
基于框架语义的隐式篇章关系推理
2015-04-21 08:43严为绒朱珊珊姚建民朱巧明
中文信息学报 2015年3期
严为绒,朱珊珊,洪 宇,姚建民,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
基于框架语义的隐式篇章关系推理
严为绒,朱珊珊,洪 宇,姚建民,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
篇章关系分析是一种专门针对篇章语义关系及修辞结构进行分析与处理的自然语言理解任务。隐式篇章关系分析是其中重要的研究子任务,要求在显式关联线索缺失的情况下,自动检测特定论元对之间的语义关系类别。目前,隐式篇章关系分析性能较低,主流检测方法的准确率仅约为40%。造成这一现状的主要原因是: 现有方法脱离论元的语义框架进行关系分析与检测,仅仅局限于特定论元特征的关联分析。针对这一问题,该文提出一种基于框架语义的隐式篇章关系推理方法,这一方法有效利用了框架语义知识库(即FrameNet)和相关识别技术,实现了论元语义框架的自动识别,并在此基础上,借助大规模文本数据中框架语义关联关系的分布概率,进行论元语义一级的关系判定。实验结果显示,仅仅利用第一层框架语义知识,即可提高隐式篇章关系检测性能至少5.14%;同时,在考虑关系类别平衡性的情况下,这一方法能提高至少10.68%。
篇章关系;隐式篇章关系;框架语义
1 引言
宾州篇章树库[1-2](Penn Discourse Treebank, 简写为PDTB)是一种以篇章为场景的论元关系语料库。PDTB统一将文字片断(句子或子句)称为论元,论元是具有独立语义的论述单元。其中,主要的测试样本为一对毗连的论元(下文统称“论元对”)。对于“论元对”中先出现的论元称为前置论元(简称Arg1),后出现的论元称为后置论元(简称Arg2)。篇章分析的核心任务是判定论元对之间的语义或修辞关系。本文重点研究论元对的语义关系检测问题。
篇章关系检测(Discourse Relation Detection)是一种对特定篇章内,论元之间语义关系进行自动判定的自然语言处理技术,不仅能够用于分析篇章的语义和语用规律,如理解篇章的结构以及评估篇章内容的连贯性;而且在信息处理领域也有广泛的应用价值,如篇章中的因果关系可用于自动问答系统和事件因果关系检测[3-4]对比关系可用于情感分析研究[5];扩展关系可进行自动文摘识别[6]等。
篇章关系分为三层,第一层关系包括扩展(Expansion)、偶然(Contingency)、对比(Comparison)和时序(Temporal)四大类;每类关系可根据语义进一步细分为多层子关系,例如,偶然关系可细分为因果(Cause)和条件(Condition)等第二层关系,第二层关系又可进一步细分为多个子关系。在此基础上,PDTB中的篇章语义关系,根据论元对(即一对论元,表示为“Arg1-Arg2”)之间是否存在显式连接词,划分为显式关系和隐式关系两类。
下面给出两项篇章关系样例,其中,例1为具有显式关系(Explicit Discourse Relation)的论元对,这种论元对具有显式连接词“but”,该连接词能够直接指定或反映两两论元之间的语义关联类别,此例中为“比较.对比”关系;例2为具有隐式关系(Implicit Discourse Relation)的论元对,这一论元对不具有显式连接词(注: 例2中的连接词为标注者推理给出的结果,原文并不存在),由此,无论连接词或篇章关系,都需根据语义信息和事物之间的本源逻辑进行估计与推理。
例1 Arg1: I tried on two dresses
(译文: 我试了两件裙子)
Arg2: but neither fits me.
(译文: 但是一件都不合身)
Relation: Comparison.Contrast
(篇章关系: 比较.对比)
例2 Arg1: McCain is beat by Obama.
(译文: 奥巴马击败了麦凯恩)
Arg2: [Implicit= So]Obama win the election.
(译文: [所以]奥巴马赢得选举)
Relation: Contingency.Cause
(篇章关系: 偶然.因果)
目前,显式篇章关系检测性能已达到93.09%[7],然而,隐式篇章关系检测性能仅约40%[8-9]。由于显式篇章关系中包含连接词,能够避免在篇章理解的时候产生歧义。因此,可直接根据句中包含的连接词推断其显式关系类型,比如,PDTB中存在连接词“before”( “在……之前”)指向“Temporal. Asynchronous”( “时序.异步”)关系的概率为100%,所以通过连接词能精确地推理篇章关系。与之相反,隐式篇章关系中缺乏显式连接词,只能通过结合上下文、语义、逻辑结构等信息进行间接的关系判定。然而,上下文的不确定性以及语义关系的歧义性等问题,使得隐式篇章关系检测的难度较高。
现有方法主要采用局部的语言特征[8-9](如句法特征、依存特征和词共现特征等)进行篇章关系检测,无法有效解释和判定论元之间的语义关系,原因在于: 局部特性无法直接诠释整个论元的外部语义关系,而仅仅能够表述论元内部的内容与组成结构。针对这一问题,本文提出一种基于框架语义的隐式篇章关系推理方法,这一方法利用框架语义作为论元整体语义的抽象表述,并借助大规模文本数据中,框架语义关联信息的分布概率,估计论元之间语义层面的关系属性。下述例3给出了基于框架语义的隐式篇章关系检测实例。
例3 Arg1: He was shot by a terrorist.
