
一种基于HBase的空间关键字查询算法*
2015-03-19 00:36邵奇峰
计算机工程与科学 2015年11期
邵奇峰,李 枫
(1.中原工学院软件学院,河南 郑州450007;2.中原工学院计算机学院,河南 郑州450007)
1 引言
随着智能移动设备的快速普及,基于位置的服务LBS(Location Based Services)应用随之大量增长,海量的空间文本数据也随着产生,传统关系数据库在横向扩展性与大数据的及时处理上已力不从心,以可横向扩展的HBase分布式数据库处理这些海量的空间文本数据无疑是最佳方案。针对海量空间文本数据集,地理区域范围内的空间关键字查询需求日益迫切,如何在HBase数据库中实现高效的空间关键词查询成为了研究热点。基于关系数据库的传统地理信息系统通常使用基于树的索引(如R 树、四叉树、k-d树等)实现空间查询,以此类索引处理海量空间数据效率较差,同时基于行健的HBase数据库也较难支持传统的多维空间索引。传统多维空间索引不能适用于HBase数据库,因此对空间数据进行降维处理,以映射到一维空间进行索引和查询会更加简单。
Niemeyer G[1]于2008 年 提 出 了Geohash 编码,其把二维的经纬度坐标编码成一维的字符串,可全球唯一地标识每一坐标点,同时空间上相邻位置点的Geohash编码通常具有相同的前缀,这对基于HBase实现邻近点搜索具有明显优势。目前Geohash 已被广泛应用于空间数据的处理,如Google App Engine、Lucene和Solr等[2,3],但对其在空间关键词查询,尤其是基于NoSQL 数据库的空间关键字查询的探讨和研究较少,文献[4]探讨了基于Geohash的面数据区域查询,但其主要基于关系数据库实现。为了支持空间关键字查询,文献[5]和文献[6]以R*树为基本索引结构,分别提出了名为IR2树和IR 树的混合索引结构。文献[7]提出了另一名为S2I的混合索引结构。但此类方案都没有考虑大数据情况下如何保证空间关键字查询的高效性和可扩展性等问题。文献[8]研究了基于HBase的空间关键字查询,其仅描述了矩形空间区域内的文本检索,并没涉及其它几何形状区域内的文本检索。因此,为了解决海量空间文本数据的检索问题,本文依据HBase数据库的keyvalue数据模型及相邻位置点的Geohash 编码具有相同前缀的特性,提出了一种结合Geohash 编码与分词技术的HBase二级索引构建方案;实现了对空间信息和文本信息的同时索引,并基于该二级索引提出了一种多边形区域内的空间关键词查询算法;最后通过与传统经纬度索引方案的实验比较,验证了该算法的高效性和可扩展性。
2 HBase数据模型
作为Apache Hadoop项目的子项目及Google BigTable的开源实现,HBase是一个分布式的、列式存储的NoSQL数据库,相对于执行批处理任务的Hadoop平台,HBase专门用来实现对海量数据的实时处理[9]。HBase运行在普通商用服务器上,可平滑地横向扩展,以支持从中等规模到数十亿行、数百万列的数据表。表是HBase展现数据的逻辑组织方式,而基于列的存储则是数据的物理组织方式,本节将从逻辑模型和物理模型两个方面阐述HBase的数据模型。
2.1 逻辑模型
表1为一个HBase表的逻辑模型。

Table 1 Logical model of HBase表1 HBase数据的逻辑模型
HBase以表的形式组织数据,表由行(Row)和列(Column)组成,每行通过唯一的行健(Rowkey)进行区分,所有行按照行健的字典顺序升序存储。每行可以有不同的列,每列属于一个特定的列族(Column Family)。行和列确定的存储单元为单元格,每个单元格可以按时间保存多个版本的值,并通过时间戳(Timestamp)标识。表1 中每行对应一个时间戳,时间戳值越大表示数据越新。
