
路网环境下基于星图的位置隐私保护技术研究*
2015-03-19 01:29侯士江刘国华
计算机工程与科学 2015年8期
侯士江,刘国华,候 英
(1.燕山大学工业设计系,河北 秦皇岛066004;2.东华大学计算机科学与技术学院,上海201600)
1 引言
目前,基 于 位 置 的 服 务LBS(Location-Based Services)[1,2]吸引了众多的移动用户。常见的例子包括兴趣点POI(Points Of Interest)查找,它帮助用户找到POI,如酒店和电影院等,并能提供丰富的讯息,如特别优惠或代金券等。然而,与此同时,人们也对使用LBS时导致敏感信息泄露的问题倍加关注。
在任意路径点移动模型[3,4]中,用户可以在任意方向以任何速度移动,大多数现有的解决方案无法解决用户在路网中移动的约束,即路网中用户的移动和基于位置的服务处理受制于底层的道路网络。
更具体地说,任意路径点模型下所提供的保护对网络约束移动模型是不充分的。例如,空间隐匿技术[5~10]通过空间隐匿区域来模糊精确位置,保护用户的隐私,并用面积的大小作为度量指标。然而,这样的指标不适用于路网模型,因为一个非常大的区域可能仅包含一个路段,使得攻击者很容易追踪移动用户。此外,路网状况,即网络拓扑对查询代价和通信效率也会产生重大影响,这是位置隐私保护解决方案中应该重点关注的问题。例如,基于地理位置的查询处理的最基本的操作——计算网络中两个点距离的复杂程度会随底层网络结构的变化显著不同。因此,通常采用基于路段的隐匿方法。
基于路段的隐匿方法减少了计算开销,因为基于路段的隐匿区域比矩形隐匿区域返回更少的候选结果[11]。Kolahdouzan M 和Shahabi C[12]提出了基于泰森多边形的网络图,将大的网络分为小的泰森多边形。它预计算中间结果并基于缓存的结果构建查询答案。Papadias D 等[13]提出了网络扩展算法,从查询点开始隐匿并通过边扩展隐匿范围,直到满足用户的隐私需求。该算法无法向用户提供完全的保护,因为它遵循的最佳优先搜索扩展过程,很容易被攻击者加以利用。Wang T 和Liu L[14]提出了基于X-Star的隐匿算法,为用户实现查询处理成本和高隐私保护的平衡。另外,文献[15,16]也对路网环境的隐私保护问题做了研究。
2 概念和模型
本节对路网模型、位置隐私模型以及相关概念进行阐述。
2.1 路网模型
路网模型为无向图G(vG,εG),节点集vG和边集εG分别代表道路接口和直接道路连接。路网模型如图1 所示。dG(n)表示图G中节点n的度。具体来说,如果dG(n)≥3,n被称为交叉节点;如果dG(n)=2,n被称为中间节点;如果dG(n)=1,n被称为端节点。
为了模型化用户移动所受的底层路网约束,引入了路段的概念:路段是边的序列,这里每个都是不同的,并且对于i=0或者i=L,节点ni的度要么为1要么dG(ni)≥3,其余的节点dG(ni)=2。即n0和nL要么是交叉节点要么是端节点,其余节点均为中间节点。
注意,每条边要么自身就是一个路段要么唯一地属于某条路段的一部分,也就是说可以将路网分割为路段集。因此,可以做如下假设:每个移动用户沿着路段移动,并将其基于位置的查询连同当前位置信息提供给LBS服务商,然后LBS基于提供的位置信息执行查询。