(译文: 他被恐怖分子射中)
Frame1: Attack (框架1: 袭击)
Arg2: He unfortunately passed away.
(译文: 他不幸逝世)
Frame2: Death (框架2: 死亡)
依据: (Frame1 vs Frame2,篇章关系: 偶然.因果,即Contingency.Cause关系)
断言: (Arg1 vs Arg2,篇章关系: 偶然.因果,即Contingency.Cause关系)
上述例3表明,“Attack”为Arg1的框架类别,“Death”为Arg2的框架类别,框架“Attack”和“Death”之间往往蕴含一种“偶然.因果”关系。由此,可以利用抽象语义之间的这一关联关系,推断Arg1和Arg2之间的语义关系也为“偶然.因果”关系。
由此,本文利用框架语义知识库(FrameNet*http://framenet.icsi.berkeley.edu(FrameNet的下载地址))建立论元的框架语义识别标准,其中每个论元的核心目标词(即FrameNet中的Target)都可以抽象为
一种框架(Frame),如上例中的核心目标词“shot”和“passed away”分别对应框架“Attack”和“Death”。
本文通过SEMAFOR*http://www.ark.cs.cmu.edu/SEMAFOR (工具SEMAFOR的下载地址)工具对1 019种框架进行自动识别,SEMAFOR是由Dipanjan Das等人开发的框架语义分析工具,该工具可对给定的句子进行目标词与框架的精确识别。本文采用框架语义辅助篇章关系检测的动机如下:
1) 现有篇章关系检测方法,如Wang和Zhou等[8-9],往往专注于单论元内部的语言学特征进行关系分类,忽视了论元之间的语义关联特性。论元内的语义片段、语法片段、句法片段和依存片段等特征皆为局部特征,不能刻画论元的整体概念,而论元之间的关系是概念之间关联属性的抽象与反映;
2) 框架语义之间存在较强的语义衔接关系,并且,论元的核心框架语义是论元整体语义的抽象,具有较强概括性,从而,框架语义之间的关系能够较为宏观地解释论元之间的语义关系,对于分析与推理隐式篇章关系有着较高的辅助作用。
在此基础上,本文采用如下步骤进行隐式篇章关系推理: 首先,通过框架语义分析工具SEMAFOR标注论元对的目标词及其框架类别;其次,基于大规模语料库GIGAWORD[10]计算目标词之间的互信息,并统计框架之间的最大似然关系;最后,通过框架之间的关系推测待测论元之间的关系。
本文组织结构如下: 第二章介绍相关工作;第三章简要介绍框架语义学;第四章详细论述基于框架语义的篇章关系推理方法;第五章给出实验设计;第六章进行总结。
2 相关工作
目前,篇章关系检测研究以全监督或半监督机器学习方法为基础,包括基于语言学特征的篇章关系分类方法和基于概率统计的篇章关系推理方法。
基于语言学特征的篇章关系分类方法中,Pitler等[7]采用有监督的篇章关系分类方法训练分类器,并使用情感词极性、动词短语长度、动词类型、句子首尾单词和上下文等特征进行关系分类,最终在PDTB测试集上获得了优于随机关系分类的性能。Lin等[11]继承了Pitler等的方法体系,细化了上下文特征的采集技术,使用了句法树的结构特征与依存特征;同时,结合Soricut等[12]于2003年提出的论元内部结构特征,在PDTB第二层隐式关系分类上获得40.2%的精确率。随后,Wang等[8]基于卷积树核函数提升了句法结构特征的区分能力,但性能并没有显著的提升(精确率约40.0%),仅略优于以浅层句法树为特征的关系分类性能。
基于概率统计的篇章关系推理方法中,Marcu等[13]首次将概率统计应用于篇章关系分析,基于词对的共现特征对论元之间合理的连接词进行估计,并利用连接词与篇章关系映射概率,实现关系判断。Saito等[14]继承了Marcu等的方法,加入了短语特征,提高了日文隐式篇章关系推理的性能。随后,Zhou等[9]验证了三元文法的共现概率及其关系指向,也能提高隐式关系的判定,相比于Saito等,该方法不局限于语法的规范,满足了词特征相互组合的连贯性和灵活性,但是其性能仅在偶然和时序关系上有所提升,精确率分别达到70.79%和70.51%,对扩展和比较关系的分类性能仍然偏低。
总体而言,上述基于语言学特征的分类方法,往往局限于有限的语言学资源,导致分类特征(如句法结构和依存特征)的缺失或训练不充分,负面影响了关系分类效果。此外,其上述基于统计信息的推理方法采用句子中孤立的片断(包括词、短语和三元文法)作为推理线索的采集对象,存在表义不全和表义不准的偏差,而这一偏差往往导致关系推理的异常。本文针对上述问题,提出了一种基于框架语义的隐式篇章关系推理方法。该方法以论元的整体框架语义为关系推理线索,尝试解决推理线索的片面性与局部性,此外,该方法在大规模语言学资源中采集和统计框架之间的关系概率,并将这一概率应用于论元语义关系的判定过程,从而避免了有限训练数据导致的线索缺失和训练不充分的问题。
3 框架语义简介
