
一种面向不均衡网络流的综合抽样方法*
2015-01-04 12:02李景富杨志强
火力与指挥控制 2015年12期
李景富,杨志强
(黄淮学院,河南驻马店463000)
一种面向不均衡网络流的综合抽样方法*
李景富,杨志强
(黄淮学院,河南驻马店463000)
针对互联网流量中短流数量多但承载信息少、长流数量少但承载报文数多的特点,提出了一种面向不均衡网络流的综合抽样IS(Integrated Sampling)方法。IS方法首先采用容量固定的高速缓存实现有限时间窗口内报文的实时归并,在此基础上,IS方法采用可部分重构的哈希函数实现单报文流聚类,采用流长和时间组合赋权的权值更新模块和频繁项模块共同实现频繁项流的抽取,对于网络中的其他流量,IS方法通过多个蓄水池模块实现蓄水池分段抽样。实验证明,相对于单一的抽样方法,IS方法在相同缓存下能够抽取出更为丰富地网络流信息,算法能够实时应用于高速网络中。
网络流,流抽样,哈希聚类,频繁项提取,蓄水池抽样
0 引言
随着大数据时代的到来,互联网中产生的流量数据规模急剧增长,在同一时刻一条骨干链路中就可能活跃着数百万条流,如此巨大的数据量给网络流量采集、传输、存储、分析及管理带来了巨大的压力[1-5],流量抽样通过一定的方式从整体流量数据空间中抽取出特定样本,是一种以有限样本数据获得总体数据认识的有效方法,网络流量抽样作为一种以有限资源获取网络行为统计信息的方式引起了广泛地关注[6-9]。
由于网络流分布不均衡,网络流长处于两端的流其特性严重偏离均值[10-11]:①网络流长大的流在总体流数中所占比例极小,采用均匀流抽样方法将遗漏掉大部分的大流,但是该部分流承载的报文数中所占比例极大,对大流进行监控只需很少的流缓存就能掌握网络流量的总体特性,因此,在能够有效识别大流的基础上应当尽量采集网络中全部的大流;②网络流长小的流在总体流数中所占比例极高,采用均匀流抽样方法将抽取到过多的小流,同时小流携带的有效信息有限,将大部分的流缓存用于保存小流是不值得的,为了降低小流占用的缓存数量,在保证实时性的情况下可以通过聚类小流实现小流宏观信息的保存。
基于此,本文提出了一种面向不均衡网络流的综合抽样方法(Integrated Sampling,IS)。该方法能够抽取出更为丰富的流信息,算法能够实时应用于高速网络中。
1 网络流综合抽样方法设计
本文的设计目标是以有限的缓存实时抽取尽可能多的流量信息,与之相对应的流量抽样方法是全流抽样方法。然而目前全流抽样中研究的多是抽取IP流中部分报文组成不完整的IP流,并调整不同流的抽样概率确保流相对标准差恒定。此种情况下全流抽样方法抽取的IP流的流量特征具有较大地偏差,在整体抽样率较低时使用这些不完整的IP流进行流量分类等应用时会引起较大的误差。因此,比较理想的抽样方法是先将网络报文归并成流,然后针对归并好的IP流进行抽样获取相对完整的网络流。
