
基于HEVC视频编码标准的并行解码策略研究
2015-01-06 08:12:24刘争艳李劲禾
阜阳师范大学学报(自然科学版) 2015年1期
刘争艳,李劲禾,李 絮
(阜阳师范学院计算机与信息工程学院,安徽阜阳 236037)
基于HEVC视频编码标准的并行解码策略研究
刘争艳,李劲禾,李 絮
(阜阳师范学院计算机与信息工程学院,安徽阜阳 236037)
将并行化策略引入到新一代HEVC视频编码的标准中,提出一种在解码阶段的熵片中应用并行策略的算法。通过将每行最大编码单元(LCU)作为一个熵片来编码视频,以波阵面并行的方式解码多行LCU。算法在配置为12 Intel Xeon Cores、3.3 GHz的PC机上进行了评估测试。其结果显示,在视频分辨率为1 920×1 080 p(53.1 fps)和2 560×1 600 (29.5 fps)引入并行化策略后的执行速度与采用顺序执行时的执行速度相比较有了显著的提高,并且能够达到很好的实时性效果。
视频编解码;HEVC;并行处理;高清视频
随着终端处理能力以及人们对多媒体数据体验的要求越来越高,4K视频、3D蓝光、高清电视等已经逐渐成为视频应用的主流趋势。而现有的H.264/AVC编码标准的压缩效率针对高清、超高清视频的应用需求已显得力不从心。因此,国际电联组织(ITU-T)和移动视频专家组(MPEG)成立了视频编码联合小组(Joint Collaborative Team on Video Coding,JCT-VC)[1],已经研究并制定新一代视频压缩标 准 HEVC(HighEfficientVideoCoding,HEVC)。该标准已于2013年1月26日发布并正式成为国际标准,并且JCT-VC小组已把相关技术集成到一个软件代码库中,形成该标准的测试平台HM。HEVC标准的提出主要面向高清电视(HDTV)以及视频捕获系统的应用,提供从QVGA至1 080 p以至超高清电视(7 680×4 320)不同级别的视频应用。其核心目标在于:在H.264/AVC High Profile的基础上,压缩效率提高1倍,即在保证相同视频图像质量的前提下,视频流的码率减少50%[2-3]。HEVC同样采用预测加变换的混合编码结构,然而HEVC的编码结构更为灵活。其中,将编码单元(CU)作为编码的基本单元,类似于H.264的宏块;将预测单元(PU)作为预测的基本单元,是在CU基础上进一步分割得到;将转换单元(TU)作为变换的基本单元,更能适合不同图像的内容[3-5]。本文针对HEVC标准的特点,在视频解码阶段引入并行化策略以实现支持实时高清和近实时的4k标准画面的PC平台。
1 HEVC
HEVC标准继续采用之前H.264/AVC标准的混合编码框架结构[6-9]。其技术框架仍然基于以块为单元的预测加变换的混合编码框架。在此混合编码结构下,HEVC在对编解码时每个编码阶段都进行了大量的技术创新,其中包括多角度帧内预测,运动估计融合,基于大尺寸四叉树块的分割结构,高精度运动补偿,自适应环路滤波以及基于语意的熵编码技术[8]。图1描述了HEVC的基本框架。
