
纳米出版物语义模式及其与知识发现的关系
2015-03-22 05:33:16,
中华医学图书情报杂志 2015年12期
,
随着网络信息技术、数据存储处理技术的快速发展,科学文献数量呈指数级增长态势,急需探索一种能够体现语义关联的新表达模式。这项工作受到了语义组织、语义关联研究专家的重视。英国皇家化学学会的“Prospect”项目启发专家开始探索不同于传统语义表达的新模式,经过对荷兰的“Article of the Future”、美国的“OpenMath”[1]等项目的跟进研究,最终由70多人组成的语义专家联盟——概念网络联盟于2009年明确提出Nanopublication的概念是一种新的语义表达模式,其借助计算机程序可以实现语义的新标注、再组织,是一种新语义表达模式[2]。
1 Nanopublication的概念
“Nanopublication”与纳米科技并无相关,只是取纳米的微小之意,表示一种遵守语法规则、可以通过机器输入、识别、处理、输出的不可拆分的最小出版信息元[3]。纳米出版物与传统出版物是相同事物的不同表达,前者应用机器语言,后者应用自然语言,是一种新的语义表达。Nanopublication将传统出版物模型化为ID、结论(As)、属性(At)、密钥(Ik)四要素。其中“ID”唯一识别一“本”Nanopublication,“结论”是体现Nanopublication的核心要素,“属性”要素包含支撑信息(Si)和出处(Pr)两个数据项,“密钥”约束控制数据相容有效,ID与密钥表现形式为序列码,结论与属性均为主-谓-宾格式的三元组。模型结构如图1所示。
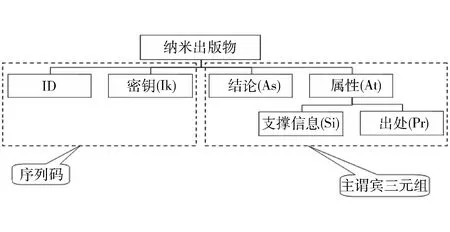
图1 Nanopublication模型结构图
其源文件类似C语言编码框架,需遵守RDF标记语言准则[4-5]。
2 Nanopublication中的知识发现
与传统出版物相比,Nanopublication更注重体现文献的细粒程度。其各要素内容与传统出版物具有一一对应关系,并将传统文献的核心内容如研究背景、研究方法、研究结论、引用文献及出版时间、出版单位等进行提炼,并语义标注[6]结构重组,形成一组人机共识的结构化语句系列。由于文献之间的研究方法、概念原理、参考文献相互引用和相互支撑,形成Nanopublication庞大的信息元网络。面对这样的知识节点网络,研究人员可以经过发现挖掘、计量分析,推断得出新的研究线索以及新的科学结论,或者大胆提出新的研究假设。研究人员不再需要阅读大量的传统文献,仅需要将Nanopublication借助计算机运行,并结合机器可视化计算处理[7],大大加速了知识发现的速度、拓广了知识发现的广度、深化了知识发现的深度。在该信息元网络中,信息流分有向、无向两种情况,发现的知识也相应不同。下面以具有5个信息元(用字母U表示)的信息流网络图分别讨论。
2.1 信息有向图
信息有向图中信息元之间由弧(即箭头“→”)连接,箭头方向的一端为弧头,另一头为弧尾,信息流的方向为弧尾流向弧头,结合实际情况可以理解为弧尾信息元支撑弧头信息元,或弧头信息元引用弧尾信息元。由图2“Nanopublication信息有向图”可发现,因U1→U2,U2→U5,故沿信息流方向可推导得出U1→U5,但逆方向U5是否能够推导出U1不得而知,需要研究证明。由于信息流方向非时针方向,所以U3、U5的关系难以确定,可能出现U3→U5或U5→U3或U3、U5无关3种情况。Nanopublication有向知识发现直观解析见图3。

