
基于新浪微博API的话题分析系统
2015-02-24 06:00程广东秦一方
山东交通学院学报 2015年4期
程广东,秦一方
(连云港港口集团通信信息工程公司, 江苏连云港 222046)

基于新浪微博API的话题分析系统
程广东,秦一方
(连云港港口集团通信信息工程公司, 江苏连云港222046)
摘要:以从新浪微博平台海量信息中挖掘知识为目的,通过获取新浪微博开放平台授权并认证,调用新浪微博API(Application Programming Interface)相应的函数接口,获取单用户基本信息及所发微博信息,应用多用户遍历思想及迭代算法,获取大量用户基本信息及微博信息,并存储到数据库中,利用数据挖掘关联规则算法进行话题分析,并将分析结果通过可视化的方式展现,最终实现话题的关注度分析、话题间关联程度分析以及话题关注人群的特征分析。
关键词:微博;话题分析;数据挖掘;API
新浪微博是一个开放式的社交平台,利用平台提供的API,可以获取用户基本信息、用户微博、用户好友信息(关注人和粉丝)、话题信息以及用户实时位置信息等[1],将这些信息存入数据库,利用数据挖掘算法进行分析可以获得需要的知识。近年来新浪微博的普及度越来越高,到目前为止,累计用户已经将近4亿,成为世界范围公认的与Twitter齐名的第二大移动社交应用[2],信息量十分庞大,从庞杂的数据信息中获取想要的知识,数据挖掘与分析技术必不可少。
1系统结构分析
话题分析系统分为原始信息采集、数据库存储、算法实现信息提取、分析结果展示等四大模块。原始信息采集是项目最重要也是最基础的环节,利用新浪API获取所需的数据;数据库存储是项目中起衔接作用的必不可少的一环,用来连接数据获取与数据分析模块,将提取到的数据以统一的格式存储起来,便于数据分析;算法实现信息提取模块是项目的核心模块,生成用户想要获得的信息;分析结果展示模块将产生的信息以可视化的形式展现给用户。项目实现简易流程如图1所示。

图1 项目简易流程图
2系统实现
2.1搭建开发环境
搭建开发环境的流程如图2所示。
2.2提取数据
新浪API提取数据是信息筛选过程,即从新浪微博平台上的海量数据信息中筛选出数据分析所需要的信息。

图2 项目环境搭建流程图
2.2.1获取微博授权
利用新浪API提取数据,首先要在新浪开放平台上注册应用,获得回调地址、APP_KEY和APP_SECRET,一起填入项目中的config.properties文件中;然后通过weibo4j.examples.Oauth2.Oauth4Code.java文件完成新浪微博的Oauth认证[3],Oauth认证流程如图3所示。Oauth认证完后,开发者即可利用新浪API完成对用户信息的提取。
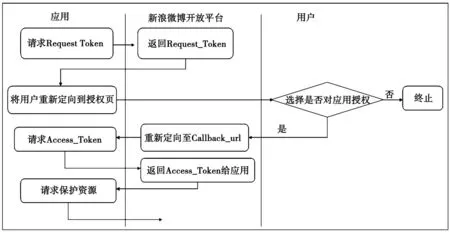
图3 Oauth认证流程图
2.2.2提取信息
新浪微博API是一组函数接口,通过调用对应的函数接口即可获得相应的功能[4]。
1)获取用户基本信息
①获取单个用户的基本信息
通过对API函数“weibo4j.examples.user.ShowUser.java”传入“uid”参数获得用户的基本信息。具体实现方法为:将由Oauth认证获得的“access_token”值赋给此函数的access_token参数;将用户的“uid”赋值给此函数的uid参数项;调用Users类中的showUserById(uid)函数,即可返回一个User对象,这个对象中即包含了此uid用户的基本信息;在Java Application上运行此函数,即可得到此用户姓名、性别、位置、粉丝数量等基本信息[5]。
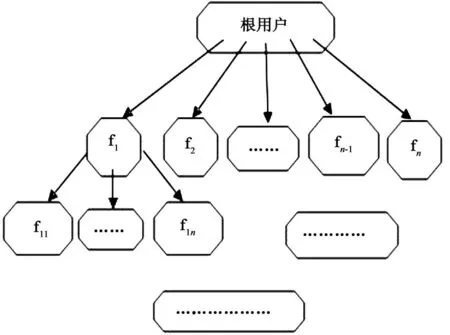
图4 遍历多用户信息模型图
②获取多个用户信息
通过获取用户粉丝uid的方法,即可获得足够数量的用户uid,根据多用户遍历的思想,通过一个用户 uid即可获得其所有粉丝的uid,然后再获取这些粉丝的粉丝的uid,如此迭代,即可获得足够数量的用户uid[6],多用户遍历思想如图4所示。
具体实现方法为:在导入的API_SDK包中找到获取粉丝uid的函数weibo4j.example.friendship.GetFollowersIds.java;从Oauth4Code类得到的“access_token”及根用户的“uid”值传入GetFollowersIds类的主函数中,调用FriendShips类中的getFollowersIdsById()函数获得根用户的所有粉丝的uid,将这些uid存入String ids[]数组中,利用迭代算法获得和这些uid有粉丝关系的所有uid[7],迭代算法实现为代码:
private void diedai(String[] ids , int max , String at){
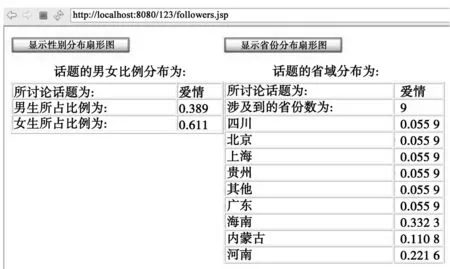