考虑到IP流归并的时间和空间复杂度,传统的NetFlow组流方式不能够实时应用于高速骨干链路,于是本文通过最近最少使用LRU(Least Recently Used)方式在线归并有限时间内的网络报文,然后根据归并的有限时间内的流量信息指导流抽样,整个综合抽样IS方法的原理如图1所示。
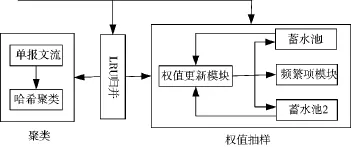
图1 IS算法基本原理
系统由LRU归并模块、聚类模块和权值抽样模块3部分组成。LRU归并模块以最近最久未使用LRU方式归并新到的网络报文,聚类模块通过哈希方式聚类LRU归并模块中淘汰出的单报文流,权值抽样模块根据不同的流长实现权值抽样。对于流长超过阈值的流,权值抽样模块尽量全部保存;对于不同流长的流,权值抽样模块设置不同的蓄水池实现分段抽样。
同时为了提高LRU报文归并的准确性,对于当前保存在权值抽样模块中的IP流,若其有新报文到来,直接令该报文进入权值抽样模块进行更新,而对于LRU归并模块中流长超过阈值的流,直接将其从LRU归并模块中移至频繁项模块中。这样权值抽样模块中将保存大量流长较大的IP流,这些IP流将承担网络流中大部分的报文负载,从而使得进入LRU归并模块中的报文数量大为减少。该操作等同于增加了报文归并的时间窗口长度,能够提高LRU报文归并的准确性。
1.1 单报文流聚类方法
由于高速骨干网络中单报文流在流总数中占有较高的比率,且单报文流通常情况下对应于网络中的异常流量,单个单报文流并不承载有用信息,直接存储网络中的全部单报文流会导致耗费大量的内存空间保存一些价值不高的信息,此种做法是不值得的。通过聚类将具有相似特性的单报文流归并到一起,不仅减少了内存使用量,而且聚类后的流量能够清晰地刻画出单个单报文流无法描述的异常特征,如网络中的“多对一”、“一对多”等特性必须通过聚类才能体现出来。因此,对单报文流进行聚类是十分必要的。
哈希函数能够将较长的字串映射成短字串,通过哈希函数能够很容易地实现多个五元组字符串的聚类,但哈希函数的可逆性差。为了直接反映原始五元组的信息,本文采用文献[12]中构建的带哈希增强算法的Bloom Filter Reproduction(BFR)方法实现哈希聚类。BFR方法的原理是通过8个哈希函数将96 bit的源/目的地址、源/目的端口长字串按照比特划分为8个16 bit的段。为了确保从所划分段中还原出原字串的精度较高,BFR采用划分段比特位部分重叠的方法,同时为了降低哈希冲突带来的干扰,BFR为所划分的8个段设置8个相互独立的存储空间。令Tuple={(a.b.c.d),(e),(f.g.h.i),(j)}分别表示单报文流的源地址、源端口、目的地址、目的端口,则BFR使用的哈希函数为:

BFR方法可以在实时的情况下实现单报文流的聚类,同时由文献[12]可知:若长字串Tuple是活跃的,则BFR映射后的短字串一定是活跃的;若BFR映射后的短字串部分是活跃的,则短字串可以反映单报文流的聚类特征。通过BFR方法聚类单报文流能够以较少的资源占用和较高的准确率揭示网络流量中混杂的多种异常现象。
1.2 权值抽样策略
