
跨平台电网规划数据融合与存储模式
2015-03-11 07:34:38赵春晖吴志力姜欣崔灿孙毅
电力建设 2015年3期
赵春晖,吴志力,姜欣,崔灿,孙毅
(1.国网北京经济技术研究院,北京市 102209; 2.华北电力大学电气与电子工程学院,北京市 102206)
跨平台电网规划数据融合与存储模式
赵春晖1,吴志力1,姜欣1,崔灿2,孙毅2
(1.国网北京经济技术研究院,北京市 102209; 2.华北电力大学电气与电子工程学院,北京市 102206)
随着电网规划各业务系统平台的建立以及异构业务数据的急剧增加,急需打破各系统平台之间的业务壁垒,建立完善的业务信息共享与交互体系。文章在分析现有业务系统数据格式及存储现状的基础上,深入研究异构数据融合与存储的关键技术,并提出一种跨平台电网规划数据融合与存储模式。通过建立统一业务数据信息模型,完成异构数据的融合处理;构建基于Hadoop的分布式文件存储系统,实现海量异构数据高效快速的存储与索引,为电网规划系统乃至电力行业的海量异构数据与信息共享提供理论指导与体系架构支撑。
跨平台业务;数据融合;Hadoop;异构数据存储
0 引 言
近年来,随着信息计算技术的不断发展,电力行业各业务领域的信息系统建设也在不断推进,目前各类业务系统平台的建立已初步实现单一类型数据的高效融合与存储[1]。针对电力系统中越来越多的非结构化数据,尚无较有效的异构数据融合与存储方案。在电网规划体系中,规划、技经、评审等业务系统不断积累了大量异构数据,由于这些数据在系统建设初期设计要求各不统一,通常具有不同的格式、不同的业务属性,造成了未来各业务信息系统间数据共享和交换的极大困难。构建良好的数据管理平台,为各业务领域提供良好的技术支撑,需要根据现有的问题开展针对跨平台多业务的数据融合与管理模式方面的研究,探索建立具有计算速度快、稳定性高、维护简便等优点的统一信息平台,构建业务数据的大集中管理架构。
数据融合与存储的方式研究较多,文献[2]提出一种模糊联合聚类方法(fuzzy co-clustering for high-order heterogeneous data, HFCC),实现对高阶异构数据进行融合与聚类分析。算法最小化每个特征空间中对象与聚簇中心的加权距离,推导出对象隶属度和特征权重的迭代更新公式,设计出聚类过程的迭代算法,并且从理论上证明了该迭代算法的收敛性。文献[3]提出了基于solr的异构数据融合检索技术,实现了对xml文件的索引和检索,为异构数据融合检索提供了解决方案。基于Hadoop和分布式文件系统(hadoop distributed file system, HDFS)的异构数据存储方式也是研究的热点。文献[4]提出了针对能源数据的Hadoop存储体系以及基于多级索引表DHT的快速索引算法。
电网规划系统数据有较明显的电力行业特色,一般的数据融合方式无法适用于电网规划的各个业务平台。针对各平台的数据格式特征以及不同的存储需求,需要研究一套适用于电网规划体系各业务平台的跨平台数据融合与存储模式,不仅能够为电网企业的统一信息共享平台提供理论和技术基础,还能为大规划体系中异构大数据的高效处理、存储和应用做保障。本文在对现有业务平台数据融合、共享与存储现状分析的基础上,研究跨平台电网规划数据融合与存储模式所涉及的关键技术,最后提出跨平台电网规划数据融合与存储体系架构,为建设快速、稳定、实用的统一信息平台提供建设思路。
1 现状分析
