
虚拟环绕声算法研究与IP 核实现
2015-03-06 01:31龙芬,丁林
电子科技 2015年7期
龙 芬,丁 林
(1.咸宁职业技术学院 机电工程系,湖北 咸宁 437100;2.凹凸科技(中国)有限公司 电池管理事业部,湖北 武汉 430074)
由式(6)可得,在时域中,为两函数的卷积
则a(n)、b(n)可当作(P+1)点和(Q+1)点的有限序列,对式(11)做逆Z 变换得
借助于数字信号处理技术的发展,头相关传递函数(HRTF)理论已开始进行系统研究。早期,HRTF 主要应用于分析研究多通道重放系统中的单声道改善,其数据的并行处理,时序信号的高精度都为高保真HRTF 技术的实现提供了技术支撑。
1 虚拟音频技术
虚拟音频技术的理论核心就是利用头相关传递函数(Head Related Transfer Function,HRTF)对音频信号进行处理,模拟声波从声源中心发送到听者双耳接收到声波,并产生听觉的整个声波传递过程。虚拟音频的发声源即空间摆放的扬声器或相对封闭的耳机,通过对音频信号的加工,基于声传递模型以在双耳处产生出同样的空间声像效果。这一技术在多媒体与虚拟现实、人工智能、通信、消费电子的声重放系统、室内空间声学设计、心理听觉与生理听觉的科学实验等方面都有重要的应用价值[1-4]。
从声源处开始,声波传递到双耳鼓膜处的整个过程就是双耳产生空间声效的过程,如将这个过程进行数学模型描述,就是HRTF 描述即传递函数描述。这些频谱的变化是由于躯体、头及外耳或耳廓对声波的衍射造成的,并且其特性依赖于声波传播的方位角、仰角和听者与声源的距离。一般来说,HRTF 是一个复杂的且与声源位置、听众位置以及特定监听器的物理尺寸和形状相关的函数。声音信号经HRTF 传递函数滤波并传递到听者的鼓膜处产生听觉之后,使听者主观能感受到虚拟声源在准确的空间某一点上的存在。HRTF 是频率域函数,其对应的时域函数就是头相关冲激响应(Head-Related Impulse Response,HRIR)。
假定头部固定不动,则文中即可将声源到听者双耳的整个声波的传播过程看成是一个时不变线性系统如图1 所示。

图1 声源到双耳的传递过程
头相关传递函数HRTF 的定义是,在空间自由场中,声波从声源到双耳传播过程的传递函数,其表达式可写成[5-7]

式(1)和式(2)中,PL、PR分别为点声音到左、右耳处的频域复声压;P0是头部未在原点中心处的频域复声压,其表达式为

式(3)中,ρ0为媒质密度;c 为声速;Q0为点声源强度;为声波波数;e-j2πft为简谐声波的时间因子,于是e-jkr即可用来表示点声源传递的声波随距离的传输。
任一声源在空间位置上均对应着一对HRTF 函数,其是声源到头中心距离r、仰角φ、声源方位角θ 以及声波频率f 的函数。式中的a 表示一组与生理结构和尺寸相关的参数[8-10]。
由此可知,HRTF 为多参量函数。当然,在描述具体的传输过程时,不同情况下,各参数所起的作用也不同,在某些情况下,为了便于讨论,个别参数甚至可以忽略,比如,在远、近场情况的讨论中,远场则可忽略掉变量声源到头中心距离r,若不讨论个性化HRTF,参数a 则可省略掉。
由定义可知,HRTF 与HRIR 互为时频关系。由信号的相关理论可知,这是一对傅里叶变换对,如下
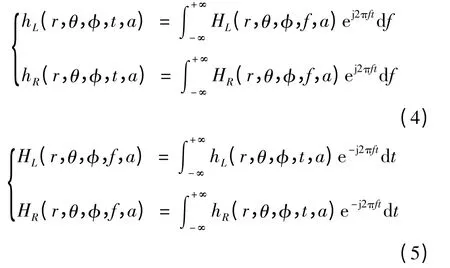
同样,HRIR 与声源到头中心距离r、声源方位角θ、仰角φ、时间t 以及生理参数a 有关,也是多变量函数。
人耳之所以能听到声音,主要与双耳声压有关,不同的声压给人的声音效果也不同,因此,由特定的HRTF 或HRIR 若确定了声压,便容易实现相应的声效。由式(1),式(2)可得