本文利用框架语义的关系解释和推理论元之间的篇章关系,其中框架语义遵循FrameNet[15](框架语义知识库)的定义与标准。FrameNet是由美国加州大学伯克利分校构建的一个基于框架语义学的在线知识库,该知识库在自然语言处理和语义研究等方面都有实用意义。FrameNet通过框架描述单词的释义,即词语背后隐藏的概念结构和语义等信息。从而,框架语义能够形成特定场景(包括事件、状态、关系或实体)的概念表述。
FrameNet由框架库、句子库和词元库三部分组成。其中,框架库主要对词语进行分类描述,并给出框架语义的定义,以及描述框架语义之间的概念关系;句子库是具有框架语义标注的句子样本集,往往用于框架语义识别任务的训练与测试;词元库在句子库的基础上生成,记录词元的语义搭配模式。FrameNet中共定义了1 019种框架,大体分为四类: 事件(Event)、状态(Situation)、关系(Relation)和实体(Entity),如表1所示。

表1 四类框架(未全部列举)
在FrameNet中,对句子的框架语义标注是一种类似于“谓词-论元”结构的“目标词-框架”(Target-Frame)结构。目标词是由动词、形容词或名词组成,标记为“Target”;框架是对目标词的一种抽象,标记为“Frame”。每个句子可能包含一个或多个“目标词-框架”结构,如下述例4所示。
例4 The Funding sources are shrinking, but the needs grow explosively.
(译文: 资金来源减少,但需求呈爆炸性增长)
例4包含四种“目标词-框架”结构,其中,目标词分别为: “source”、“shrink”、“need”和“grow”(例子中的黑体部分);框架分别识别为: “Source_of_getting”、“Expansion”、“Needing”和“Expansion”,且目标词与框架一一对应。换言之,论元的每个目标词都可以抽象为一种框架,如例4中目标词“source”抽象为框架“Source_of_getting”。
4 基于框架语义的隐式篇章关系推理
本文基于框架语义推理隐式篇章关系,即针对待测论元对,使用SEMAFOR工具分别识别出论元对(Arg1和Arg2)的目标词集合与框架集合,通过框架语义之间隐含的关系对论元之间的关系进行判定,图1给出了推理的方法框架。本文推理隐式篇章关系的方法框架主要包括三个方面: 关系样本抽取(即抽取包含Golden连接词的论元对);框架对的最大似然关系;待测论元对的隐式篇章关系推理。
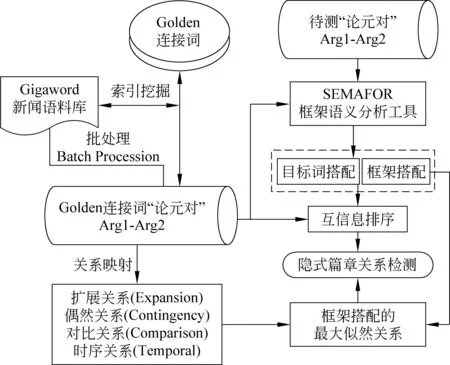
图1 基于框架语义的隐式篇章关系推理架构
4.1 关系样本抽取
关系样本抽取的目的是从大规模语言学资源中获取篇章关系样本,每项样本都必须满足如下两种条件:
1) 具有前置论元Arg1和后置论元Arg2;
2) Arg1和Arg2之间的篇章关系为显式关系。
这种关系样本中的显式关系由显式连接词唯一指定,如表2所示。从而关系样本蕴含的语义关系为已知条件,由此,可给出每个关系样本中,Arg1与Arg2的框架之间蕴含的语义关系。这类关系样本能够用于估计框架搭配生成特定关系的概率指标,进而辅助基于语义框架的隐式关系推理。这一推理方法可简单地理解为一种“以框架语义关系为桥梁的显式关系辅助隐式关系推理”的过程。
为了实现关系样本的精准抽取,本文采用PDTB中的Golden连接词唯一地指定显式关系。Golden连接词是指: PDTB 2.0中,指向某一篇章关系的概率在96%以上的连接词,共有87个。Golden连接词的歧义性小、语义较明确,比如连接词“though”指向“对比”关系的概率为100%。相比而言,非Golden的连接词往往语义不明确,且指向多种不同的篇章关系,比如,显式连接词“while”具有“当……时”和“然而”两种含义,分别指向“时序”和“比较”两种关系,从而难以利用这类连接词唯一地指向一种关系,对关系样本抽取容易引入噪声。
PDTB给出的134项连接词中,歧义连接词数量较少,且发生概率较低。表2是对PDTB中常见的连接词,统计了每个连接词对应的最大似然关系的概率,选取概率大于96%的连接词作为Golden连接词。从而,这类连接词能够有效指定特定论元对的篇章关系。

表2 PDTB中Golden连接词及其最大似然关系映射表
表2对PDTB的四种篇章关系,即“Expansion”、“Contingency”、“Comparison”和“Temporal”,分别简写为“Exp.”, “Con.”, “Com.”和“Tem.”(下文同)。
在此基础上,本文利用Apache Lucene 4.1*http://lucene.apache.org (Lucene的下载地址)建立小型搜索引擎进行本地检索,以Golden连接词作为查询,高速检索本地语言学资源中蕴含这一连接词的文字片段,并根据上述两项挖掘条件,即蕴含连接词的毗连论元,抽取关系样本。其中,Golden连接词对应的最大似然关系即为论元对之间的关系。本地语言学资源选用了GIGAWORD的版本1 (LDC2003T05),其中包含4 111 240篇新闻文本,来自四个不同的国际英语新闻专线,分别为: 法国新闻社、美联社、纽约时报以及新华通讯社。
