
基于B/S模式的GPU集群管理系统设计
2015-03-07 11:42:43张树本
计算机工程 2015年10期
康 雷,张树本,杨 坚
(中国科学技术大学自动化系,合肥 230027)
基于B/S模式的GPU集群管理系统设计
康 雷,张树本,杨 坚
(中国科学技术大学自动化系,合肥 230027)
普通PC机上搭载的GPU显卡存在功耗低、性能差的问题,不能满足大规模统一计算设备架构(CUDA)并行计算的需求。为此,将计算密集型任务转移到GPU集群中完成,设计并实现基于B/S模式的GPU集群管理系统,用户通过网页提交CUDA代码即可得到GPU集群计算后的结果。测试结果表明,该系统可使用户在任何能使用浏览器的电子设备上完成基于CUDA的计算密集型任务,不仅方便用户使用,而且能加速程序的运行过程,提高工作效率。
GPU集群;统一计算设备架构;B/S模式;资源管理;任务调度
DO I:10.3969/j.issn.1000-3428.2015.10.002
1 概述
GPU在并行计算处理能力上大大超过了CPU,而且随着NVIDIA公司的统一计算设备架构(Compute Unified Device Architecture,CUDA)[1]的推广也使得GPU逐渐走向成熟。然而,普通PC机上搭载的显卡功耗低、性能差,往往不能满足大规模CUDA并行计算的需求。随着多核技术的发展和集群计算的应用,GPU集群系统针对计算密集型任务在速度上有更大优势。
当前大多数作业管理系统都是针对CPU核进行调度的[2-3]。对于计算密集型任务,CPU核的服务器和 GPU核的服务器相比,功耗更大、热量更多,计算效率反而更低。因此,出现了单CPU+单GPU的资源调度系统[4]和单结点 GPU和多核CPU协同计算的系统[5],而GPU集群服务系统的研究目前还比较少。文献[6]研究了 3D建模在GPU集群上的应用,体现出GPU集群处理计算密集型任务的优势。文献[7]提出了GPU集群调度管理系统,但该系统采用的是C/S模式,不方便用户在各种不同的系统平台上高效执行并行计算任务。文献[8]扩展了资源管理系统TORQUE,使其
可以应用于GPU集群的管理中,但主要偏重于研究GPU集群资源的动态申请、分配与销毁,较少涉及任务调度策略。文献[9]提出了面向 GPU集群的任务自动分配系统,但其所设计的任务分配策略并没有考虑当前GPU集群的运行状态。本文针对GPU集群系统提出一种基于优先级调度策略的任务队列管理方案,同时考虑集群当前运行状态,从而提高任务调度的效率。
2 系统设计
基于B/S模式的GPU集群管理系统设计框图如图1所示。该系统主要由W eb门户、集群管理系统和GPU集群三部分组成。其中,Web门户接收用户任务请求,并提交给集群管理系统;集群管理系统调度用户提交的任务,同时维护GPU集群状态,该系统由任务队列、GPU集群资源管理模块、任务调度模块和GPU状态采集模块四部分组成;GPU集群执行任务请求并向用户返回结果。

图1 GPU集群管理系统整体设计框图
2.1 任务队列管理模块
任务队列管理模块的作用是把用户提交的CUDA任务作业根据优先级调度策略放入到任务队列中。本文系统采用的优先级调度策略根据用户申请的优先级、提交任务的时间和用户提交任务的频率把用户提交的CUDA任务作业进行排序并放入任务队列中。
本文系统分别给用户提供普通权限和优先级权限。新用户注册默认是普通权限,优先级权限需要和管理员申请,而且比例不能超过1%。
为了防止优先级用户使用频率过高使得整体用户使用性能降低的问题,提出了任务日志记录的方案,把当天(0:00-24:00)每个执行完的任务都记录在任务日志中(如图2所示),包括用户ID、作业ID和使用时间。用户ID是提交该任务的用户的ID,作业ID是任务队列管理模块在把用户提交的任务放入任务队列的时候分配给任务的 ID号,使用时间是该任务在GPU中运行的时间,即使用的GPU时间。

