传统实现方法是采用矩阵分析[5,6]的方法实现,以序列x1x2…xi…xn和y1y2…yj…ym为例.我们将其对应到一个n×m矩阵An×m,每一列按照自左至右的顺序依次对应字符x1,…,xi,…,xn,每一行按照自上向下的顺序依次对应字符y1,…,yj,…,ym.其具体对应形式如下:
x1x2……xn
(1)
当字符y1与字符x1一致时,对应的矩阵元素a(1,1)取值为1;同理,由于字符y2与字符x2一致,对应的矩阵元素a(2,2)取值为1,由于字符y2与字符x1不一致,对应的矩阵元素a(2,1)取值为0.这样我们只需判断矩阵对角线上全部为1的序列,其就为LCS的备选序列.对于n×n矩阵Bn×n而言,要将其转换为仅仅包含数值0与数值1的矩阵,一共需要n×n次运算;随后在每一条对角线上进行备选LCS挑选,最多需要进行2×n×(n+1)/2次判断,即可确定整个对角线上的备选LCS是否为真正的LCS.总体而言,需要O(2n2)次运算,就可得到每一个备选LCS的重复次数.该方法的最大优点在于将LCS变为可实现,缺点在于随着字符数量的激增,运算复杂度急速上升.如何有效地降低该算法的运算复杂度,或者说是否存在并行运算的方法来降低该算法的复杂度,就成为互联网信息急速增长的大环境下的迫切问题.针对该问题,我们尝试对其进行拓展,具体思路如下.
对于序列x1x2…xi…xn和y1y2…yj…yn而言,我们将其对应到一个n×n矩阵Cn×n,每一列按照自左至右的顺序依次对应字符x1,…,xi,…xn,每一行按照自上向下的顺序依次对应字符y1,…,yj,…,yn.其具体对应形式如下:
x1x2……xn
(2)
矩阵Cn×n中的各元素的取值方法与前述一致,不再赘述.此时,我们如果将矩阵Cn×n进行二维空间的二等分,就得到了四个维数相同的子矩阵,其构成如下:
(3)
其中C1,1、C1,2、C2,1、C2,2均为(n/2)×(n/2)矩阵.
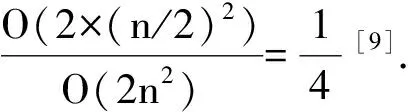
(4)
其中D1,1、D1,2、D1,3、D2,1、D2,2、D2,3、D3,1、D3,2、D3,3均为(n/3)×(n/3)矩阵.
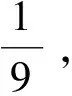
通过上述论证分析,我们明确了LCS算法的实现以及其优势与不足.在此基础上,我们采用信息学相关理论对其进行了拓展,使其运算复杂度得到了分担,具备了并行计算的基本条件.下面,我们就采用该拓展方法对网页关键词挖掘进行实证应用研究.
2.2 拓展的LCS算法在网页关键词挖掘中的具体应用
随着互联网规模的急速膨胀,以文字形式出现的互联网信息量也急速增加.如何针对这些网页信息进行有效的关键词确定,从而提高对网页信息的快速归类与检索就成为当务之急.下面我们就以一个具体实例展开分析.
在现有的互联网搜索引擎中,已经有基本能够覆盖所有信息的关键词信息,以序列{Keyi}p代表之.其中第i个关键词用Keyi表示,一共有p个关键词.当前需要确定关键词的网页的文本信息内容用序列c1c2…ci…ct表示,依照前面的方法进行矩阵转换.但是在转换之前,我们需要将离散的关键词序列转化为连续的关键词序列.具体的方法是在每一个关键词之后用特殊字符“#”作为拼接词将其连接.比如关键词“Econometric”和关键词“Math”用特殊字符“#” 拼接后就转变为关键词序列“Econometric#Math”.由此我们就可完成离散关键词的连续化操作.随后进行矩阵转换,得到下式:
c1c2……cn

(5)
其中变量ki代表通过关键词拼接后得到的第i个关键词;变量cj代表第i个网页内容信息.
