
基于模糊C-均值的空间不确定数据聚类
2015-03-07 11:42肖宇鹏何云斌
计算机工程 2015年10期
肖宇鹏,何云斌,万 静,李 松
(哈尔滨理工大学计算机科学与技术学院,哈尔滨 150080)
基于模糊C-均值的空间不确定数据聚类
肖宇鹏,何云斌,万 静,李 松
(哈尔滨理工大学计算机科学与技术学院,哈尔滨 150080)
针对现实世界中样本对象的不确定性及样本对象间界限划分的模糊性,提出基于模糊C-均值的空间不确定数据聚类算法UFCM。但由于UFCM算法在聚类过程中涉及大量期望距离的复杂积分计算,导致UFCM算法性能不理想,进而给出改进算法I-UFCM,将空间不确定对象聚类问题转化为传统的确定对象聚类问题,采用相似度计算公式减少期望距离的计算量,提高聚类结果的质量。实验结果表明,与UFCM和UK-Means算法相比,I-UFCM算法在空间不确定数据集上具有更好的聚类性能,CUP耗时降低了90%以上。
模糊C-均值;不确定数据;概率密度函数;期望距离;质心
DO I:10.3969/j.issn.1000-3428.2015.10.010
1 概述
近年来,随着聚类分析研究的不断深入,以及数据不确定性在实际应用中普遍存在,不确定数据受到越来越多的关注,因此分析和挖掘不确定数据成为当前研究的热点[1-3]。目前,国内外学者多采用概率密度函数对不确定数据进行建模,并在此基础上扩展现有聚类算法实现对不确定数据的聚类分析,例如基于K-M eans算法的UK-Means算法[4]、基于DBSCAN算法的FDBSCAN算法[5]等。但上述算法在衡量样本间相似度时计算量大。针对该问题,文献[6]提出一种基于Voronoi图和R-tree的剪枝策略,但该策略在构造Voronoi图和R-tree时会产生较大的时间开销。文献[7]依据物理学中刚体运动的转动惯量思想,推导出一个相似度计算公式,其效率比传统不确定聚类算法的效率有了较大提高。文献[8]通过子空间划分的方法进行聚类。文献[9]在度量的基础上,结合三角修剪法完成二维空间下不确定数据的聚类。文献[10]通过不确定中心点的计算实现不确定数据的划分。但是上述算法均未考
虑样本间界限划分模糊的问题。
考虑到现实世界中样本对象的不确定性和样本间界限划分的模糊性,使得样本对象更适合软划分。因此,使用模糊聚类来分析数据的不确定性更符合实际情况。其中,模糊C-均值算法是应用最广泛的一种聚类分析方法。该方法依据某个隶属度来划分样本对象,从而使得类内误差平方和目标函数最小。然而,文献[11-12]研究表明:算法易受到初始点和噪声数据的影响,并且在处理不同密度样本数据时存在较大误差。对此国内外研究者基于不同理论提出一系列方法对算法进行改进,例如:文献[12-13]提出基于核聚类和扩展高斯核聚类的算法;文献[14]在模糊 C-均值算法中引入属性权重的概念进行聚类分析;此外,还提出结合人工智能算法[15]和数理统计方法[16]优化模糊聚类算法。以上均是针对确定样本空间数据处理,未考虑空间样本的不确定性。
本文在综合分析不确定数据聚类现状和模糊C-均值算法的基础上,给出基于模糊C-均值算法的空间不确定数据聚类算法(UFCM)。针对空间不确定数据模型在聚类时需要大量积分计算导致算法性能较差的问题,以及传统欧氏距离在衡量样本间相似度时存在的不足,在UFCM算法的基础上提出改进的UFCM算法(I-UFCM)。
2 基于模糊C-均值的不确定数据聚类
2.1 模糊C-均值聚类算法
设数据集X={χ1,χ2,…,χn}为m维空间的一组待聚类样本向量,聚类样本的c个类别为V={V1,V2,…,Vc},c个聚类簇的中心表示为ν={ν1,ν2,…,νc}。用隶属度矩阵 Uc×n=(uij),uij∈[0,1]表示每个样本对各聚类簇的隶属度,其中,i=1,2,…,c;j= 1,2,…,n。2个样本对象 χi,χP之间的欧氏距离定义为:

模糊C-均值算法的目标函数为:
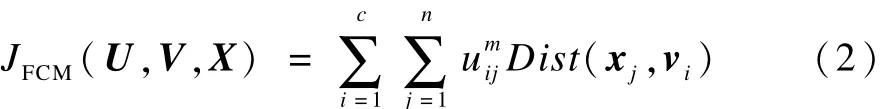
其中,m∈[1,∞)是一个加权指数,随着 m的增大,聚类的模糊性增大。根据拉格朗日数乘法,求得使目标函数在满足约束条件的前提下取得极小值的必要条件:
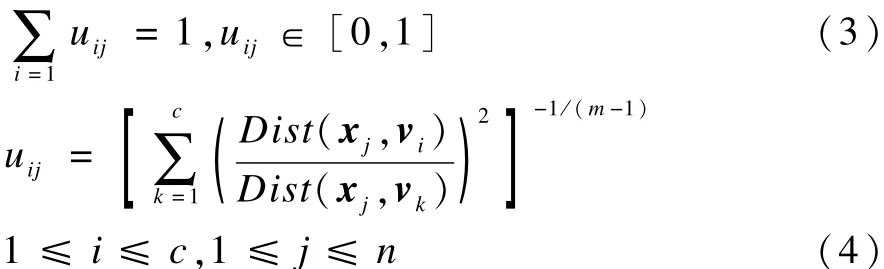
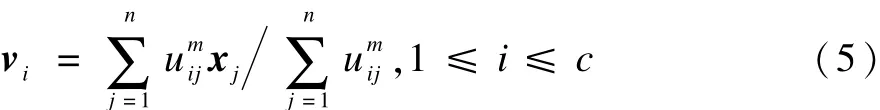
模糊C-均值聚类算法在聚类过程中通过反复迭代式(4)和式(5),使得目标函数式(2)不断减少直至最小。
2.2 空间不确定数据聚类模型
数据的不确定性主要表现在数据是否存在不确定性和数据属性级别的不确定性两方面[10]。在空间不确定数据聚类中,通常使用属性级别的不确定模型,即数据集中每个数据对象的属性不再是确定的数据值,每个数据对象也不再是一个单独的样本点,而是通过一个概率密度函数(Probability Density Function,PDF)来定义不确定区域。概率密度函数详细给出了空间中每个不确定对象可能的位置。
定义1(空间不确定数据) 在m维空间Rm中,给定一组不确定空间数据对象 O={o1,o2,…,on},距离函数d:Rm×Rm→R,对于每个不确定空间数据对象oi,都有一个概率密度函数fi:Rm→R定义不确定对象的分布。根据概率密度函数得到:

通过期望距离衡量不确定对象的相似度。
定义2(期望距离) 不确定空间对象oi和任意点 p的期望距离定义[7]:

由式(7)可得2个不确定空间样本对象间的期望距离。
定义3(不确定对象间的期望距离) 不确定空间对象oi和oj间的期望距离为:

不确定空间数据的聚类分析是对给定的一组不确定对象O及有效聚类数目k,通过映射函数h:{1,2,…,n}→{1,2,…,k}将不确定对象划分到k个聚类簇C={c1,c2,…,ck}中。聚类簇 C中的每个ci为所属簇的代表点。聚类最终使得簇内期望距离和达到最小。
2.3 空间不确定数据聚类算法
对于不确定空间数据对象集合O,聚类的c个类别为OV={OV1,OV2,…,OVc},c个不确定聚类簇中心对象为 oν={oν1,oν2,…,oνc}。不确定空间数据模糊聚类的目标函数为:
其中,ED(oj,oνi)为2个不确定空间数据对象间的期望距离。根据拉格朗日数乘法,求得使目标函数在约束条件式(3)下取得极小值的必要条件为:


基于以上分析提出算法1,即基于模糊C-均值的不确定样本空间数据聚类算法UFCM,具体描述如下:
算法1UFCM算法
输入 n个待聚类的不确定空间样本对象,有效划分数目c,迭代次数t,最大迭代次数T,阈值θ
输出 c个使误差平方和准则最小的聚类簇
Step1 随机选取c个不确定初始聚类中心;
Step2 循环;
Step2.1 根据式(10)计算不确定空间样本的隶属度矩阵U;
Step2.2 由式(11)和矩阵U计算新的不确定对象中心集合oν;
Step2.3 根据式(9)计算目标函数JUFCM,并且t=t+1;
Step4 由最终的隶属度矩阵U划分样本。
UFCM算法在计算样本隶属度矩阵时需要计算不确定空间对象之间的期望距离ED。当不确定空间对象的数量较多或者概率分布函数较为复杂时,式(8)计算复杂、耗时长。此外,UFCM算法基于FCM算法发展而来,传统的模糊C-均值算法在计算样本点间相似度时采用欧氏距离作为衡量标准。这种标准计算方法具有一定局限性,易受到噪声点的影响,并且在处理不同大小和密度样本数据时存在较大的误差。
3 改进的UFCM聚类算法
针对UFCM算法的不足,提出改进的基于模糊C-均值的聚类算法(I-UFCM)。改进算法通过特定转换机制,将不确定空间对象用一个确定的空间样本点表示,将不确定对象的聚类问题转化为经典的确定数据对象的聚类问题。算法采用新的相似度计算公式衡量样本间距,再加上有效的策略,改善传统欧氏距离测定方法的不足,从而提高聚类结果的质量。
3.1 空间不确定数据聚类的确定化
将不确定空间数据确定化,即通过一个样本点ki表示由一组样本点所代表的不确定空间对象 oi,从而将n个不确定空间数据对象聚类问题转化成n个确定空间数据对象的聚类问题。因此,为每个不确定空间对象定义其质心,也称为期望中心。
定义4(不确定对象质心) 对于每个不确定空间对象 oi,oi的分布区域为 Rm,其质心 ki定义如下[8]:

依据物理学中刚体转动惯量思想及依此推导出的平行轴定理,对于空间任意不确定对象 oi及不确定空间中任意点 χP,根据质心式(12)和期望距离式(7)定义新的期望距离计算公式为:
ED(oi,χP)=ED(oi,ki)+D ist(χP,ki) (13)
可见,新的期望距离计算公式只需计算出ED(oi,ki)及Dist(χP,ki),即可快速便捷地计算出ED(oi,χP),从而省去多次计算概率密度函数。
因此,对于不确定空间数据模糊聚类,可以用c个聚类簇中心点ν={ν1,ν2,…,νc}代替原有的c个不确定聚类簇中心对象。此时,不确定空间数据模糊聚类目标函数JUFCM为:

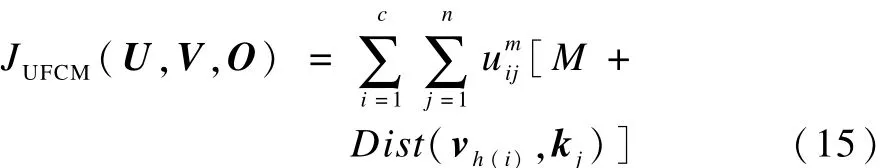
其中,νh(i)表示映射函数h下的聚类簇中心点。对于每一个空间不确定对象oi及其密度函数fi都是定量。因此无需反复计算对象的期望中心距离 ED(oj,kj),并且ED(oj,kj)可事先计算得出且保持不变。因此,ED(oj,kj)可用 M表示,此时目标函数为:
可见,只需给出每个空间不确定对象的质心 kj,而无需考虑每个不确定空间对象的 ED(oj,kj),即可求出目标函数在式(3)约束条件下的极小值。
3.2 相似度计算公式
在处理不同大小和密度样本或有噪声存在的数据时,传统欧式距离存在较大误差[15]。特别是在每次计算聚类簇中心点时,簇中心极易受到簇中样本数据分布密度的影响。由于不确定空间数据整体分布的不确定性,传统的欧氏距离计算方法不适宜应用于不确定数据聚类问题。
本文采用新的样本间相似度衡量标准,即对一组空间样本数据集 X={χ1,χ2,…,χn}有[16]:

其中,β基于统计学知识且由样本数据集计算得出,其定义式为:
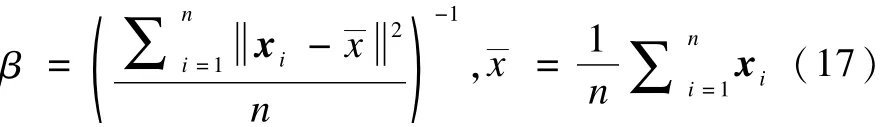
采用新的相似度计算公式,将I-UFCM算法的模糊聚类目标准则函数改写为:
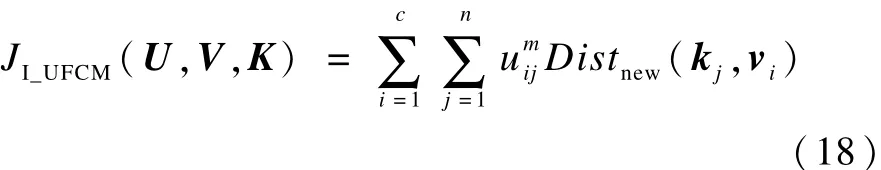
同样,式(15)以式(3)为约束条件构造拉格朗日函数,并求其取得极小值的必要条件为:

3.3 I-UFCM聚类算法
I-UFCM算法计算每个不确定空间对象的质心,并将其质心存入 K中,此外,改进算法选用新的相似度度量标准衡量样本间相似度。I-UFCM算法的具体描述如下:
算法2 I-UFCM算法
输入 n个待聚类的不确定空间样本对象,有效划分数目c,迭代次数t,最大迭代次数T,阈值θ
输出 c个使聚类目标函数最小的聚类簇
Step1 根据式(12)计算每个不确定空间对象的质心,K=ki∪K;
Step2 令t=0,并初始化初始聚类中心点集合,即构造集合 ν={ν1,ν2,…,νc};
Step3 循环;
Step3.1 根据式(19)计算空间样本ki的隶属度矩阵U;
Step3.2 根据式(20)和隶属度矩阵U计算新的样本中心集合ν;
Step3.3 根据式(18)计算每次划分的目标函数JI-UFCM,并且t=t+1;
Step5 由最终的隶属度矩阵U划分样本。
对于n个空间不确定对象,I-UFCM算法首先通过计算式(12),花费O(n)的时间复杂度即可得到n个不确定样本对象的质心。此后,在聚类过程中,I-UFCM算法采用新的相似度衡量准则,其时间复杂度为O(nct),其中,n为不确定空间样本对象的质心;c为聚类划分数;t为算法有效迭代次数。
4 实验结果与分析
本文分别采用UCI数据集和人工模拟数据集对UFCM算法和I-UFCM算法进行实验,并与传统的UK-Means不确定聚类算法进行对比。实验采用F-measure(F)作为聚类外部评测标准,同时从类间距和类内距出发,采用内部评测标准评测聚类效果。
4.1 不确定数据集的构造
实验中所采用的UCI数据集的特征参数如表1所示。

表1 UCI实验数据集的特征参数
为在UCI基础数据集的基础上构造不确定数据集,需要添加一个不确定数据生成策略。为每个数据源中的样本数据定义一个概率密度函数fi,使每一个样本对象由一组样本点来表示,而每个样本点都对应一个概率值,即每一个样本对象oi,有:
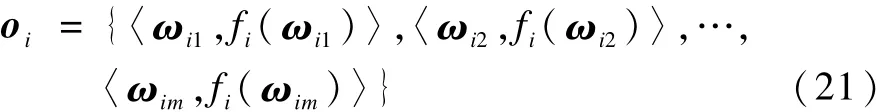
其中,ωim为不确定对象oi的一个样本点;fi(ωim)是与每个样本相对应的概率
此外,为对比算法性能,需构造一组人工模拟数据集。人工模拟数据是在二维空间[0,l]×[0,l]中生成n个空间不确定对象的数据集。对于每一个不确定对象 oi,在边长 d的正方形包围框中,随机生成m个样本点,并且为每个样本点赋一个介于0和1之间的均匀分布概率值。将 m个样本点的概率值标准化,使其总和为1。从而构造一组在[0,l]×[0,l]中的 n个二维空间不确定对象的数据集。
4.2 结果分析
实验对传统UK-Means算法及本文提出的UFCM算法、I-UFCM算法分别进行50次独立聚类实验,记录每次实验结果,求其平均值并对比3个算法的实验结果,如表2所示。在表2中,F-AVG(C,C~)为聚类外部评测标准F-measure(F)指标,其值越高则说明算法聚类的效果越好;Q-AVG(C)为类内距和类
间距的指标合并,即Q(C)=intra(C)-inter(C)。由于将类内距intra(C)和类间距inter(C)标准化后其范围均在[0,1]内,因此 Q(C)取值范围在[-1,1]之间。