Figure 1 A road network model图1 路网模型
2.2 位置隐私模型
考虑网络约束移动模型下的两种类型的隐私问题,即位置匿名和位置多样性。第一个要求保证了一个特定的移动用户在一组用户(匿名集)中的不可分辨性,通常利用位置k-匿名[5,8]的概念。
定义1(位置k-匿名) 用户提交的位置是k-匿名的,如果至少k-1个其他活动用户提交相同的位置。
单纯确保位置匿名的研究[5~9]未考虑底层的路网约束,所以在路网环境下不能提供足够的保护。例如,在图1中,假设用户u3和u4发布k-匿名位置分别为A1和A2。假设A1和A2是大小相同且包含相同数量的活动用户,依照标准的位置匿名概念,u3和u4被认为享受同等质量的隐私保护。然而,对于攻击者而言,追踪u3要比u4容易得多,因为u3仅与单个路段有关,而u4与段集相关。直观地说,从攻击者的角度来看跟踪用户的难度与路段的数量成正比。这也促使引入第二个隐私度量标准——位置多样性[17]。
定义2(路段l-多样性) 用户发布的位置是l-多样性的,如果它满足位置k-匿名且至少包含l个不同的路段。
为了满足这些需求,提出了位置匿名化操作。
定义3(位置匿名化) 令q表示移动用户u提交的基于位置的查询。位置匿名化将q的精确位置信息用一个满足u的服务配置的匿名位置来代替。
在路网环境下,假设匿名化操作在路段上进行,匿名位置由一组路段集组成。需要指出的是,为了便于描述,路段的长度因素未加讨论;若要处理路段长度的非均匀性,也很简单,如为短路段指定高多样性要求,或将长路段划分为一组短路段。
同时,引入可信的第三方位置匿名引擎LAE(Location Anonymization Engine),作为移动用户与LBS提供商之间的中间层,并执行位置匿名化操作。与其它方案相比,这种集中式LAE 架构有更多的优势:(1)相比大量的个体LBS提供商与复杂的商业利益冲突,它更容易提供安全保护和操作规则;(2)在LAE的帮助下,用户可以实现基于客户端或P2P 对等架构[10,18]所无法达到的隐私保证,如位置匿名性和多样性;(3)此外,这种体系结构已经成功地应用于各种位置私有化系统[5~8,19]。
LAE具体负责:(1)接收查询和移动用户的具体位置信息;(2)根据用户的隐私需求,匿名化位置信息,并将其传送到LBS提供者;(3)通过过滤假的信息,从服务提供者给出的候选结果集中提取准确的查询结果;(4)传递给客户确切的答案。
3 位置匿名操作过程
位置匿名操作包含两个主要阶段,匿名星选择和超星构建。简单来说,在第一个阶段,依据低成本星选择策略,将一组邻近查询群组在匿名星结构中;在第二个阶段,合并邻近星形成超星结构满足个体的隐私需求。
3.1 匿名星选择
首先介绍位置匿名的基本结构——匿名星的概念。
定义4(匿名星) 对于网络G中的交叉节点n,匿名星n是G的子图,由n和所有与n相连接的路段组成。
根据这个定义,每个dG(n)≥3的节点n与一个唯一的匿名星φn相关联。例如,在图1中,匿名星由节点n4和段组成。
匿名星结构具有一些优异的特性:(1)它保留邻近段的位置,将它作为匿名的基本单元,将会使匿名位置具有高度紧凑的结构;(2)能够索引,因为节点标识符可以代表一个星而没有信息损失,用它代表匿名位置可以减少通信成本,并简化实现。
给定路网G=(vG,εG),可以构建相应的星形网络,其中的每个节点代表G中的一个星,两个节点是相邻的如果G中相应的星分享共同的段。图2是图1相应的星图网络。需要指出的是,在Gφ中,所有边都是单位长度,路网G中φi和φj的距离定义为在Gφ中的网络距离,称之为跨步(Hop),表示为hG(φi,φj)。例如,在图1中,,因为它们在Gφ中的最短路径由和组成。

