
基于SOM-DB-PAM混合聚类算法的电力客户细分
2015-03-07 11:43:33胡晓雪赵嵩正
计算机工程 2015年10期
胡晓雪,赵嵩正,吴 楠
(西北工业大学管理学院,西安 710129)
基于SOM-DB-PAM混合聚类算法的电力客户细分
胡晓雪,赵嵩正,吴 楠
(西北工业大学管理学院,西安 710129)
针对电力客户具有客户数量大、存在孤立点等特点,提出一种适用于对大量电力客户进行快速聚类的SOM-DB-PAM混合聚类算法。该算法利用自组织映射神经网络训练输入数据,以获取代表输入模式且数据量远小于输入数据量的原型向量,使用围绕中心点的切分(PAM)对该原型向量聚类并用Davies-Bouldin指标判定最优聚类个数以保证聚类效果。实验结果表明,与传统聚类算法相比,该算法具有更高的分类正确率,当客户数量较大时,能实现对客户的快速、有效聚类,并减少人为指定聚类个数的盲目性和主观性。
电力客户细分;围绕中心点的划分;自组织映射;混合聚类算法;聚类分析
DO I:10.3969/j.issn.1000-3428.2015.10.056
1 概述
随着电力工业改革的深入推进和智能电网建设的逐步开展,电力客户在电力市场中的地位日益凸显,这一趋势促使供电企业将工作重点转移到客户服务上来,客户服务质量成为制约电力公司发展的关键因素。客户细分是产品差异化战略的一个替代概念[1],其主要思路是找出具有相似人口统计学、行为、价值特征的客户群[2]。 细分战略基于以下逻辑:针对类似客户组成的更小群体的独特需求所采取的营销方式,应当比针对不同客户组成的大市场需求所采取的营销方式更有效率[3]。对市场
条件下的电力客户进行深度细分,有助于供电企业了解客户用电行为,识别价值客户,制定有针对性的服务措施和差异化营销战略,从而提升服务水平。
我国学者主要从供电企业的视角开展基于价值的电力客户细分研究。在细分技术方面,层次聚类和K-means聚类,因为具有操作简单和受大部分统计软件支持的特性,被广泛用于处理细分问题。文献[4]建立了基于层次聚类的电力客户细分模型;文献[5]针对K-means初始条件随机化、容易陷入局部最优解的缺陷提出了一种改进的Hopfield-K-means算法;文献[6]在计算对象到聚类中心距离时考虑了指标权重的影响,提出结合AHP加权的K-means聚类模型;大部分研究采用如下思路:建立电力客户价值评价指标体系;评估客户价值;对价值评分进行分类,此时,研究重点由细分技术转换为评价指标体系的构建和评价方法的选取[7-9]。其中,文献[10-11]分别采用K-means和BP神经网络对电力客户价值评分聚类,后者尝试使用遗传算法优化BP以解决BP存在局部收敛和收敛速度慢的问题。