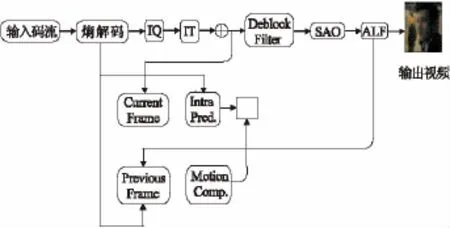
图1 HEVC解码器的基本框架
相对于H.264/AVC标准来说,HEVC标准与其存在一个重要的差异就是帧编码结构不同。在HEVC中定义了一套新的图像划分语法单元,主要包括编码单元(Coding Unit,CU)、预测单元(Prediction Unit,PU)和变换单元(Transform Unit,TU)。CU类似于H.264/AVC中的宏块或子宏块,但又略有不同。在H.264/AVC标准中,一个编码单元的尺寸是从8×8至16×16,而在HEVC中规定了一个CU的尺寸范围可以从8×8到64×64。从而可以为高清视频图像的有效表示提供有力支持。此外,为了更方便地表示CU,还定义了最大编码单元(Largest coding unit,LCU)和最小编码单元(Smallest coding unit,SCU)。LCU是一帧图像划分过程中的基本单位,而一个CU可以从其最大编码单元的尺寸开始,按照四叉树的形式被不断分割为更小的CU,直到达到最小编码单元,其间分割的次数称为深度。这样可以利用LCU尺寸和分割深度值来表征一个CU的尺寸。为了降低重构帧和原始帧像素之间的失真,HEVC技术标准中新增加了两类新的滤波器:一类是自适应环路滤波器(A-daptive Loop Filter,ALF)、一类是自适应样本偏置(Sample Adaptive Offset,SAO)。SAO是以图像按四叉树分割之后的亚区域为单元,对每个亚区域经去块滤波后的重构像素进行自适应补偿,以进一步减少失真。ALF是对SAO处理过的重构像素进行滤波。这两类滤波器的使用,进一步提升了重构帧的质量。
2 并行策略应用可能性分析
2.1 片与块级并行性分析
在以往的视频编码器H.264/AVC中,并行策略是基于片级或块级之上的。在基于片级并行策略中,一帧被分成彼此独立的几个片。然后利用多个线程来并行处理独立的片,利用这种方法可以达到在提高吞吐量的同时减少帧延迟的目的。然而,若将一帧划分为多个片必然会引起编码效率的显著降低。原因是如下:首先,这种方法破坏了上下文模型的训练,无法跨越片的边界来进行上下文的选择。因此,熵编码效率并不高。其次,在预测阶段,不能很好的利用相邻片像素来进行预测。最后,对于每片还需要在比特流中存在一个额外的片头起始码。
此外,在块级中实现并行性是不依赖于帧中的多个片,也没有相关的编码损失。在帧内编码块中,如H.264/AVC中的宏块和HEVC中的最大编码单元LCU是通过使用波阵面方法来满足预测和滤波的需求,以此在并行中得到重建帧。但是,在熵解码过程中不能在块级层面进行并行化处理,必须在整个帧中按顺序执行。然而,对于多个帧来说可以并行进行熵解码。但是,这种并行方法需要帧缓冲来保持熵解码的语法元素,并且只能通过减少帧重建和滤波阶段的帧延迟来实现。
