
基于迁移的微博分词和文本规范化联合模型*
2015-04-18 07:55:29钱涛姬东鸿戴文华
华南理工大学学报(自然科学版) 2015年11期
钱涛 姬东鸿† 戴文华
(1.武汉大学 计算机学院, 湖北 武汉 430072; 2.湖北科技学院 计算机科学与技术学院, 湖北 咸宁 437100)
基于迁移的微博分词和文本规范化联合模型*
钱涛1姬东鸿1†戴文华2
(1.武汉大学 计算机学院, 湖北 武汉 430072; 2.湖北科技学院 计算机科学与技术学院, 湖北 咸宁 437100)
传统的分词器在微博文本上不能达到好的性能,主要归结于:(1)缺少标注语料;(2)存在大量的非规范化词.针对这两类问题,文中提出一个分词和文本规范化的联合模型,该模型在迁移分词基础上,通过扩充迁移行为来实现文本规范化,进而对规范的文本进行分词.在实验中,采用大量的规范标注文本及少量的微博标注文本进行训练,实验结果显示,该模型具有较好的域适应性,其分词错误率比传统的方法减少了10.35%.
分词;文本规范化;域适应;迁移模型;微博
微博已成为当前自然语言处理(NLP)领域的一个研究重点,但传统的NLP工具在微博域上并不能获得较好的性能[1- 2].中文分词是NLP最基础的任务,它的好坏决定了其他NLP任务的性能.
微博分词通常看作是一个域适应问题,大多数方法从微博中抽取域特征[3],扩充域词典[4],然后采用传统的方法(如CRF、Transition-Based等方法)来学习模型.然而,当前的标注语料大都是基于规范文本的,而微博域缺少相关的标注语料,使得传统的分词工具在微博域并不能获得较好的分词性能,其中,最主要的原因之一是微博中存在大量的非规范词,如“给力”、“妹纸”、“鸡动”等.
文本规范化是微博的一个预处理过程,其目的是把非规范词转化为规范词,进而转化为规范文本.它通常被看作是一个噪音信道问题[5]和翻译问题[6].大多数工作主要研究英语的规范化,它们通常采用分阶段的非监督方法,先检测再规范化.
不同于英文依据词是否在词典中来判断一个词是否为非规范词,中文非规范词的判断是非常困难的.中文非规范词的构成形式具有多样性,如同音词、缩写、音译、重复、释义等,由于这种多样性,人们在处理文本规范化时,通常根据不同的变化类型训练不同的模型[7- 8].当前的研究结果显示,文本规范化有助于提升微博域中其他NLP任务的性能[2,8].
对于中文微博,由于文本规范化需要预先分词,且规范化有助于分词,因此有必要将分词和规范化任务进行联合.Wang等[9]提出了一个联合分词和非规范词的检测模型,但并没有对非规范词做规范化处理;Kaji等[10]提出了基于日文的联合分词、词性标注和文本规范化的模型.这些模型采用大量标注的非规范文本进行训练,因而实现代价较大.
文中提出一个分词和规范化联合模型.该模型采用基于迁移的分词模型,扩充迁移行为以实行文本规范化;同时,采用规范标注文本进行训练,克服了缺少标注语料的问题;另外,该模型融合少量的微博标注文本进行训练,能同时获取非规范及规范文本特征,自然地实行特征扩充[11],因此具有较好的域适应性.
该联合模型基于一个自动构建的非规范词典来检索非规范词所对应的候选规范词.该词典由〈非规范词,规范词〉对组成,其构建基于如下假设:非规范化词通常都有相应的规范词与之对应[7- 8],如妹纸——妹子、海龟——海归、童鞋——同学等.
1 基于迁移的分词模型
中文分词输入一个未分割的句子,输出一个已分割的序列,可表示成如下最优化问题:给一个句子x,输出F(x)满足:
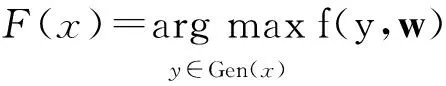
(1)式中:Gen(x)为可能的分割序列集;目标函数f(y,w)评估生成的分割序列,其中y表示生成的序列,w表示序列所对应的特征权重向量.
