
基于Hadoop的分布式文件系统实现
2015-03-14 11:31罗光明
西华师范大学学报(自然科学版) 2015年1期
罗光明
(四川水利职业技术学院,四川 成都 611230)
基于Hadoop的分布式文件系统实现
罗光明
(四川水利职业技术学院,四川 成都 611230)
为了解决现阶段海量数据的传输效率低下的问题,设计了基于Hadoop的分布式文件系统。系统是基于Hadoop的架构进行研究的,用MapReduce编程模型实现海量数据的上传与下载,从而达到数据的高效传输,并对其进行了传输性能测试。通过测试,基于Hadoop的数据传输效率远远大于传统的数据传输效率,该系统具有一定的实用性.
Hadoop分布式系统,MapReduce编程模型,高效传输
自进入21世纪以来,网络信息发展就迈入了一个全新的阶段,网络信息的发展对我们的生产、生活和学习的影响非常之大,从根本上变革了我们的生产和生活方式.同时,随着网络信息技术的快速发展也推动了各类资源信息的全球化共享.根据全球著名统计机构统计,在2012年底,全球的互联网用户达到了26.5亿.网络信息技术正以不可阻挡的趋势在向前发展,在推动着人类的进步和人类的信息文明.因此,如何在充满信息的世界中驾驭这些海量的信息并把这些信息转为财富,已经成为了IT互联网各个行业的必争舞台[1].但现阶段的情况却是传统的数据存储平台已不能适应海量数据的并行处理速度需求和容量需求,故如何实现海量数据的上传、下载和存储成为了我们需要解决的问题.云计算的出现为解决这一问题带来了曙光,尤其是云计算平台Hadoop的使用,为解决海量数据存储与处理提供了实施的方法.
1 Hadoop平台搭建
Hadoop集群搭建有3种模式,分别为单机模式、伪分布式模式和完全分布式模式.由于该Hadoop平台是搭建在云实验教学平台上的,故选用完全分布式Hadoop集群作为数据上传与下载平台.搭建的Hadoop云计算平台由5台机器组成,一台作为Master实现Damenode和Jobtracter功能,其余四台作为Slave(分别命名为Slave1、Slave2、Slave3和Slave4)实现Datanode和Tasktracker功能,
Hadoop云计算平台搭建涉及到JDK的安装、SSH的配置(实现无密码登录)、Hadoop平台中相应配置文件的参数配置和Eclipse跟Hadoop平台的连接.
1.1 jdk安装
由于Hadoop使用java程序编写,故在运行Hadoop平台前需先安装jdk,为Hadoop的运行提供JVM,安装jdk的步骤:
(1)在Ubuntu命令窗口输入sudo apt-get install sun-java6-jdk.
(2) 在命令窗口输入sudo gedit /etc/profile ,在打开的文件中添加下面的内容:
export JAVA_HOME= (java安装位置,自动安装的目录为/usr/lib/jvm/java-6-sun)
(3) 输入命令java -verison验证安装成功与否
1.2 SSH安装
ssh无密码登录安装步骤如下:
(1) 创建密钥
Generating public/private rsa key pair.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /.ssh/id_rsa.
Your public key has been saved in /.ssh/id_rsa.pub.
(2) 添加公密到信任列表
(3) 启动ssh-agent
(4) 添加id_rsa到ssh-agent
(5)修改目录权限
sudo chmod 600 ~/.ssh/id_rsa sudo chmod 600 ~/.ssh/id_rsa.pub
sudo chmod 644 ~/.ssh/known_hosts
sudo chmod 755 ~/.ssh
(6) 登陆测试
1.3 Hadoop平台配置
(1)解压Hadoop源码包
终端下进入hadoop源码包所在目录,使用复制命令把hadoop源码包复制到/home/hadoop下,其命令为cp hadoop-1.2.1.tar.gz /home/hadoop,然后解压,命令为:
tar -xzvf *.tag.gz.
