
基于二次网格的字符图像特征提取方法
2015-03-06 01:31:56方玉玲
电子科技 2015年10期
方玉玲,魏 赟
(上海理工大学 光电信息与计算机工程学院,上海 200093)
车牌识别技术是智能交通系统中的关键技术之一,广泛应用于交通管制、监控系统、停车场管理处、军事要塞等场所。完整的车牌识别系统技术核心主要有3 部分:车牌定位、字符分割、字符识别[1-2]。其中,字符识别是整个识别系统的关键部分,直接影响识别系统的好坏。目前,主流的车牌字符识别方法有3 类:(1)模板匹配字符识别算法[3]。该方法实现方式是通过对样本与模版进行匹配,取相似性最大的样本为输入模式所属类别。但由于所采集的样本形态各异,实际应用中经常会由于模版的概括能力有限而导致识别错误。(2)神经网络字符识别算法[4-5]。该方法是先对待识别字符进行特征提取,然后用所获得的特征向量来训练神经网络分类器,通过训练好的分类器将字符识别出来。影响该方法的因素较多,如车牌定位、训练分类器样本数量、训练次数等,都会制约识别速率与准确率。同时,由于该算法计算复杂度较高,难以达到实时识别的应用目的。(3)多特征字符识别法[6]。该方法先提取出字符相关结构,再经分类器进行多次分类达到字符识别的目的。该方法对易混字符有较好的区分能力,但对相似字符要进行多次降维和分类才能达到准确区分的目的,算法复杂性高,计算量大。
本文针对不同类型的字符识别问题,充分利用字符关键特征,在二次网格化基础上依次提取出字符图像的曲率、占空比、质心、散度共4 种特征向量。然后利用C_SVC 类型的SVM 模型,设置核函数为线性核,SVM 模型训练之后,即可在高维特征空间中将不同类别的汉字、字母及数字所映射成的特征向量很好的区分开,训练生成的分类器在车牌识别过程中有较高的识别准确率。同时,由于模型的核函数为线性,分类器识别过程计算量小,复杂度低,算法效率更高。通过对大量样本的实验,该算法在保证快速识别的情况下,相比其他算法,识别的准确率也有所提高。
1 车牌字符特征提取综述
字符特征的提取是指从经过尺寸归一化处理的字符二值图像中提取出字符的关键特征,同时要满足特征向量的维数尽可能少,正确分类的精度尽可能高,系统有较高的稳定性和鲁棒性的要求[7]。一般来说,字符主要有结构特征和统计特征。结构特征对于笔画结构上相近的字符易于区分,缺点是该类特征难于提取,而且实现起来的鲁棒性和抗干扰能力较差;统计特征是对字符笔画像素的一种累加。因此,在对一些相似字符的识别能力上不如结构特征,但是其优点是抗干扰能力强且足够稳定。
1.1 传统字符特征提取算法思路分析
(1)基于投影归一化的字符特征提取方法。该方法实现的基本思想[2]是先将字符二值图像转化为一个二维的0-1 矩阵,其中0 代表背景像素点,1 代表字符笔画像素点,然后分别对矩阵的行和列进行投影生成行投影向量和列投影向量,再对行、列投影向量进行维数归一化和密度归一化生成双投影归一化特征向量。
外轮廓分布特征,有些字符仅从外部轮廓结构就可区分出来,如“S”和“I”。以字符“S”为例,如图1(a)示,按从上到下、从右向左的顺序进行扫描,每次扫描可获得一组特征向量;笔画的斜率特征,把所得斜率值分为正、负、零值3 类,如图1(b)示。分别对正、负斜率值进行累加,否则累加零斜率点的数目。此特征可以较好地表征字符笔画长短和笔画形态;拐点幅度特征,在字符识别中,笔画拐点的数量和位置与字符识别密切相关。此处将相邻斜率值不相等的点定义为拐点并计算其幅度,如图1(c)示。此特征是对斜率特征无法完全体现字符笔画结构特征的补充。
内部像素统计特征,只对字符外围结构或轮廓特征进行提取,容易混淆外部特征相近而内部差异大的字符,如“B”和“D”,对于这样的字符,还要依靠字符内部的像素特征来加以区分,如图1(d)示,分别统计字符内部不同区域内目标像素的个数,得到特征向量。
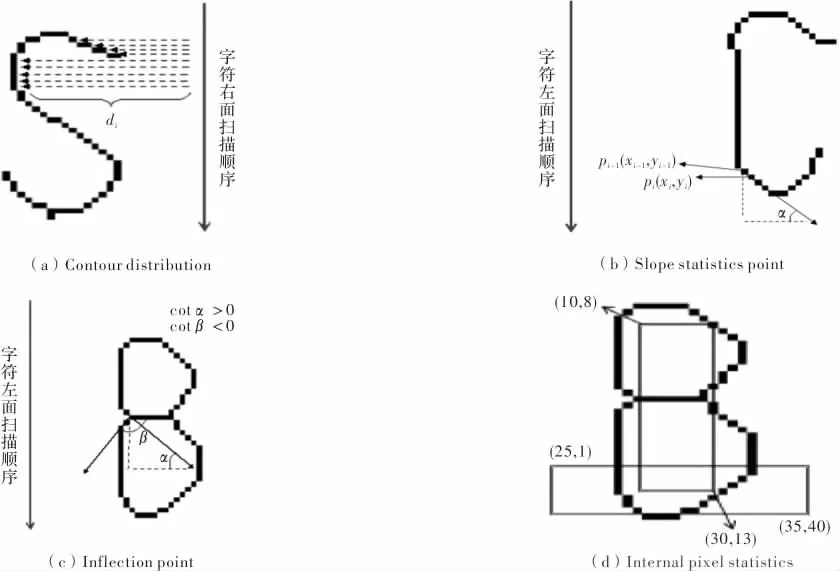
图1 组合特征示意图
该方法在识别相似字符时效果较好。但提取组合特征之前需对字符图像进行细化处理,由图2 和图3可知,经细化后字符图像与原图像相比发生了较大变化,尤其对于相近字符“0”和“D”,经细化后严重影响了识别准确率。