文中把Z&C模型[12]作为基线系统.Z&C模型是一个基于迁移的分词模型,它将分词看作是一个迁移序列生成过程,其主要优点在于特征选择更灵活,不仅可利用字的特征,还可利用词及状态序列的特征.基于迁移的分词模型的目标函数可表示为
(2)
其值为分割迁移行为评估值之和.式(2)中,|x|表示句子x的长度,i表示字符的序号,Φ(x,yi,ai)表示在字符i处迁移行为ai时的特征向量.
一个迁移分词模型被定义为一个四元组M=〈C,T,W,Ct〉,其中:C是状态空间;T是转换集,每一个转换表示为一个函数C→Ct,Ct是一个终态集;W是一个输入句子w0…wn-1,其中wi表示一个字符.模型学习时,对每一个可能迁移(即从一个状态转换到另一个状态)进行评估打分.每一个状态是一个四元组ST=〈Si,u,v,c〉,其中Si表示已被分割的前i个字符序列,u表示最后一个被分割的词在句子中的索引,v表示倒数第二个被分割的词在句子中的索引,c表示分割序列Si的评估值.
图1给出了分词模型的演绎推理系统.该系统的处理过程如下:系统从左至右对每个字进行处理,处理每个字时,分别执行以下2种迁移行为(或推理规则):
(1)APP(i),把字符wi从未分割队列中删除,并加到已分割的最后一个词的后面构成一个新词,其评估值c=c+α,其中α为行为APP时新增的局部评估值.
(2)SEP(i),把wi从未分割队列中去除,把它与最后一个词分割,作为一个可能的新词.其评估值c=c+β,其中β为行为SEP时新增的局部评估值.
例如,给定句子“工作压力啊!”,一个可能的迁移行为序列可表示如下:SEP(工)、APP(作)、SEP(压)、APP(力)、SEP(啊)、SEP(!).

图1 基于迁移的分词模型的演绎推理系统
Fig.1 Deductive system of transition-based segmentation model
2 分词、文本规范化联合模型
文中所提联合模型扩展自基于迁移的分词模型,其处理过程与基于迁移的分词模型类似.主要区别是除了前述两种迁移行为(APP和SEP)外,为了实现文本规范化,该模型还引入了另一种迁移行为——SEPS.执行该行为时,如果最后一个分割的词在词典中存在它的规范词,则用该规范词代替非规范词.图2给出了该模型的一个迁移例子.
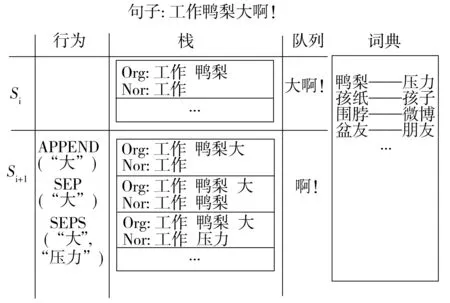
图2 联合模型的迁移行为示例
如图2所示,在处理当前字“大”时,首先把它从队列中去除掉,然后分别执行以下3种行为:
(1)APP(“大”):在非规范化分割序列中把“大”加到最后一个单词“鸭梨”后作一个词.
(2)SEP(“大”):“大”与“鸭梨”分割作为一个新的单词.
(3)SEPS(“大”,“压力”):执行SEP(“大”),且在规范文本分割序列中用“压力”替换上一次SEP行为分割的最后一个词“鸭梨”.
例如,给定句子“工作鸭梨啊!”,一个可能的迁移行列序列可表示如下:SEP(工)、APP(作)、SEP(压)、APP(力)、SEPS(啊,压力)、SEP(!).
词典替换基于一个非规范词典,词典的每一项由〈非规范化词、规范词〉对组成.由于是使用已存在的词典,因此模型并不需考虑非规范词的多样性.2.1 形式化
文中所提联合模型与分词模型的另一个主要区别在于联合模型生成一个分割序列对:规范及非规范序列对,可表示为公式(3).对一个句子x,模型的输出F(x)满足:

(3)
式中,Gen(x)表示可能的输出序列对.使用目标函数f(y,y′,w)评估生成的分割序列对,其中y、y′分别表示生成的规范及非规范序列,目标函数表示如下:
(4)
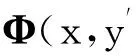
由于该联合模型生成了规范及非规范分割序列对,它能获得两类特征——非规范和规范文本特征,因此该模型具有以下优点:
(1)采用规范文本特征,该模型能直接使用大量已标注的规范语料文本进行训练,克服了微博文本缺少语料的问题;
(2)使用两类特征,其中规范文本特征作为公共特征,非规范文本作为域特征,自然地实现了特征扩充[11],模型具有较好的域适应性.
