
一种适用于微博主题提取的SMLDA模型
2015-04-01 03:25:12华绿绿黄廷磊刘久云夏威
桂林电子科技大学学报 2015年3期
华绿绿,黄廷磊,刘久云,夏威
(桂林电子科技大学 计算机科学与工程学院,广西 桂林541004)
随着网络空间数据量越来越庞大,人们随时都会淹没在数据中,很难快速地找到有价值的信息,导致未能制定合适的决策。数据挖掘成为社会各个领域的需求。近年来,新浪微博社交网络依靠LDA模型[1]对瞬间产生的大量数据进行一个主题挖掘工作。然而,新浪微博数据具有信息简短、不受时空限制、信息量大、更新传播速度快等特征,这给传统的LDA模型带来一定的困难[2]。
目前,针对英文微博环境下的主题提取模型已有较多研究,但针对于中文微博的主题提取模型仍处于初步阶段。Weng Jianshu等[3]为了发现有关敏感性主题的权威博主,采用先聚类后通过LDA模型建模方法;作者主题模型[4](author topic model,简称ATM)是LDA的一种扩展模型,其引入了文章的作者信息,对于简短微博而言,LDA模型处于劣势;Zhao等[5]对ATM模型进行了扩展,提出了Twitter-LDA模型,它与ATM模型的主要区别是,Twitter-LDA不仅可在微博用户层面进行主题建模,而且可针对一条微博进行建模;Labeled-LDA[6]一定程度上降低了微博文本语法不规范的干扰。张晨逸等[7]基于LDA提出一种MB-LDA(micro blog latent dirichlet allocation)模型,它引入了微博文本之间的相关性和用户之间的相关性。中文微博和外文微博除了文字字符不同外,在功能上也有差异。谢昊等[8]针对中文微博提出了一个RT-LDA模型,不仅考虑博主和转发信息的主题关联性,还添加了背景主题。冯普超[9]针对中文微博提出了一种基于CMBLDA模型的微博主题挖掘,融入了4种类型微博特点。鉴于前期研究者的经验和新浪微博的数据特征,提出一种SMLDA(Sina microblog latent dirichlet allocation)模型,在加入背景主题的同时添加新浪微博特定主题标签关系,通过调整处理顺序,采用吉布斯抽样算法[10]进行主题提取。
1 LDA模型概述
传统的LDA模型的主要思想为:对于给定的一个文档集,主题模型认为每个文档包含了若干个主题的概率,而每个主题又由很多词语构成,形成了一个多项式分布,不同的主题在文档上的分布也不同[11]。在这个框架中,文档主题都是潜在变量,而文本中所有词语是可见的。生成一个文档时,其中词的概率分布式为:

LDA是第一个完备的主题模型,它在文档-主题、主题-词语这2个层级进行建模,并以概率分布表示建模过程,其目的是为了得到θ(包含参数α的狄利克雷分布)和φ(包含参数β的分布)。联合概率分布可表示为:
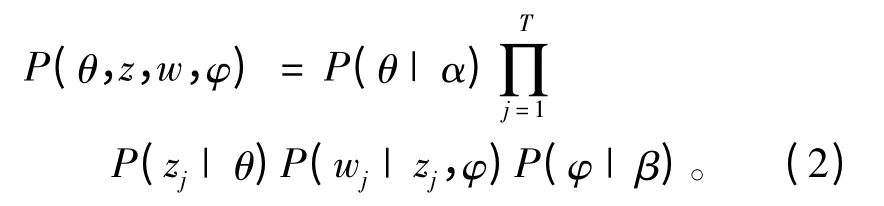
其中条件概率表明了变量之间的依赖关系。为了合理设计算法,可使用概率图简化模型。LDA的Bayesian网络如图1所示。

图1 LDA模型的Bayesian网络Fig.1 Bayesian network of LDA
2 SMLDA模型
2.1 SMLDA模型的生成过程
微博文本与传统文本有着显著的不同。微博文本信息中带有“@”、“#”和“转发”这类信息。“@用户”代表微博作者之间具有关联关系,一般而言,带有“@”标签的微博就是与被@作者的微博主题具有较强的相关性;“转发”就是用户可转发别人的微博,可加评论,因而2条微博之间相互关联;“#主题#”是指微博文本的特定主题的标签。如“为所有遇难者默哀#雅安地震#”,这就是有关雅安地震的主题。根据微博信息的特征,SMLDA模型通过加入微博作者之间关系以及特定主题的标签与微博文本之间的关联关系,运用Gibbs抽样算法进行主题提取。SMLDA模型的Bayesian网络如图2示。
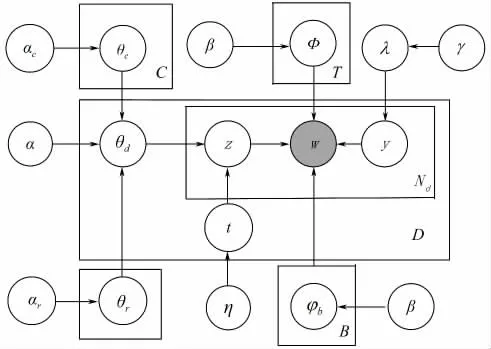
图2 SMLDA模型的Bayesian网络Fig.2 Bayesian network of SMLDA
SMLDA模型的生成过程如下:
1)任意选择某个有关主题-词语的分布φ,生成φb~D(β)分布,其中φb为背景主题,而且生成λ~D(γ)分布。
2)假设数据集包含T个主题,首先生成关于主题的分布φ~D(β)。
3)SMLDA生成1条微博时,因为有些转发微博和原创微博正文均有带“#”的主题,所以考虑特定标签“#”的文本,而转发微博内容又带有回复“@”的对话性质微博(专门评论回复而不转发的数据“转发”),若有,则为转发微博信息,θr为转发部分和主题之间的分布,r取值为1,从αr中抽取出θr并赋值给θd,否则r取值为0,继续判断是否含有“@”,若有,则πc=1,其描述1个“@”类型的微博(对话性质和“@”用户的微博),然后获取θc有关参数αc的分布并赋值给θd,若无,则πc=0,直接获取θd~D(α)。微博中关于主题的θ分布为:
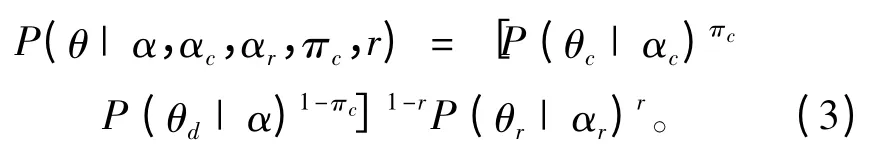