图2 原字符“0”和“D”
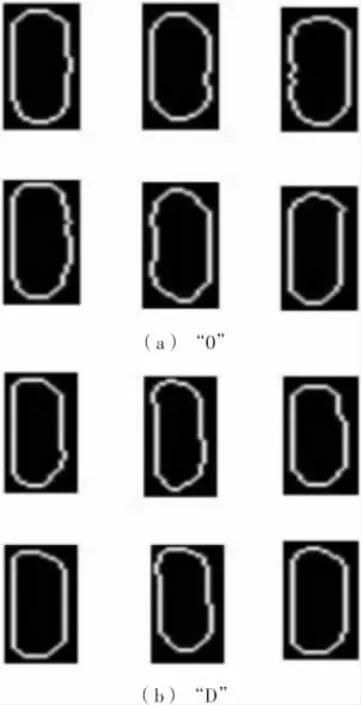
图3 细化字符“0”和“D”的比较
1.2 字符特征提取算法流程
本文提出一种将两种特征相结合的特征提取方法,其主要思想是对网格化后的字符图像按网格顺序提取字符笔画的曲率、使用率、质心和散度[8]共4 种组合特征,然后通过建立SVM 模型,设定SVM 类型与核函数类型,将要识别的不同字符作为不同的类别,并设定不同类别的标签,利用对应样本图像提取出的特征向量进行训练,得到的分类器即可用来进行字符识别。具体算法流程如图4 所示。

图4 本文算法流程图
1.3 字符图像预处理
为了提高字符识别的准确率和整个车牌识别系统的性能,在提取字符特征之前,还需要将经字符分割后的不同分辨率的单个字符进行预处理,得到具有归一化分辨率的字符图像。本文中的所有字符均经过图像尺寸归一化为20×40,即图像宽为20 个像素,高为40个像素。归一化处理后的部分字符如表1 所示。

表1 部分经尺寸归一化后字符图像结果
1.4 字符图像网格化
网格化是指将预处理后的具有统一分辨率的字符二值图像均匀的划分为多个子网格区域,对每一个子区域进行关键特征的提取。提取出的子网格特征体现出了字符笔画相对于整体的一种分布情况。本文将对字符二值图像进行两次网格化,分别提取出关键字符特征。
(1)将预处理后的字符二值图像均匀的划分为2×2=4 个子网格,如图5 所示。
由于实证分析的被解释变量是“支付方式”这一虚拟变量,所以本文运用Logistic 回归模型进行实证研究。本文选取的解释变量(Yi)表示“收购方选择现金支付方式”。

图5 归一化及初次网格化后的字符二值图像
对初次网格化后的字符二值图像提取字符笔画外轮廓的曲率特征。
(2)将预处理后的字符二值图像均匀的划分为8×4=32 个子网格,如图6 所示。