后面的实验显示,利用大量的规范语料和少量的微博语料进行训练后,模型的性能得到较大提升.
2.2 解码和训练
解码算法采用基于束的宽度搜索算法.对于待分词的句子,从左至右地处理每个字符,在处理一个字符时,分别执行3种迁移行为(APP、SEP和SEPS);接着,产生新的输出序列集,同时保留N个评分最高的候选输出序列;然后,在当前候选输出序列的基础上处理下一个字符,直到处理完所有字符;最后输出评分最高的候选输出序列.算法1给出了详细的伪代码.其中:agenda储存当前的候选输出序列集,N-Best从当前的agenda返回前N个分数最高的候选项,GetNorWord在非规范词典中检索非规范词所对应的候选规范词.
算法1:解码器
输入:sent:Infomalsentence,Dictionary
输出:Bestnormalizationsentence
1.agenda←NULL
2.forindexin[0..LEN(sent)]:
3.forcandinagenda:
4.APP(agenda,cand,sent[index])
5.SEP(agenda,cand,sent[index])
6.norWords←GetNorWord(cand.lastWord)
7.forwordinnorWords
8.SEPS(agenda,cand,insent[index],word)
9.agenda←N-BEST(agenda)
10.returnBEST(agenda)
训练过程与解码算法过程类似,区别在于当训练结果与标准不一致时,学习算法会对参数进行更新.学习算法是一个基于泛化的感知机算法[13],参数更新采用Collins等[14]提出的“提前更新”策略.
2.3 特征
文中模型使用了Z&C模型[12]所使用的全部特征模板,包括基于字、词的特征模板.由于缺少标注语料,这些特征对于文本标准化任务来说所包含的信息太少.许多研究指出,语言统计信息对文本规范化有着重要的作用[8,10].
文中从基于词的语言模型抽取语言统计特征.语言模型从标准的规范文本中构建.在实验中,学习了3个语言模型,分别是一元、二元、三元模型,其对应的特征模板依次为word-1-gram、word-2-gram、word-3-gram.
每类模型按概率分成10个等级,分别对应于10个特征模板.例如,二元单词“压力-大”的概率在第二级中,则其特征表示为“word-2-gram=2”.
在实验中,采用SRILMtools(见http:∥www.speech.sri.com/projects/srilm/)在GigawordCorpus(见https:∥catalog.ldc.upenn.edu/LDC2003T05)上训练语言模型.实验结果显示,语言统计特征同时提升了文本标准化和分词的性能.
3 非规范词典的建立
虽然构建大规模的非规范词典是非常困难的,但“非规范-规范”词对关系能从大模型的Web语料中获取[7],且非规范词的构成具有一定规律.基于此,文中采用两种方法构建和扩充非规范词典.由于篇幅原因,这里仅给出简要介绍.
第1种方法是从大规模微博文本中抽取“非规范-规范”词对关系.许多非规范词和规范词通常在相同的的文本中共现,从文本中能抽取出它们的关系模式.如表1所示,从第1个例子能抽取出模式“formal也称informal”,从第2个例子中能抽取出模式“informal(formal)”.文中使用Bootstrapping算法来抽取“非规范-规范”词对.首先手动收集一个小的词对集,然后使用这些词对作为种子,抽取关系模式,再利用这些模式识别更多的关系,并把它们扩充至词典.由于抽取的词对有大量的噪音,一个基于相似度的分类器被用于打分并过滤噪音,最后前n个得分最高的词对加入词典.

表1 “非规范-规范”词共现例子
第2种方法是利用非规范词的生成规律来生成新的非规范词.虽然非规范词具有多样性,但是其生成具有一定的规律,如采用组合、音借、缩写、同音、重复等方式生成.文中利用已识别的“非规范-规范”词对学习出生成模式,从而构建更多可能的“非规范-规范”词对.例如:在“妹子-妹纸”中,采用模式:子→纸,把“妹子”变成“妹纸”.使用这种方式,能生成更多的词对,如“汉子-汉纸”、“男子-男纸”、“孙子-孙纸”.
为了保证词典质量,两种方法都采用人工辅助监督.在实验中,一共构建了32 787个非规范词对.
