
基于加权估计的软件实验室能力比对测试结果评价
2015-02-21 06:34王勇利王艳军张海军
实验室研究与探索 2015年3期
王勇利, 王艳军, 张海军
(中国人民解放军91404部队,河北 秦皇岛 066001)
基于加权估计的软件实验室能力比对测试结果评价
王勇利, 王艳军, 张海军
(中国人民解放军91404部队,河北 秦皇岛 066001)
为实现对软件测评实验室能力比对测试结果的定量分析与评价,本文在融合参加能力比对测试各方所发现软件缺陷的基础上,以测试广度和测试深度作为评价要素,选取正态分布作为趋势估计曲线,通过调整诸权重及系数、归一化趋势估计曲线幅度等手段,统一评价基准,构建出一种能力比对测试结果评价体系模型。还对此模型组织实施、关键过程实现手段等方面进行详细阐述。该评价模型可直接用于对软件测评实验室能力比对测试结果的定量分析与评价,对于构建新的定量评价体系也具有较强的借鉴意义。
软件测评; 能力比对; 定量评价; 等价类划分
0 引 言
能力测试是用来考核实验室的测试、校准或鉴定所能达到的能力和水平所组织的实验室间的比对测试[1],软件测试实验室应定期组织或参加实验室间的比对[2],组织和参加实验室间比对或能力测试是软件测评实验室核查测试或鉴定结果的有效性、确保测评工作质量的主要方法,也是确认方法性能的技术手段之一[3]。对于重要的被测软件,可采用不同测试机构或多个项目组进行平行测试比对,以保证测试结果的质量[4];由实验室在其自行组织的能力测试及比对,不仅是实验室对内部人员技术能力进行考核、评比的一种有效途径,其结果也是实验室自身能力评审的重要内容。通过能力比对测试,不仅能够评价实验室的检测能力,还可从统计数据中分析出准确度的影响因素,是控制检测质量的有效措施[5]。
软件缺陷分布呈现不确定、不易穷举等特性,因此对于用于能力比对的测试样例,无法确保其预设缺陷域(指由组织者在测试样例中预先埋置的软件缺陷的集合)总能完全覆盖该样例的缺陷全集域(测试样例软件客观存在所有缺陷的集合)。简单地统计各测试组测试结果在预设缺陷域中的击中数或命中概率,并不能客观、全面地反映该测试组的测试水平,以此为依据对能力比对活动进行的评价也缺乏相应的合理性、公正性。同样,由于不能保证在任何情况下存在某个测试组所发现的缺陷域能够完全涵盖其他各测试组所发现的缺陷域、不同严重等级的软件缺陷所反映的测试成效和水平也存在差异,故以各测试组所发现缺陷总数为依据对实验室能力比对活动进行评价,缺乏共有的评比基准,无法保证评价结果的有效性、合理性。
学科与机构评价的一般方法是选取或构建出某一指标体系作为评价模型,以此为基础分别计算出每个被评价对象的得分,之后按照得分进行排序分层[6]。本文选取能够反映测试技术能力的主要指标作为评价要素,提出一种基于加权赋值、趋势估计拟合的软件测评实验室能力比对测试结果评价模型——“加权估计法”,实现能力比对测试结果的定量分析和评价。