Figure 2 A star-graph network model图2 星图网络模型
如果路段上有活跃查询,则这条路段被标记为是活动的。为了使模型抗推理攻击和能够适应多查询共享处理,在同一段上的所有查询共享同一匿名位置。
对于某个活动段s上的查询,如果选择星φ作为匿名位置,就称为φ“被选择”,s被分配给φ,记为s←φ。考虑段s有两个节点和,如 果和都成立,那么s与两个匿名星和相关联,对图1 中而言,即和。在这种情况下,需要确定将s分配给或中的哪一个。对于整个网络而言,需要选择一组星集Φ涵盖所有活动段。
为了实现低查询处理成本,希望将成本模型合并到选择过程。令cost(φ)表示执行匿名位置为φ的查询处理成本,AS表示路网中当前活动段集,Φ是选定的星集,那么总成本最小化的问题可以表示为:
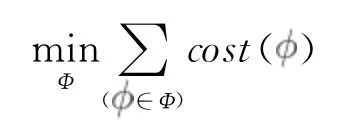
s.t.∀s∈AS,∃ ∈Φ,s←φ
低成本段—星分配方案旨在找到一组涵盖所有活动段的最低成本的星集。遗憾的是,这个优化问题没有有效的解决方案,除非P=NP。
因此,代替试图找到全局最优解,提出一种有效的随机算法,可以找到高质量的近似解,并且对推理攻击具有很好的鲁棒性。
具体来说,插入新查询及段s的操作(InsertQuery)分为以下四种情况:(1)如果某个星已经覆盖了s,该算法停止;(2)如果两个星和都已经选定而s未被覆盖,则s分配给两颗星之一的概率与相应成本成反比;(3)如果只有一个或者被选中,s就分配给这个星;(4)如果没有和被选中,则分配到其中一个星的概率与对应的成本成反比。
本质上,该方法将活动段s分配给的概率为,反之,分配给
3.2 超星的构建
在前一阶段,依据查询处理成本,选择一组星集覆盖活动段。在这个阶段,满足移动用户的隐私需求。这一目标通过合并相邻的星形成超星结构,充当其内部查询的匿名位置。
如图2所示,假定用户u3和u4分配给星用户u2分配给星,用户u1和u10分配给星。然而,单独的包含的活跃用户数并不能满足用户u3的的隐私需求。通过合并和,获得一个超星ψ,满足了所有用户的需求。
现在,描述合并星形成超星结构的过程(MergeStar):从最初的星 开始,逐步增加邻近星,直到超星内的所有用户的隐私需求得到满足。具体来说,首先检查星 是否已经满足用户的隐私需求;如果没有,迭代添加邻近的活动星(如果可能)。如果存在这样的星,依据一定的规则进行合并,形成新的超星。这种扩张过程迭代进行,直到满足其内所有用户的隐私需求,或报告失败(所有相关查询将会推迟到队列,等待新到来的查询触发匿名化)。
4 基于Hilbert序列的空间隐匿算法
基于Hilbert 序列的空间隐匿算法HSGCloaking通过五个步骤创建匿名区:构建星形网络,使用Hilbert排序将星节点映射Hilbert ID,从最高k-匿名度要求的用户位置起始选择星,扩展网络直到满足用户的需求和重置网络中其他用户条件。
4.1 匿名步骤
步骤1构建星形网络。
在此阶段,为每个dG(n)≥3的节点n都与一个唯一的星φn相关联,Gφ中的每个星节点都对应G中的一个节点。
步骤2星节点映射Hilbert ID。
在此步骤中,利用如图3所示Hilbert空间填充曲线对星节点进行排序。

Figure 3 Hilbert filling curves图3 Hilbert填充曲线
步骤3隐匿起始位置选择。
隐匿的主要过程从这一步开始。当查询位于段s上,s被分配给星 ,即s← ,那么 被选为匿名区域。如果星节点 包含最高k-匿名度要求的用户,那么它被选为起始隐匿星。如图4a所示,星节点(虚线)包含的用户u3具有最高的k-匿名度要求因此星节点被选为匿名过程的起始位置。
步骤4网络扩展。
在前一步,包含最高k-匿名度要求的星被选择。在此步骤中,从所选择的星开始扩展,扩大隐匿区域,直到满足用户的隐私需求。例如,在选星节点后,该算法扩展隐匿区域(虚线),直到它满足用户的要求,即覆盖了u1、u2、u4和u10区域(如图4a所示)。最后,它将这一区域作为匿名区,发送给LBS。
在网络扩展之前,算法要检查两个属性:(1)所包含的用户数量;(2)所选星节点与邻近星节点的Hilbert ID 差值。检查后,算法决定扩展的方向。同时,逐步增加邻近星,直到组中所有用户的隐私需求得到满足。
步骤5重置条件。
HSGCloaking算法重复步骤3和步骤4,直到网络中其他用户也形成组。在图4b和图4c中,另两组的形成也基于最高k-匿名度要求的用户的位置(虚线和点划线)。

