
基于社会网络的协同推荐方法
2015-02-20 02:27:01汪千松蒋胜王忠群
长江大学学报(自科版) 2015年16期
汪千松,蒋胜,王忠群
(安徽工程大学现代教育中心, 安徽 芜湖 241000)
基于社会网络的协同推荐方法
汪千松,蒋胜,王忠群
(安徽工程大学现代教育中心, 安徽 芜湖 241000)
[摘要]针对传统协同过滤推荐算法存在推荐精度低的问题,提出了一种基于社会网络的协同推荐方法。该方法融合了社会网络中用户的相似度与信任度,首先计算用户间的评分相似度;再由直接信任度与间接信任度加权得出用户信任度;最后综合用户相似度与信任度得出用户间的推荐权重,并以推荐权重来选取最近邻居集,为目标用户形成推荐。试验结果证明,该方法可有效提高推荐系统的推荐精度。
[关键词]社会网络;协同过滤;推荐精度;信任度;推荐权重
随着信息技术与电子商务的飞速发展,商品信息数据的爆发式增长导致人们淹没于信息数据的海洋之中,如何快速、有效地找出用户的兴趣偏好信息并给予相应地推荐这一问题,成为近年来人们研究的热点。推荐技术可有效地缓解信息过载为人们带来的困扰,但仍然存在推荐精度低的问题。
针对推荐技术精度低的问题,文献[1]利用社会学原理,从用户信任网络出发,兼顾用户群体间兴趣偏好,通过信任的可传递性来提高推荐效率;文献[2]通过引入了信任支持度的概念来准确表述信任网络中的客户信任关系,提出了一种信任度与信任支持度相结合的客户信任模型;文献[3]采用随机游走的方式选取最优的邻居集,以云模型相似度方法计算项目间的相似度,该方法提高了算法的效率;文献[4]采用了正反相结合的方式,提出了基于信任与不信任关系的推荐方法;文献[5]为了提高推荐结果的准确性以及可靠性,提出了一种结合语义Web和用户信任网络的协同过滤推荐模型;文献[6]为了在节点之间建立信任关系,从而提出了一种基于群组的信任管理模型。
