
对频率与互信息在汉语词典编撰中的作用的实例考察
2015-03-08 02:23余一骄
华中学术 2015年1期
余一骄 贾 凌
(1.2.华中师范大学语言学系,湖北武汉,430079)
对频率与互信息在汉语词典编撰中的作用的实例考察
余一骄1贾 凌2
(1.2.华中师范大学语言学系,湖北武汉,430079)
频率与互信息是近年来汉语新词自动发现中最重要的特征,它们还被列入现代汉语词典编撰选词原则中。本文以《现代汉语词典》(第6版)中全体包含“蛋”字的二字词、三字词为考察对象,分别在北京大学CCL语料库、华中师范大学Cici语料库中统计其频次,计算互信息。对比被收录词和部分未被收录词的频次和互信息却发现:部分被收录词的频次、互信息都比一些未被收录的词低。分析多组频次和互信息数值,可推测在《现代汉语词典》编撰中,词的频次与互信息其实不如词典编撰者的语感关键。
频次 互信息 现代汉语词典 词 短语
一、前言
词典应尽量多地收录词,收录最常用的词。“典型”的汉语词应具有结构稳固、意义凝聚、音节适长等特点[1],然而具有以上特征的汉字组既可能是词,也可能是短语。在现代汉语中,词、短语之间的界限不是很明确[2]。一些意义凝聚且使用频繁的二字组、三字组到底是词还是短语,有时语言学家们的意见也并不一致[3]。词、短语难区分的特点,给汉语词典选词带来诸多挑战。频率是短语词化的一个重要动力[4],汉字组的使用频率对区分词和短语起着关键性作用。另外,由于词典收录的词数有限,哪些词应被优先收录往往也存在争议。
电子词典是在中文信息处理中必需的语言学资源,电子词典的收词数量、质量直接影响中文信息处理结果的准确性。面向中文信息处理用的电子词典开发模式与传统汉语词典编撰模式有很大差异[5]。电子词典大多是先由计算机程序统计汉字组的频次、互信息(Mutual Information)等数值;然后采用特定的判别规则,分析频次、互信息统计结果,从中自动发现备选词集;最后将备选词集提供给语言学本体研究者校验。与之相反,传统的汉语词典选词以人工判断为主,收词原则严格,所收词条数量远低于电子词典。
汉字组的频率对汉语语法化、词法化研究很关键[6]。通过查询大规模真实语料库,获得特定汉字组的使用频次、频次历时变化状况,如今成为汉语语法研究的常见手段。语法化、词法化研究与汉语词典编撰联系紧密,十多年前就有研究者提出:《现代汉语词典》在收词上要充分吸收机器分词的成果,要把词的频度作为一个重要参数加以利用[7]。《现代汉语词典》(第6版)(以下简称为《现代汉语词典》)的收词原则就涉及词的使用频度[8]。《现代汉语词典》应用广泛且具有极高的学术声誉,其收词原则对电子词典开发亦具有重要的指导意义。计算语言学研究有必要研究它的收词原则,以及所收条目的频次、互信息分布特点。
