
数据抽取中文本分类分析与研究
2014-12-23 07:13郭东峰
科技视界 2014年9期
郭东峰
(新乡学院 计算机与信息工程学院,河南 新乡453000)
0 引言
Web 信息抽取技术可以大大的缩短人们对资料的整理时间,为信息检索提供方便,有利于现实文档的存档管理。而Web 信息抽取技术所抽取的内容主要为文本,不断迅速发展的互联网可以被看作是十分巨大的文档库,大量的文档信息通常分散存放在不同网站上,它们具有不同的表现形式。为实现数据抽取,首要任务是需要将文本分类处理。
1 文本的表示方法
普通的文本是无结构的,为了让计算机分析它们所属的类别,需要将文本转化成可被处理的结构化形式,目前应用最广泛方法的是向量空间模型,基本思想是把文档表示向量空间中的一个向量。特征项必须具备一定的特性:
1)特征项要能够准确标识文本内容,表征文本的主题信息;
2)特征项具有将目标文本与其他文本相区分的能力;
3)特征项的在数量上不能太多,且出现频率适中;
4)特征项要容易从文本中分离,具有明确的语义。
在中文文本类中最常用的是采用词语作为文本的特征项。词语有几个优点:相对于字具有更强的语义信息歧义较少;相对于短语,词更容易从文本中进行切分。词语由于含了多个文字组合,在文本中出现的频率较低,不适合作为特征项。
文本中关键字出现的频率统计量用x 表示,最高关键字出现频率取值为1,其它关键字频率取其与最高关键字出现次数的比值。页面向量空间表达式为:Dt(x1w1,x2w2,…,xnwn),i=1,2,…,n。关键字构成的主题向量Dk=(w1,w2,…,wn), i=1,2,…,n。网页文本Dt 与领域主题Dk之间的内容相关度Sim(Dt,Dk)使用向量夹角余弦值表示:

选择合适的多个特征词构成特征向量来表征所在的文本主题,使用特征向量作为文档的中间表示形式进行相互比较,降低了文本相似度算法复杂度。
2 文本特征的选择
待分类的网页文本中往往包括很多词语,这些词语对分类没有太大帮助,未经筛选特征项集合规模较大,文本特征向量维数较高给计算带来困难。需要提取一个能够很好地概括领域相关网页内容的特征子集,同时该子集要求能很好的区分领域主题。领域关键词是从领域文本集中经过算法选取出来的,能够高度概括和体现领域文本基本内容的词语。本文将这些词语通过特征提取算法选择出来构成空间向量。目前常用的特征选择方法有CHI 统计、信息增益和互信息等。
2.1 CHI 统计
CHI 统计方法衡量词语t 和文档类别c 之间的依赖关系,并假设t 和c 之间的非独立关系符合具有一阶自由度的x2 分布。词条对于某类别的x2 统计值越高,表明它们之间的相关性越大,特征词t 对类别c 表征能力越强。令N 表示训练语料中的文档总数,c 为某一特定类别,t 表示特定的词条,A 表示属于类别c 且包含t 的文档频数,B表示不属于类别c 但是包含t 的文档频数,C 表示属于类别c 但不包含t 的文档频数,D 是既不属于c 也不包含t 的文档频数。则t 对于类别c 的CHI 值由下列计算:

2.2 互信息
互信息的基本思想:以词条t 和类别ci 之间的共同出现程度来表示词条t 与类别ci 的相关程度。词条对于类别的公共概率越大,它们之间的互信息也越大。假设p(t,ci)表示训练集合中既包含特征t 又属于类别ci 的文本出现的概率,p(t)表示包含特征t 的文本在训练集合中出现的概率,p(ci)表示训练集合中属于类别ci 的文本的概率,A 为包含词语t 且属于类别ci 的文本数,B 为为包含词语t 且不属于类别ci 的文本数,C 为类别Ci 中不出现特征t 的文本数,N 为文本总数,则特征t 与类Ci 之间的互信息定义为:
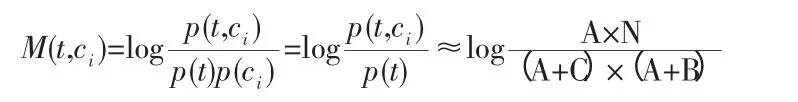
为了衡量一个特征在全局特征选择中的重要性,计算特征提供的关于类别信息的加权平均值。
2.3 信息增益
信息增益方法的基本思想是:通过计算某个特征词语存在与否对文档的信息熵的差值来判断该特征词的类别表征能力。具体方法是把训练文档集D 看作按某种概念分布的信息源,依靠文档集的信息熵和文档中词语t 的条件熵之间信息量的增益关系确定该词语在文本分类中所能提供的信息量。
3 中文文本分类方法
文本分类的方法中要有贝叶斯分类、支持向量机、K 近邻等方法。
3.1 朴素贝叶斯文本分类
贝叶斯分类器其原理是计算文本属于某个类别的概率,将文本分到概率最大的类别中去,计算时,利用了贝叶斯公式:

P(ci)是类的先验概率,P(dx|ci)是类的条件概率。对同一篇文本,P(dx)不变。设dx 表示为特征集合(t1,t2,..,tn),n 为特征个数,假设特征之间相互独立,则有:

其中P(tj|ci)为特征词的条件概率。
贝叶斯分类器因具有容易实现,运算速度快的特点而被广泛使用。
3.2 K 近邻
K 近邻分类算法是一种非参数的分类技术, 在基于统计的模式识别中非常有效。
基本原理是通过计算待分类文档与训练文档集所有文档之间的相似度,找出K 个与待分类文档距离最相近的样本,即K 个邻居,并依据这K 个邻居所属的类别来判定待分类文档的类别。先比较待分类文档与其k 个邻居的相似度,并以此作为候选类别的权重,然后使用预先得到的相似度的阈值,就可以得到文档的最终所属类别。
4 结束语
文本分类技术在自然语言处理、信息检索、文本挖掘等领域都有着广泛的应用,其主要任务是在预先给定的主题类别标记集合下,根据文本内容判定它所属的类别。文本分类是许多数据管理任务的重要组成部分,基于文本分类技术的应用领域越来越多,自动论文摘要,数字图书馆、网络分类新闻组、文本过滤、机器翻译等获得大量应用。同时,经过分类后的文本可以减少用户甄别信息时间,满足不同用户需求,发挥信息自身其最大使用价值。
[1]郑庆华,刘均,田锋,等.Web 知识挖掘理论、方法与应用[M].科学出版社,2010,6:136-140.
[2]蒲筱哥.基于Web 的信息抽取技术研究综述[J].现代情报,2007,10:215-219.
[3]陈钊,张冬梅.Web 信息抽取技术综述[J].计算机应用研究,2010,12.
[4]刘伟,孟小峰,孟卫一.Deep Web 数据集成研究综述[J].计算机学报,2007,30(9):1475-1489.
猜你喜欢
数理化解题研究(2017年4期)2017-05-04
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
新校长(2016年8期)2016-01-10
电子器件(2015年5期)2015-12-29
电测与仪表(2015年9期)2015-04-09
弹箭与制导学报(2015年1期)2015-03-11
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