图2 Nanopublication信息有向图

图3 Nanopublication有向知识发现图
2.2 信息无向图
信息无向图中信息元之间由边(即直线“-”)连接(图4)。
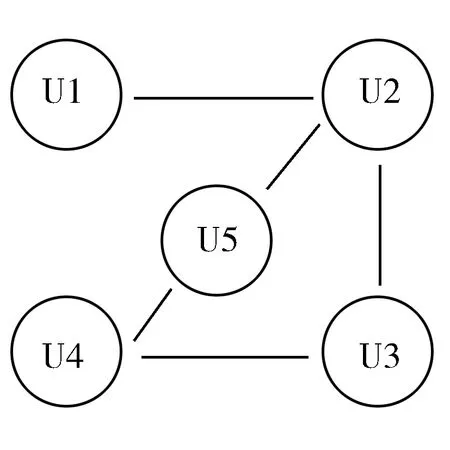
图4 Nanopublication信息无向图
图4中信息元之间的边无方向性,信息流也无方向性,两个信息元用边连接表示二者相关,或共用某个方法、理论、概念、数据。
由图4“Nanopublication信息无向图”可发现,因U1-U2,U2-U5,故通过U2可以建立U1和U5的相关性,即U1-U5,此时U1与U5的相关性不具有方向性,可以描述为U1-U5,也可以描述为U5-U1;U4-U5,U4-U3,不需考虑信息流是否满足时针方向,U4与U3、U5均相关,据无向图的特性可推导出U3、U5具有相关关系,即U3-U5。
Nanopublication的无向知识发现直观解析详见图5。

图5 Nanopublication无向知识发现图
以上的Nanopublication有向、无向图仅用5个信息元简单说明情况。实际的Nanopublication网图的信息元数量庞大,关系错综复杂,但是经过可视化处理后能够直观发现直接连接的信息元之间的关系,或者是通过有向、无向图特性挖掘,分析它们的间接相关关系。
因此,相对于传统出版物,Nanopublication的优点是可以借助机器帮助研究人员阅读处理,细化到信息元程度。这样可以扩大人工阅读数量,提高人工阅读质量,拓展人工阅读的知识范围。与传统出版物相比,Nanopublication有直观、深入、立体、简化等许多优点,让研究人员更易揭示知识间隐藏关系,或探索证明知识间的可能相关关系。
3 知识发现中的Nanopublication
3.1 知识发现与Nanopublication的产生
为解决大数据环境下知识发现、知识挖掘方面的诸多难题,数据语义领域的专家致力于研究在开放网络环境下海量数据的互操作算法。在研究中,信息专家发现数据可以构建新的结构形式,重新定义数据关系,实现新的数据组织、语义表达、出版模式,Nanopublication应运而生。
Nanopublication是针对传统文献详细、冗长、静态线性、小数据处理的弊端而发现的新知识。Nanopublication依托软件程序语言思想,遵循一定的语法规则,凭借预定义的可控词表库进行软件编码[8];借助机器实现其强大的大数据处理能力,发挥其文献参考、学术交流的核心重要作用。
3.2 知识发现与Nanopublication的改进
目前,基于Nanopublication可视化得到的均是图状结构的数据关系,当数据间的关系属于层次结构关系时,应用树型结构模型更准确。因此,需要在可视化操作的程序中加入数型结构的各类操作模块,以供程序在运行中分支调运。图状可视化结果也有一定的改进空间,如果能够在有向图的“弧”、无向图的“边”上将精缩信息以类似标“权值”的形式标注在“弧”或者“边”的旁边,会更立体、明确。
3.3 知识发现与Nanopublication的平衡发展
