
结合PageRank算法的Lucene评分机制改进研究
2015-04-25 08:13:04张禹周翔
三明学院学报 2015年4期
张禹,周翔
(1.福建江夏学院 电子信息科学学院,福建 福州 350108;2.闽江学院 软件学院,福建 福州 350108)
21世纪以来,因特网上的Web数量不断增加,伴随着近年来Web2.0理念的诞生,未来的桌面应用可能有相当大的一部分将转移到Web平台上,再加上云计算等技术的不断完善,互联网上的数据挖掘已经凸显出十分明显的商业价值。搜索引擎自诞生以来就一直扮演着Web结构挖掘者的角色,在当前这样一个万维网高速的扩张的时代,网络用户为了获得准确的信息资源,已经根本离不开它。
现有的搜索引擎与其诞生之初相比,无论在搜索的召回率(recall,又称查全率)和精确度(pricision,又称查准率)方面都有了很大的进步[1]。当然,在部分搜索主题下,还存在着一些不完善的地方,例如:用户在使用搜索引擎进行搜索的过程中找到的并不完全是预期的结果,经常会包含一些无关的页面链接。更为严重的是,有时候这些数据还可能出现在返回的页面链接列表的前端。这是搜索引擎开发者所不希望看到的[2]。如何有效地排除无关噪声数据,获得尽可能准确的信息,一直是搜索引擎开发者的努力方向,而解决问题的有效途径就是通过Web挖掘技术。
1 PageRank算法
Web挖掘技术分为:内容挖掘、使用挖掘与结构挖掘[3]。Web内容挖掘包括文本数据挖掘、多媒体数据挖掘;Web使用挖掘包括用户访问模式(习惯)分析与网站定制分析两类;Web结构挖掘包括网页超链接挖掘与页面内在结构挖掘[4]。现有的全文搜索引擎的数据收集过程都是通过网络爬虫程序访问链接来实现的。基于该特点,使用Web结构挖掘技术更能有效地应用于搜索引擎中,提高其搜索精度。
在Web结构挖掘中,PageRank算法是其经典算法之一。该算法是Google搜索引擎最早用到的挖掘算法,其基本理念是利用该算法和文本链接标签,词频统计等因素相结合的方法对由搜索主题检索出的海量结果进行排序,根据PageRank值的大小来判别页面等级值高低,让重要程度更高的页面排在所有结果的前面[5]。
PageRank算法的思想基于以下几个假设条件:(1)某一页面被其他页面引用次数多,那么,该页面可能具备很高的重要程度;(2)某一页面虽然被其他页面引用的次数有限,但是如果引用它的页面中存在着已经被评价为重要等级的网页,则该页面也有可能是重要的;(3)任何一个页面的重要程度都是被平均地分配给它所引用的页面去;(4)如果用户一开始随机地访问Web集合中的一个页面Web1,之后以这个页面为基准随着页面上的链接向外或者向前浏览其他目标页面(过程中不后退),那么,用户点击超链接浏览下一个页面WebX的概率就被认为是页面WebX的PageRank值[6]。
PageRank算法的定义如下:假设u是一个Web页,F(u)是u指向的所有页面集合,B(u)是所有指向 u的页面集合,设 N(u)=|F(u)|是从 u发出的链接数 ,c(其值小于 1)是一个归一化因子(以Google为例,取的是 0.85),则 u的PageRank值的定义公式[7]如式(1):