最近邻居集的选取作为协同过滤推荐技术的关键步骤,其准确性直接影响系统的推荐准确性。较早之前就有学者研究表明,用户往往更加倾向于接受熟人、好友而非推荐系统的推荐[7~9],可见推荐的准确性不仅仅与目标用户的兴趣偏好相关,还与其在社会网络中的用户信任有更加紧密的联系。为此,笔者通过融合目标用户在社会网络中的相似度与信任度,提出了一种基于社会网络的协同推荐方法。
1理论与方法
1.1基于用户-项目评分的相似度计算
1)建立用户-项目集定义用户集合为U={u1,u2,…,un},商品项目集合为I={i1,i2,…,in};ru,i表示用户u对项目i的行为(如购买或评分行为),当用户无行为时ru,i则记为0;所有用户对项目的行为可以表示为一个m×n的矩阵,记为Rm×n。
2)用户-项目评分相似度计算目前相似度的计算方法主要余弦相似度、修正的余弦相似度及Pearson相关相似度度量方法,笔者采用修正的余弦相似度计算方法:

(1)

1.2基于社会网络的用户信任度计算
传统协同过滤推荐算法主要是依据相似用户具有相似的偏好兴趣,但由于用户的评分数据较为稀疏,导致在计算用户相似度时,存在较大的偶然因素,无法较为准确地度量用户间的相似性[10]。假设在某个推荐数据集中,2个用户ub、uc均属于用户ua的邻居集;并且在以往的历史推荐里,用户ub、uc对ua各推荐了10次。通过用户uc的反馈得知,由用户ub推荐的10次结果中只有2次结果符合用户ua的兴趣;而由uc产生的推荐符合ua兴趣偏好的结果有8次,这表明用户ua对uc给出的推荐信任度要远远高于ub给出的推荐。而在现实环境中,人们更加倾向于采纳亲戚或好友给出的推荐,即在社会网络中,信任度的高低对目标用户的购买决策具有较大的影响作用。
因此,笔者在用户评分相似度的基础之上,利用社会网络中用户间的信任关系作为选取最近邻居的另一个根据。信任在社会网络中的传递涉及到直接和间接信任2个方面:直接信任即是2个网络用户节点之间直接可以建立联系,笔者的研究中表示为2个用户之间有一定数量的共同评价项目;间接信任即2个网络用户节点之间并没有直接的联接关系,但是由网络中的其他节点联接起来,这体现了信任的可传递性。
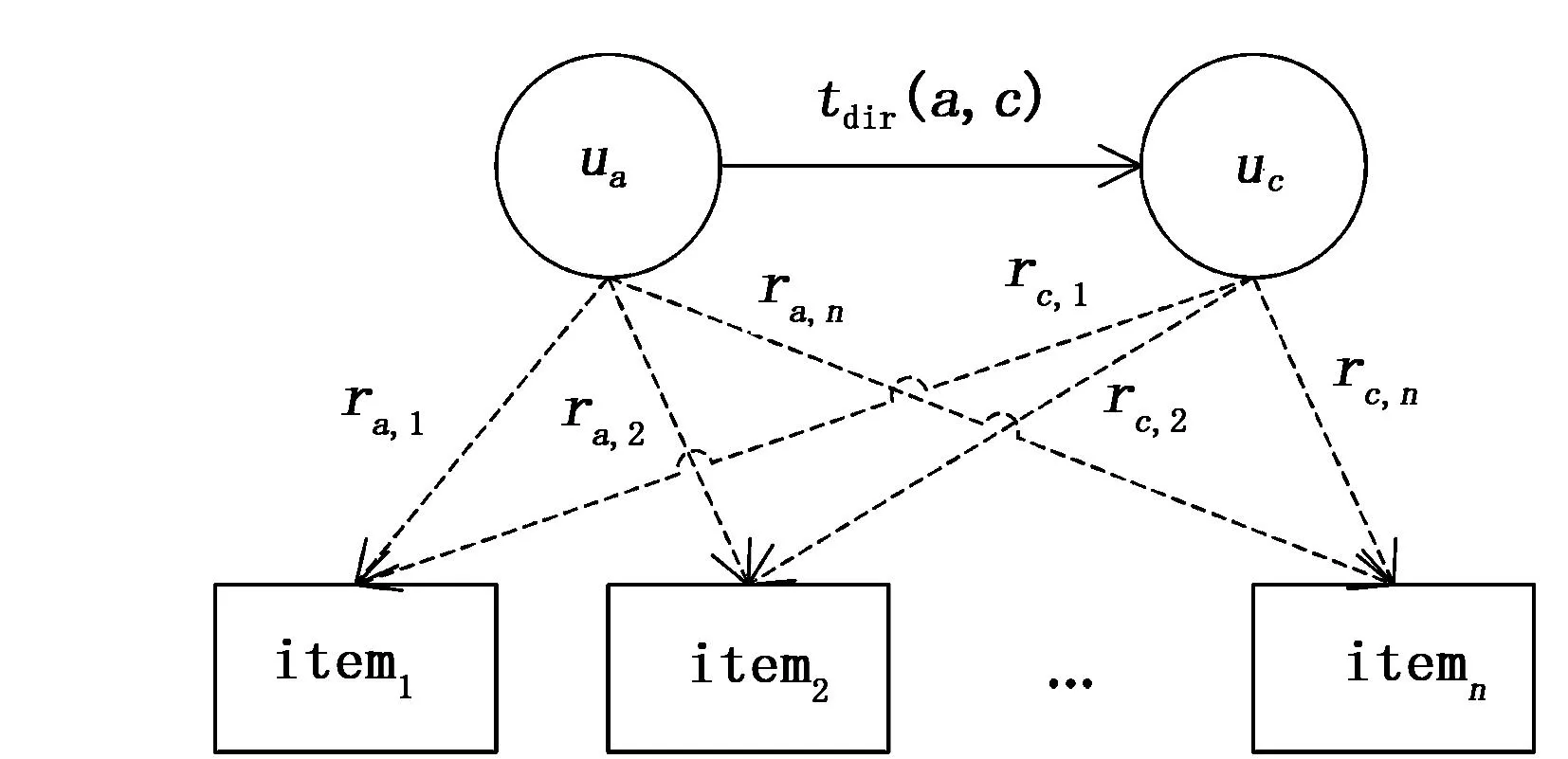
图1 社会网络中直接信任关系图
