
基于社交网络的社会化推荐算法研究
2014-12-23 12:17朱彦杰
科技视界 2014年9期
朱彦杰
(许昌学院,河南 许昌 461000)
美国著名的第三方调查机构尼尔森调查了影响用户相信某个推荐的因素[1],调查结果显示,90%的用户相信朋友对他们的推荐,70%的用户相信网上其他用户对广告商品的评论。从该调查可以看到,好友的推荐对于增加用户对推荐结果的信任度非常重要。在社交网站中,可以通过好友给自己过滤信息,只关注与阅读和自己有共同兴趣好友分享来的信息,从而避免了很多无关的信息,自然地减轻了信息过载问题。
在社交网站方面,国外以Facebook 和Twitter 为代表,国内社交网站,以QQ 空间、人人网、朋友网、新浪微博等为代表;这些社交网站形成了两类社交网络结构。一种是,好友一般都是自己在现实社会中认识的人,比如同事、同学、亲戚等,并且这种好友关系是需要双方确认的,如Facebook、QQ 空间,这种社交网络称为社交图谱。另一种是,好友往往都是现实中自己不认识的,而只是出于对对方言论的兴趣而建立好友关系,好友关系也是单向的关注关系,如Twitter、新浪微博,这种社交网络称为兴趣图谱。同时,也必须指出,任何一个社会化网站都不是单纯的社交图谱或兴趣图谱。在QQ 空间中大多数用户联系基于社交图谱,而在微博上大多数用户联系基于兴趣图谱。在微博中,也会关注现实中的亲朋好友,在QQ 中也会和部分好友有共同兴趣。
1 社交网络及其数据分类
在社交网络中,需要表示用户之间的联系,可以用图G(V,E,w)定义一个社交网络,其中V 是顶点集合,每个顶点代表一个用户,E 是边集合,如果用户va 和vb 有社交网络关系,那么就有一条边e(va,vb)连接这两个用户,w(va,vb)用来定义边的权重。前面提到基于社交图谱或兴趣图谱的两种社交网络,基于社交图谱的朋友关系是需要双向确认的,因而可以用无向边连接有社交网络关系的用户;基于兴趣图谱的朋友关系是单向的,可以用有向边代表这种社交网络上的用户关系。对图G 中的用户顶点u,定义out(u)为顶点u 指向的顶点集合(也就是用户u 关注的用户集合),定义in(u)为指向顶点u 的顶点集合(也就是关注用户u 的用户集合)。显然在无向社交网络中out(u)=in(u)。一般来说,有3 种不同的社交网络数据[2]。
双向确认的社交网络数据:在以Facebook 和人人网为代表的社交网络中,用户A 和B 之间形成好友关系需要通过双方的确认。因此,这种社交网络一般可以通过无向图表示。
单向关注的社交网络数据:在以Twitter 和新浪微博为代表的社交网络中,用户A 可以关注用户B 而不需要得到用户B 的允许,因此这种社交网络中的用户关系是单向的,可以通过有向图表示。
基于社区的社交网络数据:还有一种社交网络数据,用户之间并没有明确的关系,但是这种数据包含了用户属于不同社区的数据。比如豆瓣小组,属于同一个小组可能代表了用户兴趣的相似性。
2 基于社交网络的推荐算法
2.1 基于邻域的社会化推荐算法
假设给定一个社交网络及其用户行为数据集,社交网络列出了用户之间的好友关系,用户行为数据集给出了不同用户的历史行为和兴趣数据,在这种情况,给用户推荐好友喜欢的物品集合,其算法思想:
用户u 对物品i 的兴趣pui可以通过如下公式(1)计算:其中out(u)是用户u 的好友集合,如果用户v 喜欢物品i,则rvi=1,否则rvi=0。另外,要注意的是,在用户u 的好友中,不同的好友和用户u 的熟悉程度和兴趣相似度也是不同的。因而,应该在推荐算法中考虑好友和用户的熟悉程度以及兴趣相似度,由公式(2)所示:wui由两部分相似度构成,一部分是用户u和用户v 的熟悉程度,另一部分是用户u 和用户v 的兴趣相似度。