图6 归一化及二次网格化后的字符二值图像
对二次网格化后的字符二值图像提取占空比、质心、散度共3 组特征向量。以上的关键特征中,曲率和散度反映了字符笔画的轮廓结构,属于结构特征;占空比和质心体现了字符笔画像素的累计情况,属于统计特征。本文依次对网格化后的二值图像提取出以上4种特征。这样每幅字符二值图像可提取到2×2×1+8×4×3=100 维特征向量。
2 字符特征提取
2.1 曲率
曲线的曲率是针对曲线上某个点的切线方向角对弧长的转动率,表明曲线偏离直线的程度。类似的,斜率在数学定义中也是对直线倾斜程度的度量,通过代数和几何,可计算出直线的斜率。
在网格化字符二值图像中,文中采用斜率的计算方式来表征曲率,即字符笔画弯曲情况。根据前文介绍的斜率提取方法,设当前统计点为pi+1(xi+1,yi+1),前一统计点为pi(xi,yi)。则该点处斜率计算公式为
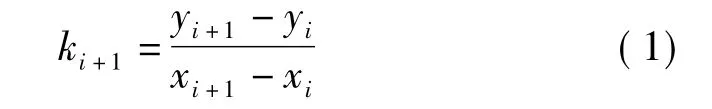
若所得相邻统计点的斜率相等,即ki+1=ki(ki=ki-1),且ki可为任何数值,则累加具有相同斜率值的像素点的数目,当该累加值超过所在网格中目标像素点的一半时,定义该网格内特征向量为零向量,表示该网格中字符笔画为直线,否则定义该网格内特征向量为单位向量,表示此网格中字符笔画为曲线。该特征对于字符笔画相近的“0”和“D”,“2”和“Z”,“5”和“S”,“8”和“B”等有较好的区分效果。
2.2 占空比
在网格化字符二值图像中,占空比是指子网格区域Bj(j=1,…,32)内的目标像素的总个数占该区域像素总个数的比率。字符子网格区域Bj的面积为

该区域内字符像素占空比为
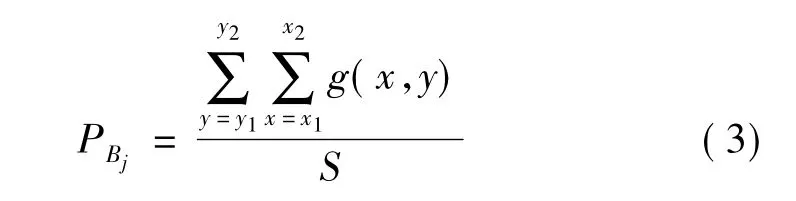
其中,S 为子网格区域的面积;g(x,y)为点(x,y)处的像素的灰度值,设目标像素的值为1,背景像素的值为0,y1、y2、x1、x2分别为区域Bj上下左右的边界值。
2.3 质心
质心即质量的中心,指物质系统中被认为质量集中于此的一个假想点。质心的坐标可用组成该物质的质点坐标的加权平均值来表示。设i 表示物质系统中的某一点,mi为质点i 的质量,xi为质点i 的坐标向量。则质心Xm的计算公式为