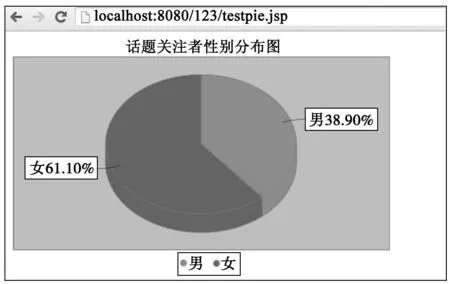
for(int i=0;i System.out.print(ids.length); con_to_showuser(ids); con_to_timeline(ids); Friendships fm=new Friendships(); fm.client.setToken(at); try { String[] id =fm.getFollowersIdsById(ids[i]); int maxx = id.length; diedai(id , maxx , at); } catch (WeiboException e) { e.printStackTrace(); } } 2)获取微博信息 ①获取某个用户的微博 通过调用API接口类 “weibo4j.example.timeline.GetUserTimeline.java”,即可根据用户的uid获得用户的微博信息,具体的实现方法为:获取用户uid和由Oauth认证得到的access_token;调用Timeline类中的getUserTimelineByUid(uid)函数, 返回一个StatusWapper类的对象,此对象中即包涵了用户所发微博的前20条微博信息[8]。 ② 获取多个用户的微博信息 通过迭代获取足够多用户的微博信息。 2.3数据库设计及数据存储 1)设计数据表 根据数据分析的需要,设计3张数据库表:user_info表、weibo_info表以及province表。user_info表用于存储用户的基本信息,包括用户uid、用户名uname、性别gender、省份province、位置location等信息。weibo_info表用于存储用户微博的信息,包括用户uid、微博tid、微博内容text等信息。province表用于存储省份编号pid和省份名称pname;创建视图usable,是联合user_info表和weibo_info表的部分字段组成的,包括用户uid、性别gender、省份province、位置location、微博内容text等属性[9]。 2)连接Java项目与数据库 在下载JDBC包到工程以后,就可以将Java工程与指定数据库进行连接。 3)数据库存储 通过提取数据的方法,Java项目获得用户信息及用户微博信息,Java项目与数据库连接后通过执行sql语句,将数据存储到数据库中对应的数据表中。 2.4数据分析 数据挖掘算法包括关联规则算法、分类算法和聚类算法等[10],本文主要用到关联规则算法。 1)分析话题的关注度 分析话题的关注度是从微博表中找出与待分析话题相关的微博条数与微博表中总微博条数的比例[11]。通过sql查询语句实现,查找出与待查找话题相关的微博条数及查找出表中所有的微博条数。 2)分析两个话题的关联程度 通过对支持度和可信度的分析得到两个话题的关联程度。话题的支持度即微博中提及到的话题与收集到的微博总条数之比;而话题的可信度就是话题一推导出话题二的真实度,即在提及到话题一的微博中,同时也提及到了话题二的微博条数的比例[12]。 通过执行4条sql语句实现,分别统计话题一的微博总数、话题二的微博总数、通过API所采集到的经过purify()函数整理过的微博总数、同时提及到话题一和话题二的微博总数。 3)分析某话题关注人群的特征 分析关注某话题人群的特征包括人群的性别分布和人群的地域分布。通过genderfb()函数获得某话题的男女分布比例,该函数的代码如下: public float[] genderfb(String topic) throw SQLException{ getConn(); float[] str=new float[2]; int i=0,j=0,k=0; String sql1="select count(*) from utable where text like′%"+topic+"%′"; String sql2="select count(*) from utable where text like′%"+topic+"%′and gender′=′m′"; String sql3="select count(*) from utable where text like′%"+topic+"%′and gender=′f′"; st=(Statement) conn.createStatement(); ResultSet rs1=st.executeQuery(sql1); st=(Statement) conn.createStatement(); ResultSet rs2=st.executeQuery(sql2); st=(Statement) conn.createStatement(); ResultSet rs3=st.executeQuery(sql3); while(rs1.next()){ String