1 评价要素选取
通过比较Z比分数的大小实现对实验室的能力评定[7]是比较常见的做法,然而这种稳健的统计技术仅适用于单一要素下的评定,无法针对多要素进行综合评价[5]。在现实研究中,为了客观全面地分析问题,常要记录多个指标并考虑众多的影响因素,这样的数据虽然可以提供丰富的信息,但同时使得数据分析工作更趋复杂化[8]。评价模型中评价要素的选取规模应同时兼顾多维化和简单性的要求,在满足评价需求的前提下,尽可能地对评价要素空间进行降维处理。
对于软件测评实验室承担的软件测试项目,过程度量覆盖了测试过程的有效性、效率和质量所需的各个方面,包括生产率、测试用例有效性、测试广度、测试深度、测试用例通过数、测试用例失败数、不符合项数等[9]。能力比对测试主要是对各实验室(测试组)技术能力的考核,因此可仅选取与测试技术能力相关的主要度量特性作为构建评价模型的要素因子,而项目管理、实施效率等不太相关的度量特性则可加以忽略。上述诸测试过程度量中,测试广度用于衡量有多少测试需求已经被测试(测试广度理论上应该达到100%),测试深度用于衡量被测试覆盖的基本路径占被测软件中基本路径总数的百分比[9],综合两者即反映出测试工作的整体有效性,可作为“加权估计法”评价模型的要素空间。
文献[9]从测试需求角度阐述的测试广度、测试深度一般性定义,适用于对测试有效性的常规性评价。能力比对测试重点关注各测试方之间的相对测试能力,并不关注某个或全部测试方测试工作的绝对有效性。考虑到软件测试的直接目的是发现软件中存在的缺陷[10],故可从测试所发现的软件缺陷域重新定义测试广度和测试深度相对含义。测试广度与测试深度这种反向定义,适用于基于测试结果的定量评价活动。
2 相关定义
定义1 问题划分:将所有的软件缺陷进行等价类划分[11]后得到的输出。
定义2 问题划分的类型:分为验证性问题划分和逻辑性问题划分2种。问题划分的类型是利用测试结果进行测试深度分析的基础。
问题划分的类型的确立标准可根据测试项目具体特性进行制定。比如,可以根据发现缺陷的测试设计的复杂性来进行分类:验证性问题划分可以是对某一类不需要依靠复杂逻辑设计或流程设计就能发现的软件缺陷的抽象,逻辑性问题划分可以是对某一类需要利用复杂逻辑或流程设计才能发现的软件缺陷的抽象;也可以根据发现缺陷的测试设计(用例)所涵盖的功能点数量进行分类:验证性问题划分的衡量标准是发现缺陷的测试设计只涵盖1个功能点,逻辑性问题划分的衡量标准是发现缺陷的测试设计涵盖2个或2个以上的功能点。
定义3 得分S:利用“加权估计法”进行测试结果评价所得到的最终定量结果,得分S=测试广度指标E+测试深度指标1D1+测试深度指标2D2。