用户u 和用户v 的熟悉程度主要描述用户u 和v 在现实生活中的熟悉程度。这里熟悉度依据用户之间的共同好友比例来度量。熟悉程度由公式(3)表示。用户u 和用户v 的兴趣相似度的度量方法是:如果两个用户喜欢的物品集合重合度很高,两个用户的兴趣相似度就很高。兴趣相似度由公式(4)表示。其中N(u)是用户u 喜欢的物品集合。

2.2 基于图的社会化推荐算法
社交网站中存在两种关系,一种是用户对物品的兴趣关系,一种是用户之间的社交网络关系。通过图模型来表示这两种关系,便于对用户进行个性化推荐。用社交网络图来表示用户的社交关系,用户物品二分图来描述用户对物品的行为,这两个图可以合并成一个图。如图1,该图上有用户顶点(圆圈)和物品顶点(方块)两种顶点。若用户u对物品i 产生过行为,那么两个节点之间就有边相连。图1 中用户A对物品a、e 产生过行为。如果用户u 和v 是好友,有一条边连接这两个用户,图中用户A 和B、D 是好友。
在社交网络中,除了常见的、用户和用户之间直接的社交网络关系,还有一种关系,即两个用户属于同一个社群。可以加入一种节点表示社群(如图2,最左边一列的节点,六边框),而如果用户属于某一社群,图中就有一条边联系用户对应的节点和社群对应的节点。
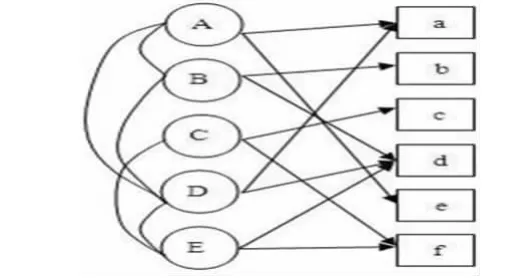
图1 社交网络图和用户物品二分图的结合
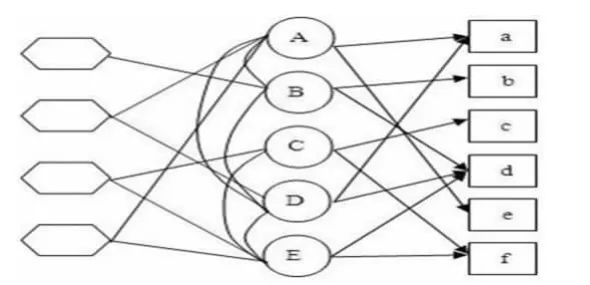
图2 融合两种社交网络信息的图模型
在定义完图中的顶点和边后,需要定义边的权重,其中用户和用户之间边的权重可以定义为用户之间的相似度的α倍(包括熟悉程度和兴趣相似度),而用户和物品之间的权重可以定义为用户对物品喜欢程度的α倍。α 和β 需要根据应用的需求确定。如果希望用户好友的行为对推荐结果产生比较大的影响,就选择比较大的α,相反,如果希望用户的历史行为对推荐结果产生比较大的影响,就选择比较大的β。
在定义完图中的顶点、边和边的权重后,可以利用PersonalRank算法[3]度量图中任两个顶点之间的相关性,从而给每个用户生成推荐结果。具体如下:假设要给用户u 进行个性化推荐,可以从用户u 对应的节点vu开始在用户物品二分图上进行随机游走,游走到任何一个节点时,首先按照概率α 决定是继续游走,还是停止这次游走并从vu节点开始重新游走。如果决定继续游走,那么就从当前节点指向的节点中按照均匀分布随机选择一个节点作为游走下次经过的节点。这样,经过很多次随机游走后,每个物品节点被访问到的概率会收敛到一个数。最终的推荐列表中物品的权重就是物品节点的访问概率。
3 实际系统中的社会化推荐算法
基于邻域的社会化推荐算法比较简单,在实际系统中却是难以操作的,因为该算法需要事先获得用户所有好友的历史行为数据,而这一操作在实际系统中是比较重的操作,因为大型网站中用户数目非常庞大,用户的历史行为记录也非常庞大,所以不太可能将用户的所有行为都缓存在内存中,只能在数据库前做一个热数据的缓存。如果需要比较实时的数据,这个缓存中的数据就要比较频繁地更新,因此避免不了数据库的查询,然而,数据库查询一般是很慢的,特别是针对行为很多的用户更是如此。因而,若一个算法再给一个用户做推荐时,需要他所有好友的历史行为数据,这在实际环境中是比较困难的。