对每个“非规范-规范”词对,统计出替换概率.考虑到在缺乏上下文的情况下无法判断是否应该替换,例如对“鸭梨好大啊”,是否用“压力”替换“鸭梨”?可根据替换概率来判断,这样可部分弥补训练语料不足的缺点.
4 实验
4.1 语料标注
为了训练和评估文中所提模型,开发了一个微博语料库,从新浪微博中抽取语料,对网址、情感符、用户名、标签作预处理,最后得到了5 894个微博文本,包含32 061个词.
两个具有语言学背景的学生手工标注了上述语料的词边界并进行文本规范化.分词采用CTB(见https:∥catalog.ldc.upenn.edu/LDC2010T07)标准.非规范词一共标注了1 071个,其中包含616个不同的非规范词对.非规范词占整个语料的1.34%.为了验证前面的假设——每一个非规范词通常有一个对应的规范词,文中分析了标注的一致性.其Cohen’s Kappa值为0.95,这说明非规范词是很容易被标注的.
4.2 实验设置
标注的实验数据按7∶1∶2的比例分成3部分:训练集、开发集、测试集.实验中采用两类训练数据进行训练:一是直接用CTB进行训练;二是融合CTB和微博语料进行训练.由于微博语料太少,在实验中没有单独采用微博语料用于训练.
实验中,采用传统的F值对分词、文本规范化进行评估.
4.3 基线
为了和联合模型进行比较,文中采用以下两个基线系统:
(1)Stanford分词器.采用Standford分词器直接对开发和测试数据进行分词.
(2)S;N分词.先用基于迁移的分词模型分词,然后在分词的基础上直接进行文本规范化.
每个系统按是否采用语言模型特征分为两个子系统.
4.4 开发集结果
开发集主要用来确定束搜索的宽度及训练次数.实验显示,当宽度为16、循环次数为32时,开发集测试性能最好.另外,开发集也用来分析与基线的比较、词典对性能的影响等.表2给出了开发集的实验结果.其中,S;N表示Pipe-Line模型,SN表示文中提出的联合模型,“模型”+lm表示在原模型的基础上增加语言模型特征.可以看出,传统NLP工具在微博域上并不能获得较好的性能,采用Stanford分词器,其分词性能为87.55%.

表2 开发集结果1)
1)Seg-F1—分词的F值;Nor-F1—规范化的F值.
(1)与Pipe-Line的比较
实验的主要目标之一是验证文本规范化是否有助于提升微博域的分词性能.从表2可以看到,联合模型的性能要比Pipe-Line的性能高.说明文本规范化有助于提高分词效果,且两个任务彼此受益.
总体而言,分词性能提升不是很高,这主要是由于非规范词在语料中所占比重太小(只占语料的1.6%).此外,表3也给出了开发集中规范词和非规范词的识别精度(即召回率).使用词典后,非规范化词的识别精度大大提高,规范词的识别精度也有小幅提升,说明非规范词不仅有助于非规范词性能的提升,而且有助于规范词的分割.
表3 开发集上规范词、非规范词及所有词的识别精度1)
Table 3 Recalls of formal,informal and all words on development set

系统CTB训练CTB+微博训练NRIRRNRIRRS;N0.86110.50000.85240.89090.74240.8873SN0.86140.65530.85520.89110.84470.8890S;N+lm0.90430.41290.89250.92510.61740.9177SN+lm0.90450.76520.90090.92550.87880.9244
1)NR—规范词的召回率;IR—非规范词的召回率;R—所有词的召回率.
(2)语言模型的影响
从表2可以看出,当使用语言统计特征时,分词和文本规范化性能得到较大提升,说明使用语言统计信息不仅有助于文本规范化,而且能帮助微博分词.
此外,由表3可知,使用语言模型特征后,联合模型SN+lm中非规范词的分词性能得到较大提升;但对于Pipe-Line模型S;N+lm,非规范词的分词性能反而下降了.产生这种现象的主要原因是非规范词的低频性——在使用语言特征时,含有非规范词的文本评估得分会较低,导致不能正确地分词,甚至影响规范词的分割.而当把它规范化后,评估分数会相应地提升.这说明直接在微博文本中使用语言统计特征会产生副作用,而文中所提联合模型更适合使用语言模型特征.
