
性能势算法研究及在RoboCup中的应用
2014-12-23 01:19:58杨宛璐黄浩晖王广涛
计算机工程与设计 2014年3期
杨宛璐,陈 玮,黄浩晖,王广涛
(广东工业大学 自动化学院,广东 广州510006)
0 引 言
强化学习(reinforcement learning)[1]是解决智能体寻优路径的有效手段,通过与环境不断交互来改进自身行为最终获得最优行为策略,在各个机器学习领域都有广泛的应用。强化学习分为两种类型:折扣奖赏强化学习和平均奖赏强化学习。传统的平均奖赏类型强化学习更多考虑当前动作对未来的影响,适于解决不具有终结状态或者具有循环特性的问题,但其研究还处于一个初级阶段。早期,Schwarz提出了一种平均奖赏学习算法R-learning,采用值迭代的思想来获得最优策略,用于解决平均奖赏的MDP问题[2];后来Tadepalli提出基于模型的H-learning[3]。这两种算法都是基于值迭代,但是某个策略的平均奖赏和的逼近过程并不是很稳定,并且其对参数环境的敏感也是一大弊端。随后,高阳等人[4]将性能势理论引入到强化学习技术中,得到一种新的平均奖赏强化学习算法G-learning。该算法主要针对的是单链马尔科夫过程,对于多智能体这种非马尔科夫环境,直接使用的效果并不好。文献[5]提出了一种在多链马尔科夫状态下,求取平均代价的方法;文献[6]结合敏感性分析方法(sensitivity-based approach)[7]和优化几何方差方法(geometric variance reduction)[8]提出了基于性能势的预估平均奖赏方法。本文把改进的G-learning引入到多智能体系统中,考虑其它马尔科夫链对agent所产生的影响。算法选择最优的参照系,旨在加快其收敛速度,并成功应用在Keepaway平台上,降低了状态空间的大小,从而达到了预期学习效果,加快了学习过程。
1 强化学习
在人工智能领域中,强化学习是一种重要的解决学习问题的方法。在强化学习中,agent通过与环境的交互获得知识,以此来改进自身的行为。试错和回报是强化学习的两个最显著的特征,它主要是依靠环境对所采取行为的反馈信息来评价,并根据评价去指导以后的行为,使行为效果更佳,通过试探得到的较优的行为策略来适应环境。强化学习将环境映射到动作形成策略,最终目标是获得使得长期的积累的最大奖赏大的策略。在强化学习中,存在两种评价奖赏值的标准,折扣累积奖赏值式(1)和平均累积奖赏值式(2)。近年,研究更多的是折扣累积奖赏值,它注重的是近期的回报,表示当前动作对agent的影响,注重的是眼前的利益,符合大多数一般问题的求解。然而,对于不具终结状态或者具有循环特点的问题,便显得不适用。因此,对于注重长远利益的问题,需要更多地考虑当前动作的决策对未来环境的影响,平均奖赏强化学习方法更适于解决这类问题

1.1 平均奖赏强化学习
R-learning是一种典型的无模型的平均奖赏强化学习算法,它在学习的过程中环境模型是不可知的。R-learning由4个关键部分组成:策略函数、回报函数、值函数、环境模型。策略函数被定义成从观察到的状态到选择的动作的映射;回报函数可以看作是强化学习的目标,在每一步学习过程中,回报函数估计智能体与环境之间的相互作用的效果,智能体的学习目标是使的长期积累奖赏值最大化,换句话说,回报的状态到选择的动作的映射;回报函数可以看作是强化学习的目标,在每一步学习过程中,回报函数估计智能体与环境之间的相互作用的效果,智能体的学习目标是使的长期积累奖赏值最大化,换句话说,回报函数可以确定哪些动作会更适于现在的环境,哪些动作被忽略掉;值函数用来估计这些被选择动作的奖赏值;而环境模型是用来模拟智能体的学习环境。
但是在目前已有的一些平均奖赏强化学习方法中,都采用采样的方式逼近某个策略的平均奖赏和,由于在逼近过程中并不稳定,则导致已有学习算法不稳定。高阳等人将性能势理论应用到强化学习算法中,用相对参考状态来替代平均奖赏和,获得一种新的平均奖赏强化学习算法——G-learning学习算法。
1.2 性能势以及基于性能势的无折扣强化学习算法