由式(6)可得,在时域中,为两函数的卷积
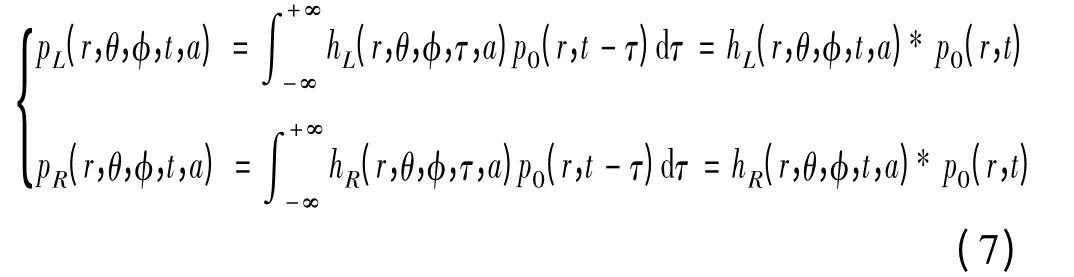
式(7)中,pL和pR时域上的双耳声压;p0为没有头存在时,头中心位置的时域声压[11]。
要想实现虚拟声效的重放,将单路频域信号和已知(θ,φ)方向上的已知HRTF 进行求积,继而用耳机重放,即可在重放时获得(θ,φ)方向的空间声像效果。
2 系统的实现
2.1 HRTF 滤波器选择与IP 核的实现
在数字信号处理中,要实现HRTF 处理的IP 核,核心部分是设计数字滤波器。考虑到滤波器的效率问题,本文采用IIR 滤波器来逼近HRTF 的设计,于是就需要用求出的IIR 滤波器的传递函数去逼近已知的H(ω)。ω 为数字角频率,逼近的程度可用HRTF 的近似误差ε∑S来描述。这里用时域或频域的平方误差来表示,相应的定义式如下

IIR 滤波器的设计方法采用Prony 法,假设已测量得到HRIR,现记为h(n),设一因果IIR 滤波器的时域脉冲响应为,则系统的传递函数如式(9)所示
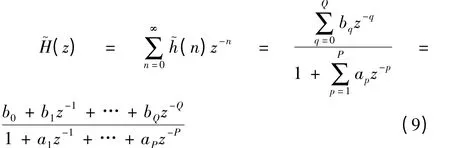
可得选择(P+Q+1)个待定的系数ap和bq,p=1,2,…,P,q=0,1,2,…,Q,使平方误差ε∑S最小,如式(10)所示

其中,U 为根据需要选择的求和上限。将式(8)改写成

令
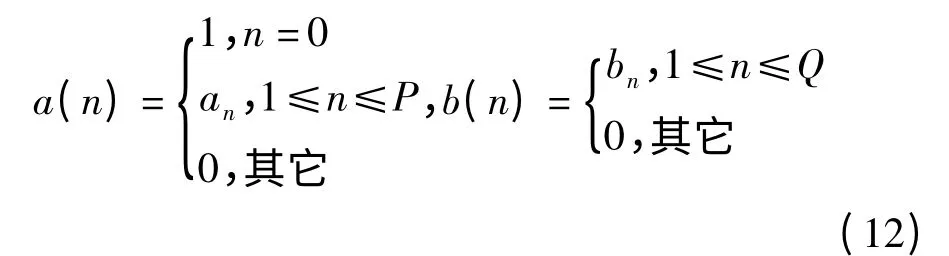
则a(n)、b(n)可当作(P+1)点和(Q+1)点的有限序列,对式(11)做逆Z 变换得
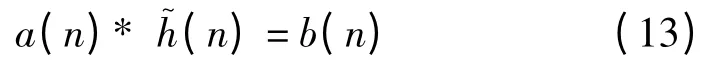
换一种形式即