继续判断是否含有“#主题#”,若有,则从包含参数η的Bemoulli分布中获取t,从而确定是从θt还是从θd中提取当前词所属的主题zd,i;若无,则t取值为0,直接从θd获取当前词所属的主题zd,i。微博中关于主题的θ分布式为:
4)确定主题分布后,就需要判断词应该选什么主题,这由y决定,当它的值等于0时,选择从φb中获取,反之,从φzd,i中抽取具体词汇wd,i。
在一个新浪微博文本当中,其文档中的词和其对应主题的联合分布可表述为:

2.2 Gibbs算法
文本SMLDA方法为了得到词语的相关概率分布,可直接计算词语-主题的后验概率,并采用Gibbs抽样算法推导得到φ和θ的值[12]。Gibbs抽样算法是一种简单高效的MCMC(markov chain monte carlo)抽样方法,其每次采样均以随机变量的后验分布代替当前的分布,并用于下一次采样,如此重复采样迭代,最终使随机变量收敛。后验分布可用式为:
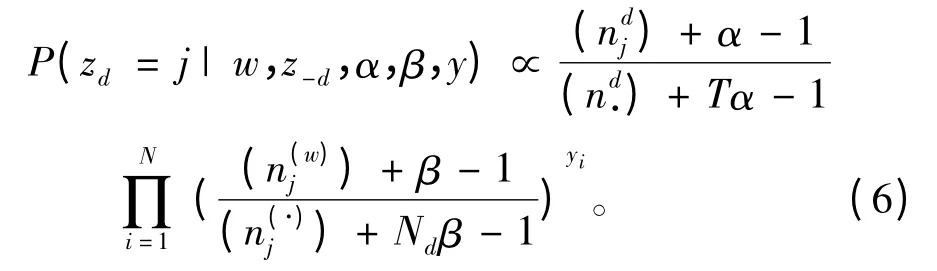
进行实验时,对式(6)重复迭代抽样,最后达到稳定状态,就可评估φ和θ的值:

其中:w为唯一词汇;为主题j的总词语数;为词语w在主题j的总数目;为某个文档d中主题j总词语数;为文档d中有归属主题的词语数。
3 实验分析
3.1 实验简介
为了更好地对微博文本进行建模,获取文本数据很重要。实验所采用的数据集从新浪微博的数据堂网站上消费获取,涵盖6万多个微博博主所发布的信息,内容包括6万名新浪微博的用户信息、2014年4月29日至5月12日的8万多条数据(包括12个主题)和139万条用户间的关注关系,通过前期对微博数据集进行中文分词、去噪等预处理工作,选取了其中的4万条数据进行实验。
3.2 性能评估指标
主题模型通常采用perplexity[13]来衡量其性能。perplexity表示不确定度,值越大,说明该模型性能越差,不确定性就越强;相反,值越小,性能越好。Perplexity的计算公式为:

其中:Mt为测试的数据文档集;wm为数据文档集中可直接看到的词语;Nm为文档m所具有的词总数。
3.3 实验结果分析
本实验建模过程中,根据已有经验[14],参数值设为α=1,β=0.01,αc=αt=1,γ=0.5,αr默认为1,描述的是转发微博主题与原创微博主题的完全相关性。
每篇文档中的词用空格分开。模型得到的数据有6个输出文件,文件说明如表1所示。

表1 SMLDA训练结果文件说明Tab.1 The introduction of SMLDA’s training result files
