
一种基于决策树的位置隐私保护方法①
2015-04-14 08:06杨松涛孟凡波
佳木斯大学学报(自然科学版) 2015年6期
杨松涛,孟凡波,焦 博
(佳木斯大学信息电子技术学院,黑龙江 佳木斯154007)
0 引 言
基于位置的服务(Location Based Services,LBS)是依赖于移动用户位置的典型应用.LBS 建立了一个机制和平台,整合分布在人们周围的零散数据,并在这个平台之上实现了更多的应用.例如:基于位置的物流运输、娱乐和购物;位置感知的紧急救援、商业广告的精确投放等.当用户体验LBS的时候,必须提交三个敏感信息:位置、时间和查询内容.如果LBS 服务器是不可信的,这些数据可能涉及用户敏感的隐私问题.位置隐私问题被公认为阻碍LBS 被广泛接受和应用的主要原因[1].个性化位置k-匿名模型允许用户自由调整个人隐私要求和最大时空容忍度,同时缩小了匿名集的势.一些研究进一步分析了用户隐私需求并提出了位置多样性、查询多样性和语义多样性等概念.位置模糊技术[8]是故意降低用户位置的分辨率来保护用户位置隐私,低空间分辨率位置造成了LBS 提供粗粒度的服务.位置模糊技术和位置k-匿名技术是相辅相成的,近年来的一些研究方法[2]结合了位置模糊和k-匿名技术,同时保护位置隐私和查询隐私.位置数据精度越高,依赖位置提供的服务越精确,而用户的隐私保护程度就越低.从主次关系角度来说,保证位置数据的可用性是基于位置服务首先要考虑的.但是,在保证数据可用性的前提下,设计合理的隐私保护方法是非常必要的.本文主要关注数据可用性与隐私保护间之间矛盾,提出基于决策树的位置匿名方法.
1 系统模型
中心服务器结构在大量的隐私保护方案中得到应用并证明了它的有效性,主要具有以下优点:(1)切断了查询位置与查询内容之间的直接联系;(2)减轻了移动客户端的计算负载;(3)屏蔽查询者的身份标识(例如:IP 地址和MAC 地址).因此,本文设计了一个基于中心服务器结构的位置隐私保护模型,此模型满足查询匿名性和位置轨迹不可追踪性.图1 显示了系统模型中的实体及它们之间的交互.这里有4 个关键部件:定位系统服务器,移动终端(MC)、位置匿名服务器(LAS)和LBS 服务器(LBSS).
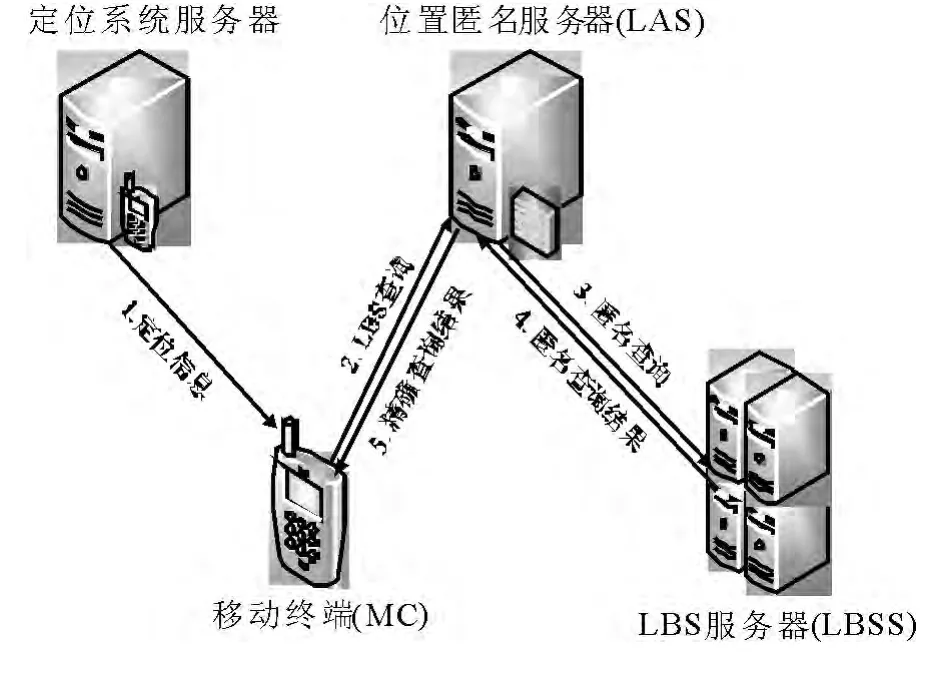
图1 系统模型
图1 所示的系统模型中,LBSS 在严格执行协议和算法的前提下,同时使用收集到的位置信息和背景知识推断用户的敏感信息,为了商业目的,LBSS 可能出卖用户的敏感信息给不友好的第3方.本文确定了4 个基本假设如下:
假设1 LAS 和MC 是完全可信的.LBSS 是半可信的,一方面为用户提供服务,另一方面有可能直接或间接地泄露用户的隐私信息;
假设2 攻击者可以从公共数据库(例如:电话黄页,家庭住址等)获得一些先验知识.同时,攻击者具备较强的统计分析和推理能力,可以利用查询信息和先验知识形成后验知识;
假设3 MC 在LAS 上注册为合法用户,定期向LAS 更新其位置信息;
假设4 LAS 使用的匿名算法是公开的.