PageRank算法的主要缺点是在于它的随机特性,其算法思想是基于用户以某个页面为起点访问该页面上所有链接的几率相等这一假设,因此一个页面的重要性被均匀分布并传递到它所引用的页面[8]。正因为重要性的平均分配而可能引起主题相关度高的页面与相关度低的页面被同等对待,即过分注重链接的出入度,从而在相当程度上导致主题偏移现象的出现。
2 Lucene框架
2.1 Lucene框架简介
Lucene是基于Java的开源框架[9],是著名的Apache Jakarta中的一个主要组成部分,而且具有Apache软件许可(ASF License)。此外,它还是一个高效率、功能完善的信息检索库[10]。利用Lucene框架,开发人员可以在其应用程序中部署强大的索引与搜索功能,如图1所示。
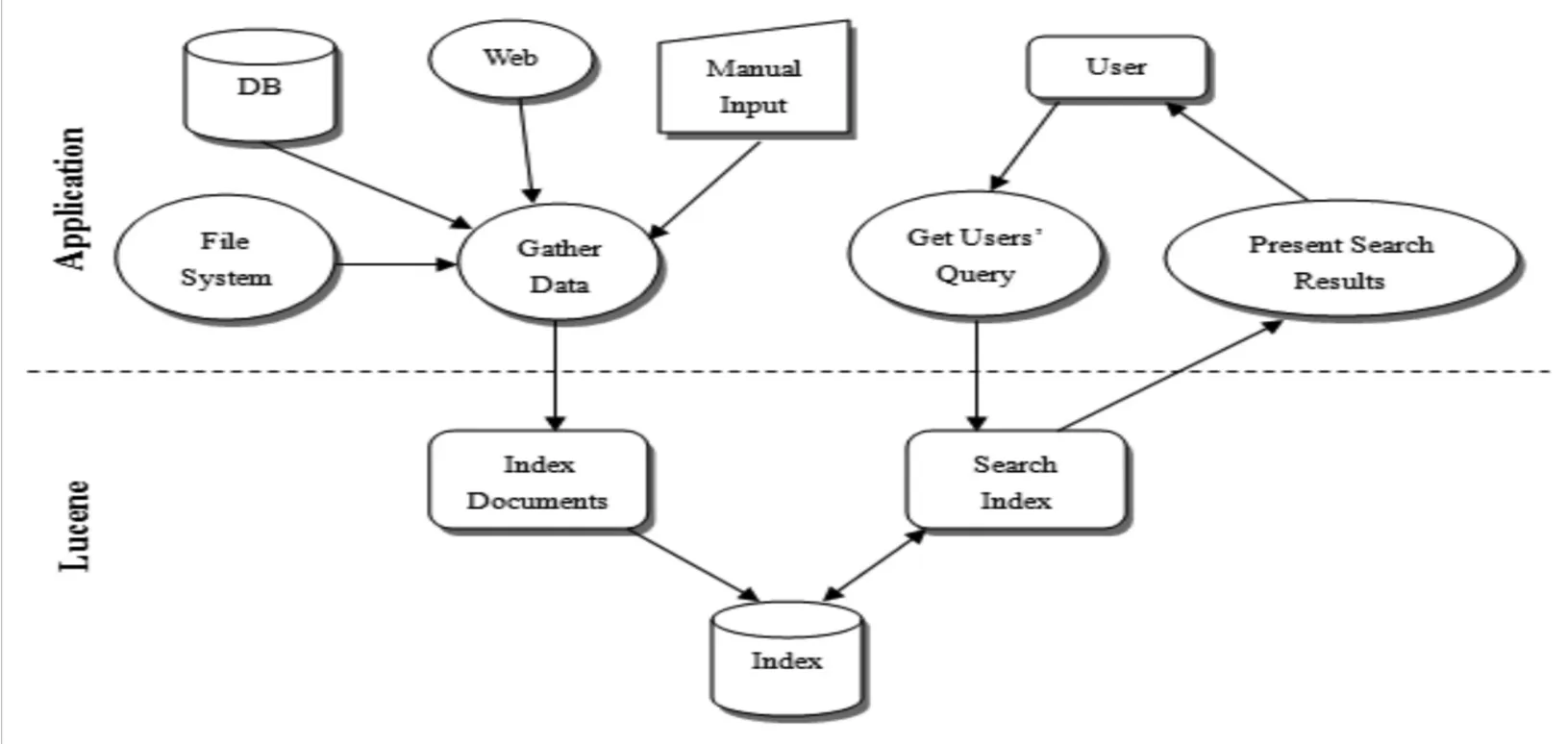
图1 搜索应用程序和Lucene之间的关系
2.2 Lucene框架下的页面评价机制
Lucene 对文档的评分公式[11]如式(2):