(3)词典的影响
非规范词典在联合模型中起着重要作用.使用词典本质上有助于减少测试语料中的未登录词.此外,词典对语料中非规范词的覆盖率也是非常重要的.覆盖率越高,则性能越好.文中所构建的词典在开发集和测试集的覆盖率分别是47.8%和49.5%.
为了调查覆盖率对分词性能的影响,手动构建了10个词典,其覆盖率分别为10%,20%,…,100%.图3显示了模型对不同词典的分词性能.随着词典覆盖率的增加,分词性能得到进一步的提升.因此,构建合适的词典对文中所提模型是非常重要的.
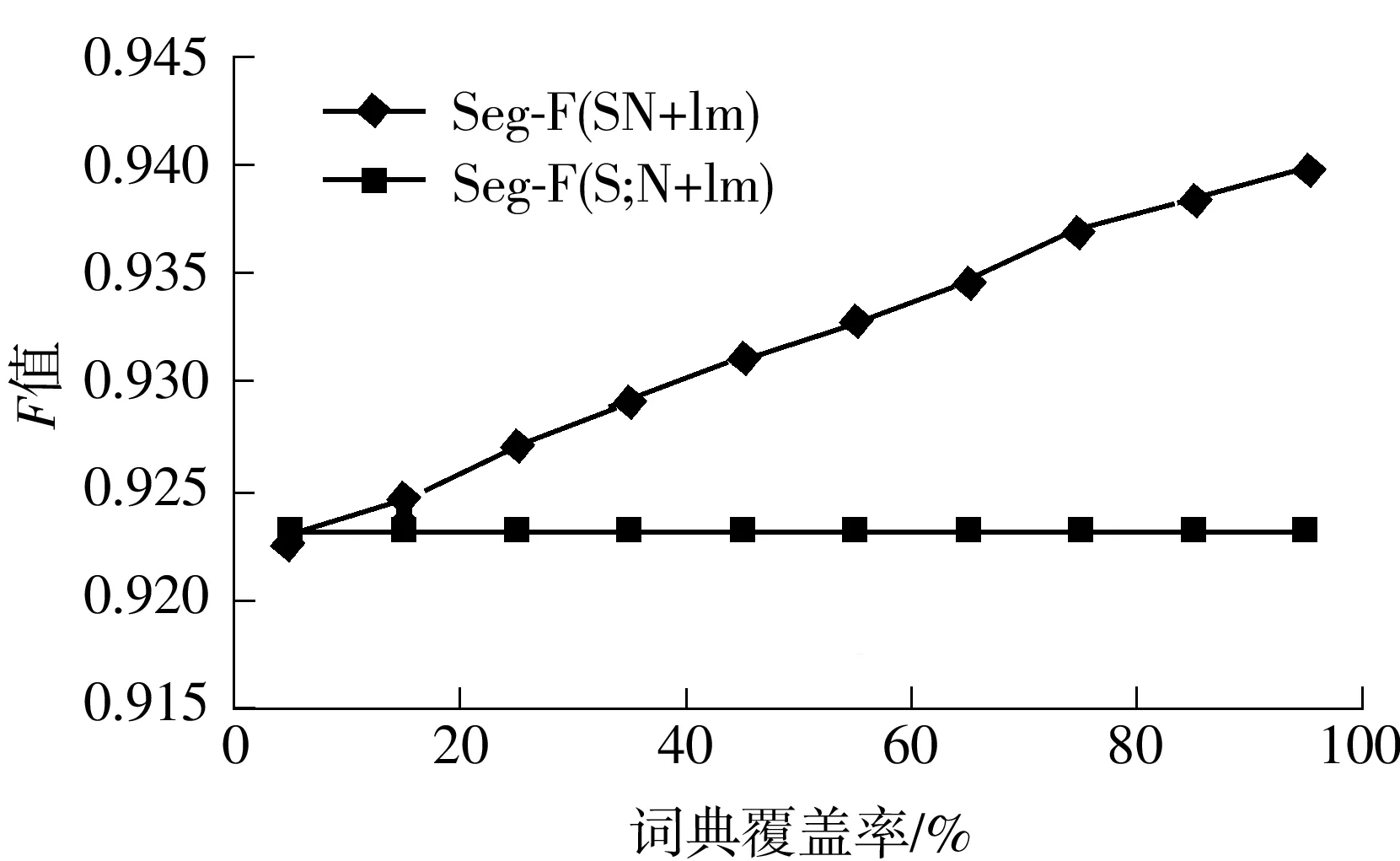
图3 开发集采用不同覆盖词典的分词F值
Fig.3Fvalue of segmentation with different cover word dictionaries on development set
4.5 测试集结果
表4给出了在测试集上的实验结果,它验证了4.4节的结论:联合模型的性能要比Pipe-Line模型的高.比较实验结果,在CTB+微博训练模型基础上,采用语言模型特征后,联合模型的分词错误率比Pipe-Line模型的减少了10.35%.