图2 任务日志
如果一个任务被分配给某个GPU,运行过程中GPU内存占用不断增大并使得GPU内存资源的95%被占用时,为了确保其他程序可以得到正确的结果,会暂时把这个任务停止掉,然后,把这个任务排放在任务队列的首位,重新分配GPU资源占用最少的GPU去执行。
2.2 GPU状态采集模块
GPU状态采集模块周期性获取GPU集群上所有GPU的状态信息(例如GPU使用率等),保存到GPU设备状态表中(如图3所示),并通知任务调度模块读取GPU设备状态表信息。状态采集可以通过nvidia-sm i命令实现。
管理系统根据GPU设备状态表查找出空闲的GPU设备予以分配。由于采集GPU状态的过程也是要消耗计算资源的,因此GPU状态采集模块采取的策略是:当任务调度模块从任务队列中取出一个任务的时候,GPU状态采集模块执行一次采集任务,将采集到的所有GPU信息传递给任务调度模块。
2.3 任务调度模块
任务调度模块从任务队列中取出一个任务,根据GPU集群资源管理模块给出的策略,选定目标GPU,并将任务分配到这个目标GPU中运行,并更新任务状态表(如图4所示),绑定用户 ID、使用的GPU设备ID和任务编号。

图4 任务状态表
2.4 GPU集群资源管理模块
GPU集群资源管理模块根据GPU状态采集模块周期性采集的数据,选出当前使用率最低的GPU,并将该GPU设备ID传给任务调度模块,使任务调
度模块优化调度,达到公平和高效的目的。
2.5 GPU计算单元
GPU是图形处理单元,适合于大规模数值并行计算,但必须和CPU配合工作使用。在CPU+GPU体系结构中,CPU负责逻辑处理,GPU负责计算密集型的数值处理,也就是说,CPU负责把需要GPU处理的任务和数据传递给GPU,GPU处理后把结果返回给CPU进程。
GPU卡有4种工作模式:默认模式,进程独占模式,线程独占模式,禁用模式。默认模式是共享模式,即允许多个进程使用同一个GPU设备。本文设定GPU卡工作模式为共享模式。
3 系统实现
3.1 任务队列管理模块
任务队列资源调度流程如图5所示。

图5 资源调度流程
下面的checkUser函数检查用户在当下是否具有高级用户权限,返回值0表示是普通用户权限,返回值1表示是优先级用户权限。


log列表是任务日志(如图2所示),保存的是当天(0:00-24:00)用户提交任务和任务运行情况。这里主要针对优先级用户,如果优先级用户在单位时间内因运行CUDA代码而使用的GPU时间超过一定阀值(本例中使用1/50),则认为该优先级用户使用优先权限过于频繁,为了公平原则,把该优先级用户当作普通用户对待,优先级用户提交的任务放入任务队列尾部。直到该优先级用户使用GPU的时间小于设定的阈值的时候,才会恢复其优先权限。这样,在最大程度上保护了所有用户的公平,使整体效率最高。
3.2 GPU状态采集模块
本文基于nvidia-smi采用python3语法写了一个GPU状态监测模块代码checkGPUs.py,主要函数如下:

程序运行示例如图6所示。
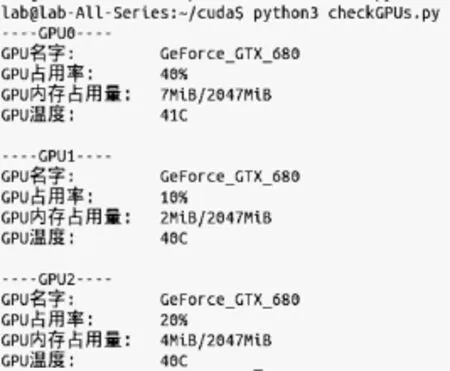
图6 GPU状态采集模块代码运行结果
3.3 CUDA程序执行
CUDA程序如下:


本文系统采用多线程方式运行CUDA程序,充分利用GPU资源并且防止程序阻塞。task列表是待执行的任务队列,每个元素包括用户ID、作业ID和作业使用的GPU设备编号;resultTable列表是执行完毕后保存任务结果的队列,每个元素包括用户ID、作业运行结果和使用的GPU设备编号。
4 实验验证
本文系统的原型实验系统采用5台Intel i7-4770 CPU的服务器,每台挂载2个NVIDIA Geforce GTX680显卡,操作系统Ubuntu 12.04 64位,编译环境CUDA 6.0。
本文注册了10个模拟用户,1个享有最高优先级,其余9个是默认优先级。因为网页采用cookie方式[10]存储用户登录信息,所以必须打开 3个不同的浏览器才能模拟3个用户。根据文献[11-13]提出的算法,写出100×100矩阵乘法 CUDA代码,并将其作为测试样例代码,测试界面如图7所示,最上面的导航条是提供用户登录操作的,登录进来后可以在线上传CUDA代码在GPU集群中运行。

图7 用户提交CUDA代码并获得结果的网页界面
图7左侧上半部分是CUDA代码填写区域,左侧下半部分是程序运行后的输出区域,如果代码出错,错误信息也会显示在这里。测试结果如表1所示。