2.2 物理模型
在逻辑模型中,HBase表可以被看作稀疏行的集合,但HBase的物理存储是把逻辑模型中的行按照列族分开存储。表2和表3为表1的列族cf1和cf2对应的物理模型,其表索引由行键、列族、列修饰符和时间戳组成。从这些表可以看出,HBase以稀疏方式存储数据,为空的单元格并不会占用存储空间。

Table 2 Physical model of HBase(column family:cf1)表2 HBase数据的物理模型(列族cf1)

Table 3 Physical model of HBase(column family:cf2)表3 HBase数据的物理模型(列族cf2)
3 Geohash概述
3.1 二维空间索引的不足
对基于经纬度编码的空间数据而言,每个维度都同等重要。执行空间查询时,简单地按二维经纬度建立索引,如先按经度再按纬度排序数据,实质上是将经度看得比纬度更重要,索引处理就会把数据进行不当的排序,因为经度上相近的数据,在空间位置上并不一定邻近。HBase数据库只能按行键来访问数据,其模式设计的关键是行键设计,采用二维经纬度坐标作为HBase行键,会使得先按经度再按纬度的顺序存储数据,这就造成了数据的空间位置与存储位置的不一致。当基于行键扫描执行空间位置查询(如查询k个最近的邻近点)时,会返回大量多余的非邻近点数据,这会增加HBase服务器与客户端的网络I/O 或服务端过滤器的处理开销。
两个维度同等相关时,简单地为经度和纬度建立复合索引的方法具有不足之处。为了使空间位置邻近的数据在HBase上也尽量紧密连续地存储在一起,保证空间数据的空间位置与存储位置的一致性,以方便构建处理海量空间数据的及时响应的HBase在线应用系统,就需基于新的空间编码方法来构建索引。
3.2 Geohash的划分与编码
为了高效地处理空间数据,基于key-value的HBase数据库需要一种平等考虑经度与纬度、能将二维空间坐标转换成为一维值的线性化算法。Peano曲线、Hibert曲线和Cantor曲线等就是此类的空间位置一维编码算法,属于空间填充曲线类别,其将二维空间降维成一维曲线,曲线是单一的、不中断的、接触空间所有分区的线条[10]。与其它曲线相比,Peano曲线计算简单且实现方便,因此本文选择实现了Peano曲线的Geohash算法为解决方案。
本文以纬度34.75°、经度113.59°的二维坐标为例,介绍Geohash编码的计算步骤。如图1a所示,纬度区间范围是[-90°,90°],将该区间二等分为[-90°,0°)与[0°,90°],目标点纬度大于或等于中点用1表示,否则用0表示;因纬度34.75°落在区间[0°,90°],标记为1;继续将区间[0°,90°]二等分为[0°,45°)与[45°,°90],纬度34.75°落在区间[0°,45°),标记为0。通过递归对半切分区间范围和确定目标点落在哪个半区,计算出一个位序列101。同理如图1b所示,计算经度113.59°的位序列为110。位序列的长度与区间划分次数有关,长度越长则表示的位置精度越高。经过在经度和纬度上分别执行区间二等分和位选择过程,再按奇数位放经度、偶数位放纬度的规则,以精度递增的顺序将经度和纬度位序列交叉排列生成一个新的位序列111001(如图1c 所示),再对该序列进行Base32编码即生成一维的Geohash散列字符串。相对于二维空间索引,不孤立使用单个维度的编码方式是一维的Geohash 值有空间位置特性的原因。一个Geohash字符串编码代表着一个矩形区域,该区域内所有的坐标点会以该字符串为共同前缀,越邻近的点共享的相同前缀字符越长,Geohash字符串越长,表示的矩形范围越小越精确,即Geohash编码具有一定的空间局部性,这对构建空间索引非常有利。