国网经济技术研究院现有业务系统主要包括一体化电网规划设计平台、工程设计评审平台和技经一体化平台。
一体化电网规划设计平台涉及以下几种业务数据:社会经济、能源资源、电力供需、电网设备、电源设备、电网运行、地理信息、典型参数、电力工程等。
工程设计评审平台包含下列业务数据:工程基础数据、工程可研批复文件数据、工程初始批复文件数据、工程概算文件数据。
技经实验室一体化平台包含以下业务数据:项目工程数据、工程可研估算数据、工程初始概算数据、工程施工图预算数据、工程竣工结算数据、结算管理数据、计价标准数据、专业资质管理数据、造价分析数据、标准成本测算数据、技经标准研究数据、全寿命周期分析数据、通用造价数据、标准成本库数据、行业信息数据、物料库数据、价格信息发布数据、年度工作计划数据。
其中,大部分一体化规划设计平台数据,如社会经济数据、电力设备及运行数据、地理信息数据等为结构化数据;而工程设计评审平台及技经实验室一体化平台中涉及的工程文件、可研文件、施工图等数据为非结构化数据。结构化数据能够使用同一格式的数据格式进行标示,主要存储在关系数据库中,而非结构化数据无法像结构化数据一样用二维表表示,也无法像结构化数据一样完全采用关系数据库来处理,其主要包括所有格式的办公文档、文本、图片、xml、html、各类报表和音频/视频信息等。非结构化数据在电力行业中所占的比例越来越高,其特征是数据格式多样,数据总量大,增长速度快且包含有关企业管理发展的重要信息。伴随着电网公司信息化的建设和发展,企业每年非结构化数据的增长量已经达到PB级别。经过多年的运行积累,各业务系统形成信息孤岛,非结构化数据的存储、管理和搜索问题日益凸显。表1为现有平台业务数据类型。
表1 现有平台业务数据类型
Table 1 Business data types of the existing platform

2 数据融合与存储关键技术
2.1 数据融合CIM模型
不同平台的数据种类和格式多种多样,要实现跨平台数据的融合就必须先对异构数据进行统一建模,只有在共同的数据模型下,才能实现快速有效的数据融合与存储等处理过程。目前电力系统已有的公共信息模型(common information model,CIM)是解决该问题的有效途径,通过定义针对经研院各业务数据的CIM模型保障未来系统能够平滑升级并与国际接轨[5]。
美国电科院/国际电工委员会建立的公共信息模型是对电网企业运营管理的典型实物对象和业务领域的一套精确描述体系[6]。CIM的原型也随之产生,它用于控制中心EMS系统建模和外部系统之间的数据交换,包括状态估计、潮流计算、拓扑分析、网络规划、安全分析、SCADA等业务领域,后被扩展到发电、输电、配电等领域[7]。
目前针对电网规划各业务平台数据的信息模型并不健全,CIM模型在电网规划的应用扩展较少,主要包括以下几个方面[8]:
(1) 规划区域类:规划潮流计算的区域范围,有平衡机,规划网架对象属于该区域;
(2) 规划地区:结合规划要考虑的维度自定义,可以是阻塞区、气候区、经济区等;
(3) 规划地区组:比规划地区更高一层的划分,由规划地区组成;
(4) 节点组:把规划区域内的连接点组织到planning zone中,从而可以成组调节规划节点特性;
(5) 支路组:用于定义规划计算断面,定义断面限额,由支路组端点组成;
(6) 支路组端点:用于定义支路组。