定义4 要素权重:包含广度权重WE、深度权重1WD1、深度权重2WD2。各要素权重决定了测试广度、测试深度对最终评价结果S的贡献程度。
定义5 测试广度指标E:某测试组所覆盖的问题划分数占总问题划分数的比重,反映了测试活动的广度特性。
定义6 测试深度指标1D1:某测试组所覆盖的逻辑性问题划分占全体问题划分的加权比重。
定义7 解算系数:用于计算D1而为验证性问题划分、逻辑性问题划分所设置的权值,体现了验证性问题划分、逻辑性问题划分对最终得分的贡献程度。
定义8 测试深度指标2D2:设某测试组逻辑性问题划分所覆盖的缺陷或用例的数量占该测试组全部缺陷或用例数量的比重为k,测试深度指标2D2为k在趋势估计函数(曲线)中的取值。D2是对某个具体测试方测试设计合理性、均衡性的估计和评价,是对D1的修正,反映了测试深度的合理性。
定义9 基础函数:用于构建趋势估计函数(曲线),基础函数应具有明确的统计特性和意义,能够反映测试深度比重合理性随测试结果中各种问题划分比重的估计趋势。
定义10 趋势估计函数(曲线):对选取的基础函数进行幅度归一化处理后,即为对k的趋势估计函数(曲线),其反映了某一测试组逻辑性问题划分与验证性问题划分比重的合理性。幅度归一化处理是指:将基础函数的定义域、值域均调整到[0,1]区间。
3 “加权估计法”评价模型概述
“加权估计法”评价模型是用于对各测试方能力比对测试结果进行定量分析的评价体系,其主要思想是:在将所有测试组所提交的测试缺陷进行融合整理后,通过选取恰当的要素权重、解算系数、趋势估计函数(曲线)进行微调,构造出“加权估计法”评价模型,在实现一致的评价基准基础上,进行评估计算、量化打分,最终为每个测试组都计算出一个得分,实现对各测试组测试结果的定量评价。
4 “加权估计法”评价模型算法
通过设置各个要素权重控制得分S所采用的分制,本文中模型采用百分制,各要素权重为:E的权重WE=40,D1的权重WD1=40,D2的权重WD2=20。设共有t个测试组,利用“加权估计法”对第i个测试组的测试工作进行分析评价后,所得到的结果为得分Si(0≤S≤100,i∈(1,2,…,t)),则“加权估计法”模型为:
(1)
其中:Ei为第i个测试组的测试广度指标,反映该测试组的广度特性;D1i为第i个测试组的测试深度指标1;D2i为第i个测试组的测试深度指标2;D1i+D2i反映该测试组测试的深度特性。
4.1 测试广度指标Ei
设在对t个测试组所发现的测试问题进行汇总归纳后,得到的问题划分的数量为N个,某一测试组所覆盖的问题划分数量为Ni(0≤Ni≤N,i∈(1,2,…,t)),则该项目组的测试广度指标Ei为:
Ei=WE·Ni/N=40Ni/N
(2)
4.2 测试深度指标1D1i