表2 聚类算法有效性对比
结果显示,对Iris,Wine和Glass 3组数据集的空间不确定对象的聚类划分中,UFCM算法和I-UFCM算法的F平均指标及Q平均指标均高于传统UK-Means算法。对于Balance数据集,UFCM算法的聚类 F平均指标及 Q平均指标略低于UK-Means算法。而改进后的I-UFCM算法在对Balance数据集的实验中,表现出更优越的聚类能力,其F平均指标和Q平均指标都高于UK-Means算法和UFCM算法。
此外,构造多个人工模拟2D空间不确定数据集测试算法的性能。对于有效聚类数k值及不确定样本对象具有相同的 m个样本点时,为公平地评价算法性能,假设3个算法在聚类初始时均选取一致的初始聚类中心点。图1反映了在有效聚类数k值确定的情况下,3个算法在不同规模的样本数下的CPU耗时情况。

图1 有效聚类数相同情况下的CPU耗时
图1显示本文提出的UFCM算法与UK-Means算法的耗时大体一致。而改进后的I-UFCM算法由于简化了期望距离ED的计算复杂度,其CPU耗时相比传统UK-Means算法和UFCM算法降低了90%以上。此外,IUFCM算法的耗时基本花费在计算不确定样本对象的质心上,然而不确定空间对象质心的计算只需一次。一旦不确定样本数据的质心计算完成,算法只需花费很少的时间完成空间聚类。
在空间不确定对象数量n和有效聚类数k值确定的情况下,图2给出每个不确定样本对象 oi在不同样本数m下,3个算法的CPU耗时情况。同样,在初始聚类时 3种算法均选取一致初始聚类中心点。