然而,上述研究均未考虑客户数量大的情形,层次聚类只适用于少量数据,随着客户数的增加,对客户逐个计算价值再聚类将非常耗时,“噪声”和孤立点数据的增多直接影响聚类效果。围绕中心点的划分(Partitioning A round Medoids,PAM)聚类算法克服了K-means对孤立点数据的敏感性,但只适用于对少量客户聚类且需预先确定聚类个数,以往研究大多依据专家经验人为指定聚类数目,具有一定盲目性和主观性。因此,本文针对电力客户具有的客户数多、数据量大、存在孤立数据等特点,提出一种基于SOM-DB-PAM的混合聚类算法,尝试利用自组织映射(Self-Organizing Feature Maps,SOM)神经网络的原型向量表征输入模式的特性,结合PAM对孤立点的容忍能力,使用SOM对大量、多维电力客户数据进行训练,并用PAM对获得的SOM原型向量聚类,用聚类效度指标Davies-Bouldin(DB)确定最优的聚类个数,从而克服上述研究的不足,实现对大量电力客户的自动有效细分。
2 电力客户细分基本思路
遵循细分研究的5个基本主题:问题定义,研究设计,数据收集,数据分析,实施和对结果的理解及每个主题涉及的关键问题[12],本文进行电力客户细分的基本思路如图1所示。

图1 电力客户细分基本思路
在问题定义和研究设计阶段,由于从企业视角开展基于客户终身价值(Customer Lifetime Value,CLV)的电力客户细分研究对供电企业具有重要意义,本文的研究目标设定为:基于客户终身价值、以识别高价值客户为目标的电力客户细分。客户终身价值包含当前价值和潜在价值两部分,筛选衡量电力客户价值的指标构成初始细分变量,由于研究对象是大量客户,用于分析的客户数据主要来源于供电企业电力营销数据库和业务文档中存储的静态电力客户基本信息和动态业务数据,因此为尽量减少不确定因素对细分结果的干扰,在确定最终细分变量时,要基于简明科学性、把握主导因素、变量独立和可量可测的原则[13],还要综合考虑数据的可获取性和数据质量并尽量移除需要人为赋值的定性指标。在实施细分前,需对数据进行预处理。
3 SOM-DB-PAM混合聚类算法
3.1 SOM,PAM和DB算法介绍
自组织映射神经网络SOM是一种同时具备矢量量化和矢量投影功能的无监督神经网络。一个SOM由排列在低维空间(称为输出层)的m个神经元(结点)组成,每个神经元用一个d维权向量Wi=(Wi1,Wi2,…,Wid)表征(d代表输入向量的维数),该权向量被称为原型向量。SOM利用持续迭代的无指导学习对输入数据进行训练,目标是将输入向量映射到与其相似度最高的原型向量表征的结点中并保持数据的拓扑结构不变。SOM可识别输入数据具有自稳性的最显著特征,适用于大样本数据。其缺点表现在:处理小样本数据时,算法的学习效率依赖于样本对象的输入顺序且受到网络连接权重和网络拓扑结构选择等的影响[14]。