在网格化字符二值图像中,质心的位置可用来表示该子网格区域Bj中字符笔画整体的偏向位置。在具体的实现中,将目标像素点对应的灰度值作为该质点的质量。设定目标像素的灰度值为1,背景像素的灰度值为0。此处对质心的计算包括竖直方向和水平方向两种,公式如下。
竖直方向质心
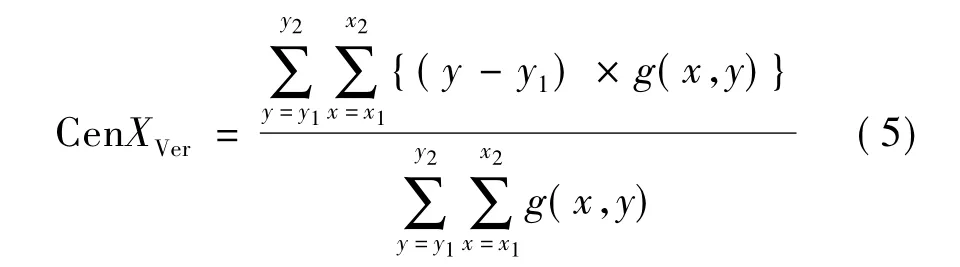
水平方向质心
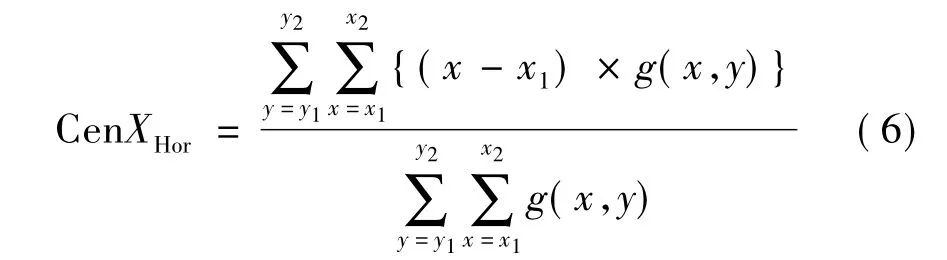
区域Bj的整体质心坐标
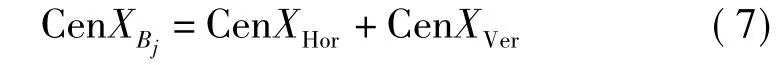
其中,y1、y2、x1、x2分别为子区域Bj上下左右的边界值;g(x,y)为坐标(x,y)处的像素点的灰度值。
2.4 散度
散度的大小用于表征空间某一点的微小体元内的矢量场向外发散的强弱程度。散度值越大,代表发散的程度越大,散度值越小,则代表发散的程度越小。矢量场F 中的某一点P(x,y,z)处的散度是指在一个包含该点的微小体元内的通量除以该体元所包含的体积V 得到的结果在体积V 趋于0 时的极值,散度的计算公式为
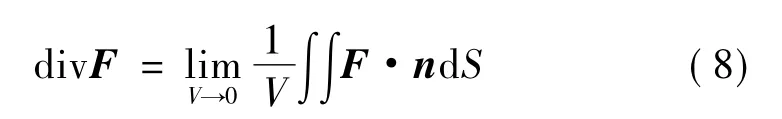
其中,n 为微小体元内点P 处的单位法矢量;dS 是积分的面积元。由散度的定义可知,divF 表示在某点处的单位体积内散发出来的矢量场F 的通量,所以divF描述了通量源的密度。从定义中还可以看出,散度是向量场的一种强度性质,就如同密度、浓度、温度一致。
在网格化字符二值图像中,散度值代表各子网格Bj内字符笔画所包含的像素点相对于该区域中心的发散程度,即字符笔画的发散程度。本文中需计算竖直和水平方向两种散度值,公式如下:竖直散度

水平散度
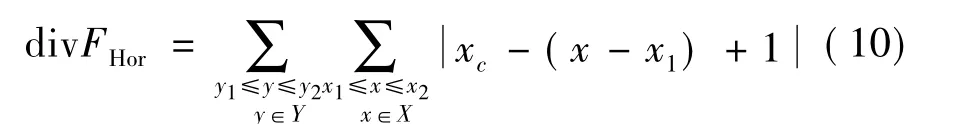
区域Bj的总体散度值
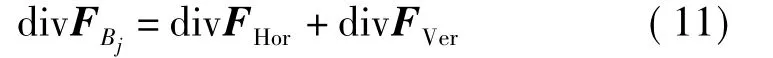
其中,(X,Y)为子区域内字符笔画像素点的坐标集;y1、y2、x1、x2分别为子区域Bj在整幅图像中上下左右的边界值;yc、xc则为子区域竖直方向和水平方向的中心值。
3 实验结果与分析
将本文算法移植到安卓智能机上,通过智能机的摄像头采集相应的图像,然后用本文算法进行识别,结果如图7 所示。同时将本文算法与综述中的算法进行对比,使用不同类型的汉字、字母、数字各1 500 个字符测试集,利用Visual Studio2010+OpenCV 进行测试,得到统计结果如表2 所示,具体实验结果和实验分析如下。