本文通过实验、计算和数据分析,试图回答以下两个问题:第一,《现代汉语词典》所收录词的频次、互信息分布有何特征;第二,选词过程中,频率、互信息与词典编撰者的语感相比,哪个更关键。
二、测试实例与语料库选取
《现代汉语词典》共收条目69 000余条[9]。要对全体词条进行频次统计、互信息计算,工作量太大,本文只能随机挑选部分词条进行考察。鉴于“鸡蛋”“鸭蛋”是词还是短语曾有过长期争议,本文特对涉及“蛋”字的汉字组进行考察。
汉字组的频次是指汉字组在语料库中的出现次数。不同的语料库其语料来源不一致,语料规模也有差异,因此在不同语料库中查询同一个汉字组所获得的频次会不同,计算出来的互信息也不一致。为了避免汉字组的频次信息受单个语料库的影响,我们特意检索两个独立开发的大型语料库:北京大学CCL语料库、华中师范大学Cici语料库。
CCL在线语料库已被汉语研究者使用多年,是国内最具影响的中文语料库。它的现代汉语语料包括509 913 589个汉字,其中“蛋”字出现42 162次[10]。在CCL网络语料库中检索汉字组,语料库检索系统能直接反馈包括该汉字组的语料条数,却不能反馈汉字组在语料库中的总频次。由于在一条检索结果中可能多次出现检索词,例如输入“鸡蛋”得到“这是一个古老的问题,没有鸡何来鸡蛋?但没有鸡蛋又何来鸡呢?”的检索结果。我们需要把CCL反馈的全部检索结果下载到本地电脑,再用汉字组频次统计软件做统计。笔者开发的“中文文本N-gram串统计与检索软件Cici V2.0”具有对指定文本进行任意汉字组频次统计、互信息计算功能,本文研究中用该软件统计来自CCL语料库的检索结果。
Cici是笔者自主开发的现代汉语语料库,包括486 408 743个汉字,其中“蛋”字出现57 988次。Cici包含四大类语料:现当代文学作品、政府公文、新闻、网络小说。虽然它的语料来源不及CCL丰富,但却收录了不少近十年的语料,因此在反映近十年的汉语使用特点方面有一定优势。网络文学在青少年中很流行,Cici包含较多网络文学作品,能反映当前对青少年读者影响巨大的语言风格。过去已用“中文文本N-gram串统计与检索软件Cici V2.0”对Cici的全体语料进行穷尽式的汉字组频次、互信息计算。在本文研究中,只需查询过去的统计结果,就可以快速获得汉字组的频次、互信息。
三、二字词的频次分布