由于网络流量分布极其不均衡,常用的抽样方法很难兼顾到各种流量的特点。基于此,本文采用基于流长的权重抽样策略实现网络流采样。①由于网络流中的频繁项主导着网络的行为,且频繁项流均包含着大量网络报文,从流量缩减的效果看,采集频繁项流的缩减效果要远远优于采集短流的缩减效果,在内存允许的情况下抽取网络中全部的频繁项是值得的,因此,有必要设置频繁项缓存模块抽取网络流中的全部频繁项;②由于未达到频繁项阈值的不同流长的流出现的频率存在较大的差异,为了使得抽取到的流更具有代表性,本文对于未达到频繁项阈值的流采用分段抽样的策略,对于流长频率高的流,抽样概率相对低一些,流长频率低的流,抽样概率相对高一些;③由于LRU归并模块采用的是基于时间的更新方式,不管网络流的流长多大,只要该流一段时间内无报文到来,在LRU缓存被占满时,该流将被淘汰。LRU归并模块对流长的重视程度不够,因此,权值抽样模块中设置了权值更新缓存模块用于更好地归并网络流,权值更新模块通过流长和时间计算网络流的权值,并且权值更新模块每次淘汰的均是权值最小的流。
权值抽样策略的原理如图1中权值抽样模块所示,权值抽样方法的步骤为:
(1)若新到报文Xi命中频繁项模块中流Ffr,则流Ffr的流长加1;若新到报文Xi命中蓄水池抽样模块中流Fre,则流Fre的流长加1,从蓄水池中删除流Fre并将该流加入到权值更新模块中;若新到报文Xi命中权值更新模块中流Fhit,按照1.2.1节的权值更新策略完成权值更新并判断Fhit流长是否达到阀值T0,若Fhit流长达到T0,则将流Fhit放入到频繁项模块中。
(2)对于从LRU归并模块或蓄水池抽样模块中进入权值更新模块中的流Fin,按照式(2)计算权值并将该流插入到权值更新模块中,若权值更新模块被占满,则删除权值更新模块中权值最小的流Flrast,进入步骤(3)。
(3)若Flrast流长在[2,L1)区间,则采用蓄水池1进行抽样;若Flrast流长在[L1,T0)区间,则采用蓄水池2进行抽样。
1.2.1 权值更新策略
根据数据流的特点,流的流长越大,该流的权值越大,同时流的时间越新,该流在最近一段时间内有报文到来的可能性越大,因此,流的权值与流长及流中最近一个报文到达时间密切相关。令权值更新模块中流F表示为〈ID,f,weight〉,其中ID表示五元组,f表示流F的流长,weight表示权值,令进入权值更新模块中的新流Fin为〈IDin,fin,iin〉,其中iin是流Fin中最近一个报文在整体网络报文中的序号,则流Fin的权值weightin为:
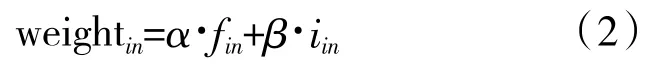
对于权值更新模块中流Fhit=〈IDhit,fhit,weighthit〉,若该流有报文Xi=〈IDhit,i〉到达,其中i是报文Xi的序号,则Fhit流更新后的流长和权重为fhit=fhit+1,weightin=α·fin+β·i。
当有新流到来且权值更新模块被占满时,删除权值更新模块中权值最小的流项F,并依据流F的流长选择蓄水池模块实现抽样;而当权值更新模块中存在流长达到T0的流F时,从权值更新模块中删除流F并将流F插入到频繁项模块中。
