
基于离散GM模型和指数平滑模型组合的统计预测方法
2015-02-18 04:56陈有为
统计与决策 2015年10期
陈有为
(西安邮电大学 经济与管理学院,西安710121)
1 离散GM模型和指数平滑模型构建
1.1 离散GM(1,1)模型
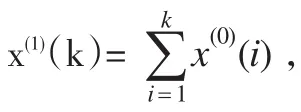
根据离散GM(1,1)模型的基本原理,设定含参数的拟合模型如下:
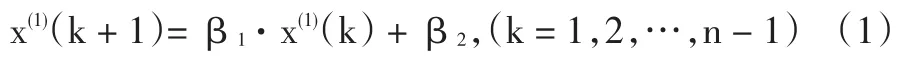
其中,参数β1和β2由最小二乘估计得到,计算方法为:

1.2 指数平滑模型
指数平滑模型是一种在数值加权平均的基础上进行预测的模型,其基本原理是:首先对原始数据进行平滑处理,然后根据处理后的新数值,经过估计参数进行模型拟合,再用该模型进行数值预测。一般而言,指数平滑模型中的加权系数根据几何级数递减,所有权数的和为1。指数平滑模型思路简单,计算方法通俗易懂,预测结果也相对较稳定,不仅适用于短期序列的预测,还适用于中期序列预测。本文采用三次指数平滑模型进行预测,其基本计算公式如下:

1.3 组合预测模型构建
灰色系统模型的一大优点在于不要求通过足够的数据建立模型,因此可以将原有数据序列的末端数据根据不同步长分别构建离散GM(1,1)模型,然后将所有的单项模型分别和指数平滑模型进行组合,再从中选择最佳组合模型,从而达到精确预测的效果。
现假设系统已经根据n个初始数据,构建了m个单项的GM(1,1)模型xi(0)(k)(其中,i=1,2,…,m;k=1,2,…,n),于是,根据这些单项模型,结合指数平滑模型,可构建组合预测模型如下:
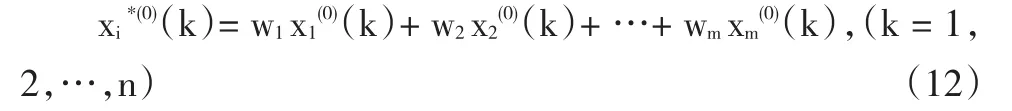
其中,w1,w2,…,wm为待定的组合加权系数,有w1+w2+…+wm=1。一般可以根据最大灰色关联系数的法则对组合加权系数进行确定。定义原始数据序列{x(0)(k)}与预测数据序列{xi*(0)(k)}的相关系数可进行如下计算:
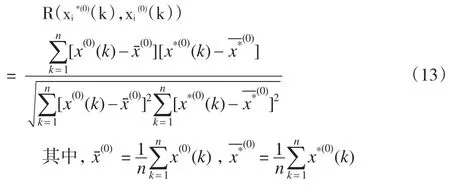
根据相关系数最大值的原则,可以解得式(12)中的权重系数wi(i=1,2,…,m)。这个问题归结为求式(13)的R(xi*(0)(k),xi(0)(k))的最大值,这是一个非线性最优解问题,可通过非线性规划求得。
在解得权重系数w*i(i=1,2,…,m)后,组合预测模型中的预测值xi*(0)(k)可表示为以下线性组合:
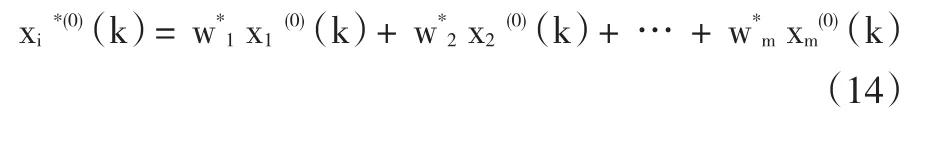
2 组合预测模型在实际统计领域中的运用
为了检验离散GM模型与指数平滑模型组合后的改进模型在实际统计运用中的有效性和预测精度,首先选取我国城镇居民家庭人均购买鲜菜量进行预测,时间跨度为1991~2012年。其中,城镇居民家庭人均购买鲜菜数量的统计数据如表1所示。
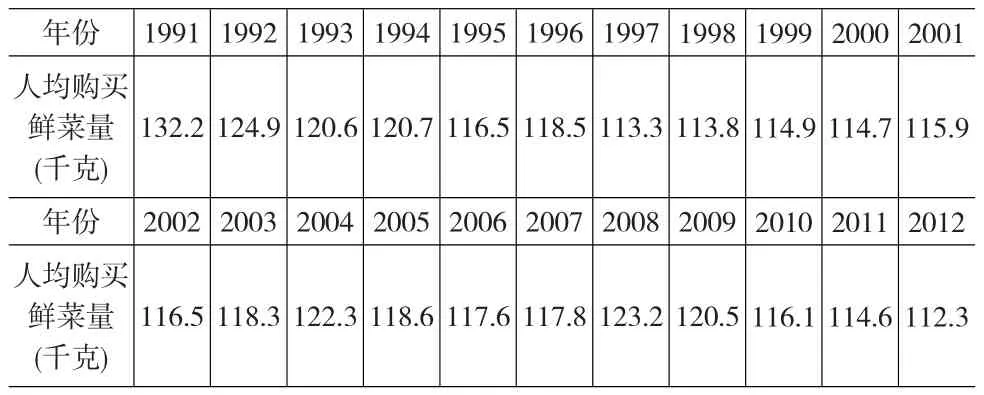
表1 1991~2012年我国城镇居民家庭人均购买鲜菜数量的统计数据
首先,根据城镇居民家庭人均购买鲜菜数量的原始数据,构建三次指数平滑模型。这里,首先需对加权系数λ进行确定。根据最小二乘原则,选定初始值 S0(1)=S0(2)=S0(3)=125.9,确定加权系数λ的值为 0.65。于是,可根据式(6)~式(11),计算得到:

根据以上的三次平滑预测模型,可以计算2003~2012年我国城镇居民家庭人均购买鲜菜数量的拟合值,结果如表2所示。
然后,根据城镇居民家庭人均购买鲜菜数量的原始数据,构建离散GM(1,1)模型。由前面的分析,这里分别根据2002~2012年的数据序列、2003~2012年的数据序列、2004~2012年的数据序列和2005~2012年的数据序列,构建4个离散GM(1,1)模型,然后分别将这四个离散GM(1,1)模型与三次指数平滑模型进行组合,并根据相关系数值最大的规则选择最优组合预测模型。
计算可得,通过2003~2012年的数据序列建立的组合预测模型的相关系数达到0.762,是四个组合预测模型中最高的,因此利用2003~2012年数据序列建立的离散GM(1,1)模型最为合理。参考式(2)和式(3),并借鉴王丰效(2011)等人的方法,采用最小二乘法对离散GM(1,1)模型的参数进行估计,结果为:

根据该递推公式,便可得到2003年至2012年我国城镇居民家庭人均购买鲜菜量的GM(1,1)拟合值,结果仍如表2所示。
根据以上三次指数平滑预测模型和离散GM(1,1)预测模型,可构建组合预测模型。根据式(13),并采用一定的计算处理,可得到三次指数平滑预测模型和离散GM(1,1)预测模型的权重系数分别为:

于是,通过加权可得到组合预测模型下我国2003年至2012年城镇居民家庭人均购买鲜菜量的预测值,结果仍由表2给出。
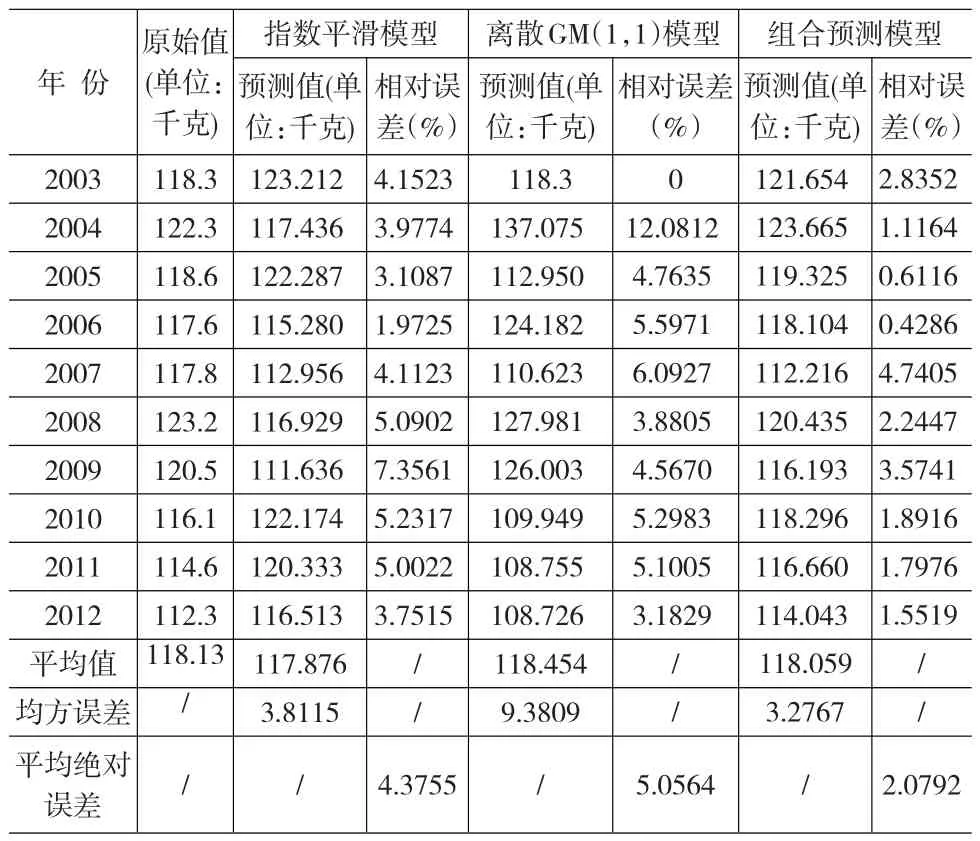
表2 三种预测模型的我国城镇居民家庭人均购买鲜菜量预测值
对比表2中三种预测方法得到的结果可知,由离散GM(1,1)模型与指数平滑模型的组合模型预测结果的均方误差低于两种单项预测方法。组合模型预测结果的均方误差仅为3.2767,而离散GM(1,1)方法预测结果的均方误差高达9.3809。从历年我国城镇居民人均蔬菜购买量的预测误差来看,组合预测方法得到的各年预测误差普遍低于另外两种单项预测方法,计算可得,组合预测方法得到的平均绝对误差值为2.0792,三次指数平滑模型得到的平均绝对误差值为4.3755,离散GM(1,1)模型得到的平均绝对误差值为5.0564。
由图1可清晰地看出,组合预测模型对我国城镇居民人均蔬菜购买量的预测值最接近原始值,而离散GM(1,1)的预测波动性最高。由此可见,组合预测模型的预测精度要高于三次指数平滑模型和离散GM(1,1)模型。

图1 三种预测模型对我国城镇居民家庭人均购买鲜菜量预测结果的比较(单位:千克)
3 结论
由于指数平滑预测模型对样本数据的条件要求较高,特别是需要大量的时间序列,而离散GM(1,1)预测模型虽然不要求提供大量的原始数据,但在实际过程中对离散的数据预测效果并不是很好,为此本文通过加权方法,设计了一种由三次指数平滑预测模型和离散GM(1,1)预测模型组合的预测模型,并选取了我国城镇居民家庭人均购买鲜菜量的实例进行预测和比较。由实证结果可知,由组合预测模型得到的预测结果在预测精度上优于三次指数平滑预测模型和离散GM(1,1)预测模型,因此这种组合预测模型可能比单项的预测模型更具有可行性。
[1]Tang H W V,Yin M S.Forecasting Performance of Grey Prediction for Education Expenditure and school Enrollment[J].Economics of Education Review,2012,31,(4).
[2]Bonsdorff H.A comparison of the orDinary and a Varying Parameter Exponential Smoothing[J].Journal of Applied Probability,1989,(27).
[3]Chang,S C Wu J Lee C T.A Study on the Characteristics of Grey Prediction[R].Proc.of the 4th Conference on Grey Theory and Applications,1999.
[4]Su Z B,An J L.Application of Grey Metabolic GM(1.1)Model in Prediction of per Capita Net Income of Rural Residents[J].Journal of Xi.an University of Arts&Science(Nat Sci Ed),2009,12(4).
[5]王丰效.改进的GM(1,1)幂模型及其参数优化[J].纯粹数学与应用数学,2011,27(6).
[6]陈露,张凌霜.基于初值修正的组合灰色Verhulst模型[J].数学的实践与认识,2010,40(11).
猜你喜欢
社会科学战线(2022年7期)2022-08-26
福建轻纺(2022年4期)2022-06-01
中学生数理化·七年级数学人教版(2018年11期)2019-01-31
娃娃乐园·综合智能(2018年23期)2018-12-26
娃娃乐园·综合智能(2018年3期)2018-03-22
领导决策信息(2017年9期)2017-05-04
中国照明(2016年6期)2016-06-15
哈尔滨体育学院学报(2014年6期)2014-03-11