《现代汉语词典》收录了14个“X蛋”格式的二字词以及“脸蛋儿”一词。“脸蛋儿”较多地使用在口语中,书面语中大多使用“脸蛋”。检索CCL和Cici两个语料库,都是“脸蛋”的出现频次远高于“脸蛋儿”。以下把“脸蛋儿”一词作二字词“脸蛋”处理,故被考察的“X蛋”格式的二字词共15个,表1列出了它们分别在CCL和Cici两个语料库中的出现频次。

表1 被收录“X蛋”格式的二字词的频次
从表1可知,“笨蛋”“彩蛋”“捣蛋”“红蛋”“混蛋”“脸蛋”“完蛋”等词在两个语料库中的频次差异显著。不妨以“混蛋”为例,考察语料来源对词汇使用频率的影响。为了吸引青少年读者,网络文学比传统出版的文学作品口语化,且爱使用詈辞。Cici中包含较多网络文学语料,因此“混蛋”等在Cici中的出现频率比在CCL中的出现频率高许多。由此例可知,汉语研究者在考察某个词的使用频率时,其实很有必要查询多个语料库。
“变蛋”“零蛋”在两个语料库中的出现频次均很低,没超过50次。我们曾在华中师大语言学系近50名本科生和研究生中做关于“变蛋”一词的调查,除了一位来自河南的学生明确表示知道该词外,其他学生几乎未曾听说过该方言词。但这位河南籍的学生并不认同《现代汉语词典》上将该词释义为“松花”,而是觉得“变蛋”是一种蛋清为黄色的“皮蛋”。

表2 被收录的“蛋X”格式的二字词的频次
表2列出了《现代汉语词典》收录的13个“蛋X”格式的二字词的频次。“蛋雕”“蛋羹”“蛋青”“蛋塔”“蛋挞”“蛋鸭”的频次很低,没超过60次。“蛋白质”“蛋白酶”等三字词均包括“蛋白”二字。在CCL语料库中“蛋白质”的频次为6 579,“蛋白酶”的频次为386,所以“蛋白”作为二字词的出现频次其实不超过5 088次。鉴于“蛋挞”是近年来从香港、澳门传入内地,并成为日趋常见的食品,它反映了人们生活的新变化。它被收录到词典,尚可以理解。但“蛋雕”“蛋鸭”等词既具有见字明义的特点,又频次极低,为何它们能被收录到《现代汉语词典》有些让人费解。

表3 部分未被收录的“蛋X”或“X蛋”二字组的频次
“鸡蛋”“鹅蛋”“鸟蛋”“咸蛋”“蛋壳”“蛋汤”等在日常生活中使用频繁,它们在CCL和Cici语料库中的使用频次如表3所示。将表3分别与表1、表2做比较,“鸡蛋”“鹅蛋”“鸟蛋”“咸蛋”的频次远比“变蛋”“彩蛋”“零蛋”高。其中,“鸡蛋”和“鸭蛋”的频次差异更值得关注。因为《现代汉语词典》第6版中新增“鸭蛋”一词,却仍没有收录“鸡蛋”。“蛋壳”的频率比“蛋青”“蛋子”等高得多,却没被收录。由此可知,《现代汉语词典》收录的词条并不完全符合高频优先的选词原则。
四、二字词的互信息分布