1.2.2 蓄水池抽样
在网络流抽样中,网络流的总数事先是未知的,且测量缓冲区的容量有限,此时的问题是如何在总数未知的流中抽取固定数量的流放入测量缓冲区中。蓄水池抽样方法是在样本总数未知的情况下,以相同概率抽取固定数量样本的一种方法,蓄水池抽样方法十分适合于流数未知的网络流抽样。蓄水池抽样的基本原理是:对于容量为n的测量缓冲区,先到达的n个流全部放入测量缓冲区,当第t(t>n)个流到达时,该流以n/t成为候选样本并随机替换掉缓冲区中的一个样本。由于不同流长的流出现的频率具有差异,为了使得抽取到的流更具有代表性,本文设置2个相同容量的蓄水池实现抽样。对于流长在[2,L1)范围内的流,采用蓄水池1实现抽样;对于流长在[L1,T0)范围内的流,采用蓄水池2实现抽样。而对于需要更精确地区分抽样流长的场合,可以通过设置更多个较小的蓄水池实现多蓄水池分段抽样。
1.3 IS算法描述
IS算法的具体步骤描述如下:
(1)对于到达的每个报文X,提取报文X对应的五元组IDX,查看五元组IDX对应的流FX是否位于权值抽样模块中,若FX位于权值抽样模块中,按照1.2节的策略更新权值抽样模块;否则,进入步骤(2);
(2)查看流FX是否位于LRU归并模块中,若FX位于LRU归并模块中,则流FX的流长fX=fX+1,进入步骤(3);否则,进入步骤(4);
(3)判断流长fX是否达到频繁项阈值T0,若流长fX达到频繁项阈值T0,从LRU归并模块中删除流FX,将流FX加入到频繁项模块中;否则,将流FX插入到LRU归并模块链表首部;
(4)将流FX插入到LRU链表首部,判断LRU链表是否被占满,若链表已满,删除LRU链表尾部流Ftail,进入步骤(5);
(5)判断流Ftail的流长ftail,若Ftail==1,进入步骤(6),否则,将流Ftail移除到权值抽样模块中,按照
1.2 节的策略更新权值抽样模块;
(6)计算流Ftail对应的哈希值,按照1.1节的单报文流聚类策略完成哈希聚类。
1.4 算法复杂度考虑
本文提出的综合流量抽样方法若采用哈希方式或CAM(Content Addressable Memory)查找报文地址,寻址时间复杂度为O(1),LRU归并模块采用双向链表实现,其时间复杂度为O(1),哈希聚类中哈希运算的时间复杂度为O(1),权值抽样模块中权值更新、蓄水池抽样及频繁项更新操作对每个报文仅需处理1个~2个表项,时间复杂度为O(1),因此,IS算法每报文时间复杂度约为O(1)。
在将网络报文归并成流的过程中,LRU归并模块的表项数越多,网络流的归并效果越好。考虑到实际情况下高速SRAM的容量是有效的,且IS算法只是归并有限时间内的网络报文,其本身并不要求归并后的网络流十分精确,因此,这里为LRU归并模块分配10 000个表项,每个表项需保存五元组、指针、流长等流特征,为其分配32个字节;为权值更新模块、蓄水池1、蓄水池2各分配1 000个表项,每个表项32个字节;为频繁项模块分配1 500个表项,每个表项32个字节;为单报文流聚类模块分配8个数组,每个数组共有个元素,每个元素占用2个字节。则系统总共占用缓存接近1.5 M字节,而目前的半导体技术完全能够提供此容量大小的SRAM缓存。因此,IS算法能够在线用于网络流量采集。