采用Geohash字符串编码作为HBase行健是一个极佳的选择。因为两个坐标点的空间距离越接近,其Geohash字符串前缀匹配越多,这就有利于在HBase行健上执行前缀匹配扫描以查询附件的POI(Point of Interest)信息。HBase按照行健的字典顺序升序存储所有行,两个坐标点的Geohash字符串前缀匹配越多,其在HBase中就会被存储得越接近,这就有利于实现数据本地化,因为HBase按行健范围划分Region,空间位置接近的数据会被存储在同一Region或RegionServer[11]。执行空间邻近点查询时,基于Geohash 字符串执行HBase行健扫描,由本地就可直接读取到所有的邻近点数据。
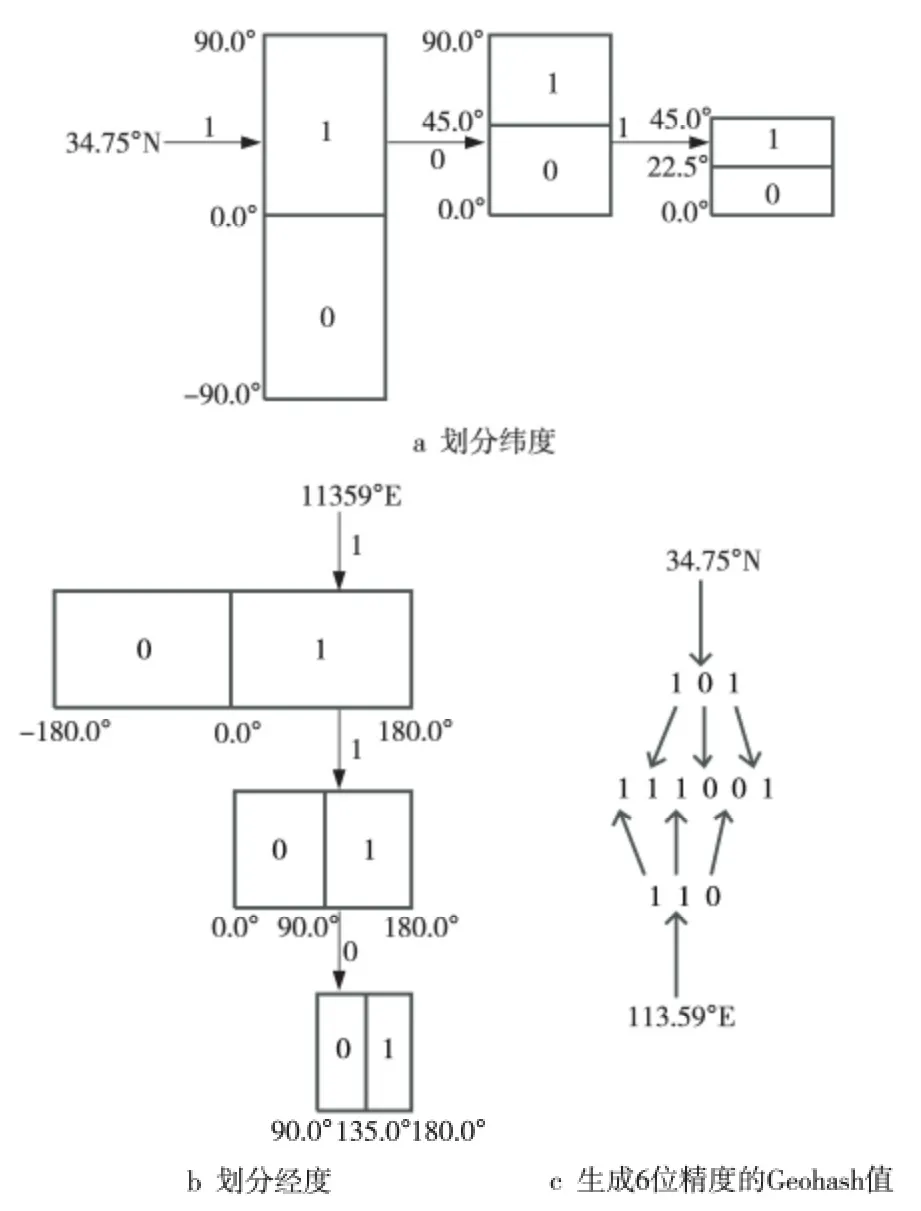
Figure 1 Subdivision and coding of Geohash图1 Geohash的划分与编码
4 基于Geohash的空间文本索引
为了在海量数据上实现高效且可扩展的空间关键字查询,本节针对HBase数据库利用Geohash算法提出了一种新的空间文本索引方法。首先,采用Geohash 算法将空间文本数据中代表空间信息的二维空间坐标降维为一维散列字符串;然后从空间文本数据的文本信息中抽取分词,并将分词字符串和Geohash 字符串合理编排,以构建HBase二级索引,实现同时从文本和空间两个维度对空间文本数据进行高效检索。以下具体阐述空间文本索引表的组织结构及其行健的生成规则。
表4中的空间文本数据主表即为空间文本数据在HBase数据库上的一种简单的组织方式,该表中的行健idi唯一标识了每一行空间文本数据,列族中的message列存储了空间文本中的文本信息,location列以二维经纬度坐标的格式存储了空间文本中的地理空间信息,date列存储了空间文本的生成时间。

Table 4 Master table of spatial text data表4 空间文本数据主表
表5为基于表4的空间文本数据索引表,表中的行健wordi_geohashj_idk由三部分组成:对主表message列进行分词处理提取的关键词wordi;对主表location列进行Geohash计算生成的Geohash字符串geohashj;以及wordi和geohashj对应的主表行健idk。一段文本可以切分出多个关键词,所以主表中的一条记录会按照切分出的关键词数量在索引表中生成多条索引记录,这些索引记录会依次按照关键词、Geohash字符串及id值的字典顺序升序存储,也就是说,空间位置相邻的同一关键词将被物理邻近地存储在一起,进行空间关键字查询时,HBase通过前缀匹配的行健扫描,即可高效直接地读取到所需的结果集。

Table 5 Index table of spatial text data表5 空间文本数据索引表
索引表中的行健wordi_geohashj_idk将一条空间文本数据中的文本信息、空间信息与标识信息综合在一起,实现了在文本和空间两个维度同时对数据进行索引。基于索引表查询时,根据扫描到的结果集,能直接在行健中截取到空间文本在主表中的行健id,由该id即可在主表中直接读取到具体的空间文本数据,因此索引表中的列族可为“空”,即不需要存储有具体含义的内容。在实际部署时,为了提高存储及查询效率,行健的长度要尽量短且固定,因此行健中的关键词wordi可替换为定长的整数编码;对于geohashj可根据地理精度需求选取尽量短的定长编码。Geohash编码支持部分键扫描,因此只要满足精度,查询者不用给出完整的Geohash编码。
5 多边形区域内的空间关键字查询算法