将式(14)代入式(10),则变为求解非线性方程问题,由于求解困难,取n≥Q+1 进近似,则问题可得到简化,可先求出ap,于是设误差
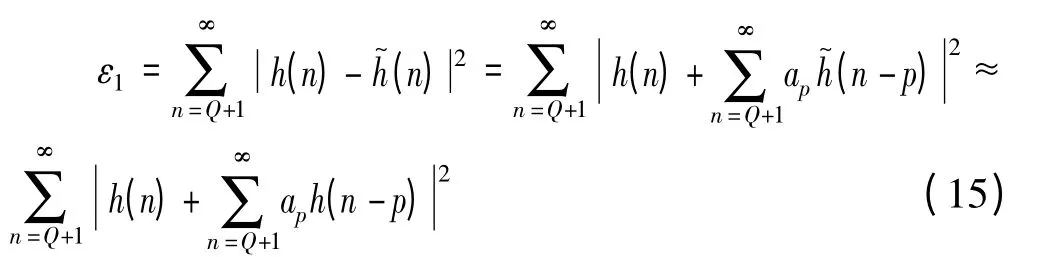
要ε1最小,即要求

由此得到关于ap的P 个线性方程,其矩阵式为

其中

可以看到rlk为h(n)的自相关函数,可求得所有p个ap,将其代入,作的近似后,可求得所有剩余Q+1 个bq,即
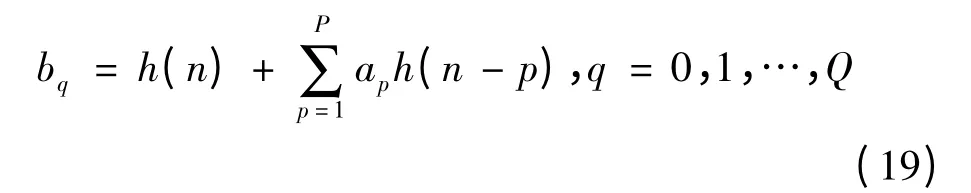
到此,将所有已求出的ap与bq代入式(9),即可得出HRTF 的I2R 模型[12]。
2.2 系统硬件设计

图2 5.1 虚拟多通道环绕声处理的整体架构
根据以上分析与选择,整个系统的架构框图如图2所示。其中,SD 卡上存储了5.1 声道的wav 文件数据。MicroBlaze是Xilinx 公司开发的一款软IP 核处理器,主要负责将SD 卡的数据读取并解析出文件的波形数据,将其按HRTF IP 核的处理需求存储到板载的SDRAM 中。HRTF IP 核负责处理波形数据,并将处理后的数据存储于板载SDRAM 的指定区域。板载的ROM 用于存放由HRTF 数据库计算所得到的多组参数(主要是CIPIC 的HRIR 数据),可通过操作人机接口来切换参数。最后MicroBlaze 读取RAM 中经过处理的数据,并通过I2S 音频接口传递给音频D/A 转换模块,并由音频模块推动耳机实现音频的回放。
经论证与比较,最终选定NexysTM3Spartan-6 FPGA开发板作为本设计的硬件开发平台。硬件所采用的FPGA 芯片为Xilinx 的XC6LX16-CS324,开发板上具有48 MB 的外部存储器,板上扩展了足够多的I/O 设备接口,可对接多种其他数字系统。板载AdeptTM的高速USB2.0 接口可作为硬件平台的供电、FPGA 布线数据的下载以及38 Mbit·s-1速率的用户数据传送等多种用途。该开发平台还配置有大量的数字功能接口板,包括超过30 种PmodsTM和VmodsTM,因此可以很方便地给Nexys 3 开发平台扩展功能,包括诸如A/D 和D/A 转换、面包板、电机驱动、显示器等功能。Nexys 3全兼容所有Xilinx 工具,比如ISE WebPackTM、EDKTM及其它工具。
2.3 系统软件设计
由于系统需要音源来测试IP 核,因此使用FatFs文件系统。其是一个适用于小型嵌入式系统使用的免费开源、高效通用FAT 文件系统,其大小大约800 kB。FatFs 文件系统的移植无需做太多修改,便可在诸多处理器上运行使用,如常见的8051,PIC,AVR,SH,ARM以及MicroBlaze 等。
FatFs 文件系统向上为程序提供相应的API 接口,向下通过底层通讯协议对SD 卡进行操作。
本设计是将波形数据存储于SD 卡中,NexysTM3Spartan-6 与SD 卡卡座通讯采用SPI 协议。因此,必须提供相应的SPI 的读写协议程序,在MicroBlaze 上编写SPI 接口代码,主要包括读、写以及初始化,其中初始化过程包括寄存器和相关I/O 口的初始化。此外还需要将MicroBlaze 配置成数据高位优先(MSB)、主机模式、SPI 总线通讯速率2 Mbit·s-1等。
在文件的研究测试中,为了不涉及复杂的音频文件的解码,方便测试,采用了无损的音频wav 波形文件。而普通的wav 文件则是单声道或是双声道。因此,对测试所用的wav 文件需要做特别的处理。
由于5.1 声道需要有6 个声道的音源,各声道量化精度至少要达到16 bit,由此,文中设计了如图3 所示的结构。