上述模型扩展主要针对xml文件的信息建模,无法完成对办公文档、文本、图片、html、各类报表和音频/视频信息等其他数据类型的建模和分析。要实现跨平台数据的融合,统一的数据信息模型是必要条件,因此需要对现有规划数据信息模型进一步扩展,研究出适用于规划、评审和技经多个平台的统一数据信息模型,并在此基础上建立完善的数据融合处理与存储机制,实现跨平台业务数据的融合与存储体系。
2.2 分布式数据存储
面对海量种类繁多的数据,现有的关系型数据库已经不能满足电网大规划体系的数据存储需求。建立高效、稳定的跨平台数据融合与存储体系必须采用另一个关键技术,即面向多源异构大数据的分布式数据存储。传统的关系数据库SQLSERVER、MYSQL、ORACLE等虽然在目前仍然能够勉强满足存储的需求,但仍需要超大容量存储空间,扩展性存在瓶颈。另一方面,传统的关系数据库在面对海量数据的查询请求时,查询效率已经严重影响了系统的性能[9]。
云计算的诞生导致了云存储的出现。云存储是指在分布式文件系统的基础上,利用网络进行数据传输,然后在计算机群集的调度下进行数据存储的一种存储方式。通过这种方式,各种不同的计算机设备和存储介质都能够经由网络而整合起来,提供存储服务。云存储的特点有:主要面向海量的数据存储,提供高性能的存储与访问服务,容错性高,可扩展性强,能够运行在普通的计算机组成的群机上[10]。
常用的PC机或者一般的存储介质就可直接通过网络环境构造成为Hadoop平台。Hadoop平台下的HDFS系统拥有以下特性:(1)分布式存储架构能有效解决硬件失效时的数据丢失问题;(2)采用批处理数据访问方式,能够高效处理海量数据;(3)海量的数据存储空间,满足TB、PB级别数据的存储需求;(4)一次写,多次读的读写方式大大降低错误率;(5)采用“移动计算”的方式,减小网络负载;(6)跨平台、跨软件设计,保证在不同软硬件环境下有效运行[11-12]。
如图1所示,Hadoop平台采用了一种Master和Slave的方式。Master是所有Slave节点的指挥中心,它并不参与具体的数据存储操作。仅仅只是当有存储或者读取请求时将其引导到对应的数据节点上操作,元数据表就存放在Master服务器上。
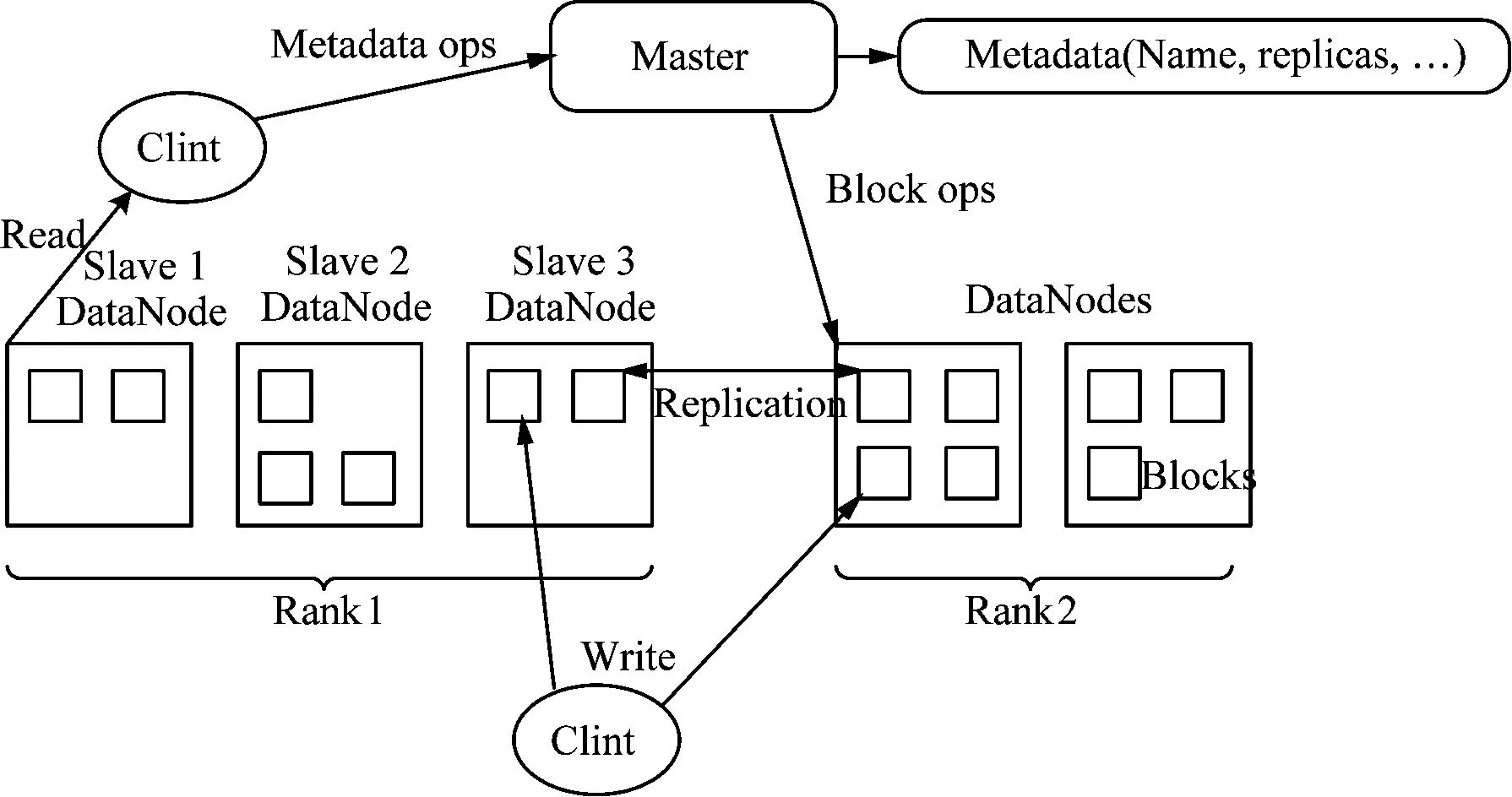
图1 Hadoop 上的 HDFS 结构Fig.1 Structure of HDFS in Hadoop
Slave节点就是实际存储数据的节点。在Hadoop系统中,Mater Node与SlaveNode是一对多的关系,单台PC允许放置1个或多个SlaveNode,如图1所示系统结构。Hadoop分布式文件存储系统是跨平台电网规划数据高效存储与索引的重要支撑技术。虽然现有Hadoop体系存在负载均衡、中断续写、系统权限等方面的不足需要改进,但该存储体系具有快速读写、海量存储、高扩展性、跨平台兼容等优越性,适合多种业务和数据类型的海量电网规划数据的存储,而且HDFS分布式文件存储体系可以采用普通PC作为数据节点,具有较高的经济性。
3 跨平台电网规划数据融合与存储体系架构
针对上述研究与分析,本文提出跨平台电网规划数据融合与存储体系架构,该体系架构针对电网规划体系包含的规划、评审、技经平台,涉及数据模型与接口、数据挖掘与融合处理、分布式数据存储以及高效联合索引机制、数据安全管理与服务等关键技术,如图2所示。
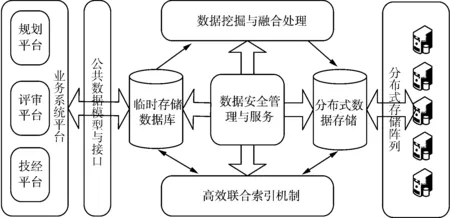