2 实验与评价
本文实验数据集选为CAIDA(Cooperative Association for Internet Data Analysis)2003年提供的一条OC48链路的流量,提取该数据集的前5 000 000个报文,记为trace_2003,将trace_2003分成5组,每1 000 000个报文为一组,按照五元组方式组流。表1显示了trace_2003中5组报文数据的流数分布情况,可以看出,trace_2003中流长分布极其不均衡。以第1组报文为例,该数据分组共包含86 817条IP流,单报文流数量占到总流数量的39.58%,流长在16以下的流占到总流数的90.76%;流长在99以上的流只有980条,但这980条流承载的报文数量达到493 979;且最长的IP流流长达到215 209,300以上大部分流长对应的流数仅为1条~2条。显然,流长处于两端的流其特性严重偏离均值,对此部分流单独处理是合适的。
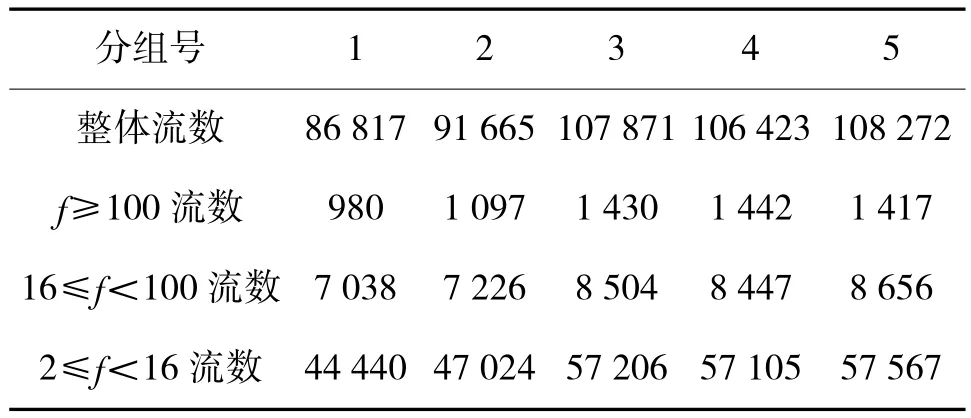
表1 全部5组报文的流数分布
2.1 单报文流聚类效果分析
IS方法中各模块缓存的分配与1.3节相同,权值更新模块中α=0.99,β=0.01,L1=16,T0=100。由于单个单报文流没有实际的意义,只有出现频率高的单报文流才有意义,同时出现频率高的单报文流通常能够反映网络异常。而由BFR的原理知,出现频率高的单报文流映射后的短字串出现的频率一定也高,而单独一个短字串的频率高并不能说明某个IP的频率高,例如聚类后的SIPH中3.74出现的频率为2 496,但SIPM的Top 20中找不到74.*,说明源地址中存在大量以3.74为前缀的IP,但不存在任意一个频率高的以3.74为前缀的源地址。于是表2统计了trace_2003中第1组报文聚类后出现频率高且相关的前5个短字串及出现频率,其中不相关的短字串如单独某个频率高的字串(SPIM=3.74等)并未在表中列出。
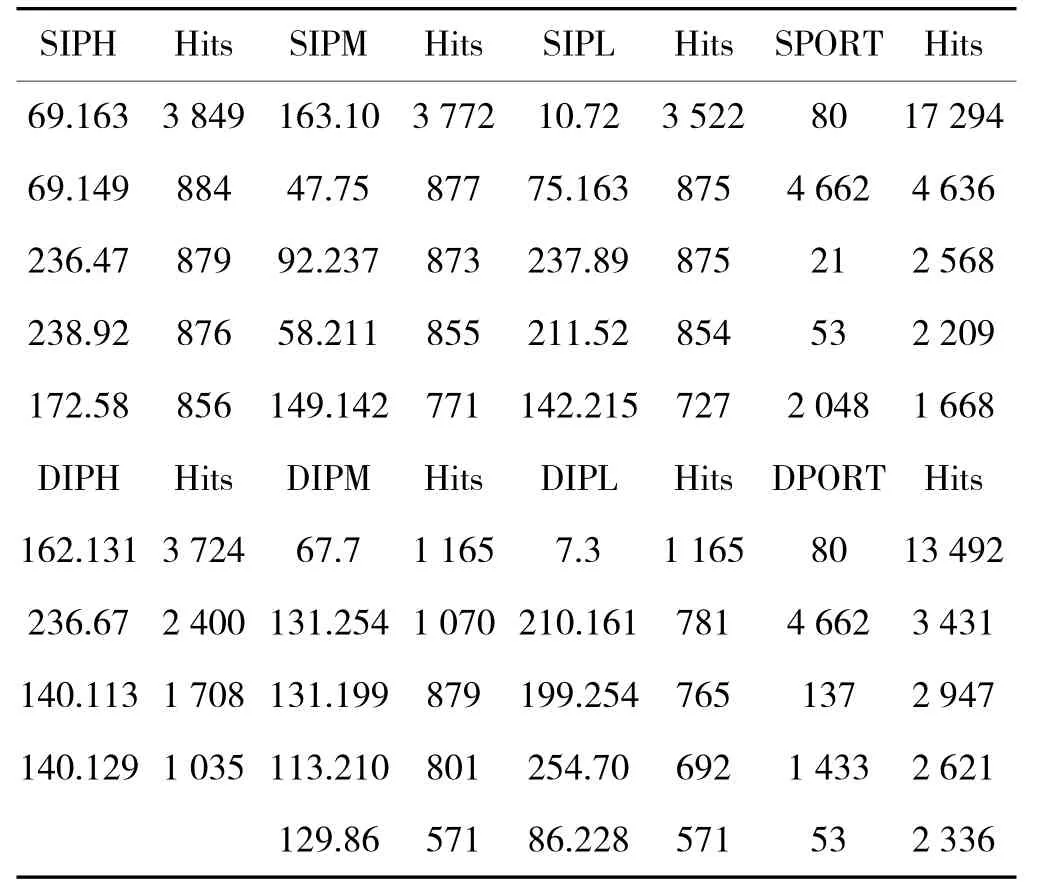
表2 单报文流聚类特性
由于不同哈希函数聚类的效果不一,SIPL、SPORT和DPORT来源于Top 5字串,DIPL来源于Top 7字串,SIPM来源于Top 8字串,DIPM来源于Top 10字串,SIPH来源于Top 14字串,DIPH来源于Top 17字串。可以看出,不论是源地址还是目的地址,其高位字符串不如低位字符串分散,更关键的是通过聚类后的单报文流可以重现出网络中的“高嫌疑”主机。