
基于PMI-IR算法的他源类网络流行称谓语语义取向的计算与分析
2015-02-23 02:44王攸然
安康学院学报 2015年4期
王攸然
(武汉大学 文学院,湖北 武汉 430070)
任何称谓语都有一定的感情色彩,或褒或贬或不褒不贬,都与其所处的上下文有关联。在网络交际中,一些网络流行称谓语诸如“女汉子”“二货”“屌丝”“砖家”等极具网络特色[1],这些称谓语除了能够起到交际中需要的指称作用之外,还常常附带了对于被称呼的这一类人群的某种特定的看法和情感色彩。
词语的情感语义计算属于语义计算中褒、贬义计算的一部分,一般语义褒贬计算对象包括词语、句子和语篇。1997年,Hatzivassiloglou和Mc Keown通过形容词的词缀和连用时所使用的连词来计算形容词的褒贬度,精确率较高,但局限于形容词的计算。词语的情感语义计算就是词语的相似度计算,只不过是计算要计算的词与设定好的褒贬基准词之间的相似度[2]。通常有两种计算方法:一是基于语料统计的PMI-IR计算方法[3-4];二是基于语义词典的方法,中文词语的计算一般是基于《知网》计算词和词之间的语义距离[5-6]。
本文主要采用PMI-IR计算方法,对一类来自于现实生活交际并在网络中使用时产生了书写形式变化的流行称谓语进行一些语义褒贬转化的计算和分析。
一、网络流行称谓语分类
按照网络流行称谓语的产生来源进行分类,大致可以分为两类:一是自源类。有一些可以说是源发自网络,比如“屌丝”“二货”“逗逼”……,本文将上述源发自网络的称谓语称为“自源类”;二是他源类。有一些在现实交际中早已使用,只不过在网络交际中产生了新义的称谓语,这种新义不同于原本的词典义,有些甚至产生了不同于日常使用的书写形式,比如“砖家”来源于“专家”、“叫兽”来源于“教授”、“深井冰、蛇精病”来源于“神经病”等,这里将这一类现实生活中存在而在网络使用中产生新义的称谓语称为“他源类”。
将被测词分为两组进行计算:他源类被测词集={专家、教授、神经病};新形式*={砖家、叫兽、蛇精病、深井冰}。因本文考察的是网络称谓词,所以选用的基准词都源自王国璋主编的《汉语褒贬义词语用法词典》中用以形容人的典型的褒贬词[7]。选用的两组基准词分别为:
正向基准词集={勤奋、善良、自强、正直、真诚、聪明、勇敢、优秀、正确、可爱、谦虚};
负向基准词集={懒散、邪恶、颓废、猥琐、虚伪、愚蠢、懦弱、恶劣、错误、可恨、傲慢}。
二、情感语义计算
根据互信息的理论,要计算被测词的情感语义,首先要计算出被测词与一个正向基准词的互信息值PMI(word,pword),再计算出被测词与一个负向基准词的互信息值PMI(word,nword),由于通过一般搜索引擎无法得出文本的总量N,因而可用概率统计中的条件概率概念导出:
其中,word1分别取每一个被考察的称谓语word,word2分别取每一个正向情感基准词pword和每一个负向情感基准词nword,对上述给定的正向情感基准词集合Pwords和负向情感基准词集合Nwords分别计算各自的PMI,再将所有正向基准词的PMI之和减去所有负向基准词的PMI之和,便得到了被考察称谓词的语义取向SO(Semantic Orientation),即:
具体计算步骤如下:
第一步:确定基准词。基准词实际上是带有确定褒义或贬义的词,也可以说是极度正向或极度负向的情感词。
第二步:通过网络搜索引擎,分别统计每一个被测词和基准词在网络里出现的次数。再统计每一个被测词分别与每一个正向基准词以及与负向基准词同时出现的次数。
第三步:利用公式(1)和(2)计算被测词的语义倾向。
最终计算结果如表1所示。
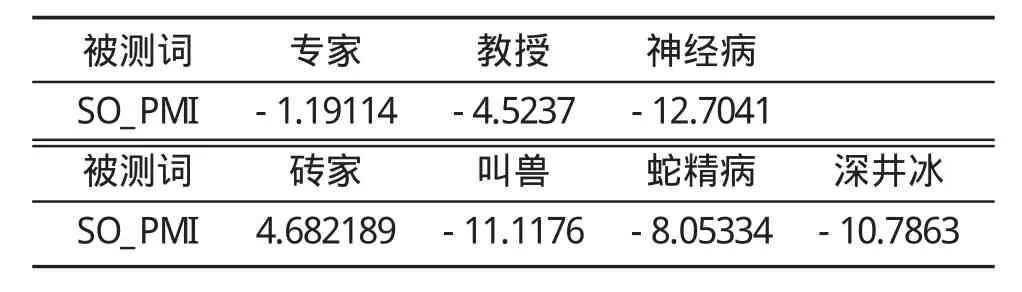
表1 被测网络称谓词情感语义取向值
三、结果分析
表1中的SO_PMI值为正就是正向值,为负就是负向值,数值越小表示负向程度越高,数值越大表示正向程度越高。被测称谓语中的“教授”、“专家”的情感语义都发生了向负向的转化,“神经病”无明显转移情况;在有新书写形式的称谓语中的“蛇精病”、“深井冰”、“逗逼”的情感语义发生了向正向的转变,“叫兽”发生了向负向的转变,而“砖家”无明显情感语义转化。
非常明显,从“专家、教授、叫兽”的SO_PMI计算结果来看,“叫兽(-11.1176)”比“教授(-4.5237)”的负向程度更高,这符合出现“叫兽”这一新写法的情感倾向,也从侧面说明了这两个称谓语所发生的情感语义转化。而“神经病、深井冰、蛇精病”的SO_PMI计算值依次是-12.7041,-10.7863,-8.05334。也就是说相较于“神经病”,“深井冰、蛇精病”的情感语义负向程度降低,因此根据计算结果,将“深井冰、蛇精病”划分为情感语义发生了正向转化的称谓语那一类。“砖家”在“聪明、愚蠢”这一对基准词计算中负向值最高,这也符合我们在网络交际中观察到的结果。值得注意的是,“砖家”的SO_PMI计算值出乎意料为正向值。究竟是计算上的错误还是其情感语义本来就无明显转化?仅凭PMI计算无法断定。这个问题以后可以通过社会调查,或用其他方式做一个对比调查来进行进一步研究。