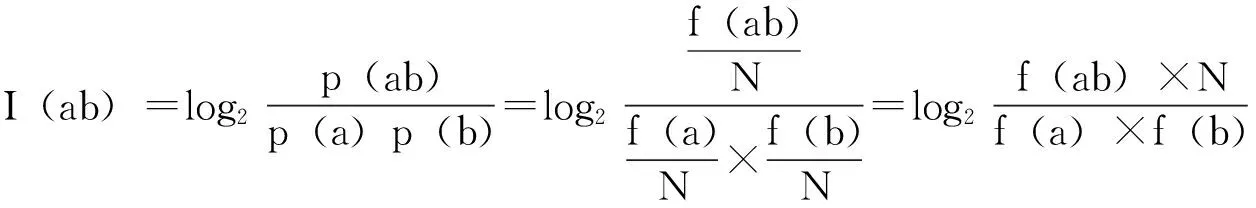
(1)
CCL网络语料库在线提供了现代汉语语料库中各汉字的频次[12],故可直接在其汉字频次表中查询f(a)、f(b)的值。根据公式(1)计算出表1所列“X蛋”格式二字组的互信息如表4所示,“蛋X”格式二字组的互信息如表5所示。“变蛋”一词的互信息在两个语料库中均小于零,自动构建电子词典时这样的二字组,肯定不会列入备选词集。

表4 被收录的“X蛋”格式二字词的互信息
在表4中,“笨蛋”“捣蛋”“混蛋”“脸蛋”“鸭蛋”等互信息很高,容易被电子词典构建软件自动识别,并收录到电子词典。在表5中,“蛋雕”“蛋品”“蛋青”“蛋塔”“蛋子”等的互信息低于2。通常在基于互信息的二字词识别中,互信息低于4的二字组不大会引起识别软件的关注。然而这些词却被《现代汉语词典》收录,这说明电子词典和传统词典的选词标准存在不可忽视的区别。
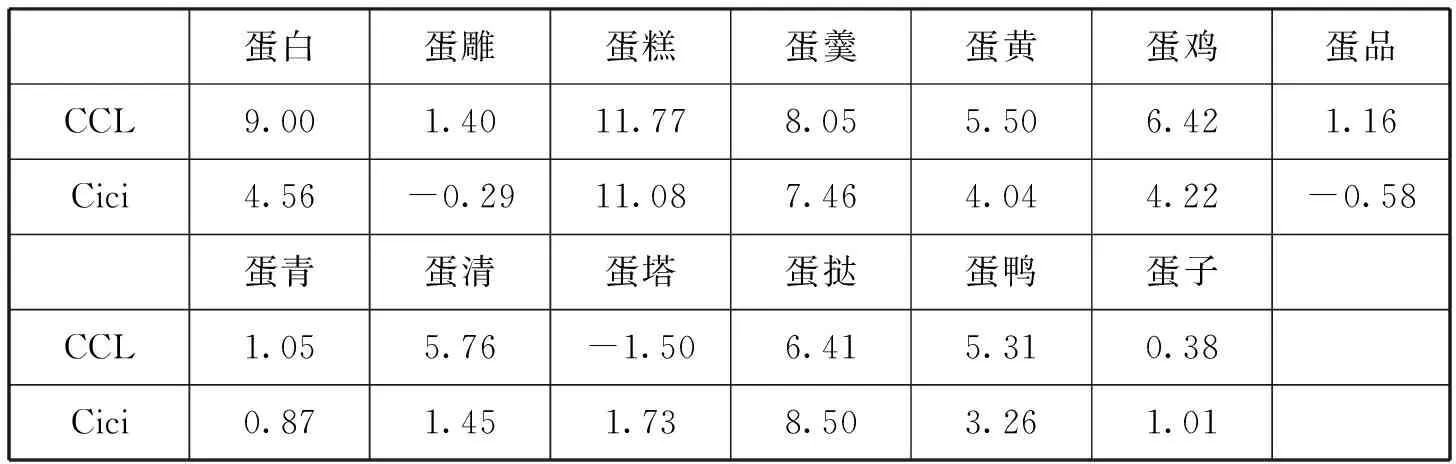
表5 被收录的“蛋X”格式二字词的互信息
表6列出了表3所列二字组的互信息。“鸡蛋”“咸蛋”的互信息比“变蛋”“彩蛋”“红蛋”“零蛋”“下蛋”等高得多;“蛋壳”的互信息比“蛋雕”“蛋青”“蛋塔”“蛋子”等高得多。《现代汉语词典》收录了互信息较低的,却没收录互信息较高的。

表6 部分未被收录的“蛋X”或“X蛋”二字组的互信息
表1至表6中的数据反映了当前中文信息处理中关于词、短语区分的一个尴尬局面。汉语研究者按传统的语言学规则来分辨词和短语,但自20世纪50年代至今,他们越来越觉得仅靠纯语言学信息难以明确分清二者。一些语言学研究者转而期望通过借助频率、互信息等定量、客观的数值特征,来区分词和短语。来自计算机背景的中文信息处理研究者因缺乏系统的语言学知识,大多坚持根据概率、统计学知识,分析汉字组的频次、互信息,从中总结出一些可行且正确率较高的汉语词自动发现算法。然而表4、表5中所列汉语词的互信息值显示:有些汉语词互信息较高,与源自概率理论的汉语词自动发现原则是一致的,但“变蛋”“蛋塔”等语言学家确认是词的互信息却极低。显然,传统词典的选词原则和电子词典的选词原则有冲突,到底哪种原则更适应未来词典编撰的需要,目前还不得而知。
五、三字词的频次和互信息分布
汉语三字组的互信息I(abc)根据公式(2)来计算,其中f(abc)是三字组abc的频次;f(a)、f(b)、f(c)是三个汉字的频次;N是语料库总字数[13]。
(2)