Nanopublication目前在医药生物领域研究较多、成果显著[9-10],但距离形成充足、成熟、规范通用的供学者广泛使用的数据资源库还有很大探索空间,需要不断研究、不断发现。另外学科发展也不均衡,人文、哲学等学科才刚刚开始探索建设词库,理工等领域还属于空白。因此,Nanopublication的进一步发展、普及都得依赖语义专家与软件专家不断的知识发现。
4 Nanopublication与知识发现的融合
Nanopublication属于语言学范畴,知识发现属于信息学范畴,从表象上不易看出二者的交集,但是通过可视化技术建立起非常紧密的联系,使二者实现了融合。从Nanopublication可以发现许多潜在知识,通过知识发现可以产生更多、更完整的Nanopublication。
Nanopublication的发展离不开知识发现,知识发现也有赖于Nanopublication的发展、普及与平衡,二者相互促进,共同发展。
Nanopublication与知识发现相融合的产物就是错综复杂的信息网图(图6),信息网图可以有效帮助人们进行信息分析、知识发现,而知识发现亦可帮助研究人员完善Nanopublication词表库、发现语法歧义、改进算法。目前国外科研机构、网络数据提供商加大发展力度,投入大量资金、人力研究Nanopublication。从事Nanopublication研究的专家开展的“知识发现”处在行业的前端,他们研发的Nanopublication数据库也越来越受到重视。
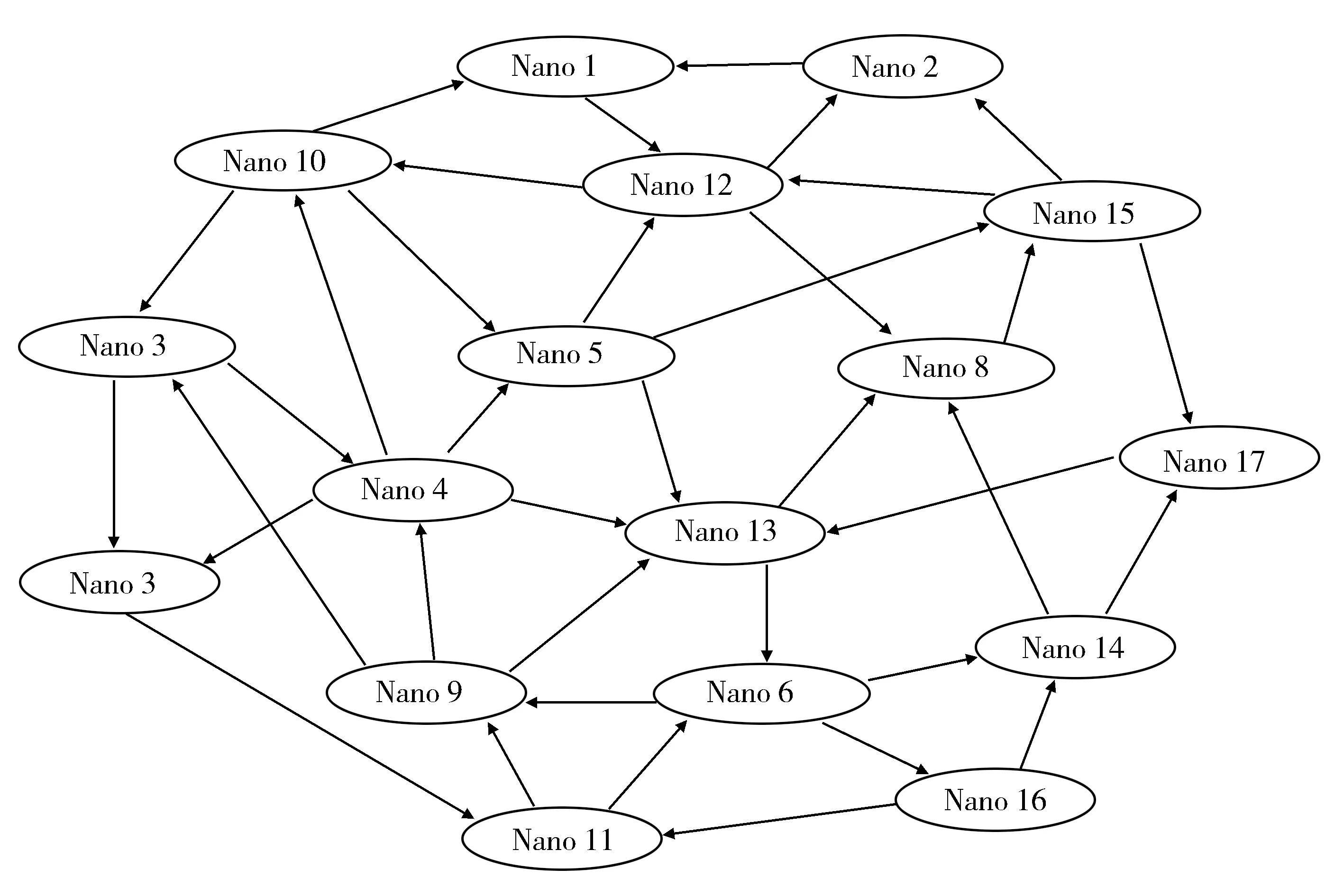
图7 Nanopublication知识网络图
5 结语
目前,由欧盟的创新药物计划基金资助、英国皇家化学学会研发的支持Nanopublication的平台系统PHACTS,可以实现Nanopublication的查询、检索、可视化聚合。该系统于2011年开始免费开放,这对Nanopublication的发展、使用将起到推动作用。
Nanopublication相互之间动态连接,若嵌入数据不规范,知识发现过程中会出现错误堆积情况,且阅读Nanopublication需要有软件程序语言基础。因此Nanopublication的普及、推广具有一定的难度,需要一定的时间。
此外,Nanopublication与传统出版物不会相互影响,相互制约,更不会取代传统出版物。二者利用自身优势服务广大信息研究人员,帮助人们进行信息分析、知识发现。
猜你喜欢
云南民族大学学报(自然科学版)(2021年3期)2021-06-24 09:07:06
军事运筹与系统工程(2020年1期)2020-09-11 06:41:08
铁道通信信号(2018年12期)2019-01-31 05:36:40
军事运筹与系统工程(2018年1期)2018-11-10 05:33:12
四川师范大学学报(自然科学版)(2018年4期)2018-07-04 11:53:22
廊坊师范学院学报(自然科学版)(2017年3期)2017-10-11 02:14:06
中国气象科学研究院年报(2017年0期)2017-07-19 09:52:42
中国学术期刊文摘(2016年8期)2016-02-13 13:04:44
中国学术期刊文摘(2016年8期)2016-02-13 13:04:44
军事运筹与系统工程(2015年3期)2015-09-08 13:12:35