对所有问题划分按照其测试深度进行分类,并为其赋予不同的解算系数,此处设:验证性问题划分的解算系数为1.5;逻辑性问题划分的解算系数为2。
设所有的N个问题划分中,验证性问题划分的个数为nv,逻辑性问题划分的个数为nl,则nv+nl=N,令:Be=1.5nv+2nl。
设第i个测试组所覆盖的Ni个问题划分中,验证性问题划分的数量为nvi,逻辑性问题划分的数量为nli,则nvi+nli=Ni,测试深度指标1D1i为:
(3)
4.3 构造基础函数
正态分布表达了随机变量(数据)与其出现的频数之间的关系[12],自然科学、社会现象等领域的许多大样本统计特性中广泛呈现出正态分布的趋势,具有较强的代表性和典型性,其统计特性与测试深度比重合理性的趋势变化相似。数学中的黄金分割法按照长段占整体的0.618将整体划分为两部分,短段比长段、长段比整体均等于0.618,体现出和谐而严格的比例特性,被认为是公认的美学定律[13],其在建筑学、艺术、自然科学等领域中应用广泛,著名数学家华罗庚在“优选法”就提出“0.618法”以快速获取试验结果的最佳方案[14],在数学上现已推导验证了在不考虑使用对分法的情况下黄金分割法为最佳的结论[15]。“加权估计法”模型可选择“黄金分割点”作为测试深度比重合理性的拐点,在正态分布函数的基础上拟合出基础函数。
4.4 测试深度指标2D2i
设第i个测试组的nvi个验证性问题划分所涵盖的测试用例数为Cvi,其nli个逻辑性问题划分所覆盖的测试用例数为Cli,则该测试组所发现问题对应的用例总数为Cvi+Cli,逻辑性问题所对应的测试用例占所有测试用例的比重为ki=Cli/(Cvi+Cli)。
选取正态分布曲线

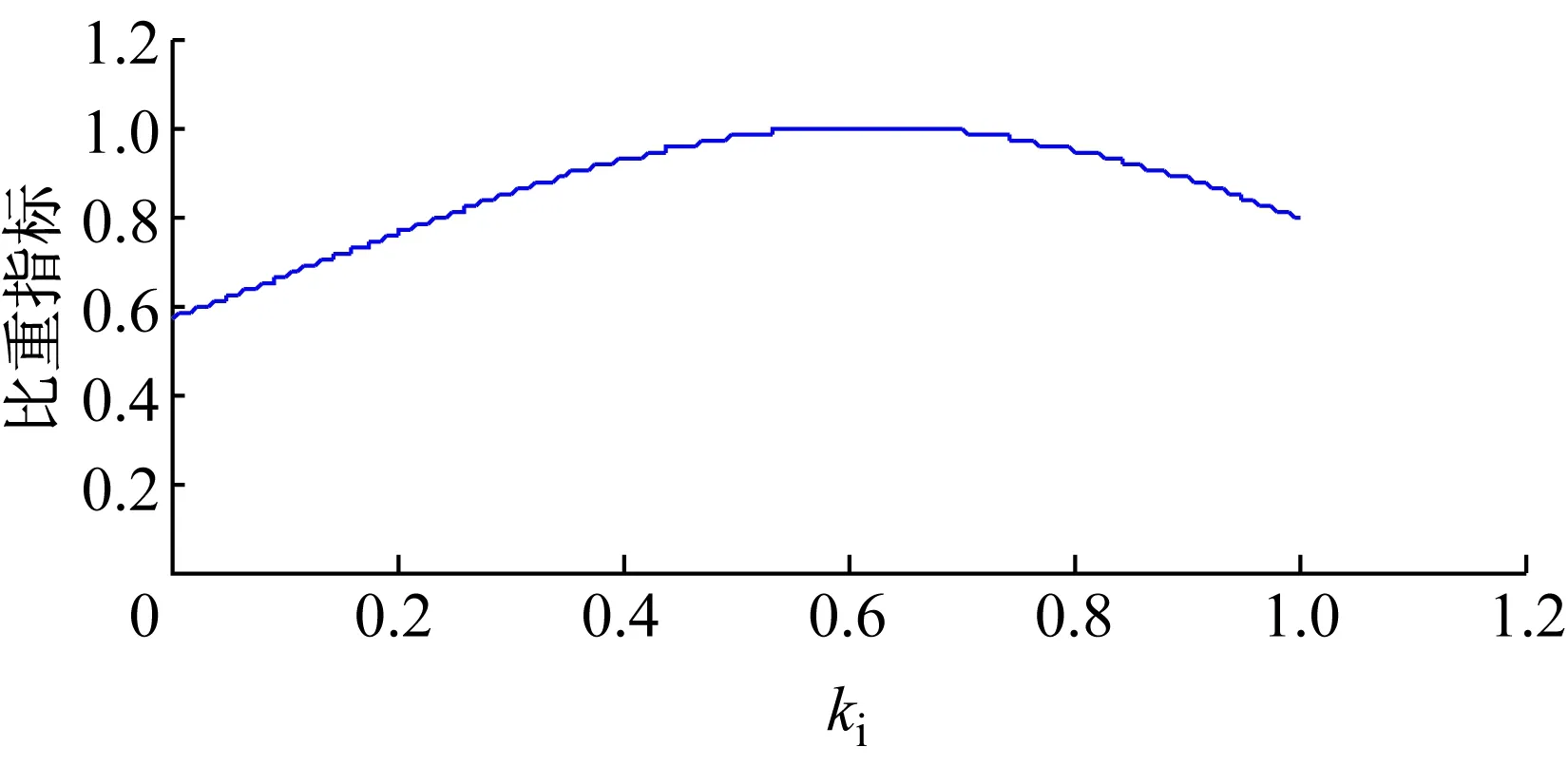
第i个测试组的测试深度指标2D2i为:
(4)
4.5 得分Si
由式(1)得,第i个测试组的最终得分Si为:
4.6 比对分析
各测试组的最终得分Si是对每个测试组测试工作的整体定量评价,其分值的高低在某种程度上反映了该测试组测试工作质量的高低:得分越高的测试组,其测试工作相对更充分、有效。
5 组织实施
5.1 工作流程
“加权估计法”的主要实施流程可分为:汇总整理、模型调整、评价计算3个阶段。
(1) 汇总整理。将所有测试组所发现的软件缺陷汇总后,对每个问题逐个分析,确定问题划分、确定每个软件缺陷所属的问题划分、确定各个问题划分的类型,统计各组所覆盖的问题划分、各组所覆盖的每个问题划分所对应的测试用例数(或缺陷数),最终得到结果评价所需的统计数据。
(2) 模型调整。通过调整要素权重、解算系数、基础函数、趋势估计函数(曲线),对“加权估计法”模型进行微调,最终确定评价模型。
