
基于GMM模型的声纹识别模式匹配研究*
2015-02-21 08:09彭亚雄
通信技术 2015年1期
于 娴,贺 松,彭亚雄,周 晚
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
基于GMM模型的声纹识别模式匹配研究*
于 娴,贺 松,彭亚雄,周 晚
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
模式匹配是声纹识别的关键问题之一,为了提高识别正确率和识别效率,本文采用GMM模型建模,训练阶段利用EM算法求取参数集,并通过MAP准则实现模式识别。引入LBG算法求取起始参数值,并设计了基于3种方法的联合判决门限决策。实验结果表明 GMM模型利用平均值向量和协方差矩阵使它具有更好的模型能力,当高斯混合数为32时识别率达到最高,联合判决门限决策有效降低了误识率与虚警率,并提高了识别效率。
声纹识别 模式匹配 LBG 高斯混合模型
0 引 言
随着信息时代的来临,计算机、通信技术等高科技技术在我们的日常生活中随处可见,让我们的生活变得更加便捷与多彩,但随之而来的问题也造成了很多人的困扰。各种卡片必须随身携带,复杂绕口的密码太难记忆,卡片丢失、密码被盗也频繁带来安全隐患和财产损失。而生物识别是生物学和信息学等技术的结合,使得身份鉴定变得更加安全、方便且不需要记忆,帮我们解决了这一难题,它主要是通过运用生理和行为这种与生俱来的特征来实现身份的识别。
声纹识别也属于生物识别,它具有获取方便、使用简单、识别成本低、可远程操作等优势,被广泛地应用于金融、证券、公安、军队、社保、医疗及其他民用安全认证等领域。当前中国对声纹识别的运用尚处起步阶段,有很广阔的发展前景。声纹识别的主要过程有预处理、特征提取、模式匹配、识别判断,本文主要对声纹识别的模式匹配算法进行研究。
声纹识别模式匹配方法有很多,如动态时间归整(DTW)、人工神经网络(ANN)、隐马尔可夫模型(HMM)、高斯混合模型(GMM)等,由于DTW精度难以对正导致识别率低,ANN训练时间较长,HMM训练计算量较大,本文选取当前文本无关声纹识别的主流技术高斯混合模型(Gaussian Mixture Model ,GMM)作为建模方法。通过GMM的离散组合,用均值和协方差矩阵来表示高斯函数,从而得到GMM[1-2]。由于高斯混合模型GMM 对语音声学特征分布有较好的拟合特性,基于最大似然决策的GMM 方法已经成为说话人识别系统的主流方法[3]。它是高斯概率密度函数的延展,因此能够很好地模拟各种形状的密度公布。
1 GMM模型算法
1.1 参数训练
GMM中的参数是利用训练样本{x1,x2,…,xm}通过计算p(x,z)的最大似然估计的方法得到,m为高斯混合密度的混合数,z为隐含随机变量。这种最大似然估计可以利用期望值最大化算法(Expectation MaXimization Algorithm ,EM),通过迭代得到[4]。其具体步骤如下:
p(x,z)的最大似然估计
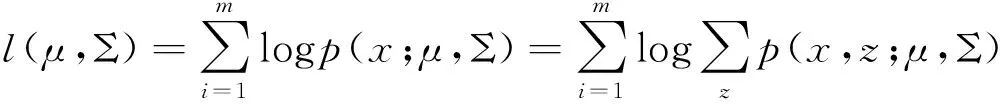
(1)
(2)
式中,i=1,2,…,m,Qi(zi)为混合权值,且∑zQi(z)=1,Qi(z)≥0,μ(j)为均值矢量,Σ(j)为协方差矩阵,这里取为对角矩阵,w(j)为混合权重,且
(3)


图1 GMM模型Fig.1 GMMdiagram
式(2)固定Σ(j),对μ(j)求导后等于0,可得
(4)
同理可得
(5)
EM算法的基本思想是把初始模型与新模型λ*,按照式(6)重复迭代,
(6)
直到它们满足
(7)
时为止,这时的λ*为最优值。
这就是EM迭代算法估计GMM参数的过程,通常情况下要得到一个稳定的GMM需要经过五到十次的迭代。
1.2 GMM模型识别
GMM的具体步骤是:在训练阶段, 根据最大似然估计准则从语音特征矢量中找出一个使得m个xi的平均概率最大的参数集λ;而在识别阶段,则是根据最大后验概率准则(Maximum A Posterior ,MAP)[5],找出使识别语音概率最大的λi作为识别结果,则由贝叶斯理论,最大后验概率可以写成
(8)
又因为p(x)没有先验知识且为无条件概率,上式可化简为求模型对数据的先验概率,即