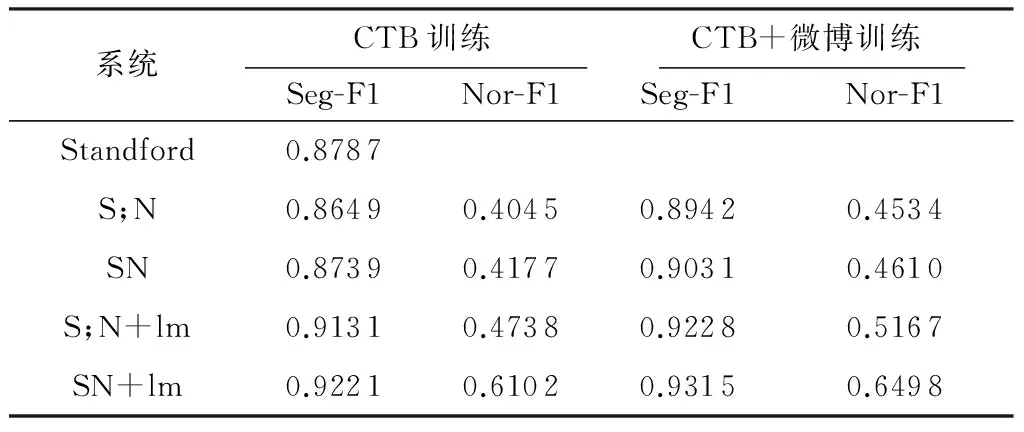
表4 测试集结果
从开发集及测试集结果可以看出,直接采用标准文本进行训练时,文中所提联合模型能提高分词性能;实验结果也显示,采用标准文本及少量的微博文本进行训练,模型的域适应性更好.这说明了微博标注语料在微博分词模型学习中的重要性.
4.6 错误分析
对于存在于规范词典中的非规范词,主要存在以下两类错误:
(1)对于一对多的词容易产生分词错误.例如:美偶-美国偶像.由于“美国偶像”包含两个词“美国”和“偶像”,在将“美偶”规范化为“美国偶像”时,没有作进一步分词处理.
(2)数字音借词识别错误.例如,“7456”在上下文中应规范化为“气死我了”,但被识别为数字.这类错误是非常难避免的,识别时需要更多的上下文信息.
5 结语
文中提出了一个基于迁移的分词和规范化联合模型,该模型能有效利用标准的标注语料进行训练,克服了缺少语料的问题.使用两类特征对模型打分,其中规范文本特征作为公共特征,非规范文本作为域特征,自然地实现了特征扩充,使模型具有较好的域适应性.实验结果显示,联合模型能使两个任务彼此受益,且语言统计特征的采用有助于提高模型的性能.该模型性能依赖于所构建的非规范词典,今后拟将进一步研究如何有效地扩充词典.
[1] Foster Jennifer,Cetinoglu Özlem,Wagner Joachim,et al.#hardtoparse:POS tagging and parsing the twitter-verse [C]∥AAAI 2011 Workshop on Analyzing Microtext.San Francisco:AAAI,2011:20- 25.
[2] Gimpel Kevin,Schneider Nathan,O’Connor Brendan,et al.Part-of-speech tagging for twitter:annotation,features,and experiments [C]∥Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics.Portland:ACL,2011:42- 47.
[3] Xi Ning,Li Bin,Tang Guangchao,et al.Adapting conventional Chinese word segmenter for segmenting micro-blog text:combining rule-based and statistic-based approaches [C]∥Proceedings of the Second CIPS-SIGHAN Joint Conference on Chinese Language Processing.Tianjin:ACL,2012:63- 68.