该公式中:d表示某一待评分的文档;q表示某一查询;score(q,d)就是反映文档d关于查询q的主题相关程度的权值;t指的是term(词),它是搜索的基本单位,构建该对象需要提供两个字符串类型的参数,第一个参数表示在当前的document中查找的field的位置,另一个参数则代表了要查询的关键词;coord(q,d)表示的是某一文档中所包含的与查询q相关的匹配关键词的个数,数量越大,则该文档所获得的分值越大;queryNorm(q)表示当前查询q的方差和,它的结果不影响当前查询结果的排序,只是进行归一化处理,用于对于当前查询语句中的各个词设置适合的权重,以体现当前查询的中心含义所在;getBoost()方法用于对不同的对象设置权值,表明其重要程度,其中t.getBoost()用于设置查询语句中每个词的权重;d.getBoost()用于在生成索引时设置某文档的权重;f.getBoost()用于在生成索引时设置域的权重。 queryNorm(q)公式[12]如式(3)。
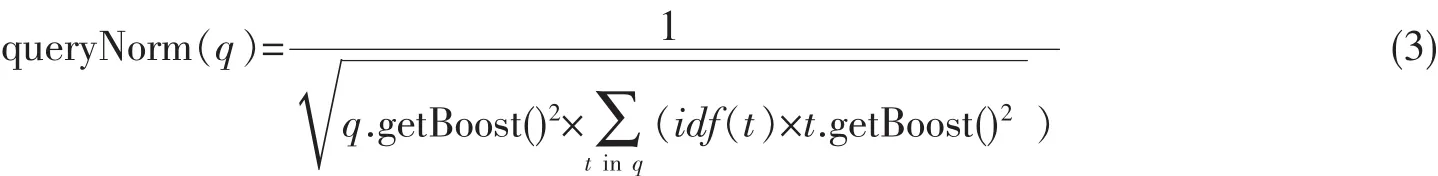
tf(t in d)表示词t在当前文档d中出现的频率 ,idf(t)用于表示词t在索引中各文档中出现的频率,norm(t,d)表示对于文档d的归一化,

式(4)中

它表示一个域中包含的Term总数越多,也即文档越长,此值越小,文档越短,此值越大,该项的设置主要是为了保证篇幅短的文档不会因为文档长度短的原因而使得其评分受影响,因为篇幅短的文档,其tf值一般情况下要比篇幅长的文档小,即查询词t在文章中的频率小,比如,“web”这个词在一篇1万个词的文档d1中出现10次,而在一篇100个词的文档d2中出现9次,而按照tf来衡量的话,必然对文档d2不公平,因而lengthNorm正是用一种反比的形式,来中和这种不公平现象[13]。
然而,如果进一步分析Lucene的评分机制,可以发现该机制过分注重页面与搜索主题的匹配程度,而忽略了页面本身的链接出入度,即有可能出现这样的情况:一个网页在某一搜索主题下,是非常重要的页面,由它发出的超链接,以及外部指向它的超链接数量很多,但是由于该页面中与搜索主题词的匹配数量有限,导致在Lucene的评分机制下,该页面反而不如链接出入度小,而与搜索主题词匹配数量大的页面,明显有失公平。
3 Lucene框架下结合PageRank的评分机制改进
通过对比可以发现,Lucene框架下的评分算法,刚好可以与PageRank算法形成有效互补,即PageRank算法过分关注于链接出入度为标志的页面权威度,忽略了搜索主题,产生主题漂移现象;Lucene的评分算法过分关注主题匹配,忽略了链接出入度。这里,可以考虑以Lucene评分机制为主体,结合PageRank算法,进行改进。
在第1节中已经描述过了PageRank的形式化公式,如式(1)所示。这里可将Lucene中评价页面的权值表示为 Score(u)引入式(1)并令