定义1 查询匿名性.匿名的本意是指在同一匿名集(AS)内的主体是不可区分的.相对攻击者而言,主体没有唯一的特征标识.匿名不是保护某一具体的主体标识,而是使攻击者不能建立主体与其行为动作的联系.匿名集的量化需要一个阈值k代表匿名度,k 在一般意义下等于匿名集的势|AS|,k 值越大,匿名效果越好.
定义2 轨迹不可追踪性.位置轨迹可以表示为T = {Ti,(x1,y1,t1),(x2,y2,t2),…,(xn,yn,tn)},其中,Ti表示该轨迹的标识符,(xi,yi,ti)(i=1…n)表示移动对象在时刻ti的位置为(xi,yi),ti为采样时间.轨迹不可追踪性是指LBSS 通过已有的先验、查询日志和候选结果集等信息,分析出用户位置轨迹的概率很低.
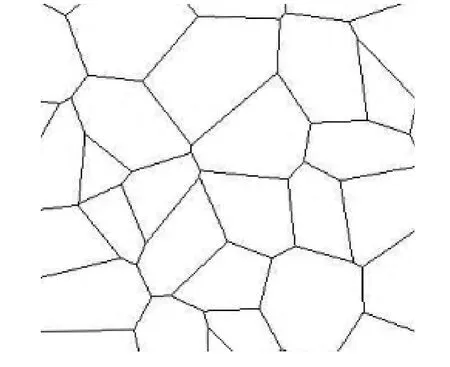
图2 Voronoi 图GV
2 决策树匿名
本文将LBS 服务空间映射为Voronoi 图GV,GV中的每个单元格cell 覆盖一个语义位置,同时每个cell 对应一个语义位置编号No.如图2 所示,查询用户的当前cell 是指包含用户当前位置的语义位置,设移动用户u 当前位置为l,则该用户的当前cell 被定义为current-C(l)=Ni.LAS 和LBSS 共享GV的信息.LAS 通过GV构建匿名决策树,实现位置k-匿名和位置l-多样性.
定义3 匿名查询请求(Q),查询用户发出的LBS 匿名查询请求可以形式化为:
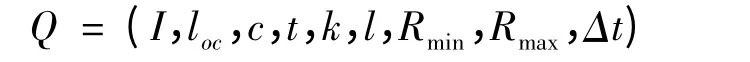
式中:I 代表用户的身份标识;loc代表用户当前位置;c 代表查询内容;t 代表查询时间;k 代表匿名度;l 代表位置的多样性;Rmin和Rmax分别代表最小和最大容忍区域;Δt 代表查询容忍时间.在查询过程中,用户通过共享loc和c 来获得相应的服务,k,l保障了用户的隐私安全,Rmin,Rmax和Δt 保证了服务质量.
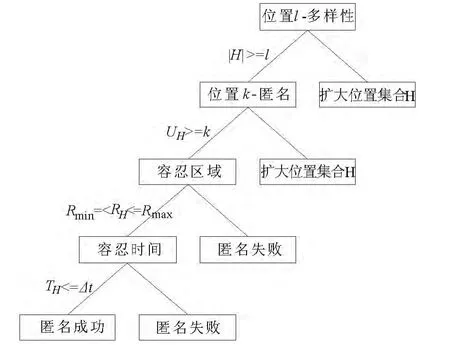
图3 匿名决策树
定义4 语义位置(Semantic location,S),语义位置是一个位置范围的描述,形式化为:
新世纪以来,中国政府在扶贫领域进一步加强了与全球减贫的“互动”交流。2004年5月,首次“全球扶贫大会”在我国上海召开,来自120余个国家和地区的代表在此次大会上交流扶贫经验,并共同签署了《上海减贫议程》,这进一步增强了国际社会的减贫共识。2005年5月,中国国际扶贫中心成立,这一机构架起了我国与国际组织扶贫合作与交流的重要平台。2015年9月,在联合国发展峰会上通过了一份关于全球减贫的新计划——《2015年后发展议程》。
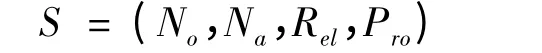
式中:No代表语义位置编号;Na代表语义位置的名称;Rel代表与该语义位置相邻的其他位置集合;Pro代表该语义位置的几何物理特性的集合,包括形状、大小、面积等信息.