假定有一个可重复且各态历经的Markov 链X ={Xn:n≥0} 在有限状态空间S=1,2,…,M,其状态转移概率矩阵为P=[p(i,j)]∈[0,1](M×M),π=π(1),…,π(M)表示状态稳定概率,f=(f(1),f(2),…f(M))T表示各个状态的奖赏值,是一个M 维的全1矩阵。而π=πp。平均性能可定义为式(6)

g=(g1,g2,…,gn)T表示系统的性能势,令g=(Ip+eπ)-1f,其中矩阵(I-p+eπ)-1被定义为基础矩阵。I表示单位矩阵,e=(1,1,…,1)T,根据泰勒公式展开成式(7)[9]

将性能势和值迭代方法相结合,得到一种新的强化学习算法-G 学习,该算法选择任意一个状态作为参考状态,采用值迭代的方法更新状态的性能势,且算法的运行只需要设定一个学习参数[10]。
根据性能势的定义,选择任意一个状态作为其它状态性能势的参考标准。假定选择状态S0作为参考状态,则sn状态下的性能势可表示为下式
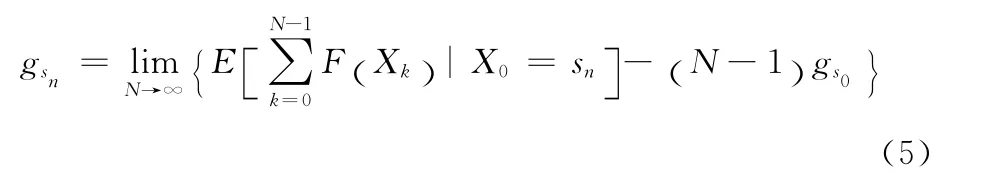
定义在策略π下,状态s相对参考状态sk的性能势
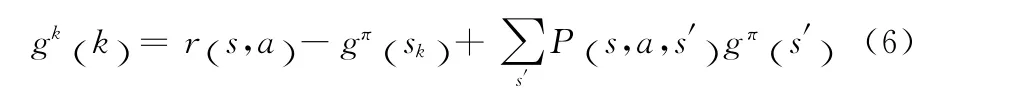
式(6)对于任意s∈S,a∈A 均成立。
性能势的无折扣强化学习算法是一种在策略的G-学习算法,其算法描述如下所示:
算法1:在策略的G-学习算法


2 基于改进的G-learning在RoboCup中的应用
2.1 改进的G-learning算法
在传统的G-learning中,算法强调的是单个智能体在复杂环境中的学习过程,该算法并不能直接将G-learning应用到多智能体系统中,所以有必要对原有的算法进行改进。改进的思想是把算法应用到多智能体环境中,考虑到其它智能体的势函数对当前智能体的影响;改进的目的是当智能体在选择动作的时候,能够考虑到其它智能体的行为对其决策的影响。智能体在策略π下进行学习,参照相对参考状态g (s0)不断改变G (s, a) 。设智能体共有k个,则γ=[γ1,γ2,…γk]T表示k 个智能体学习的权值。则G可表示为式(10)

根据bellman最优化定理,结合式(7)和式(8)的最优策略为

由式(9)来确定智能体应当采取的下一个动作,其中τ(s, a,s′) 为两次状态的停留时间。
2.2 仿真实验
机器人足球已经被成功地作为国际化竞技的基础和研究的一项挑战,它是一个完全分布式的多主体域。但这里有隐藏状态,每个智能体在任意给定的时刻里只能拥有部分世界观。智能体还有噪音传感器和执行器,他们不能准确的感知世界,同样他们也不能完全影响世界。沟通的机会也是有限的,因此智能体必须实时地做出决定。这些特性决定了模拟机器人足球是一个现实的富有挑战性的领域。
本文利用Keepaway-机器人足球的一个子任务进行仿真实验,该平台用于比较不同的机器学习方法。在Keepaway平台中,其中一个球队的keepers试图保证控球在一个有限的区域内,而另一个球队的takers试图从keepers中抢夺控球权,只有当takers从keepers那抢夺到控球权或离开了限定的区域,这个周期结束,下一个周期随之开始。
在RoboCup2D 仿真平台中,每位agent都拥有各自的原子动作,如kick,dash,turn等。而由于2D 仿真平台要求的实时性比较高,在每个决策周期内必须根据当前状态环境做出决策,因此假如每个学习步骤都以原子动作作为学习对象,必然影响决策时间,因此本文引入SMDP概念,首先根据原子动作建立宏动作指令[11]:
HoldBall():保持持球,尽可能在距离对手较远的未知保持控球;
PassBall-:传球,将球直接传给keeper(k);
GetOpen():跑位,移动到距离对手有一定空间的未知,并根据当前球的位置创造传球的机会;
GoToBall():截取一个运动着的球或移动到静止的球;
BlockPass(k):移动到持球keeper和keeper(k)之间;
Shoot():在适当的情况下射门。
在学习过程中,场上的状态描述我们主要考虑一下几个方面:
ball_pos():球的位置;
ball_distto_goal():球离球门的距离;
mate_pos():该变量为一队列,存储队友的位置信息;
opp_pos():该变量为一队列,存储对方球员的位置信息;