3.3.1 主题提取结果
采用SMLDA方法对微博数据集进行实验操作,获取有关12个主题的实验结果。由于主题数目及其概率分布较多,挑选出前3个比较热门的主题,主要包含每个主题下其概率排在前8的关键词。3个主题及其前8个词语的分布情况如表2所示。
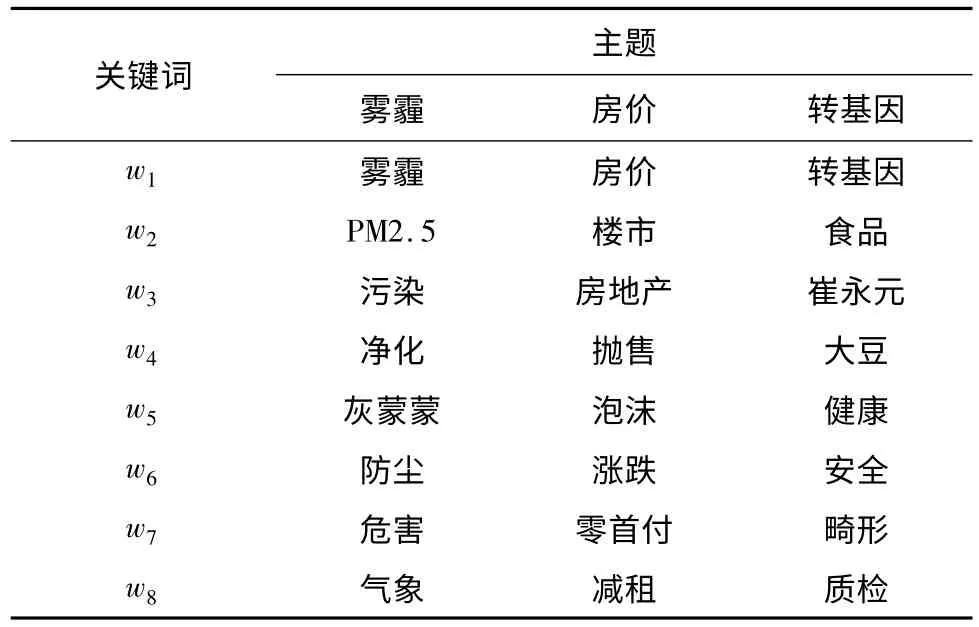
表2 3个主题及其前8个词语分布情况Tab.2 3 hot topics and 8 key words
3.3.2 实验结果对比
主题雾霾一直是大家关注的热点,为此,分别对SMLDA和LDA模型提取的主题雾霾的结果进行对比分析,提取结果如表3所示。从表3可见,同样是前8个关键词及其相对应的概率值,概率越大,说明词和主题的相关性越强。相对LDA模型,SMLDA提取的关键词和概率准确率更高,更适用于微博短文本的主题提取。
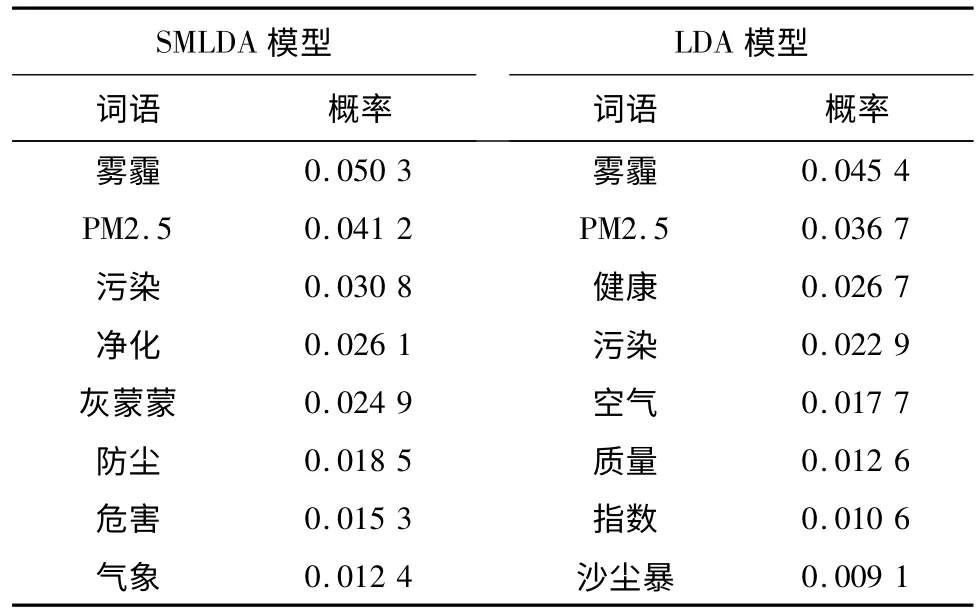
表3 2个主题模型对雾霾的提取结果Tab.3 Fog extraction results of 2 topic models
困惑度是衡量一个模型性能好坏的另一指标。在参数值设置相同的情况下,分别对LDA和SMLDA模型的困惑度进行比较,观测其取值的变化情况,比较结果如图3所示。从图3可见,当迭代次数逐渐上升时,2种模型的困惑度都在慢慢减小;在实验迭代次数相同时,SMLDA模型的困惑度值比LDA模型的小,说明其主题提取整体效果更好,更适用于短文本式的新浪微博。
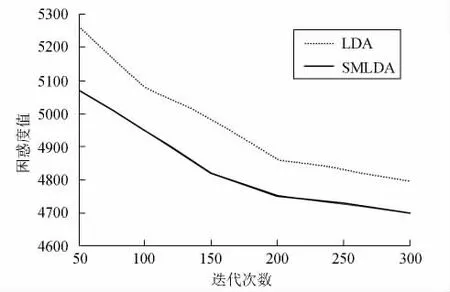
图3 2个模型的困惑度比较Fig.3 The perplexity of two models
4 结束语
根据新浪微博自身的数据特点,加入微博用户之间的相关关系、特定主题以及转发内容和背景主题,建立一种适用于中文微博的主题提取方法,即基于传统的LDA模型改进的SMLDA模型,并通过Gibbs抽样算法对数据集进行试验。实验结果表明,SMLDA模型对于中文新浪微博的主题提取效果更佳。后续研究可继续优化SMLDA模型,并利用该模型为微博数据进行文本表示,引入SVM算法,对微博文本进行主题分类处理,以提高其分类性能。
[1]Blei D,Ng A,Jordan M.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003(3):993-1022.