4.2 框架对的最大似然关系映射
本文针对挖掘所得的关系样本,分析每个样本的语义框架,并借助显式连接词对篇章关系的直接映射,构建每个样本中两两框架与篇章关系的对应性,并计算大规模样本中“框架对-关系”的出现概率,以此实现框架对的最大似然关系估计。方法细节如下:
Step1: 针对关系样本,本文使用SEMAFOR框架语义分析工具分别识别Arg1和Arg2的框架集合。详细而言,针对前置论元Arg1,获取框架集合FrameSet1,包含多项框架{Frame11,Frame12, …,Frame1m};同理于后置论元Arg2,获取框架集合FrameSet2,包括多项框架{Frame21,Frame22, …,Frame2n};
Setp2: 针对这一关系样本,对FrameSet1和FrameSet2中的框架进行两两搭配,形成所有可能的框架搭配{Frame1i,Frame2j}i=1…m, j=1…n;
Step3: 针对这一关系样本,利用其已知的关系,即关系样本中显式连接词直接指向的关系(如4.1节),约定该样本的所有框架搭配{Frame1i,Frame2j}i=1…m, j=1…n都对应于这一关系;
Step4: 针对从GIGAWORD中抽取得到的所有关系样本,进行Step1至Step3操作,将所有样本中出现的框架搭配,以及各个框架搭配在特定样本中约定的篇章关系,合并为框架搭配与篇章关系的映射表FMap,表中每个框架搭配对应一个篇章关系(注: 该表不进行框架搭配的去重,借以辅助框架搭配的最大似然关系估计)。
借助上述映射表FMap,本文对每个框架搭配进行最大似然关系的概率估计。给定PDTB中第一层四种主关系,即“Expansion”、“Contingency”、“Comparison”和“Temporal”,计算特定框架搭配{Frame1i,Frame2j}i=1…m, j=1…n在四种关系上分布概率P(r),计算方法为: 框架搭配{Frame1i,Frame2j}i=1…m, j=1…n在FMap中对应关系r的频次,除以该搭配在FMap中的总量。其中,分布概率最高的关系,即为该框架搭配蕴含的最大似然关系,如公式(1)所示。

(1)
其中,nr表示框架搭配{Frame1i,Frame2j}i=1…m, j=1…n在FMap中对应关系r的频次,N表示该搭配在FMap中的总频次。
4.3 隐式篇章关系推理
本文利用上述框架与最大似然关系的映射表,实现基于框架语义的隐式篇章关系推理。这一推理方法基于如下假设: 一对论元的篇章关系,往往由论元的框架搭配之间的关系决定。基于这一假设,对于未给定显式连接词的隐式篇章关系,可以利用两两论元形成的框架搭配,以及框架搭配在特定篇章关系上的概率分布予以推理。
鉴于一项论元往往存在多个框架(论元局部成分衍生的多项框架)的情况,本文采用目标词之间的互信息作为识别核心框架的手段,互信息越高,则触发核心框架的概率越高。由此,给定某一待测论元对,本文选择两两论元的核心框架形成搭配,并利用上述框架搭配与篇章关系的概率映射表(如4.2节),实现最终的论元隐式关系推理。具体流程如下:
Step1: 针对待测论元对,使用SEMAFOR识别Arg1和Arg2的目标词集合和框架集合,且二者一一对应。详细而言,针对Arg1,获取目标词集合TargetSet1,包含多项目标词{Target11,Target12, …,Target1m};同理于Arg2,获取目标词集合Tar-getSet2,包括多项目标词{Target21,Target22, …,Target2n};对于框架集合的生成如4.2节;
Setp2: 针对这一待测论元对,对TargetSet1和TargetSet2中的目标词进行两两搭配,形成所有可能的目标词搭配{Target1i,Target2j}i=1…m, j=1…n;对FrameSet1和FrameSet2中的框架进行两两搭配,形成所有可能的框架搭配{Frame1i,Frame2j}i=1…m, j=1…n;
Step3: 借助关系样本集,计算目标词搭配{Target1i,Target2j}i=1…m, j=1…n的互信息MI(Mutual Information),如公式2所示。

(2)
其中,MI(Target1i,Target2j)记作目标词Target1i与Target2j之间的互信息,P(Target1i,Target2j)为目标词Target1i与Target2j在文本集中同时出现的概率,P(Target1i)为目标词Target1i出现的概率,P(Target2j)为目标词Target2j出现的概率。假定两目标词在样本集中出现的频次分别为count(Target1i)和count(Target2j),共现频次为count(Target1i,Target2j),N为关系样本总数,则:
(3)
Step4: 对目标词搭配按互信息进行排序,选取其中互信息排序前N (TopN)的目标词搭配,每一目标词搭配对应一个框架搭配,每一框架搭配在4.2节中给出了其最大似然关系,通过TopN个框架搭配的最大似然关系推理论元对之间的篇章关系,即在TopN个关系中,将出现频次最多的关系,判定为待测论元对的篇章关系。