四、研究中尚存在的问题
本文尝试通过语义计算中基于搜索引擎的PMI算法,计算网络流行称谓语的情感语义转化情况。结果表明,部分称谓语的情感语义符合预期转化情况,说明此方法是可行的,并且能客观反映这类网络流行称谓语目前的情感语义状况。但数据收集和计算中还存在一些问题,这也是笔者日后研究的方向。
第一,数据“提纯”。基于搜索引擎的PMI计算要求,通过搜索引擎得到基本数据,在利用搜索引擎搜索的结果中,将被测词和基准词同时出现的数据作为计算的依据是建立在二者的同时出现能够反映出它们间的相关性也就是互信息值的基础上。比如,搜索“专家”和“可爱”同时出现的概率,期望的数据是人们针对“专家”的感觉、评论是“可爱”的,但很多数据与人们对专家的评价无关,只是出现在同一段落和文章中,这样的数据实际上是不符合我们要求的,是需要剔除的“杂质”,所以在以后的研究中要注意剔除“杂质”,以提高精确度。
第二,时间检索。尝试了在搜索引擎上通过按时间检索得到数据,并计算出能反映被测称谓语随时间变化的SO_PMI值,而SO_PMI值能更直观有效的反映被测称谓语的转化情况。但由于工作量大且限于目前的搜索技术,数据难以收集且影响因素较多,导致有效性低,所以没有进行进一步研究。因此,本次计算结果只能反映目前被测称谓语的情感语义状况并通过分析推测其转化情况,而无法客观观察具体转化情况:是一直向正向或负向转化,还是先向一个方向转化再向另一个方向转化,转化过程中是否有停滞,停滞或转化与哪些因素有关。这些问题尚需进一步研究。
第三,基准词设定。在计算过程中基准词是计算的重要依据,本文选用的基准词都是出自于《汉语褒贬义词语用法词典》中用以形容人的褒贬词,其可靠性有待考察,目前来看是可以作为计算参考的。但由于本文的被测称谓语及其情感语义都来源于网络,因而通过这些基准词反映出的情感语义倾向有时会与我们在网络中使用时的感受不同,怎样制定更适合被测称谓语的基准词有待进一步研究。
五、结语
本文采用PMI计算方法,考察了几个网络流行称谓语的情感语义转化情况。分析发现,网络流行称谓语的情感语义转化有两个特点:一是部分称谓语的情感语义的正向转化来自于他们本来的负向意义;二是网络流行称谓语的意义变化快,受一些热点事件的影响大,他们的情感语义的转化有时具有时效性,转化情况也比较复杂。若进一步研究,则一方面可以优化计算,得出更客观精确的结果,反映具体的转化情况;另一方面可以通过社会调查等方法进行对比研究,使我们能更深层的观察这类称谓语的情感语义转化情况、动因、规律等等。
[1]占升平.网络造词中的隐喻与重构——以“屌丝”为例[J].作家,2013(10):193-194.
[2]杨昱昺,吴贤伟.改进的基于知网词汇语义褒贬倾向性计算[J].计算机工程与应用,2009,45(21):91-108.
[3]段秀婷,何婷婷,宋乐.基于PMI-IR算法的Blog情感分类研究[C]//第五届全国青年计算语言学研讨会论文集,2010:22-28.
[4]李斌,卢俊之,章成志,等.基于聚类引擎的话题褒贬度计算[C]//内容计算的研究与应用前沿——第九届全国计算语言学学术会议论文集,2007:588-594.
[5]朱嫣岚,闵锦,周雅倩,等.基于Hownet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.
[6]王振宇,吴泽衡,胡方涛.基于HowNet和PMI的词语情感极性计算[J].计算机工程,2012,38(15):187-193.
[7]王国璋,汉语褒贬义词语用法词典[M].北京:华语教学出版社,2001.
猜你喜欢
计算机与网络(2022年2期)2022-03-17
有色金属(矿山部分)(2021年4期)2021-08-30
疯狂英语·新阅版(2020年11期)2020-12-21
好日子(下旬)(2020年6期)2020-08-04
当代陕西(2020年24期)2020-02-01
劳动保护(2018年8期)2018-09-12
山东工业技术(2016年15期)2016-12-01
中外文摘(2016年4期)2016-03-17
读者·校园版(2015年7期)2015-05-14
燃气轮机技术(2014年4期)2014-04-16