《现代汉语词典》收录了15个包含“蛋”字的三字组,另包含“屁股蛋儿”一词。类似对“脸蛋儿”的处理方式,在此把“屁股蛋儿”当作“屁股蛋”来处理。《现代汉语词典》中没有标注“吃鸭蛋”的词性,因此将其当短语处理。16个包含“蛋”字的三字组在CCL语料库和Cici语料库中的频次和互信息如表7所示。
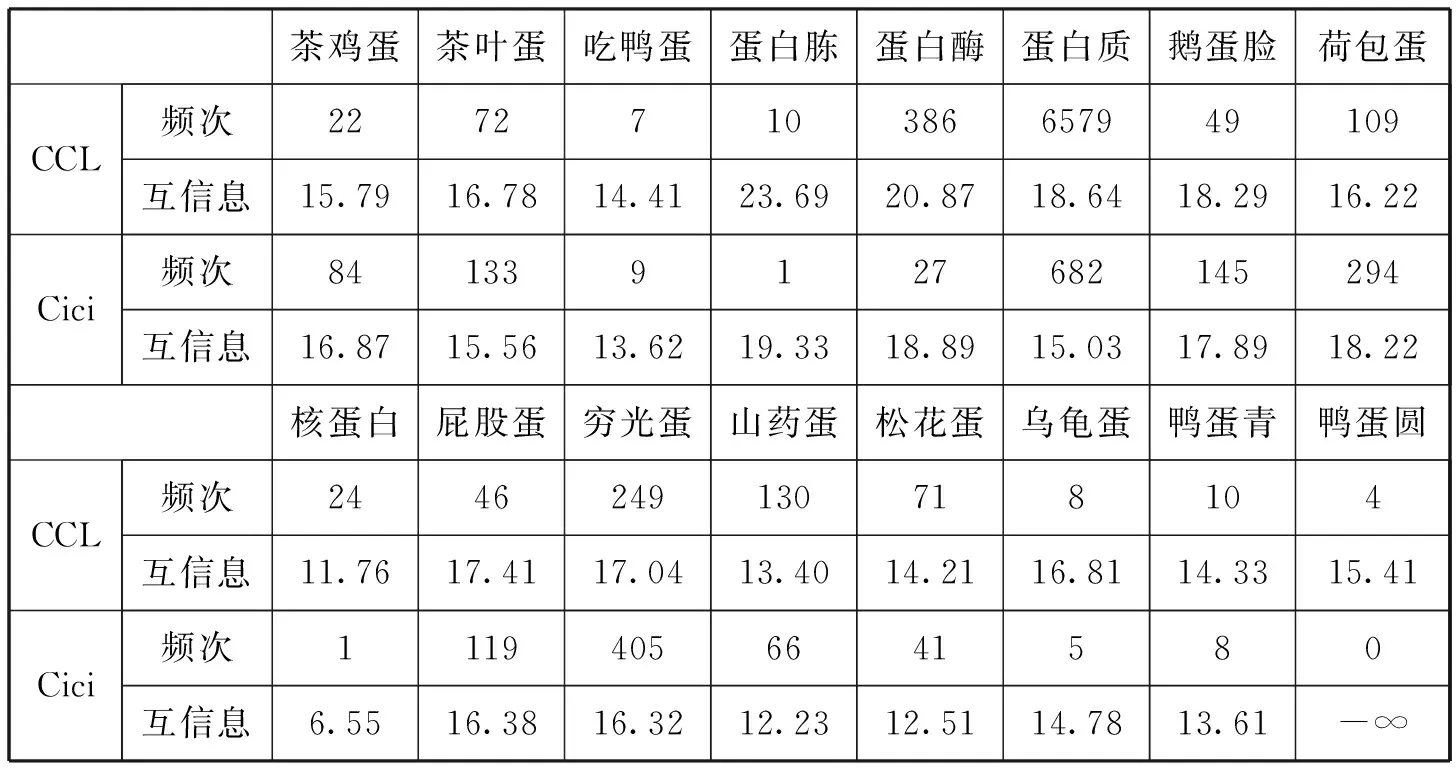
表7 被收录含“蛋”字三字组的频次与互信息
值得指出的是:“鸭蛋圆”在语料库Cici中的频次为0,故其互信息为负无穷大。“吃鸭蛋”“蛋白胨”“乌龟蛋”“鸭蛋青”“鸭蛋圆”等在两个规模约5亿字的语料库中的出现频次不超过10次,其使用频率不到每五千万字出现一次。它们不仅不满足使用频繁的选词原则,其在不同领域的通用程度也值得怀疑。表8列出了一些常见的含“蛋”字的三字组的频次与互信息。比较表8和表7,“王八蛋”“恐龙蛋”“鹌鹑蛋”“土鸡蛋”等在书面语中频繁使用,在口语中更是耳熟能详;它们的互信息比表7中一些三字词的互信息高。无论是定量比较频次和互信息,还是普通百姓的语感,它们似乎更应优先收到词典中。

表8 部分未被收录含“蛋”字三字组的频次与互信息
《现代汉语词典》还收录了“鸡飞蛋打”“借鸡生蛋”“血红蛋白”“鸡蛋里挑骨头”。由于汉语研究中词、短语难分辨主要集中在二字组、三字组,在此不对以上四字组、六字组的频次和互信息做细致分析。
六、结束语
本文考察《现代汉语词典》收录的含“蛋”字的二字词、三字词在CCL和Cici两个语料库中的频次和互信息分布特征,并将其与部分未被收录的汉字组的频次、互信息做对比。实验数据显示,一些高频词没被收录,有些低频词却被收录;一些互信息高的汉字组没被收录,有些互信息极低的词却被收录了。也许在词典编撰过程中,词典编撰者的语感比来自语料库的频次信息更关键。另外,现代汉语研究逐步采用频率、互信息等数值特征来辅助汉语本体研究。如今权威的《现代汉语词典》中的词条频次、互信息分布特点与中文信息处理中的新词自动发现规则有冲突。电子词典自动构建理论缺乏明确的语言学规则指导,阻碍了电子词典开发与传统词典编撰的相互借鉴。语言学研究中该如何看待基于概率统计理论的汉语词自动发现算法,这是一个值得进一步研究的问题。
*本文系教育部人文社会科学研究项目“逻辑推理与词义匹配相融合的中文网页语义检索技术研究”【10YJA740120】的阶段性成果。
注释:
[1] 刘云、李晋霞:《论频率对词感的制约》,《语言教学与研究》2009年第3期,第1~7页。
[2] 胡明扬:《说“词语”》,《语言文字应用》1999年第3期,第3~9页。