可得:

此公式即为结合PageRank算法的Lucene评分改进公式,其中c为归一化因子,取值为0.85,PL(u)即为页面u关于查询主题q的最后权值得分。
该权值的求解过程主要是通过将Lucene评分值加入到PageRank的迭代过程中去,并利用归一化因子c,得到最后收敛的PL值。这里每个网页的PR初值取为1。
4 校园网平台下的算法应用测试
4.1 应用测试平台构建
算法应用测试平台是一个以采用J2EE架构,结合Lucene开源程序包开发的校园网搜索引擎,测试数据来自于网络爬虫程序抓取的某高校校园网内的Web数据集。平台架构如图2所示。
4.2 基于PageRank算法的评分流程
该系统的评分流程图如图3所示。
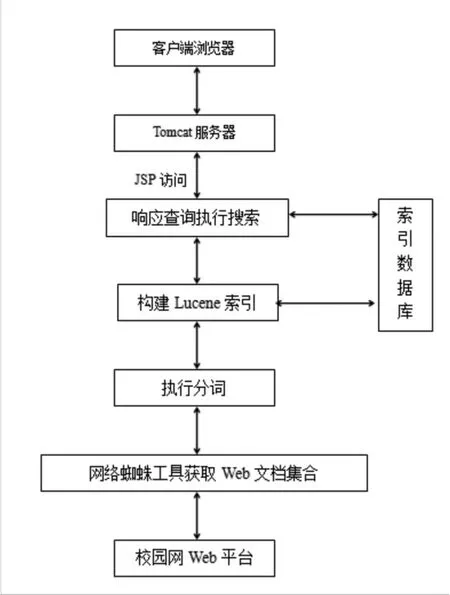
图2 校园网搜索平台架构

图3 系统评分流程图
4.3 测试结果与分析
实验选择了8个特征性比较明显的二级学院网站主页作为测试标记,将其名称上的特征词作为搜索主题。以学校内的二级学院——电子信息科学学院为例,其最明显的特征词是“电子”。在校园网内搜索 “电子”,同时考虑主题契合度与页面权威度,只要页面结构合理,最理想的搜索结果应该是电子信息科学学院的网站主页(其他二级学院的情况以此类推)。
选定测试标记后,通过系统运行产生Lucene评分机制下结合PageRank算法改进前后的两组实验测试结果,结果如表1~2所示。
测试均在校园网数据环境下进行。每一个搜索均能保证得到10个以上的搜索结果。在Lucene默认评分机制下,页面的评分值设为L,在8个标记网页中,能达到预期的只有3个(如表1所示)。分析其原因,在于Lucene过分注重内容的匹配,而未考虑页面的出入度。从5个未达预期的搜索结果来看,排名第一的页面都有一个共同特点,即这些页面中存在着大量的搜索主题词。像“奖学金名单公示”、“论文答辩安排”这类的页面中,包含每个学生的班级信息,这些班级信息里就包含了许多用户搜索的主题词,比如“电子信息工程1班”中的“电子”,“金融2班”中的“金融”等。因而在未考虑PageRank的网页出入度的情况下,所得到的结果是不理想的,未能体现出页面的重要性。

