
基于用户购买记录的改进协同过滤推荐
2014-12-23 01:14何有世宋翠莉
计算机工程与设计 2014年9期
何有世,宋翠莉
(江苏大学 管理学院,江苏 镇江212013)
0 引 言
电子商务个性化推荐系统中最典型的技术为协同过滤算法,它利用历史评分数据寻找目标用户的相似邻居,根据相似用户的评分数据进行目标用户的推荐[1],然而用户的评分数据存在极大的数据稀疏性,推荐的结果存在偏差。为了解决评分数据的稀疏性,提高推荐算法的质量,很多学者对算法进行改进和完善。部分学者提出改进相似性计算的方法来提高推荐质量,如黄裕洋、金远平提出了一种综合用户和项目因素的协同过滤推荐算法[2],通过动态调节相似度的计算值,考虑用户和项目的影响因素计算最近邻居,结合最近邻的影响权重,计算推荐结果,提高了推荐质量,但数据稀疏性问题并没有解决。部分学者提出通过用户-项目稀疏矩阵填充来降低数据稀疏性,从而提高推荐的质量,如刘庆鹏、陈明锐提出优化稀疏数据集提高协同过滤推荐系统质量的方法[3],考虑到用户评分尺度问题,采用综合均值优化的矩阵填充方法来降低数据稀疏性。然而矩阵使用评分的预测值进行填充,与实际值存在误差,导致推荐结果存在偏差。另外有学者提出基于web日志的协同过滤算法来解决评分数据稀疏性,如TingZhong Wang、XiHu Zhi提出了基于改进协同过滤算法的个性化推荐[4],通过对web日志中的浏览记录进行挖掘,并考虑时间对偏好的影响因素,进行商品推荐。该算法根据用户的web浏览记录来挖掘,然而大量用户对商品进行浏览却不一定进行购买,且用户对部分商品的浏览具有偶然性,因此挖掘出的用户偏好并不完全真实可靠,无法保证推荐结果的精确性。
鉴于上述原因,本文使用用户的购买记录进行协同过滤推荐,根据用户的购买数量进行用户的偏好挖掘。用户的购买记录客观真实地反映了用户的偏好习惯,挖掘出的用户偏好真实可靠,更接近用户的实际情况,且用户的购买记录多于用户的评分记录,在一定程度上解决了数据稀疏性问题,使推荐的结果更加精确可靠。同时,使用改进的用户相似度计算方法,提高了相似度计算的质量,结合商品项目之间的关联关系的使用,保证了推荐的质量和精确度。
1 相似度计算方法的改进
1.1 传统相似性计算方法和存在的问题
在寻找目标用户的最近邻居时,需要计算目标用户和其他用户之间的相似度sim(i,j),传统的计算用户之间相似度的方法有余弦相似度法、修正的余弦相似度法和Pearson相关系数法等[5]。3 种方法都存在自身的缺点和不足,并不完全适用于用户相似度的计算。
(1)余弦相似度:用户之间的相似性通过用户购买数量向量之间的夹角余弦来实现

式中:Sia、Sja——用户i、用户j对项目a 的购买数量,m——商品项目的总数量。
余弦相似度的计算中,将用户没有购买的商品数量默认为0,由于购买数量矩阵的稀疏性,将导致矩阵中存在很多的0值,而实际上用户没有购买不代表用户的偏好为0,因此将导致计算出来的相似性结果存在偏差,不利于预测目标用户的购买数量。
(2)修正的余弦相似性:在余弦相似性的基础上,通过减去用户对商品的平均购买数量来弥补余弦相似性的缺陷,对余弦相似性进行改进
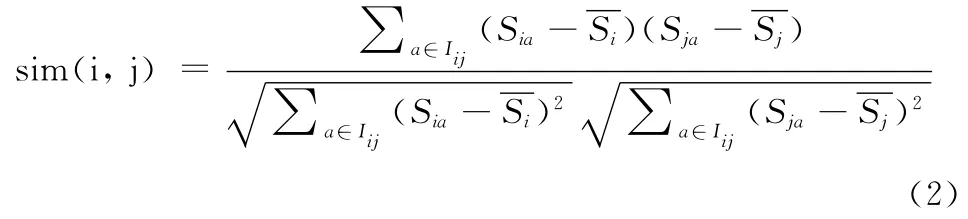
式中:Iij——用户i和用户j同时购买过的商品的集合,项目a代表购买过的商品集合Iij中的商品项目,——用户i、用户j的平均购买数量。
修正的余弦相似度中,如果用户仅购买一个商品,则平均购买数量即为该商品的购买数量,分母为0,无法计算用户之间的相似性。由于购买数量矩阵的数据稀疏性,可能存在较多用户无法计算相似性,将导致推荐结果存在偏差。
(3)Pearson相关系数:用来计算2个变量之间的线性相关关系