图2 跨平台电网规划数据融合与存储体系架构示意图Fig.2 Cross-platform data fusion and storage architecture of power grid planning
在该体系架构中,首先针对来自不同业务系统平台的异构数据进行统一的公共数据信息建模,在电力系统原有的CIM模型基础上,扩展各个系统所包含的特征类,并根据业务需求定期更新业务数据信息模型。经由统一的数据模型进行模型化后的数据融合、存储与索引流程。
数据更新上传至临时存储库后,根据不同数据对应的类标签进行特征提取,进一步进行融合聚类分析。将数据根据不同的特征进行聚类处理后存入分布式数据库即相应的存储阵列。在各平台业务应用需要相关数据时,首先发送数据索引请求至数据库,根据索引类型所对应的数据标签,采用高效的联合索引机制快速搜寻需要的数据至临时数据库,在确认数据信息的准确性后通过安全接口由各业务系统平台直接调用。临时数据库则根据业务需求的优先级来分配数据任务,并实时更新任务计划,保证数据实时、准确的处理和应用。
为保证数据的安全与可靠,整个数据的融合、存储与索引流程需要数据安全管理与服务系统全程的管理和监控,数据的安全管理不仅能防止隐私和机密数据的泄露,还能反馈整个系统在数据处理和存储过程中存在的问题,对于操作人员对系统进行定期维护和进一步改进至关重要。
4 结 论
本文在分析现有业务系统数据格式及存储现状的基础上,深入研究异构数据融合与存储的关键技术,并提出一种跨平台电网规划数据融合与存储模式。通过建立统一业务数据信息模型,完成异构数据的融合处理;构建基于Hadoop的分布式文件存储系统,高效快速地实现海量异构数据的存储与索引。为电网规划系统乃至电力行业的海量异构数据与信息共享提供理论指导与体系架构支撑。
[1]黄平,李晖,冯建雷,等.电网规划研究平台建设经验和未来发展方向[J].电力建设,2012,33(8):31-34.Huang Ping , Li Hui , Feng Jianlei , et al.Future development direction and construction experience of power grid planning research platform[J].Electric Power Construction,2012,33(8):31-34.
[2] 黄少滨,杨欣欣,申林山,等.高阶异构数据模糊联合聚类算法[J].通信学报,2014,35 (6):15-24.Huang Shaobin, Yang Xinxin, Shen Linshan, et al.Fuzzy co-clustering algorithm for high-order heterogeneous data [J].Journal of Communications,2014,35 (6):15-24.
[3] 梁艳,刘双广,劳定雄.基于solr的异构数据融合检索技术[J].无线互联科技,2013(5):61-64.Liang Yan, Liu Shuangguang, Lao Dingxiong.The retrieval technology of heterogeneous data integration based on solr [J].Academic Journal Electronic,2013(5):61-64.
[4] 王英杰.基于HADOOP的能源数据存储体系中多级索引表DHT算法的研究[D].成都: 电子科技大学,2012.