Figure 4 Illustration of forming groups图4 形成组的过程表示
4.2 隐匿算法HSGCloaking
主要匿名过程如算法HSGCloaking所示。算法第1行首先生成星形网络,在第2 行生成Hilbert曲线,在第3行合并Hilbert ID 与生成的星节点,第4行找出k-匿名度最高的用户。第5~18行处理满足用户需求。如果在一个匿名星内用户的要求得到满足,那么算法执行第6~8 行。在第9~19行,算法根据用户的需求扩展网络。
算法1 隐匿算法HSGCloaking

5 性能分析
实验在Windows系统,Pentium 4 2.81GHz处理器和2 GB 内存上进行,用真实的路网验证HSGCloaking 算法的性能。对HSGCloaking 方法在执行成本、匿名成功率、平均匿名段数方面进行广泛的实验和性能测试。执行成本指服务器端执行整个匿名过程的时间。成功率指用户的请求得到满足的情况,平均匿名段数意味着根据用户需求生成的匿名位置的平均尺寸。如表1所示,使用San Francisco路 网,其 中 包 含175 350 个 节 点 和223 200条边。在这张地图上,使用基于网络的移动 对象生 成 器Brinkoff[20]生 成10 000 个 移 动 对象,模拟交通情况。

Table 1 Experiment parameters表1 实验参数
将所提出的HSGCloaking算法与文献[14]中的X-Star算法在平均执行时间、匿名成功率、匿名区大小等方面做了比较。实验结果显示,所提出的HSGCloaking算法比X-Star算法具有更大的优势。
图5显示了两种算法的平均执行时间,显示HSGCloaking 平 均 执 行 时 间 低 于X-Star 几 乎30%。起始时与X-Star的时间差异不太明显,但随着k-匿名度的增长,HSGCloaking能节约50%的执行时间。表明X-Star的执行时间随k-匿名度的增加线性增长。然而,对于HSGCloaking,开始时执行时间逐步增加,但k-匿名度达到一定值之后反而会降低,之后一直保持稳定的状态。

Figure 5 Average execution time图5 平均执行时间
如图6 所示,X-Star的匿名成功率比HSGCloaking低很多。图6中显示匿名成功率随匿名度的增加而降低。因为大的k-匿名度需要在特定的网络区域有更多的用户数,很难满足大k-匿名度要求。

Figure 6 Anonymization success rates图6 匿名成功率
实验比较了X-Star和HSGCloaking 算法的平均路段数与k-匿名度的关系。图7显示X-Star随着k-匿名度的增加,平均路段数线性增加。然而,当k-匿名度达到某个值后,它保持不变。HSGCloaking开始时平均路段数增加,达到一定k-匿名度之后反而会减少。当k-匿名度数值很高时,很难满足用户的需求,创建匿名区域。考虑边界节点,用户查询可能不执行这些边界星节点。因为一些节点不包含任何用户,网络需要扩展。因为边界星节点选择限制,会显著地降低匿名成功率和减少匿名面积。