2.2 熵片
HEVC引入了一种新的编码工具即熵片。熵片不同于常规的片,其本身已被设计为并行执行以取代错误恢复。在熵片和普通片中,每一个片开始时执行包括上下文模型变量和解码引擎的初始化。其主要区别在于重建和滤波阶段,在HEVC中使用熵片允许跨越片界使用相邻块中的数据。熵片的片头数据要小于常规片头数据,因为在HEVC中仅仅发送视频一帧中的第一片的头部数据信息。
目前,熵片仅仅被看作熵解码阶段的一种并行性工具。有了熵片,多个线程可以利用块的并行性来熵解码同一帧,这样有利于降低帧延迟。但是,熵解码阶段是脱离帧重建和滤波阶段,所以一个大的帧缓冲仍需要存储熵解码中的数据。本文使用的方法中,在不降低并行性和编码效率的前提下,帧缓冲是不需要将熵解码与帧重建和滤波阶段结合的。
3 熵片并行解码
把熵解码与重建和过滤阶段连接一起,熵解码依赖性必须符合重建和过滤阶段的依赖性。HEVC中的重建和过滤阶段展示的波阵面的依赖性与其在H.264/AVC中所展示的相同,仅仅是编码块大小不同。波阵面依赖性把并行性限制到每排一块。目前,根据LCU的固定数量或字节大小,可任意选择每个帧内熵片数量。这会导致不规则片状与波阵面依赖性并不匹配。相反,要想匹配波阵面依赖性,必须要强制采用每行一个熵片的编码方法。对分辨率为2 560×1 600和1 920×1080的视频来说,使用每行一个熵片,亮度分量的BD率[2]损失率分别是5.4%和6.3%。使用每行一个熵片的编码方法,使得LCU行之间的上下文传播以波阵面方式出现,但在HM基础代码中不会出现。实验仿真结果显示,使用相同上下文传播时,同样分辨率下的BD率的损失可以降到1.7%和1.3%。
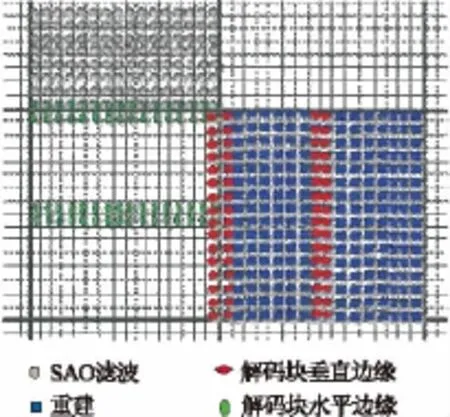
图2 解码顺序以及相应的修改后的LCU像素(每个正方形代表4×4像素块)
在本文的方法中,HEVC解码器可以通过给每行LCU分配一个线程来达到并行。在每一个称之为线解码器中,逐一处理每一行中的LCU。熵解码、重建、垂直边缘解块滤波器可以在当前LCU中执行。在HM3.0中,水平边缘解块必须超过垂直边缘的解块,因此,必须存在一个LCU延迟。反过来,在解码输出图像上操作时,也延迟了SAO滤波器,以至于只有右边较低边缘被解码时才能操作。SAO过滤器要在左上方LCU上操作,其能使用所有解码后的图像数据。此阶段解码顺序以及相应的一个修改后的LCU像素见图2。
为了保证波阵面的依赖性,利用环线策略使线性解码进程得到同步。使用环线策略,任意数量的线程都能够以线路交叉方式应用于图片解码中。应用环同步方法,能够维持波阵面的依赖性。图3显示了使用4个解码线程时波阵面的进程。
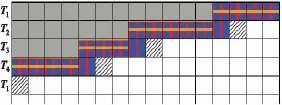
图3 使用4个解码线程时波阵面的进程