为了便于表示决策树规则,本文使用H ={S1,S2,…,Sn}代表语义位置的集合,UH代表当前语义位置集合内的移动用户数量,RH代表该语义位置集合所围成的区域面积,TH代表该位置语义集合的平均查询时间.图3 描述了匿名决策树,该决策树从位置l-多样性、位置k-匿名、查询容忍区域、查询容忍时间4 个方面来决定匿名是否成功.
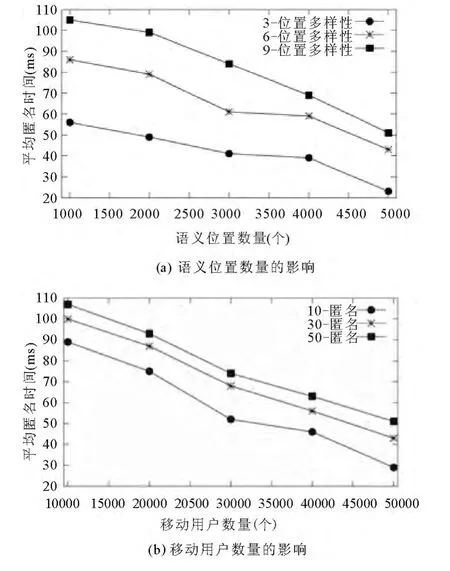
图4 平均匿名时间
基于决策树的位置匿名在LAS 内完成,具体过程如下:
(1)从Q 中提取参数loc,k,l,Rmin,Rmax,Δt;
(2)计算current-C(loc)=No,并将No加入H;
(3)判断是否满足位置l-多样性要求,如果|H|>=l,则执行下一步,否则,从No临近的语义位置中随机选择l-1 个语义位置加入H;
(4)判断H 所在区域内是否存在大于k 个用户,如果UH>=k,则执行下一步,否则,从No的临近位置中选择1 个语义位置增加到H 中,重复执行(4);
(5)判断RH是否符合容忍区域要求,如果Rmin=<RH<=Rmax,则执行下一步,否则,匿名失败;
(6)判断TH是否符合容忍时间要求,如果TH<=Δt,则匿名成功,否则,匿名失败.
查询内容语义的相似性有利于提高LBSS 的检索效率,但是,单一的查询内容可能导致查询同质攻击,即LBSS 虽然不能确定查询的发出者,但是,其根据查询候选结果集可以断定查询用户所关注的兴趣点(Points of Interest,POIs).本文为了满足查询语义的q-多样性,LAS 随机产生q-1 个不同的查询内容,连同原始查询内容构成查询内容集合.
3 分析与验证
3.1 隐私性分析
特定的隐私保护模型仅在特定的场景下成立,当攻击者具有足够多的先验知识的情况下,隐私可能泄露.查询匿名性、位置轨迹不可追踪性是度量隐私保护水平的主要指标,相关的研究工作主要是围绕这2 个指标来探讨LBS 隐私保护技术的隐私保护能力.本文从这2 个指标角度分析所提出方法的抗攻击能力.