Figure 7 Anonymization areas图7 匿名区大小
6 结束语
本文提出了适用于路网环境的隐匿算法HSGCloaking,保护用户隐私。通过将一般网络转换为星形网络,并进行Hilbert排序、隐匿星选择合并操作满足每个用户的匿名要求。框架支持k-NN 和范围查询,在实际道路网络上的实验验证了该隐匿模型的有效性。
[1] Beresford A R,Stajano F.Location privacy in pervasive computing[J].IEEE Pervasive Computing,2003,2(1):46-55.
[2] Bettini C,Wang S,Jagodia S.Protecting privacy against location-based personal identification[C]∥Proc of VLDB Workshop on Secure Data Management,2005:185-199.
[3] Broch J,Maltz D A,Johnson D B.et al.A performance comparison of multi-hop wireless ad hoc network routing protocols[C]∥Proc of the 4th Annual ACM/IEEE International Conference on Mobile Computing and Networking,1998:85-97.
[4] HyytiäE,Virtamo J.Random waypoint mobility model in cellular networks[J].Wireless Networks,2007,13(2):177-188.
[5] Gruteser M,Grunwald D.Anonymous usage of location-based services through spatial and temporal cloaking[C]∥Proc of the 1st International Conference on Mobile Systems,Applications and Services,2003:31-42.
[6] Mokbel M F,Chow C Y,Aref W G.The new casper:Query processing for location services without compromising privacy[C]∥Proc of the 32nd International Conference on Very Large Data Bases,2006:763-774.
[7] Bamba B,Liu L,Pesti P,et al.Supporting anonymous location queries in mobile environments with privacy grid[C]∥Proc of the 17th International Conference on World Wide Web,2008:237-246.
[8] Gedik B,Liu L.A customizableK-anonymity model for protecting location privacy[C]∥Proc of the 25th International Conference on Distributed Computing Systems,2005:620-629.
[9] Ghinita G,Kalnis P,Skiadopoulos S.Prive:Anonymous location based queries in distributed mobile systems[C]∥Proc of the 16th International Conference on World Wide Web,2007:371-380.
[10] Yiu M,Jensen C,Huang X,et al.Spacetwist:Managing the trade-offs among location privacy,query performance,and query accuracy in mobile services[C]∥Proc of IEEE 24th International Conference on Data Engineering,2008:366-375.
[11] Peng W C,Wang T W,Ku W S,et al.A cloaking algorithm based on spatial networks for location privacy[C]∥IEEE International Conference on Sensor Networks,Ubiquitous and Trustworthy Computing,2008:90-97.
[12] Kolahdouzan M,Shahabi C.Voronoi-basedknearest neighbor search for spatial network databases[C]∥Proc of the 30th International Conference on Very Large Data Bases,2004:840-851.
[13] Papadias D,Zhang J,Mamoulis N,et al.Query processing in spatial network databases[C]∥Proc of the 29th International Conference on Very Large Data Bases,2003:802-813.
[14] Wang T,Liu L.Privacy-aware mobile services over road networks[J].Proceedings of the VLDB Endowment,2009,2(1):1042-1053.
[15] Palanisamy B,Ravichandran S,Liu L,et al.Road network mix-zones for anonymous location based services[C]∥Proc of IEEE 29th International Conference on Data Engineering(ICDE),2013:1300-1303.
[16] Domenic M K,Wang Y,Zhang F,et al.Preserving users’privacy for continuous query services in road networks[C]∥Proc of IEEE 6th International Conference on Information Management,Innovation Management and Industrial Engineering(ICIII),2013:352-355.
[17] Machanavajjhala A,Kifer D,Gehrke J,et al.L-diversity:Privacy beyondk-anonymity[J].ACM Transactions on Knowledge Discovery from Data,2007,1(1):1-36.
[18] Ghinita G,Kalnis P,Skiadopoulos S.Prive:Anonymous location-based queries in distributed mobile systems[C]∥Proc of the 16th International Conference on World Wide Web,2007:371-380.
[19] Beresford A R,Stajano F.Mix zones:User privacy in location-aware services[C]∥Proc of PerCom Workshops,2004:127-131.
[20] Ku W S,Chen Y,Zimmermann R.Privacy protected spatial query processing for advanced location based services[J].Wireless Personal Communications,2009,51(1):53-65.
猜你喜欢
畜牧兽医杂志(2022年6期)2023-01-05
贵金属(2021年1期)2021-07-26
汽车观察(2021年11期)2021-04-24
Plasma Science and Technology(2020年3期)2020-04-24
中国计算机报(2018年25期)2018-10-08
中国计算机报(2018年12期)2018-10-08
小猕猴智力画刊(2018年7期)2018-08-08
环球飞行(2018年7期)2018-06-27
中国公路(2017年11期)2017-07-31
中国公路(2017年7期)2017-07-24