表1 结合PageRank算法前系统测试结果

表2 结合PageRank算法后系统测试结果
表2中体现的是结合了PageRank算法后的搜索结果,通过分别计算PR值和L值,利用式(7),得到最终的评分值PL。从各标记网页的排序上来看,搜索结果了有了很大改观,基本上达到了预期。二级学院的主页在结果排序中位列第一位的数量达到了6个,而剩余两个未达到第一的主页也排到了第二位,而且在权值上与第一位的网页差距也很微小,作具体分析如下:
(1)电子信息科学学院的主页在搜索结果中的排名从原来的第五上升到第二,但与排名第一的“奖学金名单公示”页面的主要差距还是在主题词匹配上,后者的Lucene评分值高出许多。因而,今后在算法改进上,可以进一步研究在式(6)中设置PageRank和Lucene评分的分值加权比例的问题,以避免此类问题的出现。
(2)金融学院的主页排名从第四上升到第二,明显看出PageRank算法在权威度评价中的作用。但是,通过分析排名第一的金融学院学生社团主页,该页面在未结合PageRank算法前,也未能列在结果的首位,同样是PageRank算法的受益者。通过分析页面的PR值可以发现,该页面的链接出入度也非常大,而且页面中的文字与搜索主题词“金融”切合得更紧密,也就是说,Lucene评分值仍然起到了很大的作用。从客观的基于数据的评判角度来看,这样的排名顺序是完全合理的,也是符合算法改进预期的。同时,这一结果也表明金融学院的网站主页的页面结构需要进一步进行搜索引擎优化(SEO)改进,以提高其有效权值。
5 结论
PageRank算法与Lucene评分机制之间在主题相关与页面出入度上,存在很大的互补特性。本文描述了一种结合PageRank算法的Lucene评分机制改进策略,并通过在校园网内利用Lucene搭建搜索引擎平台的方式来进行算法改进测试。从测试的结果上来看,基本达到了预期的目标,但与理想的结果仍然存在一定的偏差,后期还需在两种体系的分值权重设置上开展进一步的实际研究。
[1]HAN MIN,ZHANG XIANCHAO.Community identification based on a new approximate personalized page Rank algorithm[J].Advances in Information Sciences and Service Sciences,2012,20(4):649-657.
[2]WU HENGLIANG,ZHANG WEIWEI.An improved page ranking algorithm for web search engine[J].International Journal of Digital Content Technology and Its Applications,2012,13(6):38-44.
[3]黄德才,戚华春,钱能.基于主题相似度模型的 TS-PageRank 算法[J].小型微型计算机系统,2007(3):510-514.
[4]王冬,雷景生.一种基于 PageRank 的页面排序改进算法[J].微电子学与计算机,2009,26(4):210-213.
[5]谢月.网页排序中PageRank算法和HITS算法的研究[D].成都:电子科技大学,2012:18-25.
[6]平卫芳.Web数据挖掘中PageRank算法的研究与改进[D].上海:华东理工大学,2014.33-36.
[7]陈再良,凌力,周强.dPageRank——一种改进的分布式PageRank算法[J].计算机应用,2006,26(1):21-24,36.
[8]潘伟丰,李兵,马于涛,等.基于加权 PageRank 算法的关键包识别方法[J].电子学报,2014(11):2174-2183.
[9]管建和,甘剑峰.基于 Lucene全文检索引擎的应用研究与实现[J].计算机工程与设计,2007(2):489-491.
[10]李永春,丁华福.Lucene的全文检索的研究与应用[J].计算机技术与发展, 2010(2): 12-15.
[11]张晓滨,石美红,蔡桂洲.校园网搜索引擎设计[J].西安工程科技学院学报, 2002(3):243-246.
[12]高玉良.一种基于Lucene的文档检索系统的研究及应用[D].大连:大连交通大学,2012:39-43.
[13]樊同科,谢勇.一种混合搜索算法在智能 Web 中的应用[J].计算机技术与发展,2013(8):220-222,226.
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
甘肃教育(2020年18期)2020-10-28 09:05:54
电子制作(2019年10期)2019-06-17 11:45:26
电子制作(2017年8期)2017-06-05 09:36:15
中国卫生(2015年12期)2015-11-10 05:13:38
电子设计工程(2015年17期)2015-02-27 12:08:04
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06 07:49:12
技术经济与管理研究(2014年11期)2014-03-11 17:02:44
电脑爱好者(2011年11期)2011-06-22 08:20:18
河北软件职业技术学院学报(2010年3期)2010-06-06 07:18:42
