
一种基于云计算的高效数据挖掘框架研究
2015-04-21 02:38刘猛
微型电脑应用 2015年6期
刘猛
一种基于云计算的高效数据挖掘框架研究
刘猛
云计算可按软件即服务(SaaS)的形式提供数据挖掘的结果。数据挖掘的性能和质量是云计算环境下数据挖掘应用的重要使用标准。文中提出一种基于云计算的数据挖掘应用及其数据集的分布和调度框架,该框架实现了基于云计算的K均值聚类方法,并将其作为云软件即服务(SaaS)来提供给用户,其主要目标是降低应用的总体运行时间,将挖掘质量的损失最小化。仿真结果表明,相比于已有方案,其方案在速度获得显著提升的同时,挖掘质量损失最小。另外,当聚类数量和数据集的规模上升时,挖掘质量也具有良好的扩展性,可促进本文方案在云服务提供商中的应用。
云计算;数据挖掘;K均值聚类;总体运行时间
0 引言
云计算[1]作为一种新兴技术,使得人们对可配置的共享计算资源能随心所欲的访问,只需极少量的管理或服务提供商的交互,即可迅速供应和发布这些可配置共享资源。云计算包括3种服务模型:云软件即服务(SaaS),云平台即服务(PaaS),基础设施即服务(IaaS)。SaaS提供商为用户提供可以运行的应用,方便用户快速获得相关结果。PaaS提供商为用户应用的云部署提供条件。IaaS提供商为用户提供运行应用所需要的处理、存储和网络能力。
云计算是许多科学和工程应用的潜在高性能方案[2]。许多研究人员试图利用Hadoop[3]等分布式数据挖掘工具来提升数据挖掘应用的性能。然而,使用该工具来处理大数据中的数据挖掘应用的复杂度较高。一般而言,数据挖掘应用的用户只对数据的挖掘结果感兴趣,无需知道数据的挖掘地点和挖掘方式。此外,他们还关注应用的实时性和结果的准确性,即关注结果的质量。云计算通过服务水平协议(SLA)[4]可以提高服务的性能和水平。为此,本文提出一种基于云计算的分布式数据挖掘应用方案,并将其集成为云计算环境下的SaaS来提供给用户。
1 相关工作
云计算因其高灵活性和性价比,被广泛应用于分布式数据挖掘的基础设施,相继有众多研究者提出了一系列卓有成效的数据挖掘方法。如文献[5]提出并实现了一种基于Hadoop云计算平台的频繁闭项集的并行挖掘算法。该算法主要包括并行计数、构造全局频繁项表、并行挖掘局部频繁闭项集和并行筛选全局频繁闭项集四个步骤。在多个数据集上的实验表明,该方法能大幅提高数据挖掘的效率,具有较好的加速比。文献[6]针对目前搜索数据量大、搜索延迟的特点,提出了基于云计算Web挖掘的搜索模型。采用提出的基于Map/Reduce模型的改进型算法,在一定程度上减少了搜索的代价,提高了搜索效率。文献[7]提出了一种基于云计算的Web数据挖掘方法,该方法将海量数据和挖掘任务分解到多台服务器上并行处理。采用Hadoop开源平台,建立一个基于Apriori算法的并行关联规则挖掘算法来验证了该系统的高效性。
另外,随着分布式数据库的出现,分布式数据挖掘(DDM)在近年吸引了人们的眼球。文献[8]提出一种基于高性能云的分布式数据并行处理方法。使用一个专用的网络服务分层结构,适用于高性能广域网络连接的计算机集群所产生的大型分布式数据集的数据挖掘。实验结果表明,与Hadoop方法相比,该方法的性能有显著提高。文献[9]在基于不可信节点的云计算架构基础之上提出了一种新型的分布式数据挖掘模式,实现分布式数据挖掘无缝接入云计算系统,以满足物联网的需求。总的来说,上述方案大多还存在着以下不足:1)不能实现对云基础设施的实时监测,不能根据系统负载自适应地分配数据挖掘任务到云端,使得系统的负载失衡,在造成资源浪费的同时,也降低了数据挖掘的质量;2)可扩展性差,当对大数据进行挖掘时,挖掘质量较差、且延迟高。针对这些不足,本文主要研究基于云计算的聚类策略用于数据挖掘任务。目前有多种聚类技术,比如K均值聚类、分层聚类和基于密度的聚类等[10]。这些方法各有优缺点。鉴于K均值法的普及性,本文以K均值聚类为基础,提出一种基于云计算的K均值算法作为SaaS模式,并通过仿真实验验证了本文方案的有效性。
2 K均值聚类
为了便于描述,下面先对K均值聚类进行阐述。K均值聚类只根据可用信息(数据点的相似度/离散度)生成数据点的K个分区。目标是使每个数据点与其对应聚类质心间离散度之和最小化(即类内离散度)。设有m个未标识数据点χ={x1,x2,...,xm},K均值法生成χ的K个分区,且使如下目标函数最小,如公式(1):