[2]Hong Liangjie,Davison B.Empirical study of topic modeling in Twitter[C]//Proceedings of the First Workshop on Social Media Analytics.New York:ACM Press,2010:80-88.
[3]Weng Jianshu,Lim Ee-Peng,Jiang Jing,et al.Twitterrank:finding topic-sensitive influential Twitterers[C]//Proceedings of the 3rd ACM International Conference on Web Search and Data Mining.New York:ACM Press,2010:261-270.
[4]Zvi M,Griffiths T,Steyvers M,et al.The author-topic model for authors and documents[C]//Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence.Arlington:AUAI Press,2004:487-494.
[5]Zhao W X,Jiang Jing,Weng Jianshu,et al.Comparing Twitter and traditional media using topic models[C]//Proceedings of the 33rd European Conference on Information Retrieval.Berlin,Heidelberg:Springer-Verlag,2011:338-349.
[6]Ramage D,Dumais S,Liebling D.Characterizing micro blogs with topic models[C]//Proceedings of International AAAI Conference on Weblogs and Social Media.Menlo Park.CA:AAAI,2010:130-137.
[7]张晨逸,孙建,丁轶群.基于MB-LDA模型的微博主题挖掘[J].计算机研究与发展,2011,48(10):1795-1802.
[8]谢昊,江红.一种面向微博主题挖掘的改进LDA模型[J].华东师范大学学报:自然科学版,2013,11(6):93-100.
[9]冯普超.基于CMBLDA的微博主题挖掘[D].杭州:浙江大学,2014:37-47.
[10]Philip R,Eric H.Gibbs sampling for the uninitiated[R].Technical Reports from UMIACS,2010.
[11]Griffiths T,Steyvcrs M.Probabilistic topic models[C]//Latent Semantic Analysis:A Road to Meaning.Hillsdale.NJ:Laurence Erlbaum,2004:5221-5228.
[12]Blei D,Lafferty J.Visualizing topics with multi-word expressions[J].Statistics,2009:1050-1055.
[13]Griffiths T L,Steyvcrs M.Finding scientific topics[J].Proc of the National Academy of Science of the United States of America,2004,101(S11):5228-5235.
[14]Guo Xin,Xiang Yang,Chen Qian,el al.LDA-based online topic detection using tensor factorization[J].Journal of Information Science,2013,39(4):459-469.
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19 18:09:52
读者(2021年20期)2021-09-25 20:30:35
中国新闻周刊(2021年26期)2021-07-27 04:02:12
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
阅读时代(2017年3期)2017-03-11 07:24:51
信息安全研究(2016年4期)2016-12-01 06:06:54
校园英语·下旬(2016年2期)2016-03-18 10:23:20
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
快乐作文·低年级(2014年10期)2015-01-14 23:43:55
电脑迷(2012年4期)2012-04-29 06:12:13