式中:Iij——用户i和用户j同时购买过的商品的集合,项目a代表购买过的商品集合Iij中的商品项目,——用户i、用户j的平均购买数量。
Pearson相关系数法,和修正的余弦相似性存在同样的问题,导致推荐结果存在偏差。
1.2 改进的相似性计算方法
鉴于传统相似性计算方法存在的问题,需要提出新的方法来计算用户之间的相似度。余洋等[6]提出模糊聚类的相似系数计算方法,并计算其最佳分类结果。根据协同过滤推荐的实际情况,为了避免上述3 种方法存在的问题,使用绝对值倒数法来计算用户之间的相似性

式中:Sia、Sja——用户i、用户j对项目a 的购买数量,n——用户的总数量,d——预先设定的整数值,这里d=2。
绝对值倒数法能有效的避免在修正余弦相似性和Pearson相关系数中,分母为0的情况,提高了用户之间相似性计算的质量,保证了推荐算法的精确度。
2 关联规则的使用
在用户-项目购买数量矩阵中可能会出现用户之间的相似度不为0,预测目标用户将可能购买该商品,但实际上目标用户和相似用户购买的商品种类差别很大,用户并没有意向购买目标商品,表1中的用户A 和用户B之间的相似度不为0,但2个用户购买的商品差别很大,用户B并没有意向购买g产品。由于购买数量矩阵的数据稀疏性问题,将存在大量类似情况,因此需要考虑用户购买商品项目之间的关联关系,进而预测该商品的购买数量才能得出更准确的推荐结果,提高推荐的质量。

表1 相似用户A 和目标用户B购买的商品项目
将数据集中的所有商品项目设定为项目集合I={Item1,Item2…Itemm},关联规则为X->Y,X、Y 分别为项目集合I中商品组成的集合,X 为关联规则的前件,Y 为关联规则的后件,这里规定后件Y 仅包含一个商品项目,从头到尾扫描整个数据集,依次确定每一个频繁1-项集、频繁2-项集,频繁3-项集、频繁4-项集和频繁5-项集及其对应的后件项目 (为了简化计算,这里只考虑到5-项集),从而确定商品项目之间的关联关系并确定其支持度 (support)和置信度 (confidence)。
根据确定的关联关系,目标用户的目标商品为关联关系的后件,分析目标用户的商品项目中存在的关联关系。依次寻找存在的5-项集、4-项集和3-项集及对应的关联关系,最后将寻找到的所有项集放在用户的候选集合中。为了简化运算,2-项集、1-项集及对应的关联关系将不再考虑。若目标用户不存在具有关联关系的5-项集、4-项集和3-项集,将不进行关联关系的考虑,直接计算矩阵中用户和目标用户的相似性。
在候选集合中如果关联规则的支持度>20%,且置信度>20%,将符合条件的关联关系对应的用户确定为目标用户的相似用户 (重复的相似用户仅使用一次)计算这些相似用户和目标用户的相似度。
在表2中,对于目标用户User5,Item5为后件,首先选择作为前件的5-项集,这里5-项集不存在,依次选择4-项集,表2 中为 {Item1、Item2、Item3、Item4},后件为Item5,前件存在导致后件也存在的有User3,因此User3的相关关系和User5非常类似,在实现推荐时应考虑User3用户和目标用户的相似性。然后选择3-项集,包括:{Item1、Item2、Item3}和 {Item1、Item2、Item4},相关关系对应的类似用户有User1和User2。前件为2-项集和1-项集的情况不再考虑。

表2 目标用户的相似用户选取
3 基于购买记录的改进协同过滤推荐过程
基于用户购买记录的改进协同过滤推荐过程为:首先使用用户购买记录的商品数量建立用户-项目矩阵,然后使用关联规则寻找已知用户购买商品之间的关联关系,计算目标用户和已知用户之间的相似性,选择符合条件的相似用户对目标用户未购买商品进行推荐。
推荐算法的详细步骤:
用户-项目购买数量矩阵A(n,m)见表3。