K-medoid聚类算法的产生克服了K-means聚类用类中所有对象的均值表征各类中心,均值的计算受“噪声”或孤立点干扰较重的问题。PAM试图确定N个对象的K个划分,是最基础的K-medoid算法之一。PAM用被称为中心点的一组对象代表簇中心以最小化非代表对象和最接近它们的中心点的平均相异度。算法包括2个阶段:
(1)为每个类随机选择一个初始代表对象(中心点),将剩余对象按其与中心点的相异度或距离分配给离它最近的一个类,该过程称为BUILD;
(2)反复用非代表对象替换中心点以提高聚类质量;聚类质量由一个代价函数评估,该函数度量一个非代表对象是否是当前中心点的好的代替,如果是就进行替换,否则不替换,直至聚类质量无法再提高,此过程称为SWAP;详细步骤参见文献[15]。
相比K-means,PAM具有较强的健壮性,对“噪声”和孤立点数据不敏感,由它发现的簇与测试数据的输入顺序无关,能够处理不同类型的数据点。然而它和K-means一样,需事先指定聚类个数,其主要缺点还在于:当数据量较大时算法的效率很低。
确定聚类个数的方法之一是分别使用不同的聚类个数运行聚类算法,使用效度指标度量聚类结果从而判断出类内紧密性和类间分离度最佳的聚类数目[16],Davies-Bouldin(DB)指标是常用的聚类效度指标,描述为:
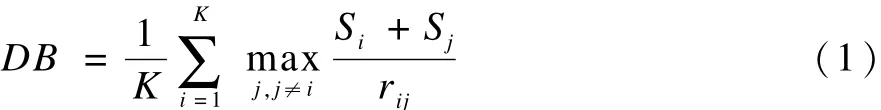
其中,K代表聚类个数;Si描述了一个类中所有点到类中心点的距离的均值;rij代表类i和类j的距离;向量mi表示类Ci的中心点;表示类Ci中包含的对象个数,如式(2)和式(3)所示。DB越小表明类内各对象与类中心距离越小(紧密性)而类间距离(分离度)越大,聚类质量越高。最小的 DB指标所对应的聚类个数即为最优聚类数目。
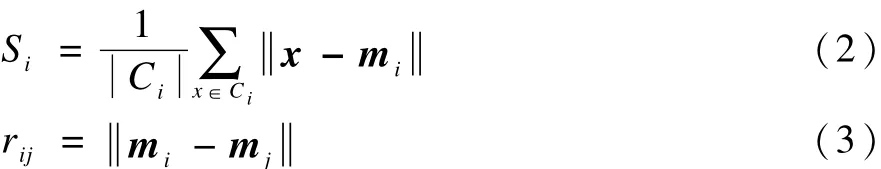
3.2 SOM-DB-PAM混合聚类算法
现有聚类技术有各自的优势和局限,建立在不同技术有效组合或集成思路上的混合聚类技术能扬长避短,是细分技术未来的发展趋势[17]。本文针对电力客户数目大、存在孤立点数据的特点,提出SOM-DB-PAM混合聚类算法,算法包括2个阶段:第1阶段构建SOM对大量输入数据进行训练,得到反映输入数据最主要特征的原型向量;第2阶段使用PAM对所获得的原型向量再度聚类,同时,使用DB指标自动判别最优聚类数目以保证聚类效度,算法流程如图2所示。该算法在集成SOM处理大样本的优势和PAM健壮性的同时克服了人为指定聚类数目存在的困难和主观性。
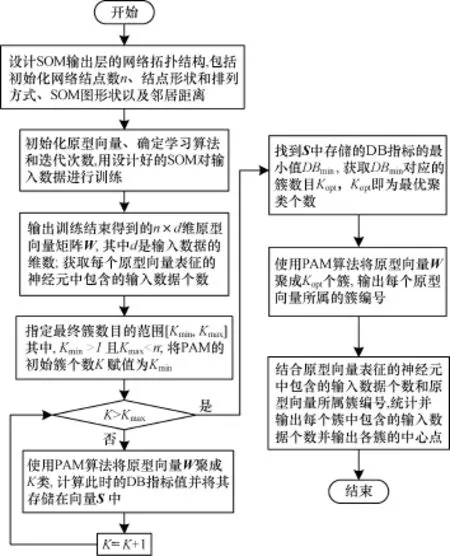
图2 SOM-DB-PAM流程