(2)配置hadoop的hadoop/conf下的配置文件
①core-site.xml配置
其配置文件代码如下:
②mapred-site.xml
其配置文件代码如下:
③hdfs-site.xml
其配置文件代码如下:
(3)格式化HDFS文件系统
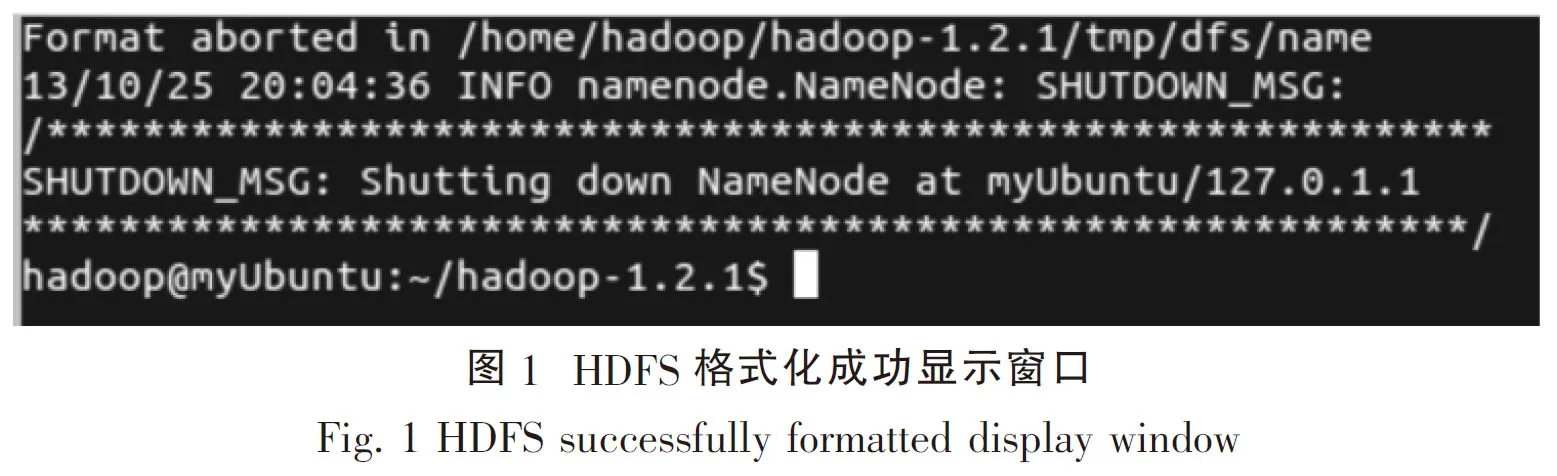
其命令为 /bin/hadoop namenode -format,当出现图1时证明HDFS文件系统格式化成功.
(4)启动Hadoop服务
启动Hadoop命令为:/bin/start-all.sh,启动后如图2所示,运行jps命令,如显示如图3所示,则Hadoop平台搭建成功.
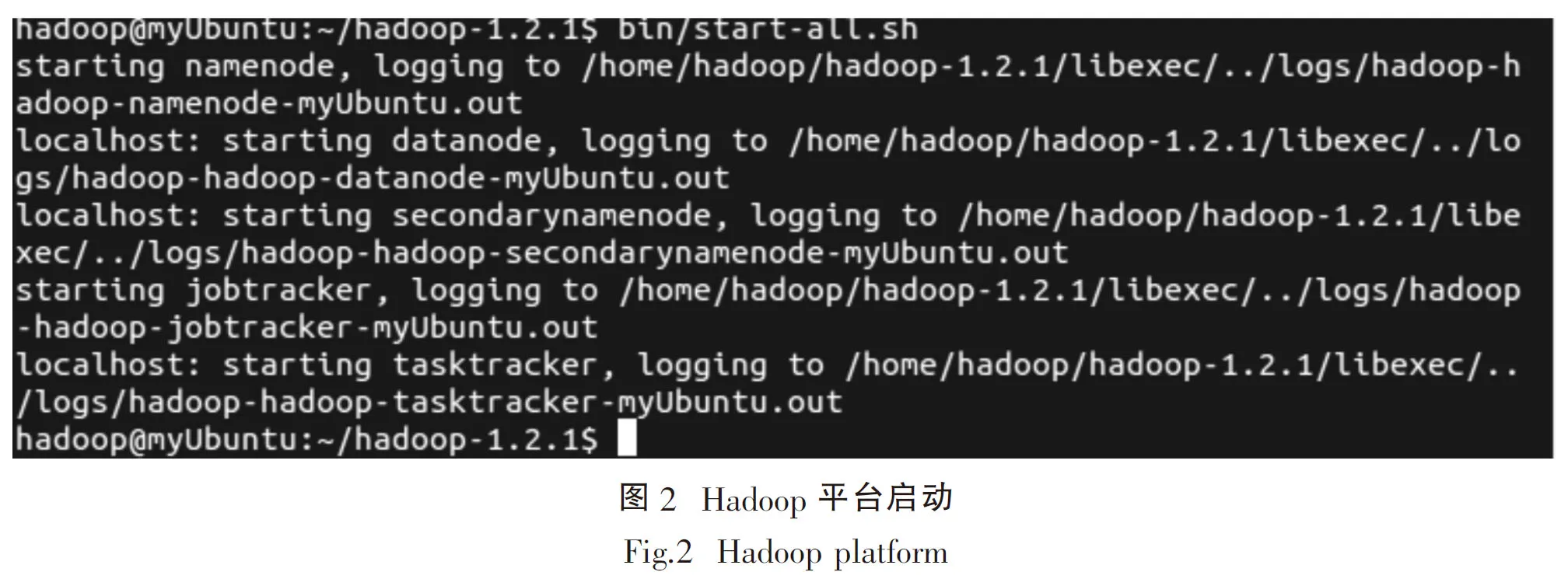

至此,完整的基于云实验教学中心的Hadoop平台搭建成功,可以用其做实际的上传与下载任务.