1)直接信任定义用户直接信任度如图1所示,其中item1,item2,…,itemn表示用户ua与uc共同评分的项目集,tdir(a,c)表示用户ua与uc的直接信任度,ra,n表示用户ua对项目itemn的评分。
对用户uc所有评价项目集合Ic,且j∈Ic:

(2)

依据预测评分与真实评分之间的误差,可以得出用户之间的直接信任计算公式:

(3)
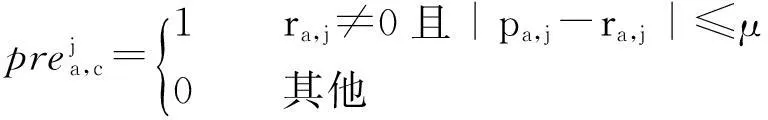
(4)
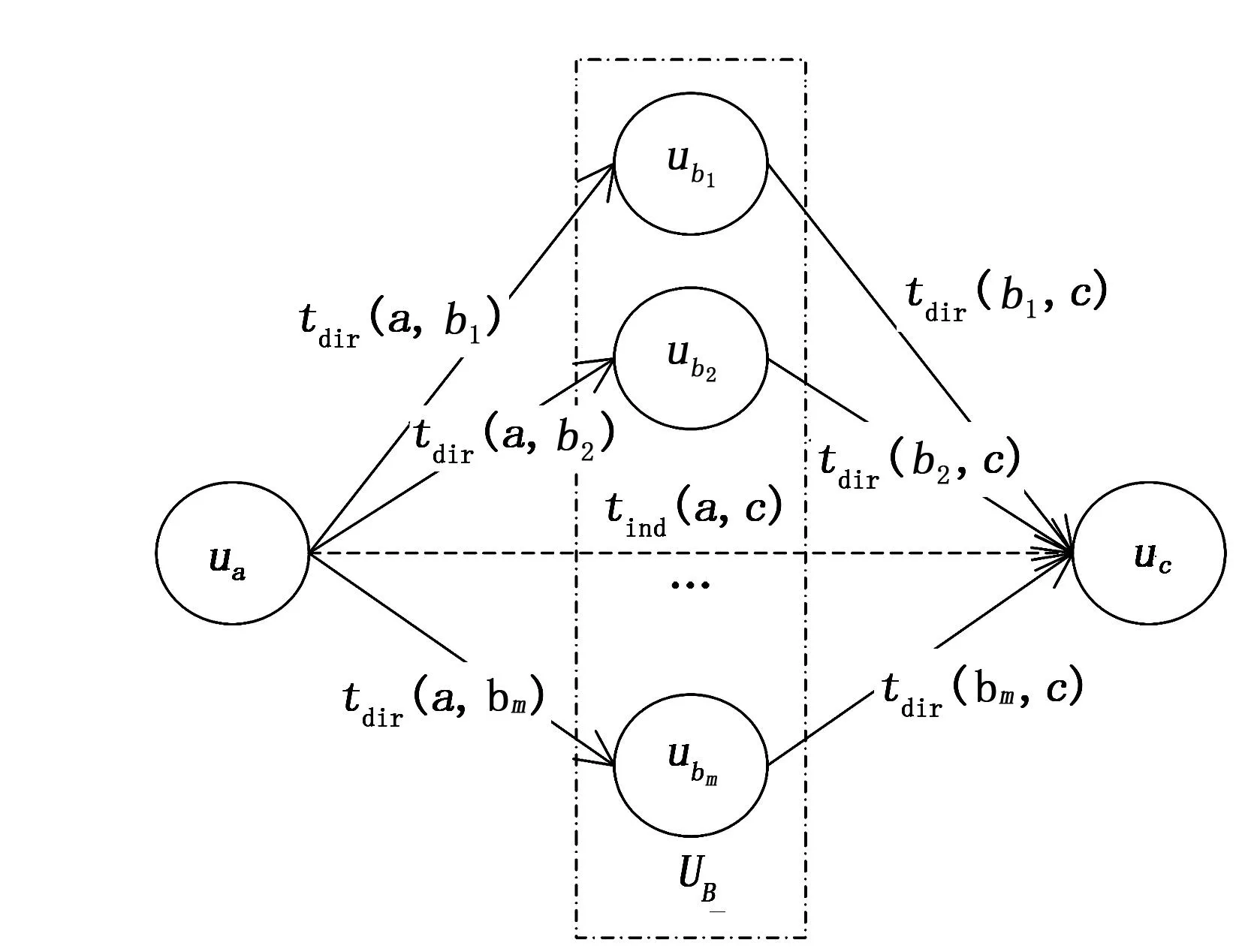
图2 社会网络中用户间接信任关系图
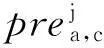
2)间接信任社会网络中,用户间的间接信任反映出信任具有可传递性的特点。假设在用户ub、uc之间并没有共同评分项目,那么用户间直接信任度为0;但这显然对用户信任度的描述是不完全正确的。因此,笔者定义用户信任度是综合了直接信任与间接信任。在社会网络中用户的间接信任关系图如图2所示,其中集合UB表示用户ua、uc共同的邻居集,tind(a,c)表示用户ua对用户uc的间接信任度。
基于以上分析,在社会网络中,只考虑2步可达信任关系,即只通过一个中间用户建立2个直接信任度为零的用户。因此用户间接信任度计算公式为:
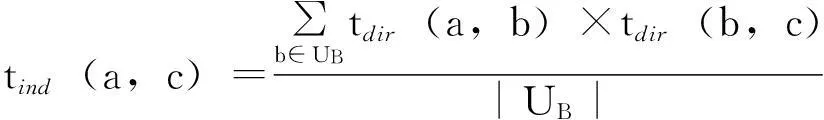
(5)
式中,UB={ui|tdir(a,ui)≠0且tdir(ui,c)≠0},即UB表示所有由用户ua节点到用户uc节点2步可达的用户集合。
3)用户综合信任度的计算用户ua对用户uc的综合信任度T(a,c)是综合了直接信任与间接信任,其计算公式如下:
T(a,c)=χtdir(a,c)+(1-χ)tind(a,c)
(6)
式中,χ表示直接信任的被重视程度,χ∈(0,1),取χ=0.8。
2基于社会网络的协同过滤推荐算法