球员的Keepaway的技能对于整个足球机器人比赛问题的求解也是非常有用的。Keepaway可看成一个MDP过程,每个队员只负责整个决策过程的一部分。每个队员都是独立地同时进行学习。在本文的仿真实验中,选择了如图1所示的3个典型的前场进攻场景,场景中防守方为agent2d底层,以这些场景开始,直到出现进球、球离开限定区域或者场景执行时间超时,终止当前场景训练,选取新的场景并分别以3 个不同点(52.5,0.0)、(47.5,0.0)、(35.0,0.0)作为参考状态对象分别运用传统R-learning和改进的G-learning 进行训练。在学习过程中,初始学习率默认值为1,并按照进行更新。每个场景限定执行1500个仿真周期,按照服务器规定每个周期为100ms,每50个场景统计一次进球数,进球变化情况如图2所示。
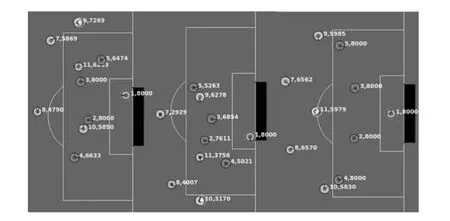
图1 训练场景
从图2可以看出,本文所采用的G-learning算法的训练效果明显优于R-learning。算法在学习过程中采用不同的参考状态,发生频率高的状态(47.5,0.0)在650 个训练场景后开始收敛,而R-learning则是在接近1000个训练场景后才开始收敛。从进球数看,应用R-learning算法的整体进球数低于G-learning算法的球队进球数,并且在收敛的初期仍有震荡,从侧面说明了R-learning的敏感性。本文的算法收敛速度比R-learning快,整体算法稳定。从训练结果看,本文的算法在收敛速度和收敛的稳定性上均优于传统的R-learning。
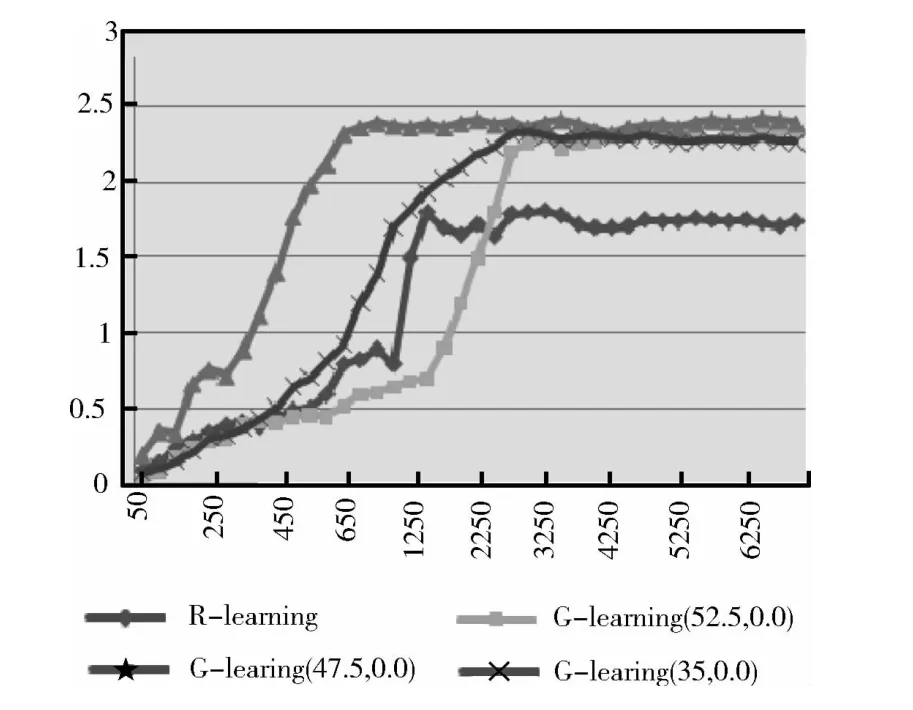
图2 运行场景目数与进球的关系
通过学习,把R-Learning与改进后的G-Learning代码应用到广东工业大学的仿真2D 球队GDUT_TiJi中,并分别与RoboCup2012世界赛的冠军Helios、亚军WrightEagle和agent2d底层进行了100场比赛,结果见表1。
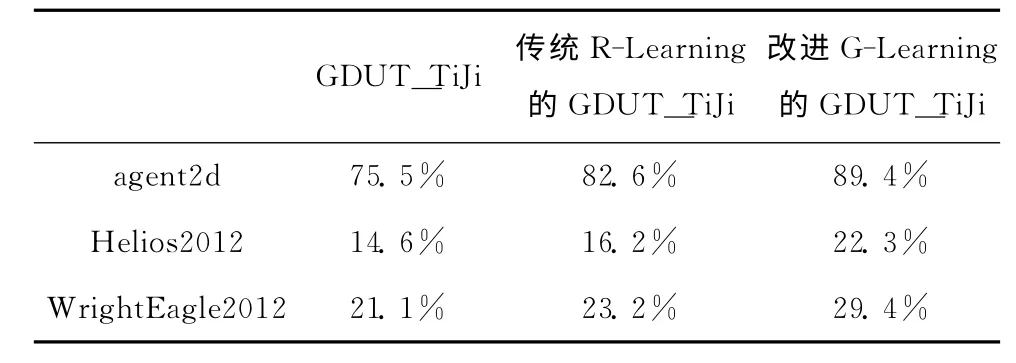
表1 仿真比赛统计结果(胜率)
3 结束语
针对在非确定性SMDP中的多智能体系统里,本文基于传统的性势能理论和平均强化学习提出了基于多智能系统的G-learning算法。该算法使用参考状态的性势能函数代替了R-learning中的平均奖赏值,同时还考虑团队决策对智能体决策的影响,使智能体做出最有利于团队的决策。仿真实验表明,通过大量情景的学习,验证了改进后Glearning算法的比传统的R-learning效果更好,而且不同的参考状态对G-learning的算法性能也会产生影响。从实验可以看出,选择发生频率高的状态作为参考状态,算法的收敛速度将会得到提高。运用改进后的G-learning后,广东工业大学的仿真2D 球队GDUT_TiJi在比赛中的效果也得到了提高。从实验仿真结果上可以看出,该算法存在收敛时间长、学习量大问题,是进一步研究的重点。
[1]Szepesvari C.Algorithms for reinforcement learning:Synthesis lectures on artificial intelligence and machine learning [M].San Rafael:Morgan&Claypool Pulishers,2009:2-3.
[2]Chatterjee K,Majumadar R,Henzinge A T.Stochastic limitaverage games are in exptime[J].International Journal in Game Theory,2007,37 (2):219-234.
[3]Tadepalli P,D OK.Model-based average reward reinforcement learning [J].Artificial Intelligence,1998,100 (1-2):177-224.