[5] IEC.Draft IEC 61970: Energy Management System Application Program Interface(EMS-API)-Part 301: Common Information Model(CIM) Base[S].
[6] 刘崇茹,孙宏斌,张伯明,等.面向电力管理系统的公共信息模型研究[J].电力系统自动化,2003,27(14): 45-48, 74.Liu Chongru, Sun Hongbin, Zhang Boming, et al.An investigation on a common information model for energy management system[J].Automation of Electric Power Systems,2003,27(14): 45-48, 74.
[7] 陈勇.基于 Hadoop 平台的通信数据分布式查询算法的设计与实现[D].北京:北京交通大学,2009.Chen Yong.Design and implementation of distributed query algorithm processing communication data based on Hadoop[D].Beijing: Beijing Jiaotong University, 2009.
[8] WU J Y, PING L D.Cloud Storage as the Infrastructure of Cloud Computing[C]//2010 International Conference on Intelligent Computing and Cognitive Informatics, 2010.
[9] 白红伟.基于云计算的电力设备状态监测数据的存储与查询[D].北京:华北电力大学,2011.Bai Hongwei.The storage and inquiry of the condition monitoring data of the electrical equipment based on cloud computing[D].Beijing: North China Electric Power University, 2011.
[10] 谢善益,梁成辉,高新华,等.CIM/CIS互操作细则在多级电网调度中的应用[J].电力系统自动化,2009,33(l): 103-107.Xie Shanyi, Liang Chenghui, Gao Xinhua, et al.Application of CIM/CIS interoperation details in multi-level power grid dispatching[J].Automation of Electric Power Systems,2009,33(1):103-107.
[11] 苏炳洪.面向智能电网的通信体系架构与标准应用研究[D].杭州:浙江大学,2010.Su Binghong.Studies and applications of communication system architecture with standard oriented to smart grid[D].Hangzhou: Zhejiang University, 2010.
[12] 潘毅,周京阳,李强,等.基于公共信息模型的电力系统模型的拆分与合并[J].电力系统自动化,2003,27(15): 45-48.Pan Yi, Zhou Jingyang, Li Qiang, et al.The separation/combination of power system model based on CIM[J].Automation of Electric Power Systems,2003,27(15): 45-48.
(编辑:刘文莹)
Cross-Platform Data Fusion and Storage Pattern of Power Grid Planning
ZHAO Chunhui1, WU Zhili1, JIANG Xin1, CUI Can2, SUN Yi2
(1.State Power Economic Research Institute, Beijing 102209, China;2.School of Electrical and Electronic Engineering, North China Electric Power University, Beijing 102206, China)
With the establishment of each business system platform of power grid planning and the rapid increase of heterogeneous business data, the barriers are badly needed to be broken between business system platforms to establish a perfect business information sharing and interaction system.Based on the analysis of the existing business system data format and the status quo of storage situation, this paper researches the key technology of heterogeneous data integration and storage, and proposes a cross-platform power grid planning data fusion and storage pattern.Heterogeneous data have been fused by establishing a unified business data information model.The distributed file storage system has been established based on Hadoop to implement fast and efficient storage and index of massive heterogeneous data.Thus, the research results can provide theoretical guidance and architecture support for massive heterogeneous data and information sharing in power grid planning system and electric power industry.
cross-platform business; data fusion; Hadoop; heterogeneous data storage
TM 715
A
1000-7229(2015)03-0119-04
10.3969/j.issn.1000-7229.2015.03.021
2014-11-06
2014-12-26
赵春晖(1973),女,硕士,高级工程师,主要从事电力系统软件设计开发、信息化管理工作;
吴志力(1969),男,高级工程师,从事输变电工程规划设计咨询工作;
姜欣(1975),男,工学硕士,从事电网规划设计和电力大数据研究工作;
崔灿(1991),男,博士研究生,主要从事电力大数据关键技术及无线传感器网络等方面的研究工作;
孙毅(1972),男,教授,从事智能电网、电力系统通信以及物联网技术等方面的研究工作。
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
数学大王·趣味逻辑(2021年11期)2021-12-03 11:04:30
测控技术(2018年9期)2018-11-25 07:44:58
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
河南电力(2016年5期)2016-02-06 02:11:32
河南电力(2015年5期)2015-06-08 06:01:46
河南电力(2015年5期)2015-06-08 06:01:46
电测与仪表(2015年21期)2015-04-09 11:52:08
电机与控制应用(2015年1期)2015-03-01 03:49:19