由于人们通常更加倾向于接受好友或亲戚熟人的推荐,即使用户之间的兴趣偏好相似度较高的邻居用户,由于信任度的差异,最终的推荐结果也会有不同。融合用户偏好的相似度与用户间信任度对提升算法的推荐结果准确性具有重要意义。因此,笔者提出一种基于社会网络的协同过滤推荐算法,其推荐过程示意图如图3所示。
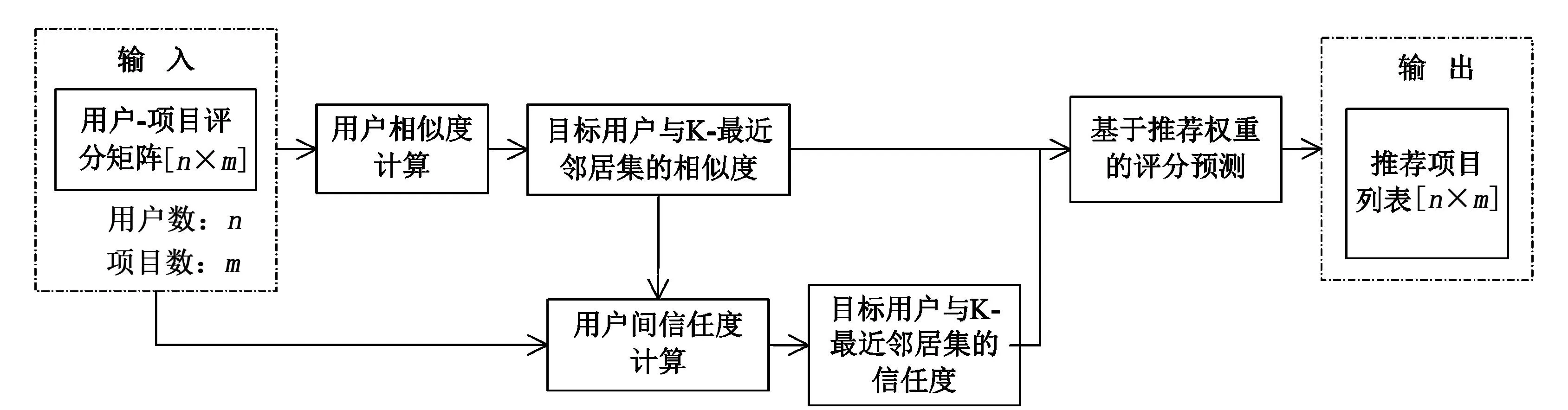
图3 社会网络中用户间接信任关系图
图3基于社会网络的推荐系统框架将引入推荐权重来综合用户偏好相似度及用户信任度,推荐权重计算方法如下:
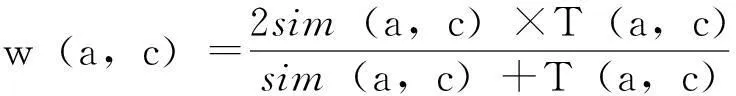
(7)
式中,w(a,c)表示用户uc与目标用户ua的推荐权重。
依据上述推荐权重w(a,c)的计算结果,选择权值最大的K个用户作为目标用户的最近邻居集UK。得出目标用户预测评分计算公式:

(8)

3算法描述及复杂度分析
3.1算法描述
输入:目标用户uT,用户-评分项目矩阵Rm×n,用户信任矩阵Tm×m,邻居数k;
输出:Top-N推荐结果。
推荐步骤如下:
Step1对每个用户u,找到同目标用户uT共同评分过的项目,将其记录在items中;
Step2依据用户评分矩阵Rm×n,使用式(1)计算用户评分间的相似度sim(a,b);
Step3由式(2)得出预测评分与真实评分之间的偏差值,然后由式(3)得出用户间的直接信任度;
Step4根据式(5)计算用户间的间接信任度,并通过式(6)计算用户间的集成信任度,并将其结果存入矩阵Tm×m中;
Step5融合用户相似度与信任度,由式(7)得出用户间的推荐权重;
Step6根据式(8)计算得出目标用户uT的所有项目的预测评分;
Step7为目标用户uT生成Top-N推荐。
3.2复杂度分析
根据算法描述,假设用户数为m,项目数为n,最近邻居数目为k,则:
1)Step1系统初始化阶段,遍历目标用户与其他用户间共同评分过的项目,因此其复杂度为O(n);
2)Step2由矩阵计算目标用户与其他用户之间的相似度,复杂度为O(m2);
3)Step3计算预测评分与真实评分之间的偏差大小,复杂度为O(n2);