在实际应用中,由于SOM输出层的网络拓扑结构、原型向量初始化方法和学习算法会影响网络的学习效率,第1阶段初期需指定网络结点数即原型向量个数n,遵循在保留输入数据主要信息基础上尽可能减少第2阶段工作量的原则,n应远小于输入样本个数并尽量大于最终所需的类目数。早期研究表明:超环面和球面SOM拓扑结构能克服平面结构的边缘效应且行列数不相等的输入矩阵比方阵更能准确表达数据特征[18],因此,SOM应选择超环面或球面拓扑结构且避免将输入矩阵设计为方阵;批学习算法具有速度快,可产生更稳定的原型向量值和具备强的可再现能力的优点,采用批学习算法对设计好的SOM进行训练,为提高训练效率,使用线性初始化方法初始化原型向量。在第2阶段中,以设定聚类数目的范围[Kmin,Kmax]代替直接指定最终聚类数,为使细分结果有意义,原则上 Kmin>1且Kmax<n,综合考虑制定营销策略时的实际需要并参考领域专家的经验适当缩小[Kmin,Kmax]区间可提高细分结果的可解释性和PAM的聚类效率。
SOM-DB-PAM混合聚类算法的主要思想是:对N个待聚类对象使用SOM先进行“粗聚类”得到n个初步的类,再用PAM对这n个初步的类进行正式聚类。由于PAM算法的时间复杂度为O(T2× d×K(N-K)2),其中,T2为算法收敛所需的迭代次
数;K为中心点数目,即聚类个数,每计算一次用非中心点替换中心点的代价所需时间为d×K(NK)2,当样本规模N和维数d都很大时,PAM的计算复杂度将非常高,而用电数据量大正是电力客户细分面临的主要问题,以某供电局管辖的居民客户为例,平均每月产生的用电记录数 N>26000,引入SOM进行“粗聚类”后,SOM-DB-PAM算法的复杂度为O(T1×n×d×N)+O(T2×d×K(n-K)2),其中,T1为SOM网络训练所需的迭代次数,由于使用SOM对数据进行“粗聚类”时,最终的聚类结果不依赖于神经元的拓扑位置,网络不需要完全收敛,可设定一个较小的 T1以降低网络的训练时间[19],此时,算法的时间复杂度主要依赖于n,而n远小于待聚类对象个数N,因此,采用SOM-DB-PAM对大量电力客户数据进行聚类,在利用PAM健壮性的同时降低了其计算复杂度。
3.3 SOM-DB-PAM聚类性能测试
由于目前尚没有针对电力客户的可供实验的公开聚类测试数据集,因此为测试SOM-DB-PAM的聚类性能,本文从某电力公司下属供电局的营销信息系统中抽取了120条电力客户用电记录组成仿真数据集进行聚类实验,每条记录由3个细分变量描述,分别为客户当月用电量、当前欠费金额和历史同期用电增长率,依据客户在这3个变量上的不同表现,可将其划分为卓越客户、风险客户和稳定客户3类,每类各包含40条记录,数据集中不含缺失值,但包含一条噪声记录。在实验前,采用线性标准化方法分别对3个细分变量进行了预处理。在SOM-DB-PAM和SOM-DB-Kmeans聚类的第1阶段,初始化 SOM网络结点数为20,结点形状为六边形,按[7×3]矩阵排列,SOM图形状为超环面,初始邻居距离为2;在第2阶段,将最终类目数的区间范围指定为[2,4]。在Matlab R2010a环境下编程实现SOM-DB-PAM并比较其与传统K-means、SOM-DB-Kmeans聚类算法的性能差异。每种算法实验10次,实验结果如表1所示。表1中的DB指标值和程序运行时间均为10次实验获得的平均值。