表3 用户-项目购买数量矩阵A(n,m)
输入:用户-项目购买数量矩阵A(n,m),目标用户C。
输出:目标用户C进行TOP-N 推荐的预测购买数量。
(1)根据关联规则的使用中所描述的方法,寻找目标用户C中寻找符合关联关系的5-项集、4-项集和3-项集,将寻找到的项集放到候选集合中。
(2)选择候选集合中支持度>20%且置信度>20%的关联关系对应的用户-项目购买数量矩阵中的相似用户,根据改进的相似性计算方法即式 (4)计算这些用户与目标用户C的相似性sim(c,n),并将相似性按从大到小的顺序排列。
(3)选择相似度最大的N 个用户作为最近邻居,根据其对应的相似度和用户的购买数量,计算目标用户C 进行TOP-N 推荐的结果,完成推荐

式中:Nc——用户C的最近邻居的用户集合,用户C 对项目h的预测购买数量为Sch,最近邻居N 对项目h的已知购买数量为Snh——用户C、用户N 的平均购买数量。
4 实验验证
4.1 实验数据选取
实验数据采用某电子商务网站交易记录数据集对该算法进行验证,该数据集中包括231640交易记录,其中包括用户ID、订单ID、商品ID、购买数量、商品金额等数据项,共1321个用户1045 个商品。本文从该数据集中抽取142个用户购买135个商品,共7672个的交易记录,包括用户ID、商品ID、购买数量等数据项进行交易记录的数据挖掘。用户购买某商品的数量越多,说明该用户越喜爱该商品。实验抽取30个用户购买135个商品的记录来测试算法的精确性。
4.2 数据稀疏性
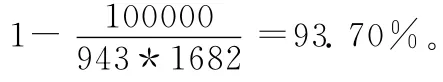
经过2个数据集的对比,表明用户的购买记录明显多于用户的评分记录,因此,采用用户的购买记录进行数据挖掘在一定程度上解决了数据稀疏性问题,且用户的购买数量真实客观的反应用户的偏好和购买习惯,提高了协同过滤算法的效率,使推荐的结果更加真实可靠。
4.3 实验结果分析
平均绝对误差 (MAE)是通过计算预测的用户购买数量和实际用户购买数量之间差的绝对值来度量算法的精确性[7]。MAE的值越小,说明预测的用户购买数量和实际购买数量的值越接近,存在的偏差越小,算法的精确性越高。用户u的平均绝对误差MAEu为

式中:Puk——用户u对商品i的实际评分,Quk——用户u对商品i的预测评分,n——用户u进行推荐的商品总数。
TOP-N 推荐中,最近邻居N 的选取对协同过滤算法的平均绝对误差存在一定的影响。当TOP-N 推荐的最近邻居分别为5、10、15、20、25时,基于用户购买记录的传统user-based算法 (简称传统算法)和基于用户购买记录的改进user-based算法 (简称改进算法)实验结果如图1所示。

图1 最近邻居N 的变化对MAE的影响
由此可见,用户最近邻居的选取对算法的精确性存在很大的影响,并不是最近邻居越多,算法推荐的精确性越高。本实验中当最近邻居N=15时,MAE的值最小,改进算法的精确性最高。
当TOP-N 推荐的最近邻居N=15 时,传统算法和改进算法的平均绝对误差结果如图2所示。