4)Step4计算用户间的间接信任度,复杂度为O(m2);
5)Step5、Step6、Step7阶段为用户推荐阶段,主要的时间是在项目的排序上,因此复杂度最差为O(m2)。
虽然推荐计算量会随着用户评分数据和标签数据的增加而有所增加,但是相比较传统的协同过滤算法,新方法在提高推荐准确度的同时并没有增加算法的推荐时间,具有一定的可行性。
4试验结果与分析
4.1数据集及试验环境
采用来源于美国明尼达苏大学GroupLens研究小组提供的MovieLens站点100K公开数据集。其内容主要包括来自943个用户对1682部电影的大约100000个评价分数信息,每个注册用户均对其观看过得电影进行评价并给出评分值且都至少评价了20部电影;评分值在1到5之间;“1”表示“不喜欢”、“2”表示“不太喜欢”、“3”表示“一般喜欢”、“4”表示“比较喜欢”、“5”表示“非常喜欢”。试验过程中,整个数据集被随机分出20%当作试验的测试集,其余的80%当作试验的训练集。
笔者采用Java实现了基于社会网络的协同推荐方法,并设计了若干试验对该方法的推荐效率进行验证。试验环境为Intel Core i5处理器,CPU主频为2.5GHz,4G内存的PC机,Windows7操作系统,jdk版本为1.7。
4.2评价指标
考虑推荐算法优劣程度,可以由很多指标来评价。笔者通过系统的平均排序分、平均绝对误差2个指标验证算法的效率及其性能。
1)平均绝对误差(MAE)通过计算测试集中用户实际评分和利用推荐算法预测出来的评分间的绝对误差值来度量推荐系统的推荐准确度。当MAE的值越小,表明推荐结果的精度越高,反之,则越低[11]。
假设预测用户评价集记为{p1,p2,…,pN},而真实的用户评价集记为{q1,q2,…,qN},则平均绝对误差MAE的计算公式为:
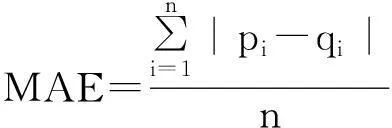
(9)
式中,n为被评分项目的数量;pi为系统预测评分值;qi为数据集中的真实评分值。
2)平均排序分通过计算项目在列表中位置度量系统推荐的精准性。其计算公式[12]如下:
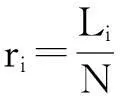
(10)
式中,N为未被评分的项目数;Li为i在推荐列表中的序号。
4.3结果分析
1)算法的准确率对比为了验证笔者提出算法在推荐结果精确度方面较其他类似算法具有的优势,把其与基于用户的协同推荐算法(CF-USER)、基于项目的协同推荐算法(CF-ITEM)及其他基于信任的推荐方法[2](CF-信任支持度)进行了对比,结果如图4所示。由图4可以看出,相同数量用户邻居集下,笔者提出算法的MAE值均低于其他几种算法,且当最近邻居数为40时,该算法推荐精度达到最优;继续增大邻居数量可以发现,该方法推荐精度逐渐地趋向于平稳。
2)算法的平均排序分对比各算法平均排序分试验结果如图5所示。由图5中可以发现,随着数据集中训练集占的比重逐渐增加,算法的平均排序分也慢慢地减小,笔者提出算法计算得出的平均排序分要低于另外3个算法。综上所述,该方法在推荐精度上要高于其他几个方法。

图4 推荐算法的MAE比较 图5 算法的平均排序分
5结语
推荐系统作为解决信息过载的一种有效手段,如何提高其推荐精度已成为非常重要的研究问题。在社会网络中考虑推荐信任对推荐准确性的提高具有重要的意义。但人们对推荐技术的满意度不仅仅体现在推荐结果的准确性上,下一步的主要工作是提出有效的算法来提高用户对推荐系统的满意度,包括推荐结果的覆盖率、多样性等等。
[参考文献]
[1]Massa P, Avesani P. Trust-Aware Collaborative Filtering for Recommender Systems[A].Proc of Federated Int Conference on the Move to Meaningful Internet: Coopis[C]. Springer Berlin Heidelberg, 2004:492~508.
[2]丛丽辉,王科,夏秀峰,等.利用信任支持度构建客户信任网络[J].计算机工程与应用,2012,48(6):110~113.