表1 使用电力客户仿真数据集的SOM-DB-PAM聚类测试结果
从表1可知:使用SOM-DB-PAM进行的10次实验中,通过DB指标均能识别出正确的聚类数目3且样本的分类正确率达到100%,高于传统K-means和SOM-DB-Kmeans的分类正确率。而使用后2种聚类算法进行的实验中,分别有2次和1次实验DB指标无法准确判断最优聚类数目(见括号),这主要是由于K-means采用随机分配初始聚类中心的策略且聚类结果受数据输入顺序的影响,导致聚类结果不稳定。由于训练SOM网络需要时间,从表1可看出,K-means在本文实验的运行时间上具有明显优势,为进一步验证SOM-DB-PAM在大规模数据集上的时间有效性和聚类效果,考虑到为大样本电力客户预先设定合理的类编号存在困难,本文还使用UCI数据集中不同规模的其他行业测试数据集评估3种算法的聚类性能,测试结果如表2所示:在不同规模的测试数据集上,SOM-DB-PAM都具有更高的分类正确率且能准确判别最优聚类个数;在程序运行时间上,由于SOM-DB-PAM和SOM-DB-Kmeans需要构建SOM网络并对其进行训练,处理小样本时,K-means具有更高的聚类效率;随着样本规模的增加,SOM-DB-Kmeans所需运行时间最少,但比SOM-DB-PAM并没有显著优势,综合分类正确率、最优聚类数目的判定和算法运行效率可知,在对大规模数据进行聚类分析时,SOM-DB-PAM优于传统聚类算法。
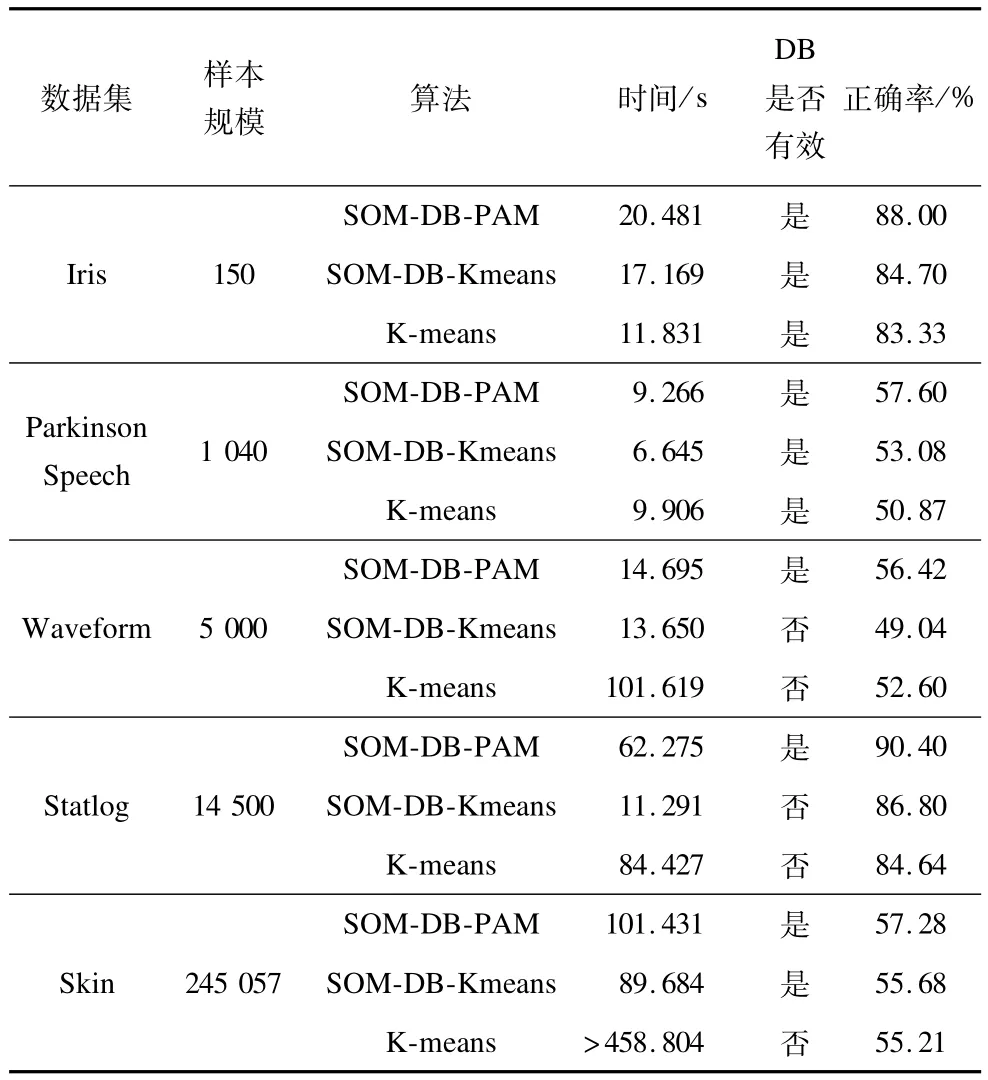
表2 使用UCI数据集的SOM-DB-PAM测试结果
4 实例分析
4.1 数据收集和数据预处理
本文从国家电网陕西省电力公司某下属供电局的营销信息系统中,抽取了16 818位居民客户的基本信息和2011年、2012年12月的用电数据进行分析,验证SOM-DB-PAM在真实电力客户细分应用中的有效性。参照已有研究建立的电力客户价值评价指标体系[8,13],在考察数据可获取性和数据质量的基础上选取11个指标构成细分变量,各变量的含义如表3所示。
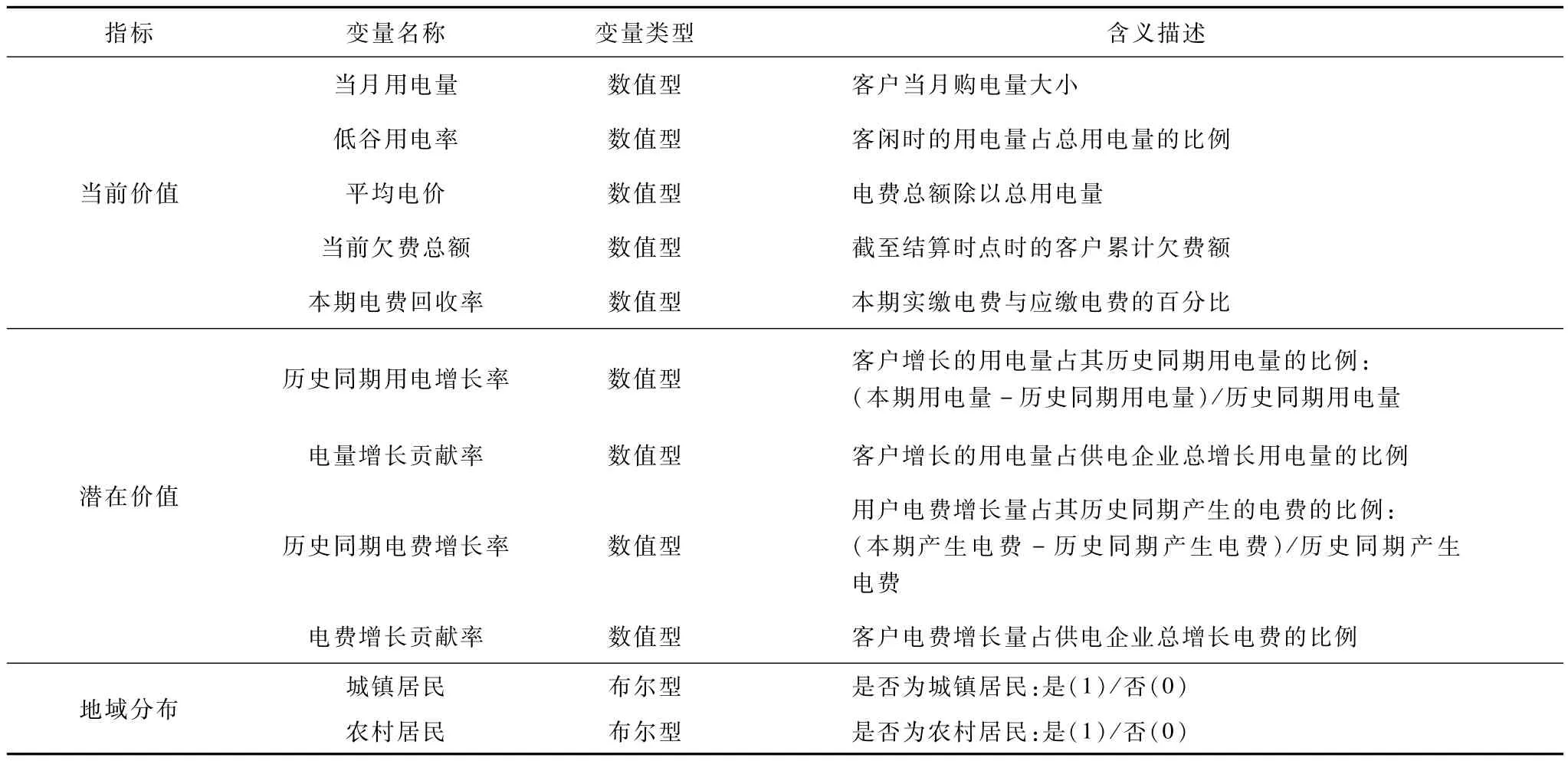
表3 电力客户细分变量及其含义
为消除数据间由于量纲不同对聚类结果产生的影响,根据各变量数据的分布特点选取合适的标准化方法[20]对原始数据进行标准化处理,如表 4所示。

表4 细分变量的标准化方法
4.2 基于SOM-DB-PAM的电力客户细分