[3] 王洪君:《从字和字组看词和短语——也谈汉语中词的划分标准》,《中国语文》1994年第2期,第102~112页。
[4] 刘云、李晋霞:《论频率对词感的制约》,《语言教学与研究》2009年第3期,第1~7页。
[5] Jingshin Chang,Yichung Lin,and Kehyih Su.“Automatic Construction of a Chinese Electronic Dictionary”,ProceedingsofthirdworkshoponVeryLargeCorpora,Cambridge:MIT Press,1995,pp.107~120.
[6] 彭睿:《临界频率和非临界频率——频率和语法化关系的重新审视》,《中国语文》2011年第1期,第3~18页。
[7] 苏新春、顾江萍:《“人”“机”分词差异及规范词典的收词依据——对645条常用词未见于〈现汉〉的思考》,《辞书研究》2000年第5期,第47~54页。
[8] 江蓝生:《〈现代汉语词典〉第6 版概述》,《辞书研究》2013年第2期,第1~19页。
[9] 江蓝生:《〈现代汉语词典〉第6 版概述》,《辞书研究》2013年第2期,第1~19页。
[10] CCL:《现代汉语语料》。[2003年]http://ccl.pku.edu.cn:8080/ccl_corpus/xiandai_char_info.pdf.
[11] 孙茂松、肖明、邹嘉彦:《基于无指导学习策略的无词表条件下的汉语自动分词》,《计算机学报》2004年第6期,第736~742页。
[12] CCL:《现代汉语语料》。[2003年]http://ccl.pku.edu.cn:8080/ccl_corpus/xiandai_char_info.pdf.
[13] 余一骄、尹燕飞、刘芹:《基于大规模语料库的高频汉字组互信息分布规律分析》,《计算机科学》2014年第10期,第276~282页。
猜你喜欢
老友(2021年8期)2021-09-09
作文周刊·小学一年级版(2020年20期)2020-09-02
大连民族大学学报(2020年2期)2020-06-16
小天使·二年级语数英综合(2018年4期)2018-06-29
计算机应用(2016年10期)2017-05-12
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
辞书研究(2014年4期)2015-05-11
弹箭与制导学报(2015年1期)2015-03-11
新课程学习·下(2014年10期)2014-10-21