当基于地理空间区域查询文本数据时,区域可能是圆形的,如一公里范围内包含“快捷”关键字的酒店信息;区域可能是矩形的,如手机屏幕显示区域内包含“西餐”关键字的点评信息;区域可能是不规则多边形的,如行政区域内包含敏感关键字的言论信息。为了适用于所有查询场景,本节基于HBase数据库及前文构建的空间文本索引,提出一种多边形区域内的空间关键字查询算法,即查找某多边形地理区域内包含某关键字的空间文本数据。因计算步骤较多,所以将其分解为了MBP(Mininum Bounding Prefixes)算 法 和 Within-Query算法。
5.1 MBP算法
实现空间区域内的关键字查询时,用户定义的空间查询区域可以是不规则的任意几何图形,算法中统一以多边形表示。一个Geohash字符串编码代表的是一个规则的矩形,每个矩形拥有四个拐角,通过在多个Geohash 字符串所表示的多个邻接矩形区域的拐角点上取凸包(Convex Hull),即可构建一个拼接组合区域。基于Geohash编码实现空间关键字查询的关键就是将被查询的多边形区域转换为多个邻接的Geohash 矩形区域,且这些矩形的拼接组合区域最小包含着多边形区域,算法MBP即用于实现该转换。
算法1MBP(queryPolygon)
输入:被查询的多边形区域queryPolygon;
输出:最小包含查询区域的Geohash 前缀集合geohashs


算法MBP基于查询多边形计算最小包围的Geohash前缀集合,该算法的输入queryPolygon是用户手绘或自定义的查询多边形区域,具体实现时可用多边形拐角的经纬度坐标集合来表示。输出geohashs则为计算出的包含查询区域且最小包围的Geohash前缀集合,最小包围的前缀集合可以把HBase扫描次数与扫描覆盖的空间区域降到最小。
计算Geohash时需要指定字符精度,其取值范围为整数1到12,表示Geohash编码生成字符串的长度,字符串长度越短的Geohash编码,表示的矩形区域越大,计算最小包围的前缀集合的关键在于确定最佳的精度以最快计算出结果。MBP算法首先计算出查询多边形的形心queryCenter,并根据具体应用涉及的地理范围区域大小,指定初始的Geohash字符精度INIT_VALUE。while循环从较高的初始字符精度开始,先计算查询多边形形心的Geohash 编 码candidate[12],再 基 于 该Geohash编码代表的矩形区域计算其凸包candidate-Polygon,并检验是否包含查询多边形,若不包含,则扩大至该Geohash及其八个空间方向的直接邻居所构成的组合区域。若仍没有包含,则降低Geohash字符精度,以扩大Geohash编码代表的矩形区域,重复进行上述检查,直到相应区域正好完全包含查询多边形,即获得了最小包围的Geohash前缀集合。
5.2 WithinQuery算法
通过调用算法MBP,算法WithinQuery将查询关键字和算法MBP 返回的Geohash编码逐一进行合并,然后基于合并字符串在HBase空间文本索引表上执行行健扫描,并对返回结果集进行验证过滤,即得到要查询的空间文本数据集。
算法2WithinQuery(keyword,queryPolygon)
输入:查询关键字keyword,多边形查询区域queryPolygon。
输出:位于查询区域的空间文本数据的id集合ids。

算法WithinQuery的输入为查询关键字keyword和多边形查询区域queryPolygon,参数keyword和queryPolygon分别描述了要查询的空间文本数据的文本信息和空间信息,而输出结果集ids即为查询到的空间文本数据的id集合,根据该id集合可在主表中获取到具体的空间文本数据。算法WithinQuery首先调用算法MBP将查询多边形区域转换为最小包含查询区域的Geohash前缀集合prefixs,因为空间文本索引表的行健格式为wordi_geohashj_idk,所以将查询关键字keyword与前缀集合prefixs的每个元素prefix合并后,在索引表indexTable上逐一执行前缀匹配的行健范围扫描;然后在返回的结果集results的每个元素result上调用方法getCoordinate(),以检验该result代表的空间文本数据的空间位置是否落在多边形查询区域内,以滤除位于前缀集合prefixs区域但不位于查询区域的无效数据,经过空间过滤后的结果集即为包含关键字keyword且真正位于查询区域queryPolygon内的空间文本数据集合;最后将符合条件的所有result的行健中的id部分返回即可。