其中ui表示聚类i的质心,表示x和ui间的欧氏距离。K均值聚类主要包括如下3个步骤:
1)初始化:采取某种启发式策略或随机选择K个初始质心(即聚类中心)。
2)聚类分配:每个数据点分配给与其最近质心相对应的聚类。
3)质心再计算:利用第2步中分配的数据点再次计算每个聚类的质心。然后,回到第2步。
上述迭代过程一直持续至满足某个终止条件为止(比如两次迭代期间均无数据点的聚类发生变更,或者达到最大迭代次数)。
3 基于云计算的数据挖掘总体框架
云计算环境下的数据挖掘总体框架如图所示:

图1 云计算环境的数据挖掘总体框架
在图1中,一个云包括可被本文框架使用的多个物理聚类。为了分发大数据,需要一个主工作站、多个与主工作站相连的计算工作站。主工作站和计算工作站间的链路速度表示数据传输时的通信处理速度。总体框架由如下组件构成:
1)主工作站:可以处理云中集中式数据的节点,调度决策也发生于该节点中。主工作站是主节点上负责分发数据的计算实体。
2)计算工作站:可进行本地数据挖掘的数据单元称为计算工作站。本文假设每个计算工作站可以访问足够多的存储空间以便存储分配给它的数据量。
3)资源管理器:通过与资源记录器的数据库进行沟通来检查资源可用性的实体。为K均值应用选择一组资源以便与存储于SLA记录器数据库中的SLA相匹配。它将所选择的资源发送到主工作站做进一步处理。有多种启发性资源选择策略可满足SLA要求。然而,这不在本文研究范围内。
在云环境下为K均值应用选择的每个计算工作站i,i∈{1,...,N},其计算容量为μi。大数据包括共Wtotal个可分割计算负载。计算工作站i处理所有负载中的一部分,即chunki≤Wtotal。本文将一个计算工作站处理chunki个单位的负载所需时间TPi建模如公式(2):

其中θi表示启动节点i计算过程的固定延时,单位为秒,μi表示节点的计算速度,单位为单位负载/秒。将发送chunki个单位负载给计算工作站i所需时间TCi建模如公式(3):

其中iλ表示主工作站往计算工作站i传输数据的启动延时,单位为秒。Ci表示主工作站和计算工作站i间通信链路的数据传输速率,单位为单位计算负载/秒。当运行SSH或访问工作站i而使用各种云软件时,启动主工作站到计算工作站i的数据传输过程,即会导致iλ延时。
为了便于主工作站确定应该往每个计算工作站分配多少负载,本文使用文献[11]中的调度算法。每个计算工作站i将被分配大小为chunki的处理负载。本文算法考虑了网络和计算能力,且基于如下公式确定负载规模:
首个计算工作站完成分配任务chunk1所需时间,由下式给出如公式(4):

对第二个工作站如公式(5):

依次地,chunkN值由下式给出如公式(6):


以式(7)为基础,通过替代相应等式中的chunk1,即可确定剩余负载chunki,i=2,...,N。
4 基于云计算的K均值聚类
本文基于云计算的K均值聚类方法架构如图2所示:

图2 本文K均值法的架构
设D表示存储于主工作站控制的中央存储器处的数据点集。首先利用第5节中的部署计算数据块大小,其中chunki表示将传递给computing-workeri的分区的尺寸。设di表示分区,即:将会分配给computing-workeri的数据点集合。因此,数据分区分配完毕后,computing-workeri通过K均值聚类方法对数据块di进行聚类,生成具有K个代表点(即:质心)的K个聚类。设Si表示computing-workeri计算出的K个质心所组成的集合。下一步骤是从所有计算工作站收集所有质心,在主工作站处存储Kn个质心。然后,主工作站对Kn个质心进行K均值聚类,计算出K个聚类。最后,使用这些聚类的质心,并结合D中每个数据点到质心的距离,计算聚类的全局集合。综上所述,基于云计算的K均值聚类伪代码如下所示:


假设已经按照第3节中SLA的要求选择了计算工作站。主工作站在部署时使用第3节中描述的公式来计算必须要分配给工作站的数据块:每个计算工作站采用μ和θ值作为输入;主节点和每个计算工作站间的通信链路采用C和λ值作为输入。主工作站将规模上升的样本数据集发送给计算工作站,测量每个计算工作站上的计算时间及从主工作站到每个计算工作站的传输时间,并对这些数据进行线性拟合。然后,利用线性回归来计算大规模数据拟合时的计算能力(μ)和网络带宽(C)。在数据规模几乎为0时进行拟合,并计算出传输延时(λ)和计算延时(θ)。所有系统参数计算5次然后取均值。由于主工作站需要计算C,λ,μ,θ,减少运行次数将能避免较大开销。
下面伪代码描述的调度程序根据本文获得的公式计算数据块。本文部署了3种调度策略:(1)基于CPU的调度策略,调度器根据计算工作站的计算能力(μ)对计算工作站降序排序;(2)基于网络的调度策略,根据主工作站和计算工作站间的网络容量(C)对计算工作站降序排序;(3)无选择策略,采取随机次序。
然后,应用中的主节点利用计算出来的数据块相应地分割应用,按照C的升序次序将应用的数据块分配给计算工作站,也就是说,首先将相应数据块分配给通信链路C最大(即最快)的计算工作站。这可以降低剩余计算工作站对相应数据块的等待时间。在将计算数据块发送给相应的计算工作站后,主工作站通过使用ssh命令,触发计算工作站远程运行。本文在主节点和每个计算工作站间配置无密码通信,每个计算工作站在完成任务后会向主节点发送一个信号。
5 框架的部署

6 仿真实验
本节评估主工作站中K均值分布式应用的数据挖掘性能。比较本文框架与应用的理想makespan和理论makespan的效率。理想makespan计算方法是大数据集的总体规模除以被选计算工作站计算能力之和。

理论makespan是本文框架根据计算应用和系统参数获得的值。另外,本文使用聚类纯度指标(Purity)来衡量聚类挖掘的质量。常用的有两种聚类纯度指标:基于多数派的总纯度指标(GP)[12]和基尼系数指标(GI)[13]。总纯度指标表示每个聚类中多数派类别的正规化频率,定义如下:

其中,K表示生成的聚类总量,W={W1,...,WK}表示利用K均值法生成的K个聚类组成的集合,C表示类别标签数量,表示聚类i中属于类别j的数据点数量,D表示整个数据集。

其中pj∩i)表示类别j和聚类i的联合概率,即:

6.1 实验环境
本文实验环境包含3个节点构成的一个异质聚类:1个主工作站和2个计算工作站。主工作站也可向自己分配任务,扮演计算工作站的角色。主工作站配置1个Intel Xeon 2.8 GHz CPU,运行CentOS 6.3 Linux操作系统。其中1个计算工作站配置AMD Opteron 252 CPU,openSUSE 12.1(i586),版本12.1,另一个为Intel Xeon 3.6 GHz CPU,运行CentOS 6.3 Linux操作系统。聚类通过一个思科交换机相连。
本文采用UCI数据库中的森林覆盖数据集。该数据集包括不同类型森林的地理空间描述,有7种类别,54种属性及581,000个左右的实例(约130MB)。对数据集正规化,为相同属性赋予相同权重。同时,在聚类期间去除类别标签,以避免无意之中产生监督。为了进行大规模数据的实验仿真,本文通过随机选择并复制部分实例,生成了具有500,000-1000,000个实例的多个森林覆盖数据集。
本文测量了分布式K均值应用的总makespan。应用的makespan表示从主工作站开始向计算工作站分配数据集至主工作站上生成最终挖掘结果所经历的时间。计算了应用相对于理想makespan的效率,同时还计算了实际makespan相对于理论值的退化情况((actual-theoretical)/theoretical)*100。通过计算数据规模上升时的总运行时间及聚类纯度来评估工作负载上升对分布式K均值的性能和挖掘质量的影响。通过计算聚类规模增加时的聚类纯度评估聚类规模的影响,即聚类数量与聚类纯度的关系。进行100次实验取均值。
6.2 实验结果分析
当部署本文框架并调整K均值应用的尺寸时,本文的主要目的是研究经过尺寸调整后的K均值makespan与理想的makespan的接近程度,如图3所示:
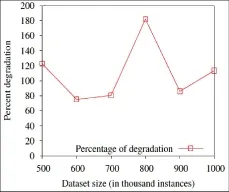
图3 真实makespan相对于理论makespan的退化比
图3表明,实际makespan与理想makespan之比达到最大值3.18。在本文实验环境中,当数据规模较大时,比率降到2.38如图4所示:

图4 正规化后的实际makespan与理想makespan
退化比例表明理论性能和实际性能间存在差异。本文框架假设数据集及运行时间之间具有线性关系。对基于聚类的应用来说,这一假设未必始终成立,因为收敛时间还依赖于被选择的数据集。然而,从总的趋势可以看出,随着数据集规模的增加,退化比例会呈现下降趋势,这表明本文方法在真实环境下确实能够降低数据挖掘应用的总体运行时间。
聚类纯度与聚类数量(K)和工作站数量(N)间的关系如图5所示:

图5 纯度与聚类数量(K)和工作站数量(N)之间的关系
X轴对应于聚类数量(K)(7-49),Y轴对应于纯度。从图中可明显看出,不论N取何值,聚类纯度均会随着K的上升而上升。以K=14和K=50为例。当K=14时,工作站为集中式(N=1)、2个工作站和3个工作站时的聚类纯度分别为0.58,0.61和0.58。当K=50时,工作站为集中式(N=1)、2个工作站和3个工作站时的聚类纯度分别为0.65,0.64和0.65。这一结果表明,当K增加时,基于云的数据聚类与集中式版本一样,均可提高聚类纯度。换句话说,基于云的聚类方法与集中式方法同样有效。这是因为对工作站获得的质心集合专门进行了一次聚类,于是每个位置本地生成的聚类模型在主节点处被有效融合。
数据规模增加对纯度的影响如图6所示:

图6 纯度与数据集规模
此时固定设置K=15。X轴表示数据集规模(单位为千个实例),Y轴表示纯度。该图表明,增加数据集规模对集中式和基于云的方法具有类似的影响。以X=500和X=1000为例。当X=500时(即:数据集有500K个实例),集中式方法和带有3个工作站的基于云的方法的纯度分别为0.58和0.60。当X=1000时(即:数据集有1百万个实例),集中式方法和带有3个工作站的基于云的方法的纯度分别为0.59和0.60。可以看出数据集对集中式和基于云方法的聚类纯度没有显著影响。根据这些结果得出结论:基于云的方法的聚类精度与集中式方法相同。
最后,为了进一步体现本文方案的优越性,采用UCI数据库中的森林覆盖数据集作为测试数据集,将本文方案与文献[6,7]中的方案在数据挖掘质量方面进行比较,实验结果如图7所示:

图7 不同方案的聚类质量比较
从图7中可以看到,随着数据集规模的增加,不同方案的聚类纯度都在下降。其中,文献[6]中方案的聚类纯度最低,而本文方案性能最好。仔细分析其原因可知,这是由于文献[6]的方案旨在应对实时性要求较强的以牺牲部分挖掘质量来达到提升挖掘效果的目的。而文献[7]的方案能够对数据挖掘任务进行优化分解,并通过定制并行挖掘规则来处理海量数据,较好的性能。而本文方案则更进一步,通过对云基础设施的实时监测、在考虑了所选资源的网络和计算延时基础上,能够自适应地从可用的云硬件网络中选择可用的硬件资源(计算和网络资源)分配给分布式数据挖掘应用,因此数据挖掘质量最优。总的来说,本文方案是有效的,能够满足目前大多数数据挖掘应用的需求。
7 总结
本文提出一种基于云计算的K均值聚类法以便对应用进行扩展。该方法的主要目标是把K均值应用作为一种SaaS云提供给云终端用户。用户只对K均值应用的性能和挖掘质量感兴趣,无需知道具体实现方法。本文的目标是通过提出一种基于云的大数据挖掘方法,向终端用户隐藏云技术的复杂性。其主要作用在于使K均值具有伸缩性并将其作为SaaS提供,同时将挖掘质量的损失降到最低。在下一步工作中将研究在本文框架中集成实时服务水平协议,以满足用户对挖掘/聚类的性能和质量要求。此外,还将提出数据的动态自主式再分配策略,以便本文框架能够实时监测基于云的应用的性能和质量指标,在必要情况下可以采取纠正措施。
[1]李德毅,张天雷,黄立威.位置服务:接地气的云计算[J].电子学报,2014,42(4):786-790.
[2]Ismail L,Barua R.Implementation and performance evaluation of a distributed conjugate gradient method in a cloud computing environment[J].Software:Practice and Experience,2013,43(3):281-304.
[3]Lai Y,ZhongZhi S.An efficient data mining framework on Hadoop using Java persistence API[C].Computer and Information Technology(CIT),2010IEEE10th International Conference on.IEEE,2010:203-209.
[4]Wu L,Garg S K,Buyya R.SLA-based resource allocation for software as a service provider(SaaS)in cloud computing environments[C].Cluster,Cloud and Grid Computing(CCGrid),201111thIEEE/ACM International Symposium on.IEEE,2011:195-204.
[5]陈光鹏,杨育彬,高阳,等.一种基于MapReduce的频繁闭项集挖掘算法水[J].模式识别与人工智能,2012,25(2):220-224.
[6]方少卿,周剑,张明新.基于Map/Reduce的改进选择算法在云计算的Web数据挖掘中的研究[J].计算机应用研究,2013,30(2):377-380.
[7]程苗.基于云计算的Web数据挖掘[J].计算机科学,2011,38(10):146-149.
[8]桂兵祥,何 健.基于高性能云的分布式数据挖掘方法[J].计算机工程,2010,36(5):76-78.
[9]陈磊,王鹏,董静宜,等.基于云计算架构的分布式数据挖掘研究[J].成都信息工程学院学报,2010,25(6): 577-579.
[10]Kantardzic M.Data mining:concepts,models,methods,and algorithms[M].John Wiley&Sons,2011.
[11]Ismail L,Khan L.Implementation and performance evaluation of a scheduling algorithm for divisible load parallel applications in a cloud computing environment [J].Software:Practice and Experience,2014,11(4):158-167.
[12]Osei-Bryson K M.Towards supporting expert evaluation of clustering results using a data mining process model[J]. Information Sciences,2010,180(3):414-431.
[13]Kavulya S,Tan J,Gandhi R,et al.An analysis of traces from a production mapreduce cluster[C].Cluster,Cloud and Grid Computing(CCGrid),2010 10th IEEE/ACM International Conference on.IEEE,2010:94-103.
Research on an Efficient Data Ming Framework Based on Cloud Computing
Liu Meng
(Dongguan Science and Technology School,Dongguan 523000,China)
Cloud computing can provide data mining results in the form of Software as a Service(SaaS).Both performance and quality of data mining are the fundamental criteria of data mining application in the cloud computing environment.This paper proposes a data mining application based on cloud computing and the framework for its distribution and scheduling of data sets. The framework implements the K mean clustering method based on cloud computing,and provides itself with the users as the cloud SaaS.Its main purpose is to reduce the whole execution time of the application and to minimize the loss of quality of mining. The simulation results show that,compared with the existing scheme,the scheme proposed in this paper can minimize the loss of quality of mining while the speed is significantly improved.In addition,it has good scalability of quality of mining when the amounts of cluster and scale of data sets both increase.It can promote this paper's program application in cloud service provider.
Cloud Computing;Data Ming;K Mean Clustering;Overall Execution Time
TP393
A
1007-757X(2015)06-0015-05
2015.03.16)
刘猛(1981-),男,江苏邳州人,东莞理工学校,讲师,研究方向:网络安全、云计算,东莞,523000
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
北京航空航天大学学报(2021年4期)2021-11-24
粉末冶金技术(2021年3期)2021-07-28
能源(2018年8期)2018-09-21
中学生数理化·高二版(2016年6期)2016-05-14
电气化铁道(2016年5期)2016-04-16
工业设计(2016年10期)2016-04-16
应用科技(2015年5期)2015-12-09
太阳能(2015年6期)2015-02-28
应用化工(2014年11期)2014-08-16