使用SOM-DB-PAM混合聚类算法对经过预处理的电力客户数据进行聚类,在第1阶段,初始化SOM网络结点数为 100,结点形状为六边形,按[13×8]矩阵排列,SOM图形状为超环面,初始邻居距离为2。在第2阶段,综合考虑当前价值、潜在价值2个维度和细分结果的可解释性将最终簇数目的区间范围指定为[4,50],为克服PAM聚类时随机选取初始中心点导致对于同一类目数,每次计算出的DB指标存在微小差异的缺点[21],对每个类目数,计算DB指标30次并用均值代表最终DB值。用DB指标获得的最优聚类个数为33,此时的DB指标值为0.699 8,得到的每个类包含的客户数和各类的中心点如表 5所示。其中,第 1列为各类的簇编号,第2列为每个类包含的客户数,其他各列对应各类的中心点在各细分变量的取值程序运行时间为:175.122 s。
为更好地解释聚类结果,33个客户簇按照当月用电量大小(单位:kW/h)被分为4类:大型客户,用电量大于 1 000;中型客户,用电量区间 (500,1 000];一般客户,用电量区间(100,500]以及用电量低于或等于100的小型客户,图3描述了各个类在当月用电量指标上的分布。其中,每个类包含的客户数大小用圆圈大小表征。
综合其他细分变量,客户又可被分为卓越客户、优质客户、稳定客户、存在潜在欠费风险的客户、存在潜在流失风险的客户以及同时具有以上2种风险的客户,对各类型客户的特征描述如表6所示。其中,卓越客户和优质客户在衡量客户价值的各指标上表现优异,历史同期用电量增长和电费增长幅度均超过10%,具有大的潜在价值,按时缴费,电费回收率超过95%,是本文要识别的高价值客户,他们仅在用电规模上存在差异,卓越客户的当月用电量更接近其所在用电量区间的上限。
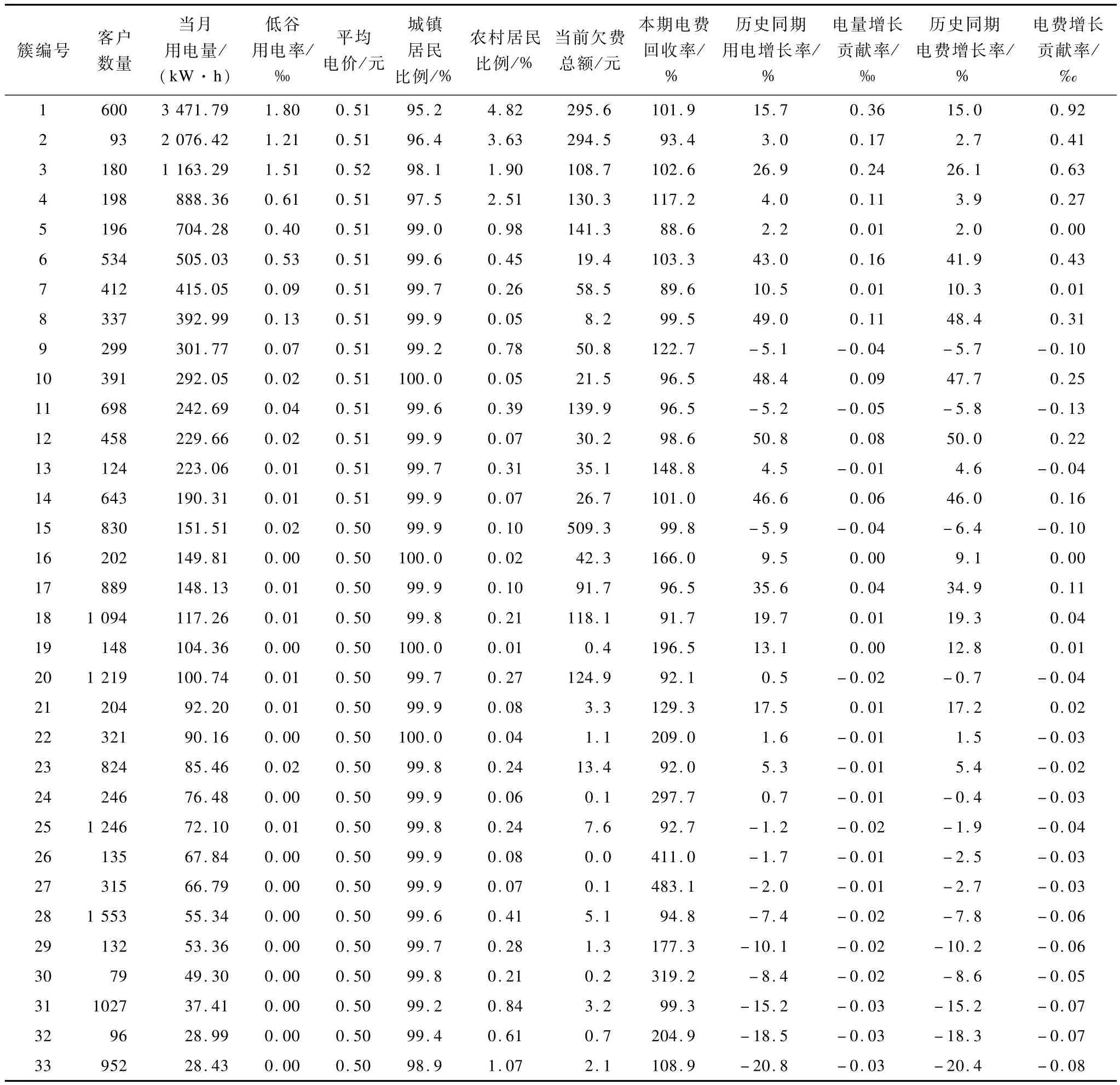
表5 各类包含的客户数和类中心点分布
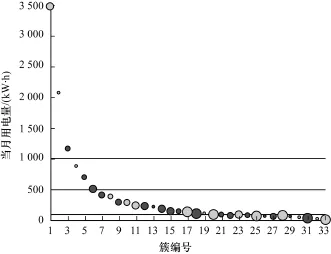
图3 各类按当月用电量分布

表6 各类型客户的特征描述
图4描述了各簇在用电量和客户类型上的交叉细分结果,高价值客户用六边形表示,图形中的数字为每个簇的簇编号。识别出的高价值客户共4 384名,占客户总量的26.07%。

图4 各簇在用电量和客户类型上的交叉细分结果
供电企业可根据各类客户的特征制定有针对性的服务措施。
从识别出的4 384名高价值客户中随机抽取50名客户,由该供电公司组织营销业务专家采用表3中指标和文献[13]提供的客户价值评价方法评价其价值,评价结果显示:46名客户的分类类型与使用SOM-DB-PAM得到的分类类型吻合。综合业务专家的意见,认为该细分结果符合业务实际需要并具有良好的解释性和一定的实用性。
5 结束语