为了最大限度利用HBase集群执行计算工作并减少返回给客户端的数据量,应使用HBase的过滤器或协处理器(Coprocessor)在服务器端实现算法中耗时的处理。对算法WithinQuery而言,把“验证是否位于查询区域”的逻辑放在服务器端的过滤器来实现,将极大地减轻HBase服务器与客户端的通信量,并可提高算法的查询效率。
6 实验与分析
6.1 实验环境
本节通过分析基于Geohash一维空间索引与基于经纬度二维空间索引的查询结果,以实验来检验提出的多边形区域内的空间关键字查询算法的执行效率,从而证明该算法的高效性和可扩展性。实验使用HBase 0.94.7和Hadoop 1.1.2,并将其部署在七个物理节点上,其中一个节点作为Master,其余六个作为RegionServer。每个节点含有双核2.5GHz CPU、8GB内存,7 200rpm 的SATA 硬盘,网络带宽为1Gbps,操作系统为Ubuntu 12.04。实验中的查询区域是半径不超过3km 的任意几何区域,测试数据使用了五个具有空间位置信息的点评数据集,所有数据的地理位置均位于半径30km 的空间范围内,数据集的文本统计信息如表6所示。

Table 6 Text statistics of datasets表6 数据集文本统计信息
6.2 实验结果分析
实验测试了不同数据量下的基于不同索引技术的空间关键字查询算法的查询响应时间,实验结果如图2所示。从图2中可以看出,随着数据量的增大,基于经纬度二维索引的查询性能逐渐降低,而基于Geohash编码一维索引的查询算法则能保持查询性能基本不受影响。这是因为基于Geohash编码的空间索引使空间位置邻近的数据在HBase上连续地存储在一起,从而实现了数据的空间位置与存储位置的一致性。将查询区域半径扩大至10km 的任意几何区域,并基于更大规模数据的实验发现,基于经纬度二维索引的查询响应时间已远超出了可等待的范围,因此,图3中只测试了基于Geohash编码一维索引的查询性能。从图3可以看出,在更大的查询区域内,随着数据量的增大,该算法的响应时间有所增加,但仍处于可接受范围内,从而验证了算法具有良好的可扩展性。

Figure 2 Response time of queries图2 查询响应时间
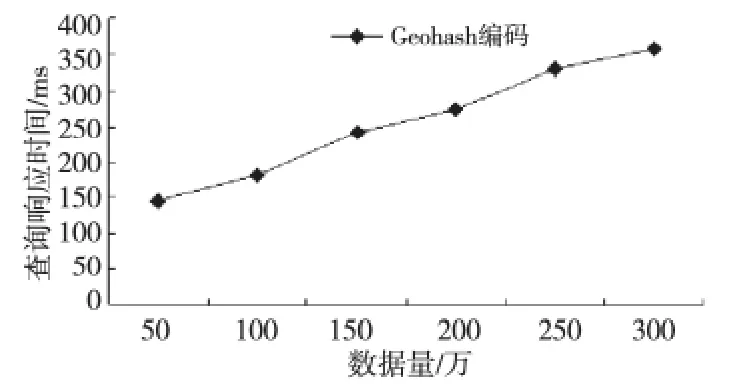
Figure 3 Scalability of query performance图3 查询性能的扩展性
7 结束语
运行在普通服务器上的HBase可方便地横向扩展支持数十亿行的海量数据集。Geohash编码把二维经纬度坐标降维成一维字符串,且空间位置相邻的Geohash 编码具有相同的前缀。所以,基于HBase数据库采用Geohash编码就非常适于解决海量空间数据中的邻近点搜索问题。本文据此给出了一种结合Geohash 编码与分词技术的HBase空间文本索引方案,并基于该索引提出了一种多边形区域内的空间关键词查询算法,为海量空间文本数据的高效存储与处理提供了新的解决方案和思路。如何深入优化查询算法以提高更大地理区域内的空间关键字查询效率是接下来应进一步研究的课题。
[1] Niemeyer G.Geohash[EB/OL].[2013-06-20].http://en.wikipedia.org/wiki/Geohash.