图2 空间不确定对象数相同情况下的CPU耗时
由图2可知,当每个空间不确定对象 oi的样本数m增大时,3个算法的CPU耗时也随之增加。在计算每个不确定空间对象oi时,改进后的I-UFCM算法的计算量和质心计算随着样本点数m的增加而增大。当质心一旦确定,空间不确定对象聚类问题就可简化成精确点的聚类问题,因此,I-UFCM算法的CPU耗时仍小于传统UK-Means算法和UFCM算法。
5 结束语
本文在模糊C-均值聚类的基础上,提出面向空间不确定数据的聚类算法UFCM。然而由于空间不确定对象模型的复杂度高,UFCM算法在聚类过程中涉及大量期望距离的复杂积分计算,导致UFCM算法性能不理想,进一步给出改进的I-UFCM算法。I-UFCM算法将不确定空间聚类问题确定化,使用新的相似度衡量方式弥补传统欧氏距离的不足,并通过实验结果验证了I-UFCM的正确性,并表明其对空间不确定数据聚类的研究具有借鉴作用。下一步将对基于连续性概率密度函数的不确定数据聚类分析进行相关研究。
[1] 张志兵.空间数据挖掘及其相关问题研究[M].武汉:华中科技大学出版社,2011.
[2] Aggarwal C C,Yu P S.A Survey of Uncertain Data Algorithm s and Applications[J].IEEE Transactions on Know ledge and Data Engineering,2009,21(5):609-623.
[3] Jiang Bin,Pei Jian,Tao Yufei,et al.Clustering Uncertain Data Based on Probability Distribution Similarity[J]. IEEE Transactions on Know ledge and Data Engineering,2013,25(4):751-763.
[4] Chau M,Cheng R,Kao B,et al.Uncertain Data Mining:An Example in Clustering Location Data[C]// Proceedings of PAKDD’06.Berlin,Germ any:Springer,2006:199-204.
[5] Kriegel H P,Pfeifle M.Density-based Clustering of Uncertain Data[C]//Proceedings of the 11th ACM SIGKDD International Conference on Know ledge Discovery in Data Mining.New York,USA:ACM Press,2005:672-677.
[6] Kao B,Lee S D.Clustering Uncertain Data Using Voronoi Diagrams and r-tree Index[J].IEEE Transactions on Know ledge and Data Engineering,2010,22(9):1219-1233.
[7] Lee S D,Kao B,Cheng R.Reducing UK-means to K-means[C]//Proceedings of the 7th IEEE International Conference on Data Mining Workshops.Washington D.C.,USA:IEEE Press,2007:483-488.
[8] Günnemann S,Kremer H,Seidl T.Subspace Clustering for Uncertain Data[C]//Proceedings of 2010 SIAM International Conference on Data Mining.[S.l.]:Society for Industrial and Applied Mathematics,2010:385-396.
[9] Ngai W K,Kao B,Cheng R,et al.Metric and Trigonometric Pruning for Clustering of Uncertain Data in 2D Geometric Space[J].Information Systems,2011,36(2):476-497.
[10] Gullo F,Tagarelli A.Uncertain Centroid Based Partitional Clustering of Uncertain Data[J].Proceedings of the VLDB Endowment,2012,5(7):610-621.
[11] Nazari M,Shanbehzadeh J,Sarrafzadeh A.Fuzzy C-means Based on Automated Variable Feature Weighting[C]//Proceedings of International Multi Conference of Engineers and Computer Scientists.Calgary,Canada:International Association of Engineers,2013:13-15.
[12] Ramathilagam S,Huang Yueh-Min.Extended Gaussian Kernel Version of Fuzzy C-means in the Problem of Data Analyzing[J].Expert System s with Applications,2011,38(4):3793-3805.
[13] 王 亮,王士同.基于成对约束的动态加权率监督模糊核聚类[J].计算机工程,2012,38(1):148-150.
[14] 王丽娟,关守义,王晓龙,等.基于属性权重的Fuzzy CMean算法[J].计算机学报,2006,29(10):1797-1802.
[15] Qu Jianhua,Shao Zengzhen,Liu Xiyu.Mixed PSO Clustering Algorithm Using Point Symmetry Distance[J].Journal of Computational Information Systems,2010,6(6):2027-2035.
[16] Wu Kuo-Lung,Yang Miin-Shen.Alternative C-means Clustering Algorithms[J].Pattern Recognition,2002,35(10):2267-2278.
编辑陆燕菲
Clustering of Space Uncertain Data Based on Fuzzy C-means
XIAO Yupeng,HE Yunbin,WAN Jing,LI Song
(School of Computer Science and Technology,Harbin University of Science and Technology,Harbin 150080,China)
Aiming at the uncertainty of sample object in real world and the fuzzy boundary between sample objects,this paper proposes a Uncertain Fuzzy C-Means(UFCM)algorithm.Because of a lot of complex integral calculation in expected distance computation,UFCM algorithm is inefficiency.Further,an improved algorithm called I-UFCM is proposed.In this algorithm,the spatial uncertain objects are transformed into the traditional certain objects for clustering. Besides,a new formula for calculation similarity is introduced instead of traditional Euclidean norm to evaluate the distance between objects.The quality of clustering results is improved by reducing the computational amount of excepted distance.Experimental results demonstrate the clustering performance of I-UFCM algorithm is more effective than UFCM and UK-Means algorithm,and its CPU time is reduced by 90%.
fuzzy C-means;uncertain data;probability density function;excepted distance;centroid
肖宇鹏,何云斌,万 静,等.基于模糊 C-均值的空间不确定数据聚类[J].计算机工程,2015,41(10):47-52.
英文引用格式:Xiao Yupeng,He Yunbin,Wan Jing,et al.Clustering of Space Uncertain Data Based on Fuzzy C-means[J].Computer Engineering,2015,41(10):47-52.
1000-3428(2015)10-0047-06
A
TP18
黑龙江省自然科学基金资助项目(F201014,F201134,F201302);黑龙江省教育厅科学技术研究基金资助项目(12531120,12541128,12511100)。
肖宇鹏(1986-),男,硕士,主研方向:空间数据挖掘;何云斌(通讯作者),教授;万 静,教授、博士;李 松,副教授、博士。
2014-09-24
2014-11-13E-m ail:pengF-14@163.com
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
北京航空航天大学学报(2021年4期)2021-11-24
测绘科学与工程(2016年4期)2016-04-17
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
数学年刊A辑(中文版)(2014年4期)2014-10-30
航天器工程(2014年5期)2014-03-11
郑州大学学报(理学版)(2014年4期)2014-03-01
测绘科学与工程(2014年2期)2014-02-27
测绘科学与工程(2013年1期)2013-03-11