随着我国国家电网公司SG186信息化工程的深入推进和95598服务系统的投入运营,电力营销数据库中存储的电力客户数据呈数量级增长,如何有效利用这些信息对客户进行快速、准确的细分和定位,是供电企业制定服务对策的前提。本文提出的SOM-DB-PAM混合聚类算法为解决这一问题提供了一种思路,针对电力客户用电行为数据量庞大的特点,首先利用SOM对数据进行“粗聚类”得到表征数据主要特征的原型向量以压缩数据量,再使用PAM对所获得的原型向量正式聚类并用DB指标识别最优聚类数目,PAM的健壮性使其不易受到用电行为噪声数据的影响,同时保证了DB指标的稳定性,而用远小于初始样本数的原型向量替代原始数据大大降低了PAM的计算量。分别采用仿真数据集和电力客户真实用电数据对算法性能进行了测试,实验结果表明,与传统聚类算法相比,SOM-DB-PAM混合聚类算法在不同规模的测试数据集上,均能正确判别聚类个数并得到更好的分类结果,将其应用于电力客户细分,能快速有效聚类并得到具有良好解释性的细分结果,算法适用于针对大量电力客户的深度细分。作为衡量聚类效度的指标,DB指标主要针对数值型细分变量,当细分变量为分类变量时,使用DB判别最优聚类数目的效果不理想,而电力客户基本信息中包含了大量对细分有价值的分类变量,如客户所在行业、用电类型、缴费方式等,研究适用于混合数据类型的聚类效度指标,扩展算法的适用范围,是电力客户细分研究有待进一步解决的问题。
[1] Smith W R.Product Differentiation and Market Segmentation as an Alternative Marketing Strategy[J]. Journal of Marketing,1956,21(1):3-8.
[2] Floh A,Zauner A,Koller M,et al.Customer Segmentation Using Unobserved Heterogeneity in the Perceived-value-loyalty-intentions Link[J].Journal of Business Research,2014,67(5):974-982.
[3] 威廉·G·齐克蒙德,小雷蒙德·迈克里奥德.客户关系管理:营销战略与信息技术的整合[M].胡左浩,译.北京:中国人民大学出版社,2005.
[4] 郭迎春.知识型电力客户关系管理研究[D].保定:华北电力大学,2008.
[5] López J J,Aguado J A,Martín F,et al.Hopfield-K-Means Clustering Algorithm:A Proposal for the Segmentation of Electricity Customers[J].Electric Power System s Research,2011,81(1):716-724.
[6] 徐天池.基于数据挖掘的电网客户细分系统设计与实现[D].广州:中山大学,2013.