表1 GPU集群服务器示例输出信息
5 结束语
本文将计算密集型用户任务转移到GPU集群系统中完成,设计并实现了基于B/S模式的GPU集群管理系统。同时,针对集群系统管理提出了一种基于优先级调度策略的任务队列管理方案,使得任务调度更加高效。下一步将对基于节能调度[14]的大规模GPU集群系统进行研究。
[1] Nickolls J,Buck I,Garland M,et al.Scalable Parallel Programming with CUDA[J].Queue,2008,6(2):40-53.
[2] Yoo A B,Jette M A,Grondona M.SLURM:Sim p le Linux Utility for Resource Management[C]//Proceedings of JSSPP’03.Berlin,Germany:Springer,2003:44-60.
[3] Staples G.TORQUE Resource Manager[C]//Proceedings of ACM/IEEE Conference on Supercomputing. New York,USA:ACM Press,2006:8.
[4] 张 繁,王章野,姚 建,等.应用GPU集群加速计算蛋白质分子场[J].计算机辅助设计与图形学学报,2010,22(3):412-419.
[5] 沈 莉,陈 林.一种CPU+GPU资源调度系统的研究[J].高性能计算发展与应用,2011,(1):28-31.
[6] Newall M,Holm es V,Lunn P.GPU Cluster for Accelerated Processing and Visualisation of Scientific and Engineering Data[C]//Proceedings of Science and Information Conference.Washington D.C.,USA:IEEE Press,2014:140-145.
[7] 李文亮.GPU集群调度管理系统关键技术的研究[D].武汉:华中科技大学,2011.
[8] Prabhakaran S,Iqbal M,Rinke S,et al.A Dynamic Resource Management System for Network-attached Accelerator Clusters[C]//Proceedings of the 42nd International Conference on Parallel Processing. Washington D.C.,USA:IEEE Press,2013:773-782.
[9] 胡新明,盛冲冲,李佳佳,等.面向通用计算 GPU集群的任务自动分配系统[J].计算机工程,2014,40(3):103-107,119.
[10] 王小红.基于Cookie的单点登录认证机制实现[J].重庆工商大学学报:自然科学版,2014,31(8):73-78.
[11] 梁娟娟,任开新,郭利财,等.GPU上的矩阵乘法的设计与实现[J].计算机系统应用,2011,20(1):178-181.
[12] 刘进锋,郭 雷.CPU与GPU上几种矩阵乘法的比较与分析[J].计算机工程与应用,2011,47(19):9-11.
[13] 马梦琦,刘 羽,曾胜田.基于CUDA架构矩阵乘法的研究[J].微型机与应用,2012,30(24):62-64.
[14] 李 新,贾智平,鞠 雷,等.一种面向同构集群系统的并行任务节能调度优化方法[J].计算机学报,2012,35(3):591-602.
编辑 金胡考
Design of GPU Cluster Management System Based on B/SM ode
KANG Lei,ZHANG Shuben,YANG Jian
(Department of Automation,University of Science and Technology of China,Hefei 230027,China)
Due to the low power and poor performance on an ordinary PC equipped with the graphics card,it can not meet the needs of large-scale Compute Unified Device Architecture(CUDA)parallel computing.Aiming at these problems,the compute-intensive user tasks are transferred to the GPU cluster system,the GPU cluster management system is designed and implemented based on B/S mode.The user submits the CUDA code through the web and gets results from the GPU cluster management system.Test result show s that the compute-intensive tasks can be done on any browserbased electronic devices.It brings convenience for the users,accelerates the process of running the program,saves the users’time and greatly improves the users’efficiency.
GPU cluster;Compute Unified Device Architecture(CUDA);B/S mode;resource management;task scheduling
康 雷,张树本,杨 坚.基于B/S模式的GPU集群管理系统设计[J].计算机工程,2015,41(10):6-9.
英文引用格式:Kang Lei,Zhang Shuben,Yang Jian.Design of GPU Cluster Management System Based on B/S Mode[J].Computer Engineering,2015,41(10):6-9.
1000-3428(2015)10-0006-04
A
TP311
国家自然科学基金资助重点项目(61233003);国家自然科学基金资助面上项目(61174062);中央高校基本科研业务费专项基金资助项目(WK 2100100021)。
康 雷(1990-),男,硕士研究生,主研方向:多媒体计算;张树本,博士研究生;杨 坚,副教授、博士生导师。
2014-10-19
2014-11-21E-m ail:kanglei@mail.ustc.edu.cn
猜你喜欢
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
制造技术与机床(2019年4期)2019-04-04 12:22:06
军营文化天地(2018年2期)2018-12-15 17:39:08
测控技术(2018年7期)2018-12-09 08:58:00
电子制作(2018年11期)2018-08-04 03:25:40
产品可靠性报告(2017年7期)2017-09-05 09:49:12
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