(9)
GMM之所以在声纹识别中运用普遍是因为它是m个高斯函数的加权平均,能够用一定量的高斯函数拟合任意语音的特征分布。
2 求取初始点
通过验证,选取不同的起始参数,会大大影响EM算法的识别率和迭代速度,因此,为了提高识别率,选取一个好的初始点是必不可少的。常用的求取初始点的算法有LBG算法、K-均值算法等,由于LBG算法压缩比大且失真较小,而K-均值算法对数据集中的孤立点较为敏感,少量的孤立点数据就会严重影响到聚类结果,因此本文选取目前码本训练性能比较好的LBG(LINE-BUZO-GRAY)算法[6]做为GMM训练中寻求初始点的方法。LBG算法步骤:
1)用训练向量的均值做为向量集的质心,并将向量集按照式(10)所示的方法分裂成双倍的数量。
(10)
其中,ο为向量集的质心,ε=0.05,表示分裂参数。
2)测量每个训练向量的欧氏距离,找出与其距离最短的质心οl,将向量分别与它们的οl分配到一个集合中去。
3)再用每个新集合的均值作为其新的质心。
4)不断执行第2、3步直到前后两次的训练向量与其οl的距离和的总体之差‖Jn-Jn-1‖小于临界值Ω=0.01为止。
5)不断执行步骤1直到向量集达到我们所需的数量,它们的均值就是我们所需要的量化结果。

图2 LBG算法流程Fig.2 LBG algorithm flow chart
3 判决门限
目前大部分声纹识别研究都局限在对某方法的有效性及对算法的局部改进上,这些方法都因为只侧重于对某方面的研究而产生了片面性。实际上,语音具有各种各样的特征,为了提高语音的识别率,本文使用联合判决门限对语音做出识别判断。既是先利用短时平均能量、短时平均过零率作为初步检测,再用GMM作精确检测的序贯识别[7]。声纹识别可用两个重要的参量来表示其识别性能,误识率和虚警率。误识率是指把待测语音中的伪冒者错误判定为与参考模板中某样本相匹配的情况所占的比例;虚警率是指拒识待测语音中正确语音段的情况所占的比例[8]。而不同的判决门限可以调节误识率和虚警率以达到相应的识别要求。
1)短时平均能量定义为
(11)

(12)
不同的α值会产生不同的汉明窗,本文取α=0.46。

2)短时平均过零率为
(13)
取
(14)
用与1)相同的方法得到均值zμ,及高、低门限值zh、zl。
3)计算训练样本与得到的GMM模型的相似程度,分别取最小和最大的作为高、低门限值sh、sl。
把上面3种方法分为两级, 第1级由短时能量与过零率共用判决, 第2级由GMM模型最大后验概率来完成,判决方法如图3所示。

图3 联合判决门限决策Fig.3 Combined threshold decision

联合判决门限不仅可以让三种方法互补,且在第一部就可排除距离模板最偏远的测试样本,缩小了需GMM检测的样本范围。且由于短时平均能量和过零率都已在预处理阶段得到,无需在识别阶段再重复计算,有效地降低了计算量。
4 实验结果及分析
实验选用的是GMM的说话人识别系统,语音采样率为8 000Hz,帧长为20ms,语音参数为16维Mel频率倒谱系数。实验语料来自50人 (男女各25人) ,每人30条语音样本, 每个样本时间为2s。
4.1GMM模型识别结果
下图为分别运用LBG算法及K-均值算法求取初始点的情况下,不同高斯混合数时GMM模型的识别结果对比。