[7] 王轶华.电力客户综合价值分析[D].上海:上海交通大学,2007.
[8] 王松涛.市场条件下的电力客户价值分析体系[J].电网技术,2010,34(2):155-158.
[9] 李泓泽,郭 森,王 宝.基于遗传改进蚁群聚类算法的电力客户价值评价[J].电网技术,2012,36(12):256-261.
[10] 曾 鸣,杨素萍,杨鹏举,等.社会节能环境下电力客户价值评估研究[J].华东电力,2008,36(6):15-18.
[11] 王春叶.基于数据挖掘的电力客户细分研究[D].保定:华北电力大学,2009.
[12] Wind Y.Issues and Advances in Segmentation Research[J].Journal of Marketing Research,1978,15(1):317-337.
[13] 蒋维杨.电力客户价值评价及信息系统开发研究[D].西安:西北工业大学,2010.[14] Zhou Kaile,Yang Shanlin,Shen Chao.A Review of Electric Load Classification in Smart Grid Environment[J].Renewable and Sustainable Energy Reviews,2013,(24):103-110.
[15] Laan V D,Pollard M J,Katherine S,Jennifer B.A New Partitioning Around Medoids Algorithm[J].Journal of Statistical Computation&Simulation,2003,78(8):575-675.
[17] Hiziroglu A.Soft Computing Applications in Customer Segmentation:State-of-art Review and Critique[J].Expert Systems with Applications,2013,40(1):6491-6507.
[18] 安 璐,张 进,李 纲.自组织映射用于数据分析的方法研究[J].情报学报,2009,28(5):720-726.
[19] Vesanto J,Alhoniemi E.Clustering of the Selforganizing Map[J].IEEE Transactions on Neural Networks,2000,11(3):586-600.
[20] Wang J.Encyclopedia of Data Warehousing and Mining[M].Hershey,USA:Information Science Press,2006.
[21] Rasanen T,Ruuskanen J,Kolehmainen M.Reducing Energy Consumption by Using Self-organizing Maps to Create More Personalized Electricity Use Information[J].Applied Energy,2008,85(1):830-840.
编辑 索书志
Power Customer Segmentation Based on SOM-DB-PAM Hybrid Clustering Algorithm
HU Xiaoxue,ZHAO Songzheng,WU Nan
(School of Management,Northwestern Polytechnical University,Xi’an 710129,China)
Based on power customers which reach a very large amount and the feature of presence of outlier,and limitations of Partitioning A round Medoid(PAM)algorithm in handling large amounts of data and predefining the number of clusters,a new hybrid clustering algorithm called SOM-DB-PAM that is suitable for fast clustering of large number of electricity customers,is proposed.In the proposed algorithm,the Self-Organizing Map(SOM)neural network is used to train input data to find prototype vectors that represents patterns of the input data set but far less than the number of it,and the prototype vectors are clustered by the PAM algorithm and to ensure the validity of clustering,the Davies-Bouldin(DB)indexis calculated for SOM prototype vectors to solve optimal number of clusters.Experimental results show that,com pared with traditional clustering algorithm s,the accuracy of classification is enhanced and when the amount of electricity customers is large,the proposed algorithm can achieve a fast and effective clustering.In addition,the blindness and subjectivity of predefining the number of clusters artificially is decreased.
power customer segmentation;Partitioning A round Medoid(PAM);Self-Organizing Map(SOM);hybrid clustering algorithm;clustering analysis
胡晓雪,赵嵩正,吴 楠.基于SOM-DB-PAM混合聚类算法的电力客户细分[J].计算机工程,2015,41(10):295-301,307.
英文引用格式:Hu Xiaoxue,Zhao Songzheng,Wu Nan.Power Customer Segmentation Based on SOM-DB-PAM Hybrid Clustering Algorithm[J].Engineering Computer,2015,41(10):295-301,307.
1000-3428(2015)10-0295-07
A
TP391
国家教育部博士点基金资助项目(20116102110036)。
胡晓雪(1986-),女,博士研究生,主研方向:数据挖掘,电力企业市场营销,客户关系管理;赵嵩正,教授、博士生导师;吴 楠,博士研究生。
2014-08-28
2014-11-12E-mail:nolanspring@163.com
猜你喜欢
电脑报(2020年12期)2020-06-30 19:56:42
华人时刊(2020年23期)2020-04-13 06:04:12
电脑报(2019年4期)2019-09-10 07:22:44
电子测试(2017年15期)2017-12-18 07:19:27
专用汽车(2016年9期)2016-03-01 04:17:02
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
智能系统学报(2015年4期)2015-12-27 09:38:39
大众摄影(2015年9期)2015-09-06 17:05:41
专用汽车(2015年2期)2015-03-01 04:05:42
电子设计工程(2015年6期)2015-02-27 12:04:53