[4]GAO Yang,ZHOU Ruyi,WANG Hao,et al.Research on the average reward reinforcement learning [J].Chinese Journal of Computers,2007,30 (8):1372-1378 (in Chinese). [高阳,周如益,王皓,等.平均奖赏强化学习算法研究 [J].计算机学报,2007,30 (8):1372-1378.]
[5]Sun T,Zhao Q,Luh P B.A rollout algorithm for multi chain Markov decision processes with average cost[J].Positive Systems,2009,389:151-162.
[6]Yanjie L.An average reward performance potential estimation with geometric variance reduction [C]//31st Chinese Control Conference.IEEE,2012:2061-2065.
[7]Cao X R.Stochastic learning and optimization:A sensitivitybased approach [J].Annual Reviews in Control,2009,33(1):11-24.
[8]Munos R.Geometric variance reduction in Markov chains:Application to value function and gradient estimation [J].Journal of Machine Learning Research,2006:413-427.
[9]CHEN Xuesong,YANG Yimin.Research on the reinforcement learning [J].Application Research of Computers,2010,27 (8):2834-2838 (in Chinese).[陈学松,杨宜民.强化学习研究综述 [J].计算机应用研究,2010,27 (8):2834-2838.]
[10]ZHOU Ruyi,GAO Yang.A undiscounted reinforcement learning base on the performance potentials [J].Guangxi Normal University (Natural Science),2006,24 (4):58-61(in Chinese).[周如益,高阳.一种基于性能势的无折扣强化学习算法 [J].广西师范大学学报 (自然科学版),2006,24 (4):58-61.]
[11]ZUO Guoyu,ZHANG Hongwei,HAN Guangsheng.A reward function based on reinforcement learning of multi-agent[J].Control Engineering,2009,16 (2):239-242 (in Chinese).[左国玉,张红卫,韩光胜.基于多智能体强化学习的新强化函数设计 [J].控制工程,2009,16 (2):239-242.]
猜你喜欢
纺织科学研究(2021年9期)2021-10-14 08:52:10
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34
小学生作文(低年级适用)(2018年3期)2018-04-17 00:58:35
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
少年博览·小学低年级(2017年4期)2017-06-09 16:22:28
作文评点报·低幼版(2017年7期)2017-03-11 20:49:41
家庭百事通(2016年3期)2016-03-14 08:07:17
山东青年(2016年3期)2016-02-28 14:25:52
少儿科学周刊·少年版(2015年4期)2015-07-07 20:56:37