考虑到当前网页内容长度与关键词序列长度,我们将矩阵进行适当的等分分解,分解为q×q个子矩阵.具体形式如下:
(6)
其中每一个子矩阵Gl,j,l∈[1,q],j∈[1,q]均为(n/q)×(n/q)矩阵.
对于上述矩阵(具体是指每一个子矩阵和母矩阵)进行如前所述的数值赋值和判断工作,并进行衔接工作.从而得到每一个关键词在网页内容中出现的次数,将此次数与之前设定的阀值进行比对,当次数超过阀值时,我们就将此备选关键词转化为针对当前网页内容的具体关键词;当次数低于阀值时,我们就将此备选关键词去除.通过此法,我们即可对复杂网页内容进行精确和快速的分类,并以分类结果对外搜索时的关键词进行搜索判定.这一方面提高了对随时产生的网页内容的快速归类,另一方面,又为网页信息的对外展示提供了关键的、准确的、可靠的决策依据.
3 结 语
本文首先对LCS算法进行了拓展,确定了其优势以及不足.并针对发现的不足,通过与信息技术相结合,确定了对其进行拓展的思路与方法.通过理论证明,不仅拓展了LCS算法,而且验证了拓展算法的有效性与协同处理性能.随后,在此基础上,针对网页信息的特征展开实证分析,确定了复杂网页的关键词挖掘方法与实现过程.
[1] 岳冬冬.一种测度数据序列同步波动强度的方法及应用[J].统计与决策,2012(22):31-35.
[2] 王克富.基于数据挖掘技术的AFH客户分类应用研究[J].技术经济与管理研究,2012(11):13-17.
[3] 孙娜,郭延锋.基于增量式学习的数据流实时分类模型[J].计算机工程与设计,2012(11):17-22.
[4] 郭建,赵显.一种基于图像处理的快速自动聚焦算法[J].湘潭大学自然科学学报,2012,34(02):22-25.
[5] EUGENIO C,DOMENICO T.Distributed data mining patterns and services: an architecture and experiments[J].Concurrency and Computation: Practice and Experience, 2012,24(15):1 751-1 774.
[6] ZHU X,MAHULE T, HAIMONTI D, et al.Peer-to-peer distributed text classifier learning in PADMINI[J].Statistical Analysis and Data Mining, 2012,5(5):446-462.
[7] CAO L.Actionable knowledge discovery and delivery[J].Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2012(2):149-163.
[8] KANISHKA B, KAMALIKA D, KIRK B,et al.Scalable, asynchronous, distributed eigen monitoring of astronomy data streams[J].Statistical Analysis and Data Mining, 2011,4(3):336-352.
[9] MIRKO B.Contrast and change mining[J].Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2011(3):215-230.
责任编辑:龙顺潮
Using the Extended Method of LCS to Solve the Keywords Data Mining for Webpage in Internet
XUGuo-hua*
(The Computer Center of Taiyuan University,Taiyuan 030032 China)
According to the rapid expansion of Internet information under the webpage key words determine the operational efficiency is low problem started the research. In classic LCS algorithm as the research breakthrough, through carries on the thorough analysis, identify its shortcomings, thus carries on the moderate expansion, the collaborative operation capacity upgrade. On this basis, using the extended LCS algorithm Corps webpage key words fast mining expansion concrete research, through the concrete example of the effectiveness of the method, and summarize the research results.
LCS; extended; webpage; keywords; data mining
2014-04-11
山西省教育科学十二五规划课题(GH-11139)
徐国华(1974— ),女,山西 忻州人,副教授.E-mail:bianji006@sina.com
TP393
A
1000-5900(2015)01-0107-04
猜你喜欢
成都信息工程大学学报(2021年6期)2021-02-12
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
数字通信世界(2019年3期)2019-04-19
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