[4] Duan Huiming,Sui Zhifang,Tian Ye,et al.The cips-sighan CLP 2012 Chinese word segmentation on microblog corpora bakeoff [C]∥Proceedings of the Second CIPS-SIGHAN Joint Conference on Chinese Language Processing.Tianjin:ACL,2012:35- 40.
[5] Pennell L Deana,Liu Yang.Normalization of informal text [J].Computer Speech & Language:2014,28(1):256- 277.
[6] Contractor Danish,Faruquie A Tanveer,Subramaniam L Venkata.Unsupervised cleansing of noisy text [C]∥Proceedings of the 23rd International Conference on Computational Linguistics.Beijing:ACL,2010:189- 196.
[7] Li Zhifei,Yarowsky David.Mining and modeling relations between formal and informal Chinese phrases from web corpora [C]∥Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing.Hawaii:ACL,2008:1031- 1040.
[8] Wang Aobo,Kan Min-Yen,Andrade Daniel,et al.Chinese informal word normalization:an experimental study [C]∥Proceedings of the Sixth International Joint Conference on Natural Language Processing.Nagoya:Asian Federation of Natural Language Processing,2013:127- 135.
[9] Wang Aobo,Kan Min-Yen.Mining informal language from Chinese microtext:joint word recognition and segmentation [C]∥Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics.Sofia:ACL,2011:731- 741.
[10] Kaji Nobuhiro,Kitsuregawa Masaru.Accurate word segmentation and pos tagging for Japanese microblogs:corpus annotation and joint modeling with lexical normalization [C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing.Doha:ACL,2014:99- 109.
[11] Hal Daumé III.Frustratingly easy domain adaptation [C]∥Proceedings of the 45th Annual Meeting of the Asso-ciation for Computational Linguistics.Sofia:ACL,2007:256- 263.
[12] Zhang Y,Clark S.Chinese segmentation with a word-based perceptron algorithm [C]∥Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics.Sofia:ACL,2007:840- 847.
[13] Collins Michael.Discriminative training methods for hidden Markov models:theory and experiments with perceptron algorithms [C]∥Proceedings of the 2002 Confe-rence on Empirical Methods in Natural Language Processing.Danfo:ACL,2002:1- 8.
[14] Collins Michael,Roark Brian.Incremental parsing with the perceptron algorithm [C]∥Proceedings of the 42nd Meeting of the Association for Computational Linguistics.Barcelona:ACL,2004:111- 118.
A Transition-Based Word Segmentation Model on Microblog with Text Normalization
QianTao1JiDong-hong1DaiWen-hua2
(1.Computer School,Wuhan University,Wuhan 430072,Hubei,China;2.College of Computer Science and Technology,Hubei University of Science and Technology,Xianning 437100,Hubei,China)
Traditional word segmentation methods fail to achieve good performance on microblog texts,which can be attributed to the lack of annotated corpora and the existence of a large number of informal words.In order to solve the two kinds of problems,a joint model of word segmentation and text normalization is proposed.In this model,on the basis of the transition-based word segmentation,the texts are normalized by extending transition actions and then the words are segmented on the normalized texts.By experiments,the proposed model is trained on both a large number of annotated standard corpora and a small number of microblog corpora.The results show that the proposed model is of better domain adaptability,and it reduces the error rate of word segmentation by 10.35% in comparison with traditional methods.
word segmentation;text normalization;domain adaptation;transition-based model;microblog
2015- 06- 11
国家自然科学基金重点资助项目(61133012);国家自然科学基金资助项目(61173062,61373108);国家社会科学基金重点资助项目(11&ZD189) Foundation items: Supported by the Key Program of National Natural Science Foundation of China(61133012),the National Natural Science Foundation of China(61173062,61373108) and the Key Program of National Social Science Foundation of China(11&ZD189)
钱涛(1975-),男,博士生,现任职于湖北科技学院,主要从事自然语言处理研究.E-mail: taoqian@whu.edu.cn
† 通信作者: 姬东鸿(1967-),男,教授,博士生导师,主要从事计算语言学、机器学习研究.E-mail: dhj@whu.edu.cn
1000- 565X(2015)11- 0047- 07
TP 391
10.3969/j.issn.1000-565X.2015.11.007
猜你喜欢
文苑(2019年24期)2020-01-06 12:06:50
智富时代(2019年6期)2019-07-24 10:33:16
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生·天天向上(2016年9期)2016-11-22 09:10:34
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