由于框架之间在篇章内部具有一定的语义逻辑关系,框架语义本身是对论元语义的一种抽象,使得框架语义对隐式篇章关系的判定、语义分析与推理具有重要作用。表3列举了四类主要篇章关系的框架语义实例,当直观反映篇章关系的显式连接词缺失的时候,框架语义成为推理论元语义关系的关键性线索(如目标词“began”和“ended”同时出现在相邻的两个论元中,对应的框架分别为“Activity_start”和“Process_end”,触发“时序”关系)。

表3 四种隐式篇章关系的框架语义样例
5 实验设计
本文提出一种基于框架语义的隐式篇章关系推理方法,本节首先给出实验设计,包括测试用的语言学资源和评价标准;然后,汇报实验结果;最后,分析存在的问题,并与前人工作进行对比。
5.1 实验数据
本文针对PDTB第一层四个主关系(Expansion、Contingency、Comparison和Temporal)进行检测。由于主流方法的测试集大多数为section 21-22或者section 23-24,所以本文选用PDTB 2.0中的section 21-22作为测试集1 (TD1),共包含1 046个英文隐式关系论元对的样本;section 23-24作为测试集2 (TD2),共包含1 192个待测样本。对于包含两种或两种以上篇章关系的待测论元对,测试时选择这些篇章关系中最主要的关系类别作为其正确的篇章关系类别,表4给出了测试集中第一层四种隐式篇章关系的样本分布。

表4 测试集中隐式篇章关系的分布
实验涉及的外部资源是大规模静态数据资源GIGAWORD,包含4 111 240篇来自纽约时报等媒体的新闻报道。由于检测任务仅涉及英文文本,本文抽取其中896 446篇英文文本作为关系样本的来源。利用这一数据,并借助基于Lucene构建小型的本地搜索引擎,实现了关系样本的抽取,实验共抽取有效关系样本约一百万项。
本系统通过SEMAFOR标注论元对(包括关系样本和待测论元对)的目标词及其框架,由于部分论元长度较短,加上SEMAFOR工具本身包含的目标词只有六万多个,存在大量的未登录目标词(即未出现在FrameNet的词典例句和训练语料中的目标词),这就导致长度较短的论元不能被识别出目标词。其中,TD1中不能识别出目标词的待测论元对共有20个,TD2有24个,从而,实际参与实验的论元对数量TD1为1 026,TD2为1 168。实际参与隐式篇章关系检测的测试样本分布见表5。

表5 实际的测试集隐式篇章关系分布
5.2 评价标准
为评估本文系统对PDTB四种隐式篇章关系的识别性能,本文使用准确率(Accuracy)作为性能度量标准,如公式4所示,准确率是目前篇章关系分析与检测研究领域的通用评测标准,其中,TruePositve表示被正确分为正例的个数,TrueNegative表示被正确分为负例的个数,Sum即是待测论元对的总数。
(4)
该评测方法在篇章关系检测领域的早期应用是: 二元关系分类精度的评测。例如,以PDTB中的第一层关系为例,如果单一关系“Expansion”为一类,则另外三种关系(包括“Contingency”、“Comparison”和“Temporal”三种关系)为另一类,称作非“Expansion”关系类,当给定待测论元对时,其具有“Expansion”关系或非“Expansion”关系。由此,如果论元对具有“Expansion”关系且系统判定其具有“Expansion”关系时,则获得TruePositve指标;相反地,如果系统判定为非“Expansion”关系中的任何一种,都为误判,即FalseNegative。相对地,如果该论元对具有非“Expansion”关系,则无论系统判定为“Contingency”、“Comparison”或“Temporal”中的哪一种关系,只要不是“Expansion”关系,则都为判定正确,并获得TrueNegative指标;否则为误判,即FalsePositve。
目前,该评测方法也用于多元关系的性能计量,计量方法是将TrueNegative设置为恒定值0,只检验每个待测论元对是否获得正确的关系判定,即只计算TruePositve指标与Sum的比值。四种主关系的多元关系检测准确率统称为Four-way Accuracy,本文实验部分简写为Four-way。
5.3 实验结果与分析
本节首先给出可行性验证;其次,阐述本文系统的性能,并给出相应的结果分析;最后,通过与现有方法的对比分析,探讨本文方法的优缺点。
• 可行性验证
本文首次提出使用框架语义推理隐式篇章关系,与直接表征论元语义关系的显式连接词不同,框架语义主要出现在欠缺显式连接词的隐式论元间,通过其语义连接以及框架之间存在的上下文衔接性,潜在反映隐式篇章关系,这一特点有利于隐式关系的自动推理。但是,利用框架搭配关系推理论元之间的关系,需要首先满足如下条件: 两两框架之间的关系需要集中在少量甚至唯一的篇章关系上。框架语义是否满足这一要求,将直接决定基于框架语义的隐式关系推理是否可行。