图3 5.1 声道wav 文件数据区数据排列
由图3 所示,要存储一个16 bit 的声道数据,需要16×6 bit 的数据,即2×6=12 Byte 数据。
在对原始的5.1 声道的DTS 波形文件的处理过程中,借助Minnetonka 公司的两个专用多声道音轨分离工具DTS Parser 和TranzGUI,首先用DTS Parser 将5.1声道的wav 文件转换为DTS 文件,再使用TranzGUI 将DTS 文件分离得到6 个声道文件,最后利用Matlab 将这6 个声道文件合并,从而得到所需wav 文件。
3 系统测试
测试系统使用了1 块NexysTM3Spartan-6 FPGA平台、1 个SD 卡pmod 模块、1 个pmod 音频输出D/A模块、1 幅高质量耳机(耳塞式)、PC 机一台、1 个普通麦克风。测试对象主要为实验室本研究小组的5 位同学。测试时首先选用了粉红噪声作为测试声源找出适合自己的HRTF 数据,然后分别选择单声道、双声道声源与5.1 声道声源作主观定位判断测试。
文中的测试数据库选用CIPIC 数据库,为比较HRTF 数据的个性化差异,这里主要挑选了其中的13套数据进行测试,如表1 和表2 所示。
由于测试的主观判断因人而异,所以为减少测试区分的难度,文中只选用了特定的几个方位进行测试。其中水平面上的方位角选用15°的整数倍,范围为-180°~180°,因此共选用了24 个方位角。中垂面上的方位角,选择-45°、0°、30°、60°、90°等5 个角度。经测试,并作出了测试结果的统计表,如表1 和表2 所示。