图4 GMM实验结果Fig.4 Experiment results of GMM
从图4可以看出,在其他条件相同的情况下,运用LBG算法求取初始点比运用K-均值算法具有更高的识别率。GMM模型的识别率会随着高斯混合数的增大,先升高再降低,当高斯混合数为32时识别率达到最高。
4.1 选择不同门限对识别率的影响
下图为分别以GMM模型低门限值(sl)、高门限值(sh)及联合判决决策作为判决门限时的误识率和虚警率柱状图。
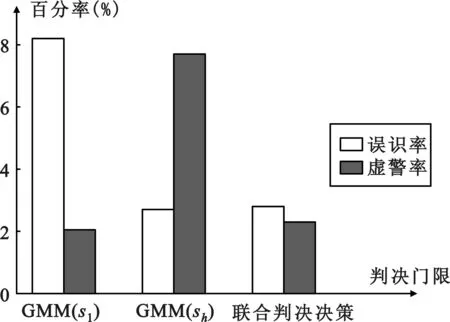
图5 不同判决门限时的误识率和虚警率Fig.5 False positive rate and false alarm rate histogram of different decision threshold
根据实验结果可知, 当采用GMM模型作为判决门限时,随着门限值的变化误识率和虚警率成反比,这个矛盾在单一门限中是固然存在的,而通过使用联合判决门限则使得误识率和虚警率都被降低到对识别率影响最小的状态。此外, 所有样本中仅通过第一级识别就被拒绝的有38.3%,而由其造成的虚警率仅为0.3%,有效提高了识别效率。
5 结 语
本文提出了在使用LBG算法求取初始点的前提下,结合EM算法和MAP准则完成声纹识别的训练和识别过程,并在统一基准条件下研究了不同的求取初始点的算法和高斯混合数对识别率的影响。优化了判决门限的设定,从实验结果来看,本文提出的联合判决门限决策在没有增加计算量的情况下有效地克服了传统声纹识别的识别性能矛盾,误识率和虚警率明显低于传统的GMM模型识别方法,说明本文提出的方法是有效的,此联合判决门限决策对基于其他方法的语音识别都具有参考价值。但必须指出的是虽然GMM模型的混合数越多,识别的结果就会越接近测试样本的分布情况,但相对的,所花费训练和识别的时间也会随之增加。且上述识别结果都是在实验室良好的环境下取得的,在现实环境中,由于噪声和信道的干扰,严重影响了识别率。在今后的工作中,将针对如何高效地提高GMM模型混合数和声纹识别的鲁棒性做进一步研究。
[1] SLEIT A, SERHAN S, and NEMIR L. A HistogramBasedSpeaker Identification Technique[C]//Internati-onal Conference on ICADIWT.Piscataway:IEEE Pr-ess,2008:384-388.
[2] 吴朝晖,杨莹春.说话人识别模型与方法[M].北京:清华大学出版社,2009:26-31. WU Chao-hui, YANG Ying-chun. Speaker RecognitionModel and Method[M].Beijing: Tsinghua Univers-ity Press,2009:26-31.
[3] 王韵琪,俞一彪.自适应高斯混合模型及说话人识别应用[J].通信技术,2014,47(7):738-739. WANG Yun-qi, YU Yi-biao. Adaptive Gaussian Mixture Model and Its Application in Speaker Recognition[J].Communications Technology,2014,47(7):738-739.
[4] DUDA R O,HART P E,STORK DG.Pattern Classific-ation[M].Second Edition.New York:Wiley Inters-cience,2000:108-112.
[5] GAUVAIN J,LEE C.Maximum a Posteriori Estimation for Multivariate Gaussian Mixture Observations of Markov Chains[J].Speech and Audio Processing,IEEE Transactions on,1994,2(2):291-298.
[6] YOSEPH L,Buzo A, GRAY R M.An Algorithm for Vec-tor Quantizer Design[J].IEEE Tran Commun,1980,28(1): 84-95.
[7] 王炳锡.语音编码[M]. 西安: 西安电子科技大学出版社, 2002. WANG Bing-xi.Speech Coding[M].Xi'an: Xidian U-niversity Press,2002.
[8] 王秋雯.基于GMM-UBM的快速说话人识别方法[D].哈乐滨:哈尔滨工业大学, 2011. WANG Qiu-wen. Rapid Speaker Recognition Based on GMM-UBM[D].Harbin:Harbin Institute of Tech-nology,2011.
YU Xian(1989-),female, graduate student, majoring in voiceprint recognition and speech signal processing.
贺 松(1974—),男,硕士,副教授,主要研究方向为信号处理;
HE Song(1974-),male,M.Sci., associate professor, mainly working at signal processing.
彭亚雄(1963—),男,副教授,主要研究方向为信号处理;
PENG Ya-xiong(1963-), male, associate professor, mainly working at signal processing.
周 晚(1987—),女,硕士,助讲,主要研究方向为电子通信。
ZHOU Wan(1987-), female, M.Sci., assistant lecturer, mainly working at electronic communication.
Pattern Matching of Voiceprint Recognition based on GMM
YU Xian, HE Song, PENG Ya-xiong, ZHOU Wan
(College of Big Data & Information Engineering,Guizhou University, Guiyang Guizhou 550025, China)
Pattern matching is one of the key problems of voiceprint recognition. In order to improve the accuracy and efficiency of recognition, this paper adopts GMM modeling, applies the EM algorithm to calculate parameter set during the training stage, and achieves pattern recognition via MAP criterion. LBG algorithm is introduced to calculate the initial parameter values, and a combined threshold decision is designed based on 3 methods. Experiment results show that GMM, with mean vector and covariance matrix, enjoys better modeling capability, and reaches the highest recognition rate when the mixed number is 32. The combined threshold decision effectively reduces the false acceptation rate and false alarm rate, and meanwhile, it improves the efficiency of recognition.
voiceprint recognition; pattern matching; LBG; Gaussian mixture model
10.3969/j.issn.1002-0802.2015.01.020
2014-09-19;
2014-12-20 Received date:2014-09-19;Revised date:2014-12-20
用于社区司法矫正的声纹识别系统研究项目(黔科合SY字[2013]3105号);贵州省中药现代化科技产业研究开发专项(黔科合中药字[2013]5066号);贵州省工程技术研究中心建设项目(黔科合G字[2014]4002号)
Foundation Item:The Research Program of Voiceprint Recognition System for Community Judicial Correction(Guizhou Branch of SY[2013]3105);The Special Research and Development of Guizhou TCM Modernization Scientific and Technological Industry(Guizhou Branch of TCM[2013]5066);The Construction Program of Guizhou Engineering Technology Research Center(Guizhou Branch of G[2014]4002)
TP391.4
A
1002-0802(2015)01-0097-05

于 娴(1989—),女,硕士研究生,主要研究方向为声纹识别、语音信号处理;
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
数字通信世界(2020年2期)2020-03-04
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
中国听力语言康复科学杂志(2019年3期)2019-06-24
火力与指挥控制(2019年4期)2019-06-14
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