(3) 评价计算。入统计数据到已确定的评价模型,实现对各测试组测试结果的评价解算,得到定量评价结果。
具体实施过程如图2所示。

5.2 完善措施
“加权估计法”的实施过程不仅仅是数据统计、分析建模等技术上的实现,还需要考评组、各个测试组的有效配合和相互协调。为了保证评价模型的合理性,最大程度地缓解人为主观因素对最终考评模型的影响,具体实施过程中可采取以下完善措施:
(1) 各测试组均选派组内人员参加考评组,通过将所有缺陷汇总打乱的方式,在屏蔽问题发现者的前提下,讨论问题划分的确立、确定各个软件缺陷所属的问题划分、确定各个问题划分的类型,以确保数据融合处理的准确性和公正性;
(2) 要素权重、解算系数、基础函数以及趋势估计函数(曲线)的确定和构建可以请所有测试组参加,以确保最终确定的评价模型的公正性和受认可度。
(3) 模型建立后,应告知相关利益方(包括各测试组、组织方等),在得到所有相关利益方的认可后,再将统计数据(包括问题划分、各个问题划分的类型、各组所覆盖的问题划分、各组每个问题划分所对应的测试用例数或缺陷数等)输入模型进行解算,得出最终评价结果。
(4) 评价模型确立后,禁止随意修改。如确需变动模型,必须同样得到各相关利益方的认可,其过程应遵循“共同构建、全员发布、认可后再使用”的原则。
(5) 为了确保问题划分的顺利实施,在能力比对测试实施前,组织者可以推荐所有测试组在其所提交的“软件问题报告单”或等效文档中遵循“一单一缺陷”的原则。
6 关键过程的实现手段
6.1 确定问题划分
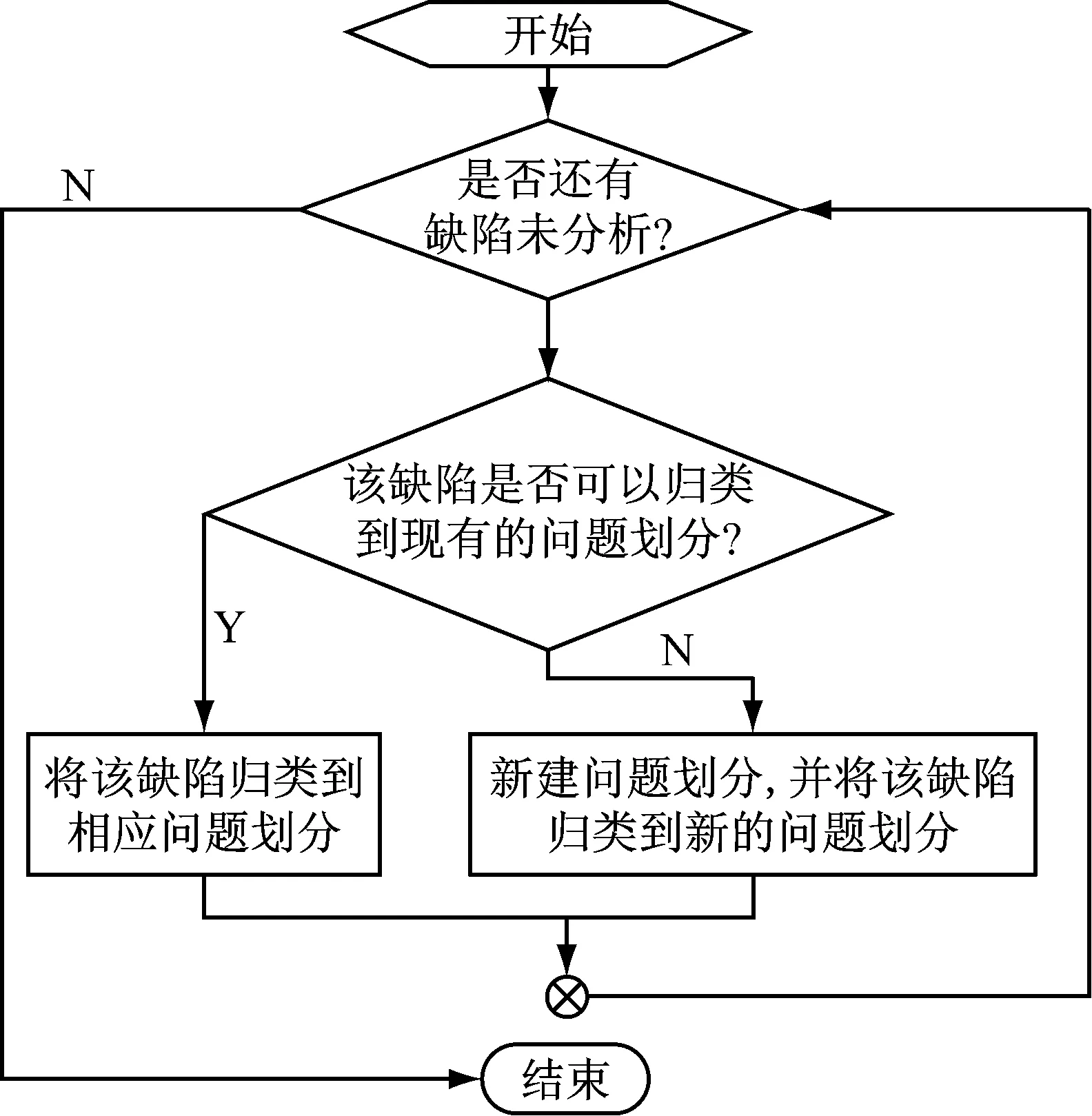
问题划分确立的基本过程是:汇总各组所提交的软件缺陷后,考评组逐个分析软件缺陷,利用等价类划分的方法,确定是否新建问题划分或将软件缺陷划入到已有的问题划分中去,如图3所示。
6.2 评价计算
“评价计算”是按照模型算法求解各测试组的广度指标Ei、深度指标1D1i、深度指标2D2i以及各组定量评价结果Si的过程,可以利用Excel等报表工具的计算功能,快速构建模型解算报表(如图4所示),相比采用Visual C++、C#等高级编程语言编写专用的解算程序,这种方式更加快捷、有效[16],有利于实验室能力比对工作的灵活开展。

图4 利用Excel实现评价计算
7 结 语
“加权估计法”依托横向融合测试结果、构造统一评比基准等手段,对各个测试组测试结果进行定量分析,实现能力比对测试的结果量化考核,为能力比对测试活动中对各测试组(测评实验室)的最终整体评价提供了重要的参考依据。该模型具有良好的操控性和灵活性,考评组可利用要素权重、解算系数、趋势估计函数(曲线)等多种因子实现对模型的微调和定制,最大程度地适应具体的能力比对测试场景。
[1] GJB 2715A-2009《计量通用术语》[S].2009.