图7 本文算法车牌识别示意图
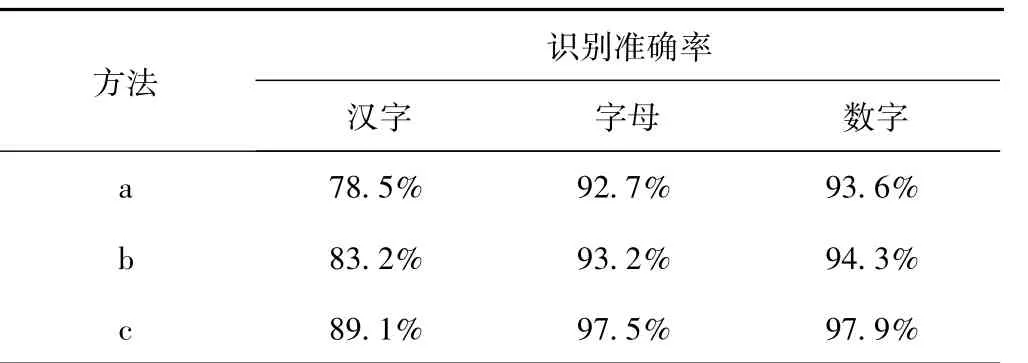
表2 本文方法与其它方法识别准确率结果对比
图7 中选取6 张具有代表性的识别结果,便于对比将原始图像与识别结果整合到一起,各图片中上半部分为原始车牌,下半部分为本文方法识别结果。图7涵盖了0 ~9 的所有数字和一些易混字符,如“8”和“B”、“5”和“S”、“4”和“A”等,很明显,本文算法所提取的特征向量,在各个类别之间具有很好的区分能力。
表2 是用本文方法与前文中介绍的其它两种方法在使用相同SVM 分类器情况下对3 类字符各1 500 副测试样本进行测试的结果。其中,a 为基于投影归一化的字符特征提取方法;b 为基于多特征组合的字符特征提取方法;c 为代表本文方法。
结果表明,本文方法应用到字符识别系统中在整体平均识别率上都优于其它两种常用的方法。表2中,方法一对字母和数字识别率高,但没有充分考虑汉字的字符结构和笔画的复杂性,因而对汉字的识别率降低,仅为78.5%,难以满足实际应用的需要;方法二能较好地提取出字符的关键特征,但在特征提取前需对字符进行细化处理,易对相似字符造成误判,严重影响了识别的准确率。本文算法在常用算法的基础上,采用互补性强的粗网格化思想对单个字符进行分块,再分别提取子网格区域的关键特征,最终对字母和数字的识别准确率均达到了97%以上,对汉字的识别率也高于其它两种方法,能满足车牌识别的使用需求。
4 结束语
车牌字符图像特征提取的方法会直接影响车牌识别系统的整体性能。本文介绍目前常用的字符特征提取方法,为克服常用算法的缺点,提高字符识别率,提出一种基于二次网格化的字符特征提取方法,对尺寸归一化后的字符二值图像分两次提取出网格内字符笔画轮廓的曲率特征向量和目标像素点的占空比、质心和散度共4 种特征向量。该方法兼具统计特征与结构特征的优点,具有较强的抗干扰能力且足够稳定。实验结果表明,本文方法不仅对字母和数字具有较高的识别准确率,同时,对汉字的识别准确率也高于其它两种方法,较好地提高了车牌识别系统的性能。
[1] 李宇成,杨光明,王目树.车牌识别系统中关键技术的研究[J].计算机工程与应用,2011,47(27):180-184.
[2] 周治紧,李玉鑑.基于投影归一化的字符特征提取方法[J].计算机工程,2006,32(2):197-199.
[3] Zhu Youqing,Li Cuihua.A recognition method of car license plate characters based on template matching using modified hausdorff distance[C].Changchun:Conference on Control and Electronic Engineering,2010.
[4] 汤茂斌,谢渝平,李就好.基于神经网络算法的字符识别方法研究[J].微电子学与计算机,2009(8):91-97.
[5] Ning Chen,Li Xing.Research of license plate recognition based on improved BP neural network[J].Computer Application and System Modeling,2010(11):482-485.
[6] 罗辉武,唐远炎,王翊,等.基于结构特征和灰度特征的车牌字符识别方法[J].计算机科学,2011,38(11):267-270.
[7] 何兆成,佘锡伟,余文进,等.字符多特征提取方法及其在车牌识别中的应用[J].计算机工程与应用,2011,47(23):228-231.
[8] 吕文强.基于Adaboost 和SVM 的车牌识别方法研究[D].南京:南京理工大学,2013.
猜你喜欢
数学年刊A辑(中文版)(2022年1期)2022-08-20 08:50:04
黑龙江大学自然科学学报(2021年4期)2021-11-19 07:05:10
高技术通讯(2021年2期)2021-04-13 01:09:46
数学物理学报(2019年6期)2020-01-13 06:08:08
测控技术(2018年10期)2018-11-25 09:35:28
数学物理学报(2018年3期)2018-07-17 06:15:30
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
计算机应用(2016年10期)2017-05-12 15:22:34
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:12
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