2 MapReduce实现数据上传下载
2.1 客户端
HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为:
public FSDataInputStream open(Path f, int bufferSize) throws IOException {
return new DFSClient.DFSDataInputStream(
dfs.open(getPathName(f), bufferSize, verifyChecksum, statistics));
}
其中dfs为DistributedFileSystem的成员变量DFSClient,其open函数被调用,其中创建一个DFSInputStream(src, buffersize, verifyChecksum)并返回. 在DFSInputStream的构造函数中,openInfo函数被调用,其主要从namenode中得到要打开的文件所对应的blocks的信息,实现如下:
synchronized void openInfo() throws IOException {
LocatedBlocks newInfo = callGetBlockLocations(namenode, src, 0, prefetchSize);
this.locatedBlocks = newInfo;
this.currentNode = null;
}
private static LocatedBlocks callGetBlockLocations(ClientProtocol namenode,
String src, long start, long length) throws IOException {
return namenode.getBlockLocations(src, start, length);
}
2.2 NameNode端
NameNode.getBlockLocations实现如下:
public LocatedBlocks getBlockLocations(String src,
long offset,
long length) throws IOException {
return namesystem.getBlockLocations(getClientMachine(),
src, offset, length);
}
namesystem是NameNode一个成员变量,其类型为FSNamesystem,保存的是NameNode的name space树,其中一个重要的成员变量为FSDirectory dir. FSDirectory和Lucene中的FSDirectory没有任何关系,其主要包括FSImage fsImage,用于读写硬盘上的fsimage文件,FSImage类有成员变量FSEditLog editLog,用于读写硬盘上的edit文件. FSDirectory还有一个重要的成员变量INodeDirectoryWithQuota rootDir,INodeDirectoryWithQuota的父类为INodeDirectory,实现如下:
public class INodeDirectory extends INode {
……
private List
……
}
getBlockLocationsInternal的实现如下:
private synchronized LocatedBlocks getBlockLocationsInternal(String src, INodeFile inode, long offset, long length, int nrBlocksToReturn, boolean doAccessTime)
throws IOException {
//得到此文件的block信息
Block[] blocks = inode.getBlocks();
List
//计算从offset开始,长度为length所涉及的blocks
int curBlk = 0;
long curPos = 0, blkSize = 0;
int nrBlocks = (blocks[0].getNumBytes() == 0) ? 0 : blocks.length;
for (curBlk = 0; curBlk < nrBlocks; curBlk++) {
blkSize = blocks[curBlk].getNumBytes();
if (curPos + blkSize > offset) {
//当offset在curPos和curPos + blkSize之间的时候,curBlk指向offset所在的
block
break;
}
curPos += blkSize;
}
long endOff = offset + length;
//循环,依次遍历从curBlk开始的每个block,直到当前位置curPos越过endOff
do {
int numNodes = blocksMap.numNodes(blocks[curBlk]);
int numCorruptNodes = countNodes(blocks[curBlk]).corruptReplicas( );
int numCorruptReplicas = corruptReplicas.numCorruptReplicas(blocks[curBlk]);
boolean blockCorrupt = (numCorruptNodes == numNodes);
int numMachineSet = blockCorrupt ? numNodes :
(numNodes - numCorruptNodes);
//依次找到此block所对应的datanode,将其中没有损坏的放入machineSet中
DatanodeDescriptor[] machineSet = new DatanodeDescriptor[numMachineSet];
if (numMachineSet > 0) {
numNodes = 0;
for(Iterator
blocksMap.nodeIterator(blocks[curBlk]); it.hasNext();) {
DatanodeDescriptor dn = it.next();
boolean replicaCorrupt = corruptReplicas.isReplicaCorrupt(blocks[curBlk],dn);
if (blockCorrupt || (!blockCorrupt && !replicaCorrupt))
machineSet[numNodes++] = dn;
}
}
//使用此machineSet和当前的block构造一个LocatedBlock
results.add(new LocatedBlock(blocks[curBlk], machineSet, curPos,blockCorrupt));
curPos += blocks[curBlk].getNumBytes();
curBlk++;
} while (curPos < endOff
&& curBlk < blocks.length
&& results.size() < nrBlocksToReturn);
//使用此LocatedBlock链表构造一个LocatedBlocks对象返回
return inode.createLocatedBlocks(results);
}
通过以上代码即可实现基于Hadoop的数据上传与下载,为了测试方法的有效性,以下选用真实数据对其进行测试.