[2] The Apache Software Foundation.Apache Lucene 4.2.0 Documentation[EB/OL].[2013-03-11].http://lucene.apache.org/core/4_2_0/index.html.
[3] The Apache Software Foundation.Apache Solr 4.2.0Documentation[EB/OL].[2013-03-13].http://lucene.apache.org/solr/4_2_0/index.html.
[4] Jin An,Cheng Cheng-qi,Song Shu-hua,et al.Regional query of area data based on Geohash[J].Geography and Geo-Information Science,2013,29(5):31-35.(in Chinese)
[5] Ian De Felipe,Hristidis V,Rishe N.Keyword search on spatial databases[C]∥Proc of the 2008IEEE 24th International Conference on Data Engineering,2008:656-665.
[6] Li Zhi-sheng,Ken C K Lee,Zheng Bai-hua,et al.IR-tree:an efficient index for geographic document search[J].IEEE Trans on Knowledge and Data Engineering,2011,23 (4):585-599.
[7] Joao B Rocha-Junior,Gkorgkas O,Jonassen S,et al.Efficient processing of Top-k spatial keyword queries[C]∥Proc of the 12th International Conference on Advances in Spatial and Temporal Databases,2011:205-222.
[8] Zhang Yu,Ma You-zhong,Meng Xiao-feng.Efficient processing of spatial keyword queries on HBase[J].Journal of Chinese Computer Systems,2012,33(10):2141-2146.(in Chinese)
[9] HBase:bigtable-like structured storage for hadoop hdfs[EB/OL].[2010-08-17].http://hadoop.apache.org/hbase.
[10] Guo Wei,Guo Jing,Hu Zhi-yong.Spatial database indexing technique[M].Shanghai:Shanghai Jiao Tong University,Press,2006.(in Chinese)
[11] George L.HBase the definitive guide[M].Sebastop01:O’Reilly Media,2011.
[12] Heuberger S.Geohash-Java[EB/OL].[2009-12-11].https://github.com/kungfoo/geohash-java.
附中文参考文献:
[4] 金安,程承旗,宋树华,等.基于geohash的面数据区域查询[J].地理与地理信息科学,2013,29(5):31-35.
[8] 张榆,马友忠,孟小峰.一种基于HBase的高效空间关键字查询策略[J].小型微型计算机系统,2012,33(10):2141-2146.
[10] 郭薇,郭菁,胡志勇.空间数据库索引技术[M].上海:上海交通大学出版社,2006.
猜你喜欢
中学生数理化·七年级数学人教版(2022年9期)2022-10-24
华人时刊(2022年1期)2022-04-26
少年漫画(艺术创想)(2020年2期)2020-06-15
疯狂英语·初中版(2020年1期)2020-03-02
中学生数理化·七年级数学人教版(2019年9期)2019-11-16
动漫界·幼教365(大班)(2019年10期)2019-10-28
趣味(数学)(2019年11期)2019-04-13
疯狂英语·初中版(2019年9期)2019-01-03
校园英语·上旬(2017年17期)2018-02-11
法语学习(2015年1期)2015-04-17