为此,本文在前期试验中,在大规模数据集上,计算并分析了各个框架搭配在不同关系上的出现概率,如图2所示。其中,横轴上的符号X表示框架搭配的最大似然关系概率,而横坐标各个采样点标注为框架搭配取得最大似然关系的概率区间,比如,框架“Attack”与“Death”对应最大似然关系“Contingency”的概率为61.82%,则该框架搭配属于60%至70%的区间;纵坐标用于反映每个区间包含的框架搭配的数量,为了便于观察,统一归一化为[0,1]区间之内,即特定框架搭配数量除以总的框架搭配数量。由图2观测可知,概率值小于50%的框架搭配数量较少,仅占总量的14.14%,由此说明框架搭配往往集中蕴含少量甚至一种语义关系,证明了使用框架语义推理隐式篇章关系的可行性。
• 基于语义框架的性能分析
本文方法利用大规模外部资源GIGAWORD,计算框架搭配的似然关系概率,其中,每个搭配对应的关系都是其所在论元对的显式关系,需要通过显式连接词对应的显式关系进行获取。然而,实验观测,显式连接词在外部数据中的分布也存在极不平衡的特性,如图3所示,其中连接词“but”的出现频率极高(图3仅列出GIGAWORD中出现频率最高的前13个连接词),极不平衡地大幅超越其他连接词数量,从而连接词“but”对应的“Comparison”关系也在训练数据中高频出现,框架语义搭配的似然关系受其干扰,偏见地指向“Comparison”关系,使推理关系分类的能力削弱。

图3 GIGAWORD中Golden连接词对应的关系样本数
针对上述问题,本文实验部分将框架搭配的训练语料GIGAWORD进行了简单地分布平衡处理,即针对“but”连接词触发的“Comparison”关系样本进行欠采样。借助这一处理,当连接词“but”对应的关系样本数为5万的时候,本文获得了较高的测试结果,如表6所示。结果显示,测试集TD1的推理性能达到52.92%(Four-way),单一关系的二元分类性能最优为91.13%(如表6中的“Temporal”关系),最劣为56.14%(如表6中的“Expansion”关系);测试集TD2的推理性能达到50.68%,单一关系的二元分类性能最优为95.72%,最劣为55.14%。

表6 隐式篇章关系性能分析
TPos:TruePositive,即正确判定正例的样本数量
TNeg:TrueNegative,即正确判定负例的样本数量
然而,观测实验结果的细节发现,虽然“Temporal”关系的二元分类性能最优,但事实上,在测试集TD1和TD2上“Temporal”关系的测试样本获得的TruePositive都为0值,即这类“Temporal”关系样本都没有被判定为“Temporal”,而是其他关系。同时,针对测试集TD1和TD2,非“Temporal”关系的样本产生的TrueNegative分别为935个和1 118个,分类准确率较高。由此,本文的关系推理系统更倾向于将所有测试样本判定为非“Temporal”类的篇章关系。造成这一现象的原因如下:
1) 测试样本分布不均衡,如表5所示,实验中使用的PDTB测试集TD1共包含1 026个测试样本,而其中仅有55个“Temporal”关系的测试样本,约占总数的5.36%,这种不平衡性在TD2和外部数据中同样存在。从而,“Temporal”关系样本的机器学习、概率估计和推理都本源地存在较高难度;
2) 外部资源分布不均衡,其中,属于“Temporal”关系的样本数占少数,从而框架搭配的似然关系受其干扰,基本不会指向这种关系,使关系分类推理“Temporal”关系样本的能力进一步削弱。
同时,测试集TD1的“Comparison”关系的测试样本获得的TruePositive也为0值,这是由于在测试样本分布中,也只有146个“Comparison”关系的测试样本,约占总数的14.23%(见表5)。
针对上述两种现象,本文实验部分将框架搭配的训练语料(GIGAWORD)进行了简单地分布平衡处理,即针对高频连接词(只考虑图3中给出的13个Golden连接词)触发的关系样本进行欠采样进行分布平衡处理。借助这一处理,本文获得了较为平衡的测试结果,如表7所示。结果显示,对训练语料的简易平衡,即可影响测试样本的关系分类平衡性。其中,“Comparison”和“Temporal”关系的TPos(TruePositive)指标都有所增长。但是,相对地负面影响了“Expansion”关系样本的分类效果,TD1减少了104个TPos,TD2减少了53个TPos。同时,也负面影响了整体推理性能,TD1的Four-way减少至46.49%,减少了66个TPos,TD2的Four-way减少至47.69%,减少了35个TPos。
上述现象说明,现有的简易平衡方法,尚无法面面俱到地顾及所有关系的分类需要,从而,训练数据或外部数据的关系平衡问题,是一项极有价值的全新研究点。就目前测试结果观察,“Comparison”关系样本的欠采样,能提高除了“Expansion”关系以外的所有关系的分类准确率,而“Expansion”关系占关系总量的40%以上(统计自PDTB 2.0的section 0-20和GIGAWORD),因此,主要的关系样本平衡应主要着眼于“Comparison”和“Expansion”关系的分布调整。

表7 隐式篇章关系性能分析