表1 水平方向测试统计表

表2 垂直方向测试统计表
(1)由表1 和表2 所示,通过计算拟合的数据hrir_final_h_158,整体辨别成功率较高,由前文所述理论可知,头部与耳廓对垂直方向上的定位影响较大,因而可得出hrir_final_h_158 所含的头部与耳廓尺寸信息和5 位被测试者的比较相近。
(2)从对多声道音源定位的测试中,通过主观的判断与分析,几位被测者均表示与普通的双声道信号相比,本IP 核对5.1 声道的音频信号的音质改善效果更明显,由此可知,5.1 声道的音频信号更适合作为本IP 核的音源。
(3)从测试的结果来看,定位的准确率相对较高,特别是文中采用的Prony 方法求得的HRTF 数据,这其中主要由于原始的HRTF 数据是基于实验室的直接测量所得,其中在包含定位信息的同时,也包含了许多的高频噪声,而文中所用滤波器对这些高频噪声起到了天然的滤波作用,因而信噪比较原始数据要高,从而提高了定位的准确率。
(4)就测试对象而言,被测对象3 为女性,其它均为男性,从表1 和表2 的统计数据可看到,水平方向上的测试,男性总体对定位信息相对较为敏感,准确率较高,且准确率相差较小,但垂直方向上的测试,总体准确率要低于水平方向,且男女性相差较小,但此时的个体差异却显现出来。由此可得到,水平方向的性别差异化更为明显,垂直方向的个体差异更大。
(5)从整体上看定位的错误率较高,这主要有几个方面的原因,首先使用非个性化HRTF 数据是其中一个重要原因,其次由于人类听觉是非线性的,而这里的数字信号处理过程使用的是线性近似,因此也难以反映出个性化的特征。由表1 和表2 的统计数据可以看出,声源定位有前后混淆和上下混淆的现象,且垂直方向更为严重。尤其是被测对象1 辨别hrir_final_155和hrir_final_158 数据处理过的音频信号时,几个方位全部辨别失败,其它被测试对象也存在类似问题。这些有待在今后研究中需进一步改善。
4 结束语
在FPGA 平台上,开发了一款能实现虚拟声源定位与3-D 环绕声效的IP 核,采用Prony 法设计了IIR的直接II 型结构的滤波器,选择5.1 声道的模型进行推导,获得了一个完整的5.1 声道到双声道转换的回放音频数字信号处理的模型。系统采用Verilog HDL语言在Nexys-3 Spartan-6 的开发平台上结合软核处理器MicroBlaze 搭建了测试系统,测试结果表明,本IP核实验了回放功能,并获得了一定的空间效果。对声回放有空间要求的声音重放系统的虚拟化实现,提供了一个较好的思路。
[1] Seki Y,Sato T.A training system of orientation and mobility for blind people using acoustic virtual reality[J].Neural Systems and Rehabilitation Engineering,2011,19(1):95-104.
[2] 张峥,黄强,范涛,等.利用头相关函数实现虚拟声源和运动声源[J].南开大学学报:自然科学版,2009,42(5):72-76.
[3] 谢菠荪.头相关传输函数与虚拟听觉[M].北京:国防工业出版社,2008.
[4] 莫尔斯P M,英格特K U.理论声学[M].吕如榆,杨训仁,译.北京:科学出版社,1984.
[5] 钟小丽,谢菠荪.头相关传输函数的研究进展[J].立体声与环绕声,2004(12):44-46,62.
[6] Simon Carlile.Virtual auditory space:generation and applications[M].London:R G Landes,1996.
[7] Otani M,Hirahara T.Numerical study on source-distance dependency of head-related transfer functions[J].Journal of Acoustics Soc.AM,2009,125(5):3253-3261.
[8] Yunjae Lee,Youngjin Park,Youn-sik Park.Newly designed HRTF measuring system[C].Japan:ICROS-SICE International Joint Conference,Fukuoka International Congress Center,2009:1781-1784.
[9] Zhang Wen,Zhang Mengqiu,Rodney A Kennedy,el al.On high-resolution head-related transfer function measurements:an efficient sampling scheme[J].Audio,Speech,and Language Processing,2012,20(2):575-584.
[10]Honda A,Shibata H,Gyoba J,et al.Transfer effects on sound localization performances from playing a virtual three-dimensional auditory game[J].Applied Acoustics,2007,68(8):885-896.
[11]Gerald Enzner,Martin Krawczyk,Falk-Martin Hoffmann,et al.3D recons tructi on of HRTF-fields fron 1D continuous measurements[J].Signal Processing to Audio and Acoustics,2011(10):157-160.
[12]Wall J A,McDaid L J,Maguire L P,el al.Spiking neural network model of sound localization using the interaural intensity difference[J].Neural Networks and Learning Systems,2012(99):1-13.
猜你喜欢
科教导刊·电子版(2022年5期)2022-03-19
家庭科学·新健康(2022年1期)2022-02-02
家庭科学·新健康(2021年11期)2021-11-23
家庭影院技术(2021年10期)2021-11-20
家庭影院技术(2021年1期)2021-03-19
紫禁城(2020年5期)2021-01-07
水泥工程(2020年4期)2020-12-18
家庭影院技术(2020年7期)2020-08-24
家庭影院技术(2018年10期)2018-11-02
家庭科学·新健康(2016年11期)2016-11-23