count1=rs1.getString("count(*)"); i=Integer.parseInt(count1); } while(rs2.next()){ String count2=rs2.getString("count(*)"); j=Integer.parseInt(count2); } while(rs3.next()){ String count3=rs3.getString("count(*)"); k=Integer.parseInt(count3); } BigDecimal bdi=new BigDecimal(Integer.toString(i)); BigDecimal bdj=new BigDecimal(Integer.toString(j)); BigDecimal bdk=new BigDecimal(Integer.toString(k)); if((i==0)){ str[0]=str[1]=0; } else{ str[0]= bdj.divide(bdi,3,BigDecimal,ROUND_HALF_UP).floatValue(); str[1]= bdk.divide(bdi,3,BigDecimal,ROUND_HALF_UP).floatValue(); } conn.close(); return str; } 通过给这个函数传入话题名即可给用户返回一个float[]数组,数组的值为关注该话题的男女比例。 调用provincenum()函数获得话题关注人群所在省份的数目,代码如下: public int provincenum(String topic) throws SQLException{ getConn(); int i=0; String sql="select count(distinct province) form utable where text like ′%"+topic+"%′"; st=(Statement) conn.createStatement(); ResultSet rs1=st.executeQuery(sql); while(rs1.next()){ String count1=rs1.getString("count(distinct province)"); i=Integer.pareseInt(count1); } conn.close(); return i; } 调用provincefb1()函数,通过传入话题名和省份数目得到这些关注者所在省份的名称,代码如下: public String[] provincefb1(String topic , int i) throws SQLException{ getConn(); float[] f=new float[i]; String[] s=new String[i]; String sql1="select distinct province from utable where text like ′%"+topic+"%′"; st=(Statement) conn.createStatement(); ResultSet rs2=st.executeQuery(sql1); int ii=0; while(rs2.next()){ String result=rs2.getString("province"); String sql2="select pname from province where pid=′"+result+"′"; st=(Statement) conn.createStatement(); ResultSet rs3=st.executeQuery(sql2); while(rs3.next()){ String count1=rs3.getString("pname"); s[ii]=count1; } ii++; } conn.close(); return s; } 最后再调用provincefb2()函数,通过传入话题名、省份名和省份数目,获得各个省份的关注者占总关注者的比例,代码如下: public float[] provincefb2(String topic , String[] ss , int max) throws SQLException{ getConn(); float[] ff=new float[max]; int ii=0, jj=0; for(int i =0; i String sql="select count(*) from utable where text like ′%"+topic+"%′ and location like ′%"+ss[i] +"%′"; String sql1="select count(*) from utable where text like ′%"+topic+"%′"; st=(Statement) conn.createStatement(); ResultSet rs=st.executeQuery(sql); st=(Statement) conn.createStatement(); ResultSet rs1=st.executeQuery(sql1); while(rs.next()){ String count=rs.getString("count(*)"); ii=Integer.pareseInt(count); } while(rs1.next()){ String count=rs1.getString("count(*)"); jj=Integer.pareseInt(count); } BigDecimal bdi=new BigDecimal(Integer.toString(ii)); BigDecimal bdj=new BigDecimal(Integer.toString(jj)); ff[i]=bdi.divide(bdj,3,BigDecimal,ROUND_HALF_UP).floatValue(); } conn.close(); return ff; } 通过调用上述几个函数,即可获得话题关注者的人群地域分布。 2.5利用JSP/html技术与用户互动 通过JSP/html技术完成与用户的互动,实现项目的实用性与可操作性。 系统从html页面完成对用户请求的捕捉,即完成对请求参数的收集,然后通过jsp页面完成对请求参数的处理以及对处理结果的展示[13]。其中html页面接受用户请求并将该请求发送给jsp页面以供其分析处理,Jsp页面通过调用JavaBean类方法和嵌入JavaScript完成对用户请求信息的处理与分析[14]。 在项目中总共用9个页面完成与用户的信息互动,分别为: 1)main.html。用于选择功能,共分为话题关注度分析、话题关联度分析和话题关注者人群特征分析等3个功能,由3个超链接组成。 2)attention.html。用于实现接受“话题关注度分析”功能的参数,页面提供供用户输入话题和条件限制的表单。 3)attention.jsp。用于对页面attention.html接收到的参数进行处理与展示结果。 4)association.html。用于实现接受“话题关联度分析”功能的参数,页面提供供用户输入待分析的两个话题名称的表单。 5)association.jsp。用于对页面association.html接收到的参数进行处理与展示结果,如图5所示。 图5 话题关联度分析结果 6)followers.html。用于实现接受“话题关注者人群特征分析”功能的参数,页面主要提供供用户输入话题名称的表单。 7)followers.jsp。用于对页面followers.html接收到的参数进行处理和以表格形式展示结果,如图6所示。 图6 话题关注者人群特征分析结果 8)genderpie.jsp。用于将话题关注者的性别分布以扇形图的形式展示出来,如图7所示。 9)provincepie.jsp。用于将话题关注者的省份分布以扇形图的形式展示出来,如图8所示。 图7 话题关注者性别分布结果 3结语 话题分析系统通过开放的新浪微博平台API,获取大量用户基本信息及其所发微博信息,实现将信息存入数据库,通过数据挖掘关联算法分析了话题的关注度、话题间的关联度以及话题关注人群的特征,并通过可视化的界面与用户可交互及分析结果展示。 图8 话题关注者省份分布结果 系统通过用户遍历思想采集大量信息,采集数据的数量及话题覆盖程度与根用户及粉丝圈的关注话题密切相关,下一步需要就如何采集到相对全面的新浪微博信息进行深入研究。 系统应用数据挖掘关联算法进行分析,应用支持度和可信度计算方法较为简单,对数据深入挖掘需要进一步探索和研究。 参考文献: [1]廉捷,周欣,曹伟,等.新浪微博数据挖掘方案[J].清华大学学报(自然科学版),2011,51(10):1300-1305. [2]李彪.微博中热点话题的内容特质及传播机制研究——基于新浪微博6025条高转发微博的数据挖掘分析[J].中国人民大学学报,2013,27(5):85-89. [3]黄延炜,刘嘉勇.新浪微博数据获取技术研究[J].信息安全与通信保密, 2013,34(06):23-26. [4]田野.基于微博平台的事件趋势分析及预测研究[D].武汉:武汉大学, 2012. [5]张国安,钟绍辉.基于微博用户评论和用户转发的数据挖掘[J].电脑知识与技术,2012,19(27):35-38. [6]杨雪.浅析数据挖掘技术[J].华南金融电脑,2005,13(8):91-95. [7]乔莹.微博用户粉丝演化模型的构建与实证[D].保定:河北大学, 2012. [8]熊小兵,周刚,黄永忠,等.新浪微博话题流行度预测技术研究[J].信息工程大学学报,2012,13(04),67-69. [9]萨师煊,王珊.数据库系统概论[M].