TPos:TruePositive,即正确判定正例的样本数量
TNeg:TrueNegative,即正确判定负例的样本数量关系推理性能比较
• 关系推理性能比较
本节汇报基于框架语义的篇章关系推理性能(Four-way),并与现有主流篇章关系检测方法进行对比分析。本文推理方法的Four-way准确率,在测试集TD1上的测试性能为46.49%,在忽略关系类别平衡性的情况下,整体性能最高能达到52.92%,测试集TD2上的测试性能为47.69%,在忽略关系类别平衡性的情况下,整体性能最高能达到50.68%,如表8所示。相对地,Wang等基于句法结构特征构建篇章关系分类器,并利用树核函数提高句法特征的分类效果,准确率为40.00%;Zhou等基于统计语言模型的基础理论,利用文法共现概率与文法关系概率,形成了一套统计策略指导的篇章关系推理方法,测试性能为41.35%。由此,针对测试集TD1,本文关系分布平衡状态下的推理性能,给出了5.14%的优化指标;而忽视分布平衡问题时,可获得11.57%的性能提升。相对而言,针对测试集TD2,本文关系分布平衡状态下的推理性能,给出了7.69%的优化指标;而忽视分布平衡问题时,可获得10.68%的提升。

表8 各隐式篇章关系推理方法的性能对比
对比结果显示,基于句法特征的篇章关系分类性能(如表8中Wang等[8]的性能),低于该实验中所有基于统计策略的关系推理性能(包括本文方法和Zhou等[9]的语言模型方法)。一定程度上,这一现象证明统计技术在隐式关系检测任务中应用的可行性。性能较Wang等取得较大提高的原因是: Wang等采用的是基于树核函数抽取句法树中的结构化信息,而句法结构特征本身并不能直接表征语义,需要通过角色等其他特征予以补充,才能在一定程度上描述语义现象,也因此,句法结构特征也无法有效地描述论元之间的语义关系。相对而言,本文方法利用论元的框架语义作为分析和推理语义关系的特征,而框架语义本身是论元语义的抽象表述,其在大规模数据中的关联概率,以及蕴含的最大似然关系,在一定程度上,能够较好地反映论元之间的语义关系,有助于隐式关系的估计与推理。且Wang等方法的算法复杂度高,本文仅采用简单的方法,实验准确率就有了明显的提升。
另一方面,本文基于框架语义的篇章关系推理方法,与Zhou等基于语言模型的关系推理方法,同为统计策略,但性能上也具有较为明显的差异(本文方法具有较高的准确率)。原因在于,虽然Zhou等的方法能够将语言片段的连贯性和关联性,融入毗邻论元的衔接属性分析当中(即论元的篇章结构关系),但不能确保其使用的序列语言片段能够描述论元整体语义,从而也无法有针对性的分析语义层面的关联关系。而篇章关系分析不仅仅是结构关系的分析,更是语义关系的逻辑性分析。缺失语义层面的特征分析与应用,则欠缺了重要的篇章关系检测途径。
然而,本文的最好性能仅仅略优于50%,距离实用化标准尚存较大距离。主要原因在于,隐含关系往往存在主观性和模糊性,不同的语境下相同的框架语义能够形成不同的篇章关系。例如,“Attack”与“Death”不仅具有因果关系,而且具有时序关系。提升现有方法,不可避免地需要融入论元以外的框架语义环境。此外,虽然本文采用的目标词和框架识别技术,具有目前国际上最优的识别性能,但准确率仍不充分(约为90%,本实验中准确率仅约为80%),尤其,对于未登录目标词而言(即FrameNet训练语料中未出现的目标词),其框架语义识别性能仅约30%,从而漏检了大量有效的关系实例,对利用框架语义及其关系的统计方法,必然造成负面影响,从而一定程度上降低基于框架语义的篇章关系推理性能。
6 总结
本文针对隐式篇章关系检测任务,提出了一种基于框架语义的关系推理方法,以框架语义及其关系的统计信息为基础,利用连接词与篇章关系的映射关系为桥梁,形成了一套基于框架语义的隐式篇章关系推理方法。利用国际标准篇章关系分析树库PDTB进行测试,证明该方法能够有效提升现有基于统计技术的篇章关系检测性能。
然而,基于框架语义的关系推理方法仍有较大提升空间,可尝试改进的途径包括两个主要方面: 其一是利用上下文语境的约束,提升推理精度;其二是优化框架语义识别技术,尤其是优化未登录目标词的框架语义识别,借以提升框架语义关系样本的抽取与采集能力,降低漏检率,辅助框架语义及其关系的概率统计。
[1] Prasad R, Dinesh N, Lee A, et al. The Penn Discourse Treebank 2.0[C]//Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC), Marrakech, Morocco, 2008: 2961-2968.
[2] Miltsakaki E, Robaldo L, Lee A, et al. Sense annotation in the Penn Discourse Treebank. Journal of Computational Linguistics and Intelligent Text Processing, Lecture Notes in Computer Science, 2008, 4919: 275-286.