3 性能测试
为了比较传统环境下数据上传与下载速率和基于Hadoop平台的数据上传与下载速率,从UCI中下载数据并将其分为10G、20G、30G、40G和50G等5组测试集,分别用传统方法和基于Hadoop的数据上传下载方法对其进行处理,其结果如图4、图5所示.
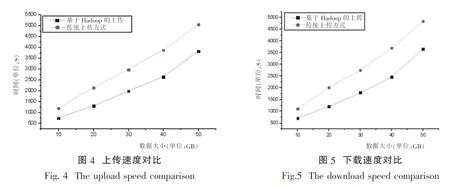
综上所述,从以上测试结果可以看出,基于Hadoop的数据传输效率远远大于传统的数据传输效率.该方案可以解决海量数据处理性能瓶颈等问题,对于现阶段解决海量数据的传输与存储具有一定的参考意义.
[1] 梁一帆.互联网与信息型教育[J].黑龙江高教研究.2009 (4):104-106
[2] 陈全,邓倩妮.云计算及其关键技术[J].计算机应用.2009.29(9):2562-2567
[3] ZHANG Q,CHENG L,Boutaba R.Cloud computing: state-of-the-art and research challenges[J].Journal of internet services and applications.2010.1(1):7-18
[4] 罗军舟,金嘉晖,宋爱波等.云计算:体系架构与关键技术[J].通信学报.2011.32(7):3-21
[5] 刘正伟,文中领,张海涛等.云计算和云数据管理技术[J].计算机研究与发展.2012.49(z1):26-31
[6] 孙大为,常桂然,陈东等.云计算环境中绿色服务级目标的分析、量化、建模及评价[J].计算机学报.2013.36(7):1509-1525
[7] 曾文英,赵跃龙,尚敏等.云计算及云存储生态系统研究[J].计算机研究与发展.2011.48(z1):234-239
[8] 崔杰,李陶深,兰红星等.基于Hadoop的海量数据存储平台设计与开发[J].计算机研究与发展.2012.49(z1):12-18
[9] STONEBRAKER M,ABADI D,DEWITT D J,et al.MapReduce and parallel DBMSs: friends or foes[J].Communications of the ACM.2010.53(1):64-71
[10] 朱建生,汪健雄,张军锋等.基于NoSQL数据库的大数据查询技术的研究与应用[J].中国铁道科学.2014.35(1):135-141
The Implementation of A Distributed File System Based on Hadoop
LUO Guang-Ming
(Sichuan Water Conservancy vocational College, Chengdu 611230, China)
In order to solve the problem that the transmission efficiency of mass data is low,the distributed file system based on Hadoop has been designed. The system is studied based on Hadoop architecture. It uploads and downloads massive data through the MapReduce programming model, so as to achieve the efficient transmission of data. According to the transmission performance test. The data transmission efficiency based on Hadoop is far greater than the transmission efficiency of the traditional.
Hadoop distributed file system; MapReduce programming model; efficient transmission
1673-5072(2015)01-0095-07
2014-12-12
罗光明(1981-),男,重庆大足人,四川水利职业技术学院信息工程系讲师,主要从事计算机应用研究.
TP393
A
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
娃娃乐园·综合智能(2022年3期)2022-04-19
电脑爱好者(2021年11期)2021-06-07
电脑爱好者(2020年9期)2020-07-05
电脑爱好者(2019年20期)2019-12-10
当代陕西(2019年14期)2019-08-26
铁路计算机应用(2018年10期)2018-11-09
军营文化天地(2018年2期)2018-04-20
中学数学杂志(初中版)(2016年5期)2016-11-01
中国老区建设(2016年9期)2016-02-28