北京:高等教育出版社,2002:156-180. [10]毛国君.数据挖掘原理与算法[M].北京:清华大学出版社,2005:40-55. [11]王晓光.微博客用户行为特征与关系特征实证分析——以“新浪微博”为例[J].图书情报工作,2010,54(14):178-182. [12]尹书华.基于复杂网络的微博用户关系网络特性研究[J].西南师范大学学报(自然科学版), 2011,55(6):203-206. [13]方忠.JSP技术及其在动态网页开发中的应用[J].微型机与应用,2000,19(11):38-41. [14]赵春兰.基于JSP的电子网站数据库连接研究[J].科技创新导报, 2010,7(6):72-74. (责任编辑:郎伟锋) The Topic Analysis System Based on Sina Micro-Blog API CHENGGuangdong,QINYifang (CommunicationandInformationEngineeringCorporation,LianyungangPortGroup,Lianyungang222046,China) Abstract:With the purpose of mining knowledge from mass information of Sina micro-blog platform, authorization and authentication from Sina micro-blog open platform is obtained, corresponding function interfaces of Sina micro-blog API (Application Programming Interface) is ultimately realized, the basic information of individual user and the micro-blogs is got, multi user traversal thought and iterative algorithm is applied, the basic information of a large number of users and micro-blogs is got,the information to the database is stored,the topic by using the data mining algorithm of association rule is analyzed,the analysis results is applied in a visual way,analysis of the topic of attention and analysis of the correlation between topics and analysis of the characteristics of topic concerned crowds is ultimately realized. Key words:micro-blog; topic analysis; data mining; API 文章编号:1672-0032(2015)04-0078-09 中图分类号:TP393.092 文献标志码:A DOI:10.3969/j.issn.1672-0032.2015.04.015 作者简介:程广东(1981—),男,山东嘉祥人,软件部副经理,主要研究方向为软件开发、系统集成、大数据处理等. 收稿日期:2015-09-15

 猜你喜欢
大众投资指南(2021年35期)2021-02-16电力与能源(2017年6期)2017-05-14中国中医药信息杂志(2016年7期)2016-12-01中国市场(2016年38期)2016-11-15人间(2016年26期)2016-11-03中学课程辅导·教师教育(中)(2016年9期)2016-10-20信息通信技术(2015年6期)2015-12-26沈阳师范大学学报(教育科学版)(2014年3期)2014-08-15河南科技(2014年23期)2014-02-27电子设计工程(2014年18期)2014-02-27
猜你喜欢
大众投资指南(2021年35期)2021-02-16电力与能源(2017年6期)2017-05-14中国中医药信息杂志(2016年7期)2016-12-01中国市场(2016年38期)2016-11-15人间(2016年26期)2016-11-03中学课程辅导·教师教育(中)(2016年9期)2016-10-20信息通信技术(2015年6期)2015-12-26沈阳师范大学学报(教育科学版)(2014年3期)2014-08-15河南科技(2014年23期)2014-02-27电子设计工程(2014年18期)2014-02-27