如表1中69.163、163.10、10.72出现的频率分别为3849、3772和3522,表明以69.163.10.72为源地址的单报文流出现的频率很高,而单报文流基本上不承载有效信息,主机69.163.10.72很可能在从事扫描行为,而目的地址中如主机236.67.7.3的频率很高,该主机很可能不能正常响应服务或者遭受DDoS攻击。在网络遭受更高强度攻击的情况下,通过聚类单报文流不仅使得需要进一步处理的IP流数大为减少,而且聚类后的单报文流能够清晰揭示网络流量中的多种异常现象,因此,将单报文流从总体流量中分离出来并单独聚类是值得的。
2.2 权值抽样效果分析
2.2.1 频繁项流抽取效果分析
首先分析IS算法的频繁项流抽取效果。由于频繁项模块的流项同时保存着五元组和流长信息,IS算法的频繁项抽取方式不会产生误报。若某个流长f≥100的流先期到达部分报文后暂时未有报文到达,且已到达报文数量未达到阈值T0,该流将可能被淘汰到蓄水池模块中,若该流直到从蓄水池中被替换出去均无报文到达,则该流的流长会被低估,因此,IS算法存在漏报频繁项的可能。
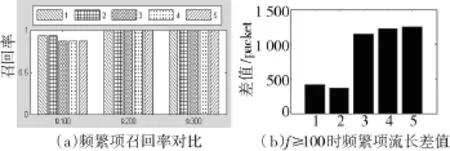
图2 IS算法频繁项流抽取效果
图2(a)统计了全部5组报文数据中流长f≥100、f≥200和f≥300的流的召回率情况,可以看出,IS算法的频繁项抽取方式具有较高的召回率,对于流长f≥100的流,频繁项的召回率始终位于86%~94%间;而对于流长f≥200和f≥300的流,频繁项模块几乎能够召回全部的流。
图2(b)统计了5组报文数据中IS算法召回的频繁项流流长之和与正确流长之和的差值,其中流长之和的差值中最大的为1 252,将该值平均到每个流上,每个流的流长统计值与流长实际值之差接近1,因此,IS算法抽取的频繁项流是比较完整的,IS算法具有较好的频繁项流抽取效果。
2.2.2 蓄水池抽样效果分析
IS算法中蓄水池抽样模块处理流的流长总处于2~99之间,由于频繁项模块抽取了网络中大部分的报文,而聚类模块抽取了网络中全部的单报文流,因此,到达蓄水池模块的流数和报文数均会大为减少,极大地减轻了蓄水池模块处理的压力,同时本文采用了蓄水池分段抽样的方式,确保在蓄水池容量一定的情况下能够抽取到更多种类的流。
在不考虑实时性的情况下按照NetFlow的组流方将报文分组归并成流,通过等概率蓄水池抽样抽取一定数量的流,并将抽取到的流与IS方法中蓄水池抽样模块抽取的流进行对比。考虑到本文权值抽样模块中共有3 500个表项用于保存流,于是等概率抽样方法中蓄水池的容量设置为3 500。
图3显示了等概率蓄水池抽样方法对于第1组报文数据抽取的IP流的分布情况,其中“100倍抽样流数”为22~350流长区间抽取流数的100倍放大。从图中可以看出,等概率蓄水池抽样方法对于流长处于两端的流的抽样效果较差,所抽取到的3 500个表项中共保存有1 412条单报文流,抽取到的流长f≤6的流数达到2 791条,而抽取的流长f≥100的流数仅为36条。显然等概率蓄水池抽样方法会抽取过多的短流,由于抽取的短流占用了绝大部分的缓存空间,同时长流出现的频率通常较低,因此,等概率抽样方法会丢弃绝大部分的长流以及少量频率低的中、短流,等概率蓄水池抽样方法用于分布不均衡的网络流量时会产生较大的偏差。