[3]朱丽中,徐秀娟,刘宇.基于项目和信任的协同过滤推荐算法[J].计算机工程,2013:39(1):58~66.
[4]Victor, Cornelis P, Cock C, et al. Trust-and Distrust-Based Recommendations for Controversial Reviews[J]. Intelligent Systems IEEE, 2011, 26(1):48~55.
[5]徐守坤,孙德超,李宁,等.一种结合语义Web和用户信任网络的协同过滤推荐模型[J].计算机应用研究,2014,31(6):1714~1718.
[6]施荣华,幸晶晶.一种基于群组的P2P网络信任管理模型[J].计算机应用研究,2010,27(7):2638~2640.
[7] 张富国. 基于社交网络的个性化推荐技术[J]. 小型微型计算机系统, 2014, 35(7):1470~1476.
[8]Bhuiyan T. A survey on the relationship between trust and interest similarity in online social networks[J].Journal of Emerging Technologies in Web Intelligence, 2010,2(4):291~299.
[9]黄创光,印鉴,汪静,等.不确定近邻的协同过滤推荐算法[J].计算机学报,2010,33(8):1369~1377.
[10]乔秀全,杨春,李晓峰,等.社交网络服务中一种基于用户上下文的信任度计算方法[J].计算机学报,2011,34(12):2403~2413.
[11] Zhou T, Jiang L L, Su R Q, et al. Effect of initial configuration on network-based recommendation[J]. Epl:europhysics Letters, 2008, 81(5):15~18.
[12]赵琴琴,鲁凯,王斌.SPCF:一种基于内存的传播史协同过滤推荐算法[J].计算机学报,2013,36(3):671~676.
[编辑]洪云飞
[引著格式]汪千松,蒋胜,王忠群.基于社会网络的协同推荐方法[J].长江大学学报(自科版),2015,12(16):29~33.
25 Design and Implementation of A Field Section Map Sketching System Based on ArcEngine Assistance
Li Gongquan,Gan Le,Wang Jing(YangtzeUniversity,Wuhan430100)
Abstract:Geological sectional map is a general geological map to present attitudes and distribution of rock strata.Rapid automatic mapping can meet the general requirement in practical application.The geography object and interface contained in ArcEngine component library can meet the requirement of geological section map.According to the production flow of field geological map, a new geological sectional map drawing system is designed based on ArcEngine, which is standardized, practical, easy for management and maintaining.The system adopts the single user system structure because a user occupies all the resources and different users can the exchange data by text files.The three main functions are considered including information inputting, section generating, and section filling.Through practical application,rock stratum map can be rapid built with topographical maps and collected data.It has higher practical value.
Key words:GIS; ArcEngine; geological sectional map
[作者简介]皇苏斌(1986-),男,硕士,助教,现主要从事数据挖掘,电子商务方面的教学与研究工作;E-mail:huangsubin2007@163.com。
[基金项目]安徽省高校省级科学研究项目(TSKJ2014B10);安徽工程大学青年基金项目(2013YQ30);安徽工程大学计算机应用技术重点实验室基金项目(JSJKF201504)。
[收稿日期]2015-02-18
[文献标志码]A
[文章编号]1673-1409(2015)16-0029-05
[中图分类号]TP391
猜你喜欢
环球时报(2018-01-23)2018-01-23 05:25:53
现代商贸工业(2016年11期)2016-12-26 14:48:07
软件导刊(2016年11期)2016-12-22 21:40:40
现代情报(2016年11期)2016-12-21 23:35:01
电脑知识与技术(2016年27期)2016-12-15 19:41:16
教育界·下旬(2016年8期)2016-12-14 10:51:08
旅游学刊(2016年9期)2016-12-06 19:53:55
电脑知识与技术(2016年26期)2016-11-24 18:12:54
商场现代化(2016年22期)2016-10-18 19:58:46
计算机工程(2015年4期)2015-07-05 08:27:45