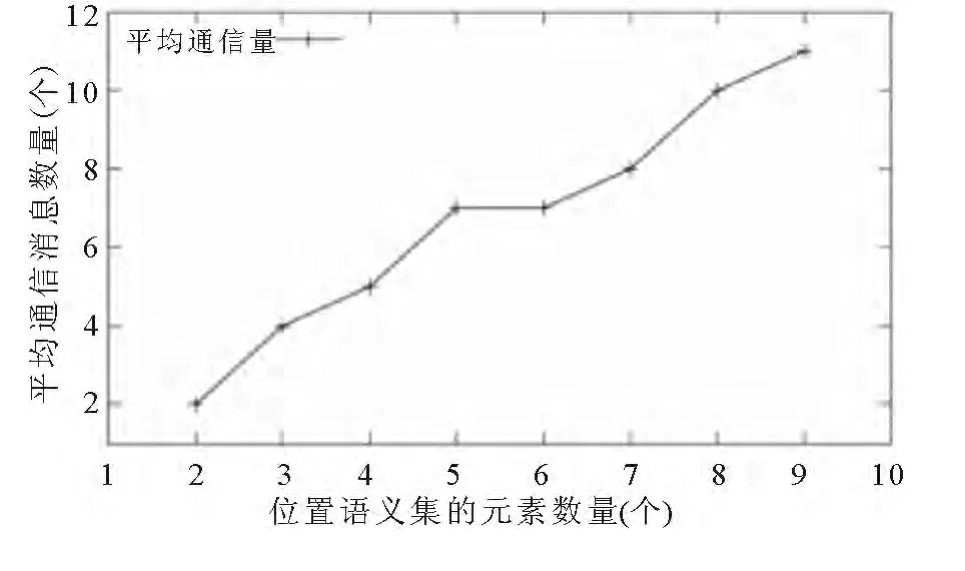
图5 平均通信量
(1)从查询匿名性分析.位置k-匿名是最流行的查询隐私度量方式,给定集合U={u1,u2,…,uk}是k 个移动用户的集合,∀ui∈U 的位置坐标位于匿名区域(Anonymous Spatial Region,ASR)内.如果攻击者确定查询q 由ui发出的概率为1/k,则称ui实现了位置k-匿名.本文方法中的H 内至少包含k 个用户,符合位置k-匿名的定义,因此本文方法具有匿名性,进而不会遭受受限空间识别攻击和观察识别攻击.同时,本文方法不仅实现了k-匿名,而且保证了查询内容的q-多样性,查询者与查询内容是多对多的关系,进而不会遭受查询同质攻击和关联攻击.
(2)从位置轨迹不可追踪性分析.位置k-匿名混淆了匿名查询和位置隐私的概念,k-匿名可以切断查询和用户身份的关联,但是无法保证用户的位置隐私和轨迹隐私.k 值的大小不依赖于k-ASR,在用户密集区域,k-ASR 可能汇聚成一点(例如:一个酒吧),在稀疏区域,k-ASR 可能很大.所以,唯一的k 值无法度量位置隐私和轨迹隐私.本文提出的匿名方法同时满足了位置k-匿名性和位置l-多样性.攻击者的最小推断区域是多个语义位置的并集,进而不会遭受位置同质攻击和推理攻击.
3.2 实验验证
本文算法采用C#实现,在Intel(R)Core(TM)i3-2310M CPU 2.10GHz 处理器、4GB 内存的Windows 7 平台上运行.模拟数据集由业界认可的Thomas Brinkhoff 路网数据生成器生成,以城市Oldenburg 的交通路网作为输入,生成模拟的移动用户数据集.我们在模拟数据集上对本文方法的平均匿名时间、平均通信量进行实验.
平均匿名时间主要受到语义位置划分的精细程度、匿名度k 和移动用户数量的影响,图4(a)显示语义位置数量影响匿名时间,语义位置数量越多越容易满足位置l-多样性要求,匿名时间越短.图4(b)显示移动用户数量与匿名时间成反比,移动用户数量越多越容易实现k-匿名,匿名时间越短.同时,从图4(b)可以看出,匿名度k 与匿名时间成反比,即k 越大,则匿名时间越长.
平均通信量主要受到位置l-多样性和查询q-多样性的影响.我们假设查询语义的q-多样性数量在1 到2* |H|内随机选取,每个POIs 消息是100kB.图5 显示用户隐私要求越高,平均通信量越大.
4 结束语
大量的位置隐私研究工作基于“零和博弈”的观点,提出了权衡服务质量和隐私保护的方法,其中位置k-匿名、位置模糊是位置隐私研究的主流技术.综合考虑个性化匿名查询中的各种影响因素,提出了基于决策树的匿名方法,实现了个性化匿名查询.隐私性分析表明方法具有查询匿名性和位置轨迹不可追踪性,并且具有一定的抗攻击能力.实验结果验证了方法的平均匿名时间和平均通信量较低,可以满足LBS 即时服务的要求.但是,随着用户隐私要求的提高,匿名成功率下降明显,有待于在后续研究中进一步完善.
[1] 王璐,孟小峰.位置大数据隐私保护研究综述[J].软件学报,2014,25(4):693-712.
[2] 杨松涛,马春光.随机匿名的位置隐私保护方法[J].哈尔滨工程大学学报,2015,36(3):1-5.
猜你喜欢
自动化学报(2021年8期)2021-09-28
爱你(2018年16期)2018-06-21
山东青年(2016年10期)2017-02-13
现代商贸工业(2016年22期)2016-12-27
电脑知识与技术(2016年25期)2016-11-16
新闻世界(2016年8期)2016-08-11
指挥与控制学报(2015年4期)2015-11-01
金融理财(2015年7期)2015-07-15
河南科技(2014年5期)2014-02-27
中国广播(2014年1期)2014-01-20