ALF是在编解码环路内,位于Deblock和SAO之后,用于恢复重建图像以达到重建图像与原始图像之间的均方差(MSE)最小。它是在独立的通道为整个图片执行操作。在ALF中的LCU独立,可以并行处理每个块。在我们的操作中,为了减少高速缓存线冲突和同步开销,将8个连续的LCU分在一个单元组,由一个独立核来处理。
4 实验结果
4.1 实验配置
在HM3.0参考译码器[1]上,我们验证并行HEVC解码器。针对当前HEVC标准中最为苛刻的应用场景的要求,选择了高效的随机存取“配置文件”。表1显示了 JCT-VC主要的编码参数。HEVC测试序列中所有视频,使用HM 3.0参考编码器的参数。由于空间原因,以及主要是对高分辨率的应用程序感兴趣,将结果按照A类(2 560×1 600)、B类(1 920×1 080)和S类(3 840×2 160)的顺序呈现。在并行解码实验中,本文使用了基于Intel Xeon X5680的处理器。编码参数配置如表1,主要的硬件和系统参数设置如表2。
4.2 加速测试
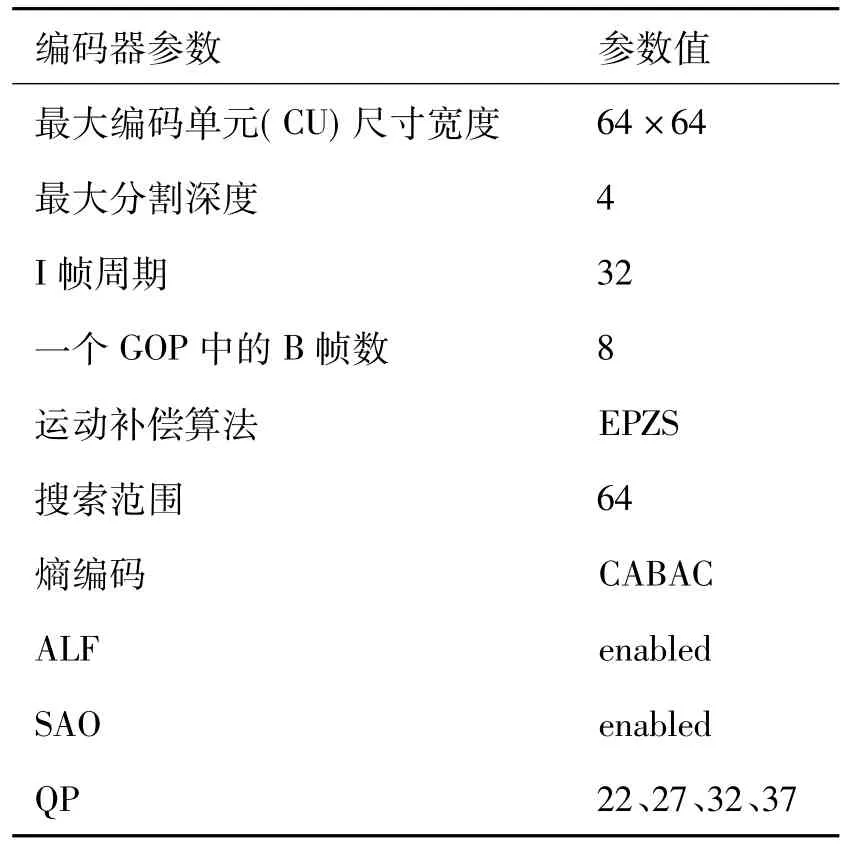
表1 编码参数设置
图4显示了所研究的3个顺序级别下的平均加速度。平均加速度代表着各个顺序在4种不同QP值下各执行5次后的平均加速度。各个顺序的加速度最多偏离平均值的6%。加速曲线显示,核心数在4核的时候,并行效率可以达到82%,可以获得相对较高的效率。而当核心数达到12核的时候,并行效率下降到53%。另外,分辨率越高,加速度就越大。
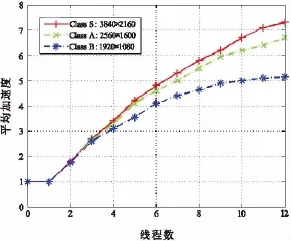
图4 三类顺序级别下的平均加速度

表2 实验硬软件系统设置
4.3 执行配置文件和性能分析
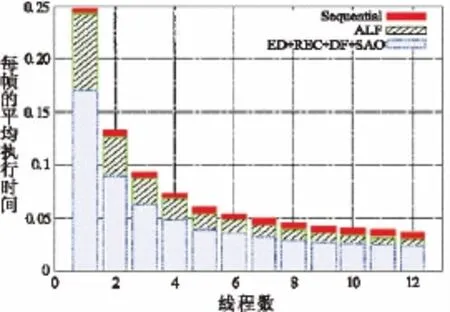
图5 A类序列的执行时间分析
图5显示了顺序执行、波阵面部分(熵解码(ED)、重构(REC)、去块滤波(DF)、SAO以及ALF的平均执行时间。从图中可以看出对于十二核来说,整个执行时间分别是19%、63%和18%。由于其大规模并行特点,ALF部分随着线程数量的增加呈直线减少。而波阵面部分也会下降,但最终趋于饱和。对于顺序部分,主要由字节流解析和头部解码组成,其数保持不变。但是根据阿姆达尔定律可知,这将会带来整体执行时间的增加。
5 结束语
本文提出了并行化策略在新一代视频编码标准HEVC中的应用,并对其进行评估。所提的策略中具有几个理想化的特性。首先,它在多核处理器上实现了良好的扩展效果。其次,可以根据硬件的处理能力和性能要求来选择线性解码器的数量。第三,使用多核增加了吞吐量的同时降低了帧延迟,这样既能适应低延迟又能适应高吞吐量的应用场景。
[1]Itu T.Joint collaborative team on video coding[EB/ OL].(2011-07-20)[2015-01-06].http://www.itu.int/en/ITU-T/studygroups/com16/video/Pages/jctvc.aspx.