图3 等概率蓄水池抽样
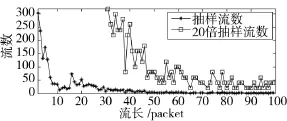
图4 蓄水池分段抽样
图4显示了IS算法中蓄水池抽样模块对于第1组报文数据抽取到的IP流的分布情况,其中“20倍抽样流数”为31~99流长区间抽取流数的20倍放大。可以看出,经过单报文流聚类、频繁项抽取及蓄水池分段抽样共同作用后,蓄水池抽样模块抽取到的2~99流长区间的2 000条流中,流数分布变得平缓,被抽取到的短流的流数显著减少,16~99流长区间的流数具有一定程度的增加。由于本文仅设置了2个蓄水池将流长[2,99]区间划分为2段实现抽样,被抽取的短流的数量仍然偏高,对于需要抽取流长分布更加均衡的IP流的场合,可以通过设置更多个较小的蓄水池实现多蓄水池分段抽样。同时IS算法对于流数较少但流长较大的频繁项流全部抽取,对于流数很多但携带可用信息有限的单报文流聚类处理,更重要的是IS算法的时间和空间复杂度能够满足网络流量在线处理的要求,IS算法的抽样效果明显优于等概率蓄水池方法。
由于本文采用容量有限的SRAM缓存实现实时流抽样,在缓存被占满而有新流报文到达时,总会有部分报文被淘汰,因此,所抽取流的完整性是IS算法必须考虑的一个问题。定义流完整率为所抽取流的流长与该流实际流长之比,由2.2.1节可知所抽取的频繁项流的完整率几乎为1,图5显示了IS算法中蓄水池抽样模块抽取到的2~99流长区间的2 000条流的流完整率分布情况,图中坐标(x,y)表示流完整率小于x的流其流数为y。可以看出,蓄水池抽样模块抽取到的绝大部分流的流完整率较高,全部流中有1 363流的流完整率为1,流完整率在0.5以下的流数为282,流完整率在0.8以上的流数为1 503,而流完整率在0.9以上的流数为1 437。尽管IS算法会造成少数网络流的流完整率降低,但换来的是系统能够实时处理网络流,且能够抽取到分布更为合理的网络流,这样做是值得的。
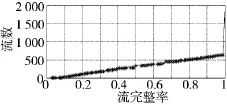
图5 蓄水池抽样模块流完整率分布
3 结束语
随着互联网流量数据规模的急剧增长,及时准确地从海量流量中抽取出需要的网络流对于网络管理和网络安全具有重要的意义。针对互联网流量中短流数量多但承载信息少、长流数量少但承载报文数多的特点,提出了一种面向不均衡网络流的综合抽样IS方法。IS方法在实时归并网络报文的基础上,采用BFR哈希函数实现单报文流聚类,采用频繁项模块实现频繁项流的抽取,对于上述之外的其他网络流,IS方法采用蓄水池分段抽样方法实现更多种类流长网络流的抽取。通过实际网络流量测试表明,相对于单一的抽样方法,IS方法在相同的缓存下能够抽取出更为丰富的网络流信息,并且算法能够实时应用于高速网络中。
[1]陈松,王珊,周明天.基于实时分析的网络测量抽样统计模型[J].电子学报,2010,38(5):1177-1180.