为了让它能够具有比较快的响应时间,需要改进基于邻域的社会化推荐算法。改进的方法有两种:一种是两处截断法,第一处截断就是在拿用户好友集合时并不拿出用户所有的好友,而是只拿出和用户相似度最高的N 个好友(N 取一个比较小的数),从而给该用户做推荐时可以只查询N 次用户历史行为接口。第一处截断在查询每个用户的历史行为时,可以只返回用户最近1 个月的行为,这样就可以在用户行为缓存中缓存更多用户的历史行为数据,从而加快查询用户历史行为接口的速度。另一种解决方法是重新设计数据库。通过前面分析可以发现,社会化推荐中关键的操作就是获得用户所有好友的行为数据,然后通过一定的聚合展示给用户。如果对照一下微博,就会发现微博中每个用户都有个信息墙,这个墙上实时展示着用户关注的所有好友的动态。因此,只要能够实现这个信息墙,就能够实现社会化推荐算法。Twitter 给每个用户维护一个消息队列,当一个用户发表一条微博时,所有关注他的用户的消息队列中都会加入这条微博。这样用户获取信息墙时可以直接读消息队列,所有终端用户的读操作很快。Twitter 这种架构思想[4]移植到社会化推荐系统中,其具体设计为:首先,为每个用户维护一个消息队列,用于存储他的推荐列表;接着,当一个用户喜欢一个物品时,就将(物品ID、用户ID 和时间)这条记录写入关注该用户的推荐列表消息队列中;最后,当用户访问推荐系统时,读出他的推荐列表消息队列,对于这个消息队列中的每个物品,重新计算该物品的权重。计算权重时需要考虑物品在队列中出现的次数,物品对应的用户和当前用户的熟悉程度、物品的时间戳。同时计算出每个物品被哪些好友喜欢过,用这些好友作为物品的推荐解释。
4 结束语
社会化推荐得到许多网站的重视,一方面好友推荐可以增加推荐的信任度,好友往往是用户最信任的,用户往往不一定信任计算机的智能,但会信任好朋友的推荐。另一方面,社交网络可以解决冷启动问题,当一个新用户通过微博或者Facebook 账号登录网站时,可以从社交网站中获取用户的好友列表,然后给用户推荐好友在网站上喜欢的物品。从而可以在没有用户行为记录时就给用户提供较高质量的推荐结果,部分解决了推荐系统的冷启动问题。当然,社会化推荐也有不足,其中最主要的是就是很多时候并不一定能提高推荐算法的离线精度(准确率和召回率)。特别是在基于社交图谱数据的推荐系统中,因为用户的好友关系不是基于共同兴趣产生的,所以用户好友的兴趣往往和用户兴趣并不一致。
[1]http://blog.nielsen.com/nielsenwire/consumer/globe-advertising-consumers-trustreal-friends-and-virtual-strangers-the-most/[OL].
[2]项亮.推荐系统实践[M].人民邮电出版社,2012,6.
[3]Fouss Francois,Pirotte Alain.Random-walk Computation of Similarities between Nodes of a Graph with Application to Collaborative Recommendation [J].IEEE Transactions on Knowledge and Data Engineering,2007.
[4]http://www.infoq.com/news/2009/06/Twitter-Architecture[OL].
[5]MaayanRoth,AssafBen-David.Suggesting Friends Using the Implicit Social Graph[J].ACM 2010.
猜你喜欢
中等数学(2021年9期)2021-11-22
少先队活动(2020年12期)2021-01-14
小雪花·初中高分作文(2019年10期)2019-02-12
山东科学(2018年6期)2018-12-20
中成药(2017年3期)2017-05-17
杂草学报(2012年1期)2012-11-06
小雪花·成长指南(2009年10期)2009-12-04