图2 N=15时,传统算法和改进算法的MAE
从上面两组实验可以看出:基于购买记录的改进Userbased算法与基于购买记录的传统User-based算法相比,算法精确度较好,推荐质量较高。用户的购买数量的挖掘,用户相似性计算方法的改进,结合关联关系的使用,提高了改进协同过滤算法的精确度,保证了推荐结果的准确可靠。
5 结束语
本文在前人的研究基础上,使用用户的购买记录进行数据挖掘,从而进行协同过滤推荐。本文的主要贡献在于:①采用用户购买记录中的购买数量进行数据挖掘。与用户评分记录挖掘相比,用户的购买记录更加客观真实,且在一定程度上降低了数据稀疏性;与用户访问日志挖掘相比,用户的购买记录挖掘出用户的偏好更加客观真实,推荐的结果更加精确。②采用改进的相似性计算方法即绝对值倒数法来计算用户之间的相似性,提高了相似性计算的质量,保证了推荐的精确性。③结合商品项目的关联规则的使用,提高了目标用户对目标商品购买数量预测的精确性,避免出现用户之间的相似性不为0,预测目标用户将购买该商品,但两个用户购买的商品差别很大,目标用户并没有意向购买该产品的情况,提高了数据挖掘的精确性,保证了推荐的质量和正确性。本文的实验结果表明,基于购买记录的改进协同过滤推荐,降低了数据稀疏性,提高了推荐的质量,能够提供较为精确的产品推荐结果。今后的主要任务是进一步研究关联关系对协同过滤推荐的影响、改进算法、提高算法的效率和推荐的质量。
[1]LI Hui,HU Yun,LI Cunhua,et al.The personalized recommendation algorithm based on neighborhood relationship research [J].Computer Engineering and Application,2012,48(36):205-209 (in Chinese).[李慧,胡云,李存华,等.基于近邻关系的个性化推荐算法研究 [J].计算机工程与应用,2012,48 (36):205-209.]
[2]HUANG Yuyang,JIN Yuanping.A collaborative filtering recommendation algorithm combining the user and project factors[J].Journal of Southeast University,2010,40 (5):917-921 (in Chinese).[黄裕洋,金远平.一种综合用户和项目因素的协同过滤推荐算法 [J].东南大学学报,2010,40(5):917-921.]
[3]LIU Qingpeng,CHEN Mingrui.Optimization of sparse data sets to improve the quality of collaborative filtering recommendation system against[J].Journal of Computer Applications,2012,32 (2):1082-1085 (in Chinese). [刘庆鹏,陈明锐.优化稀疏数据集提高协同过滤推荐系统质量的防范 [J].计算机应用,2012,32 (2):1082-1085.]
[4]Wang Tingzhong,Zhi Xihu.The personalized recommendation method based on improved-collaborative filtering algorithms[J].Computer Science and Information Engineering,2012,169:425-430.
[5]ZHANG Zhongping,GUO Xianli.An optimized collaborative filtering recommendation based on the project grade predictions[J].Computer Application Research,2008,25 (9):2658-2660 (in Chinese). [张忠平,郭献丽.一种优化的基于项目评分预测的协同过滤推荐 [J].计算机应用研究,2008,25(9):2658-2660.]
[6]YU Yang,XIONG Hongbin.The determination of environmental noise data similarity coefficient using fuzzy clustering analysis[J].Environmental Protection Science and Technology,2010,16 (3):1-4 (in Chinese). [余洋,熊鸿斌.环境噪声数据采用模糊聚类分析时相似系数的确定 [J].环保科技,2010,16 (3):1-4.]
[7]WANG Qian,YANG Liyun,WANG Deli.Collaborative filtering algorithm based on attribute values grade distribution for user preferences [J].Journal of Systems Engineering,2010,25 (4):561-568 (in Chinese).[王茜,杨莉云,杨德礼.面向用户偏好的属性值评分分布协同过滤算法 [J].系统工程学报,2010,25 (4):561-568.]
[8]Zhang Dongzhan,Xu Chao.A collaborative filtering recommendation system by unifying user similarity and item similarity [J].Web-Age Information Management,2012,7142:175-184.
[9]Zhang Dejia.Collaborative filtering recommendation algorithm based on user interest evolution [J].Advances in Multimedia,Software Engineering and Computing,2012,129:279-283.
[10]Huang Shuiyuan,Duan Longzhen.E-commerce recommendation algorithm based on multi-level association rules[J].Ad-vances in Electronic Commerce,2012,148:479-485.
[11]Yuki Ogawa,Hirohiko Yamamoto,Isamu Okada.Development of recommender systems using user preference tendencies:An algorithm for diversifying recommendation [J].The International Federation for Information Processing,2008,286:61-73.
[12]Yang Hongmei.Collaborative filtering algorithm based on improved similarity calculation [J].Information Computing and Application,2011,243:271-276.
[13]Li Wenlong,He Wei.An improved collaborative filtering approach based on user ranking and item clustering [J].Internet and Distributed Computing Systems,2013,8223:134-144.
[14]Li Yu,Yang Xiaoping.Collaborative filtering recommendation based on preference order[J].Research and Practical Issues of Enterprise Information SystemS II,2008,255:1567-1573.
[15]Deepa Anand,Kamal K Bharadwaj.Enhancing accuracy of recommender system through adaptive similarity measures based on hybrid features[J].Intelligent Information and Database Systems,2010,5991:1-10.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
新世纪智能(数学备考)(2021年9期)2021-11-24
河北画报(2020年8期)2020-10-27
当代陕西(2019年15期)2019-09-02
天津科技大学学报(2018年4期)2018-08-22
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
浙江大学学报(工学版)(2016年2期)2016-06-05
俄罗斯问题研究(2013年1期)2013-03-11
网络安全与数据管理(2010年1期)2010-05-18