[2]张震,张进,汪斌强,等.基于流量负载自适应的时间分层分组抽样[J].系统仿真学报,2009,21(23):7421-7427.
[3]王洪波,陈时端,林宇.高速网络超连接主机检测中的流抽样算法研究[J].电子学报,2008,36(4):809-818.
[4]Zhao Q,Xu J,Kumar A.Detection of Super Source and Destinations in High-Speed Networks:Algorithms,Analysis and Evaluations[J].IEEE Journal on Selected Areas in Communictions,2006,24(10):1840-1852.
[5]张玉,方滨兴,张永铮.高速网络监控中大流量对象的识别[J].中国科学:信息科学,2010,40(2):340-355.
[6]裴育杰,王洪波,程时端.基于两级LRU机制的大流检测算法[J].电子学报,2009,37(4):684-691.
[7]宁卓,龚俭,顾文杰.高速网络中入侵检测的抽样方法[J].通信学报,2009,30(11):27-36.
[8]潘乔,裴昌幸,朱畅华.一种用于异常检测的网络流量抽样方法[J].西安交通大学学报,2008,42(2):175-178.
[9]Kumar A,Xu J,Wang J.Space-Code Bloom Filter for Efficient Per-Flow Traffic Measurement[J].IEEE Journal on Selected Areas in Communications,2006,24(12):2327-2339.
[10]Androulidakis G,Papavassiliou S.Improving Network Anomaly Detection Via Selective Flow-based Sampling[J].IET Communications,2008,2(3):399-409.
[11]赵月爱,陈俊杰,穆晓芳.非平衡技术在高速网络入侵检测中的应用[J].计算机应用,2009,29(7):1806-1808.
[12]龚俭,彭艳兵,杨望,等.基于Bloom Filter的大规模异常TCP连接参数再现方法[J].软件学报,2006,17(3):434-444.
An Integrated Sampling Method Over Imbalanced Network Flows
LI Jing-fu,YANG Zhi-qiang
(Huanghuai University,Zhumadian 463000,China)
Aiming at the property of huge quantity and little information of small flows and small quantity and high payload of big flows,an Integrated Sampling(IS)method over imbalanced network flows is proposed.The fixed size of high-speed memory is used to aggregate packets into flows within limited time windows on line in IS algorithm first.Then,the partially reconstructed hash functions are used to cluster single packet flows,and the weight-updating module in which the flow weight is assigned by length and time together and the frequent-item module are cooperated to mine frequent items.Lastly,the multi-reservoir modules are introduced to sample flows in a stratified way for the rest flows.The experiment on real traffic shows that IS is capable of sampling more abundant information of flows comparing with other single sampling method at the same memory cost and it can be applied in the high backbone network on the wire.
network flows,flows sampling,hash cluster,frequent items extraction,reservoir sampling
TP393
A
1002-0640(2015)12-0074-06
2014-11-29
2015-01-26
河南省科技攻关计划基金(122102210510);河南省教育厅科学技术研究重点基金资助项目(13A520786)
李景富(1981-),男,河南确山人,硕士。研究方向:计算机网络等。
猜你喜欢
歌海(2022年4期)2022-11-27
成都信息工程大学学报(2022年3期)2022-07-21
建材发展导向(2022年4期)2022-03-16
邮电设计技术(2021年2期)2021-03-13
中国品牌(2020年7期)2020-11-09
考试与评价·高二版(2020年4期)2020-09-10
茶道(2020年2期)2020-08-06
寻根(2020年1期)2020-04-07
老友(2019年4期)2019-05-10
计算机与数字工程(2018年5期)2018-05-29