[3] Riaz M, Girju R. Another look at causality: Discovering Scenario-specific Contingency Relationships with no Supervision[C]//Proceedings of the 4th IEEE International Conference on Semantic Computing (ICSC), Pittsburgh, USA, 2010: 361-368.
[4] Do QX, Chan YS, Roth D. Minimally supervised event causality identification[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Edinburgh,UK,2011: 294-303.
[5] Zhou L, Li B, Gao W, et al. Unsupervised discovery of discourse relations for eliminating intra-sentence polarity ambiguities[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Edinburgh, Scotland, UK 2011: 162-171.
[6] 王继成,武港山,周源远等. 一种篇章结构指导的中文Web文档自动摘要方法[J]. 计算机研究与发展, 2003, 40(3): 398-405.
[7] Pitler E, Raghupathy M, Mehta H, et al. Easily identifiable discourse relations[C]//Proceedings of the 22nd International Conference on Computational Linguistics (COLING), Manchester, UK, 2008: 87-90.
[8] Wang Wen-Ting, Su Jian, Tan CL. Kernel based discourse relation recognition with temporal ordering information[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL), Uppsala, Sweden, 2010: 710-719.
[9] Zhou Zhi-Min, Xu Yu, Niu Zheng-Yu, et al. Predicting discourse connectives for implicit discourse relation recognition[C]//Proceedings of the 23th International Conference on Computational Linguistics (COLING), Poster, Beijing, China, 2010: 1507-1514.
[10] Napoles C, Gormley M, Durme BV. Annotated Gigaword[C]//Proceedings of the Joint Workshop on Automatic Knowledge Base Construction & Web-scale Knowledge Extraction (AKBC-WEKEX) of NAACL-HLT, Montreal, Canada, 2012: 95-100.
[11] Lin ZH, Kan MY, Ng HT. Recognizing implicit discourse relations in the Penn Discourse Treebank[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing (EMNLP), Singapore, 2009: 343-351.
[12] Soricut R, Marcu D. Sentence level discourse parsing using syntactic and lexical information[C]//Proceedings of the 2003 Conference of the North America Chapter of the Association for Computational Linguistics on Human Language Technology (NAACL), Edmonton, Canada, 2003: 149-156.
[13] Marcu D, Echihabi A. An unsupervised approach to recognizing discourse relations[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Morristown, NJ, USA, 2002: 368-375.
[14] Saito M, Yamamoto K, Sekine S. Using phrasal patterns to identify discourse relations[C]//Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics (HLT-NAACL), New York, USA, 2006: 133-136.
[15] Fillmore CJ. Frame semantics and the nature of language[J]. Annals of the New York Academy of Sciences, 1976: 20-32.
Implicit Discourse Relation Inference Based on Frame Semantics
YAN Weirong, ZHU Shanshan, HONG Yu, YAO Jianmin, ZHU Qiaoming
(School of Computer Science and Technology, Soochow University, Suzhou, Jiangsu 215006, China)
Discourse relation analysis is a task of natural language understanding which aimed at analyzing and disposing the semantic relation and rhetorical structure of discourse. Implicit discourse relation analysis is an important subtask of automatically detectind senses of semantic relation between arguments in the absence of direct cues. Currently, the performance of implicit discourse relation analysis is low and state-of-art accuracy can only reach 40%. The major cause of this situation is that the existing methods did not analyze arguments in the semantic frame, limited only to the local features and correlation analysis of arguments. This paper proposes a method of implicit discourse relation inference based on frame semantic. This method automatic recognised semantic frame of arguments through FrameNet and related identification technology. On this basis, we indentify the semantic relation of arguments by the distribution probability of frame semantic relation in large-scale text data. The experimental results show that, only using the first level of frame semantic can improve the detection performance of implicit discourse relation up to 5.14%; meanwhile, this method can make the accuracy rate increased by 10.68% in the case of considering the balance of relation categories.
discourse relation; implicit discourse relation; frame semantics

严为绒(1988-),硕士研究生,主要研究领域为篇章分析。E⁃mail:sallyrong8521@gmail.com朱珊珊(1992-),硕士研究生,主要研究领域为篇章分析。E⁃mail:zhushanshan063@gmail.com洪宇(1978-),通讯作者,博士,副教授,主要研究领域为篇章分析、话题检测与跟踪等。E⁃mail:tianxianer@gmail.com
1003-0077(2015)03-0088-12
2014-02-17 定稿日期: 2014-06-23
国家自然科学基金(61373097,1003152,61272259,60970056,60970057,90920004);教育部博士学科点专项基金(2009321110006,20103201110021);江苏省自然科学基金(BK2011282);江苏省高校自然科学基金重大项目(11KJA520003)以及苏州市自然科学基金(SYG201030、SH201212)
TP391
A
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
成都理工大学学报·社会科学版(2022年1期)2022-05-26
开放教育研究(2020年2期)2020-03-31
阅读与作文(英语初中版)(2019年10期)2019-11-27
中国修辞(2017年0期)2017-01-31
高中生学习·高三版(2016年12期)2016-12-26
长江学术(2016年4期)2016-03-11
中文信息学报(2012年2期)2012-06-29
儿童时代·快乐苗苗(2009年5期)2009-06-04