[2] 中国合格评定国家认可委员会.能力验证规则[S].2006.
[3] GJB 2725A-2001《测试实验室和校准实验室通用要求》[S].2001.
[4] GJB 2725A-2001附加指南《软件测评实验室测评过程和技术能力要求》[S].2007.
[5] 孙彩玲,张永祥,田纪春.基于主成分分析的实验室比对中检测能力的综合评价[J].实验室科学,2012,15(2):118-121.
[6] 黄水清,张俊,阎素兰.黄金分割法在学科及机构评价中的应用[J].图书情报工作,2012,56(22):33-36,41.
[7] 中国合格评定国家认可委员会.能力验证结果的统计处理和能力评价指南[S].2006.
[8] 富伯亭,杨海燕.主成分分析在实际中应用的探索[J].山西广播电视大学学报,2010(1):45-46.
[9] 梁成才.软件测评实验室软件测试项目的度量研究[J].计算机工程,2005,31(23):90-92.
[10] 胡 琨,刘 浩,刘 涛.初议软件测试[J].科技广场,2008(5):241-242.
[11] 范明红,浦云明,汪志华.等价类测试与划分研究[J].计算机技术与发展,2009,19(7):62-65.
[12] 辛秀东.正态分布统计技术在线缆质量控制中的应用[J].电线电缆,2005(5):35-37.
[13] 邱均平,赵蓉英.世界一流大学及学科竞争力评价的意义、理念与实践[J].评价与管理,2007,2(5):33-38.
[14] 邱均平,杨瑞仙.2009年世界一流大学与科研机构学科竞争力评价的做法、特色与结果分析[J].评价与管理,2009,7(2):19-28.
[15] 邱均平,杨瑞仙.基于ESI数据库的材料科学领域文献计量分析研究[J].情报科学,2010,28(8):1121-1126.
[16] 黄宇.Excel电子表格在电气调试中的应用[J].煤炭技术,2009,28(8):48-49.
The Weight and Evaluation Model for Software Testing Ability Comparison among Software Testing Laboratories
WANGYong-li,WANGYan-Jun,ZHANGHai-Jun
(NSTC, Qinhuangdao 066001, China)
In the testing ability comparative test for software testing laboratories, it is hard to estimate the results of every laboratory quantitatively. To solve the intractable conundrum, this paper advances the “Weight and Evaluation Model” (the WE model), an evaluating model for software testing ability comparison, based on weighting evaluation, curve fitting and trending. The WE model takes the extent and depth of every software testing activities synthetically and synchronously, and can evaluate each lab's testing results quantitatively according to the same criteria, This paper also indicates the crucial actualizing means and method for organizing and actualizing the WE model.
software testing; ability comparative test; quantitative estimate; equivalent compartmentalization
2014-05-18
王勇利(1982-),男,安徽巢湖人,硕士,工程师,软件测试人员,研究方向为软件测试及其工程化。
Tel.:15233011029;E-mail:lhxl999@163.com
TP 311.5
A
1006-7167(2015)03-0246-05
猜你喜欢
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
当代陕西(2019年8期)2019-05-09
电子竞技(2019年22期)2019-03-07
电子竞技(2019年21期)2019-02-24
电子竞技(2019年20期)2019-02-24
电子竞技(2019年19期)2019-01-16
成都信息工程大学学报(2018年3期)2018-08-29
高中生·天天向上(2018年1期)2018-04-14
电子元器件与信息技术(2017年4期)2017-03-08
成才之路(2016年16期)2016-07-11