[2]蔡晓霞,崔岩松,邓中亮,等.下一代视频编码标准关键技术[J].电视技术,2012,36(2):80-84.
[3]Sullivan G J,Ohm J,Han W,et al.Overview of the high efficiency video coding(HEVC)standard[J].Circuits and Systems for Video Technology,IEEE Transactions on,2012,22(12):1649-1668.
[4]雷海军,杨忠旺,陈 骁,等.一种快速HEVC编码单元决策算法[J].计算机工程,2014,40(3):270-273.
[5]Wiegand T,Ohm J R,Sullivan G J,et al.Special section on the joint call for proposals on high efficiency video coding(HEVC)standardization[J].Circuits and Systems for Video Technology,IEEE Transactions on,2010,20(12):1661-1666.
[6]夏 龄,舒 涛.一种H.264/AVC视频编码并行算法[J].计算机工程,2013,39(4):314-317.
[7]朱秀昌,李 欣,陈 杰.新一代视频编码标准——HEVC[J].南京邮电大学学报(自然科学版),2013,33(3):1-11.
[8]夏 龄,舒 涛.一种H.264/AVC视频编码并行算法[J].计算机工程,2013,39(4):314-317.
[9]刘争艳,李 絮,陈 蕴.基于二维映射关系的视频信息隐藏算法[J].计算机工程,2010,36(22):225-227.
Research on parallel decoding strategy based on HEVC video coding standard
LIU Zheng-yan,LI Jin-he,LI Xu
(School of Computer and Information Engineering,Fuyang Teachers College,Fuyang Anhui236041,China)
The parallel strategy is introduced to a new generation of HEVC video coding standard.A decoding stage used in the entropy in the parallel strategy algorithm is proposed.The maximum per line coding unit(LCU)as entropy to video coding,the wave front parallel manner decode multi line LCU.Tests carried out to evaluate the algorithm in the configuration for the PC Intel 12 Xeon cores,3.3 GHz,The results show that the execution speed in video resolution is 1 920×1 080 p(53.1 fps),and 2 560× 1 600(29.5 fps)after the introduction of the parallel strategy execution speed when compared with the sequential execution has been significantly improved,and can achieve real-time effect.
video codec;HEVC;parallel processing;HD video
TP311.52
:A
:1004-4329(2015)01-054-04
2014-05-20
安徽省教育厅自然科学基金项目(KJ2013Z259);阜阳师范学院自然科学基金项目(2013FSKJ02ZD,2014FSKJ09);大学生创新创业训练计划项目(FS201310371115);全国统计科学研究重点项目(2014LZ32)资助。
刘争艳(1981-),男,硕士,讲师。研究方向:视频编码与图像处理。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
医学信息学杂志(2020年12期)2020-02-21 07:15:12
中国外汇(2019年19期)2019-11-26 00:57:32
计算机与网络(2019年18期)2019-09-10 19:20:47
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
电脑知识与技术(2018年4期)2018-03-19 16:55:18
环球市场(2017年36期)2017-03-09 15:48:21
铁路技术创新(2015年3期)2015-12-21 12:55:46
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
