
后端实现时几种减小时钟延迟的有效方法
2014-12-05 02:01:30顾光华张海平何志伟
电子与封装 2014年3期
顾光华,张海平,何志伟
(中国电子科技集团公司第58研究所,江苏 无锡 214035)
1 引言
随着现代嵌入式芯片设计的芯片功能及复杂性的不断提高,需要实现更高的时钟频率、更多的时钟域及更复杂的时钟结构。现在的工艺尺寸可以缩减到65 nm、40 nm或更小,先进的工艺技术可提高集成电路器件集成度及生产出更大的芯片尺寸,但这同时意味着时钟网络的负载越来越重并可能穿过更长的距离。因此,芯片时钟的不确定性和时钟延时会变得更为可观,芯片的时序收敛也成为一项艰巨的任务。例如,台积电的65 nm低功耗设计标准如下:
WC corner(setup check):set_timing_derate from 0.95 to 1.0
BC corner(hold check): set_timing_derate from 1.0 to 1.1
假设时钟频率为800 MHz,时钟周期1.25 ns,如果时钟延时较大(如500 ps)则占用的时钟比例较大,有可能达到时钟的50%左右。这种情况下建立时间和保持时间很难满足,时序很难收敛,芯片的功能也基本无法实现。所以,最大限度地减少时钟延时实现更小的时钟漂移,对于设计频率较高的集成电路至关重要。本文将介绍在不同转换率的输入输出单元、大负载电容端口和来自不同时钟域的时钟网络情况下怎样处理可以实现较小时钟延时的时钟网络。
2 不同转换率的输入输出单元
在大多数情况下,系统时钟是由输入输出单元产生的,如晶振等,这样的输入输出单元的时序特性会影响时钟树的综合结果。输入输出单元根据不同的负载会产生不同转换率,在时钟源产生时钟上升漂移和时钟下降漂移,由于它是时钟源,这种漂移会通过时钟网络传播。然而,时钟树自动综合时会试图插入缓冲器或反向器来平衡这些漂移。这些插入单元会使时钟延时变大。
为了避免这个问题,应根据实际情况,选择合适转换率的输入输出单元,但实际情况是很难找到一个完美的输入输出单元。图1对应的是一个晶振输入输出单元的时序参数,从时序表可以发现,存在约300 ps的上升沿和下降沿的延迟差异。
这种延迟的差异将通过时钟网络传播,为了防止这种非对称的传输延迟的时钟根,时钟源定义点应移至输入输出单元的输出引脚。例如,时钟源应该定义如下:
Create_clock -name xclk-p 30-waveform {0 15}[get_pins {IO_xclk/XC}],而不是Create_clock -name xclk-p 30-waveform {0 15} [get_ports{IO_xclk}],这样可以使时钟延时更小。
3 大负载电容端口
某些宏模块(IP)端口的输入电容是非常大的。输入电容由两部分组成,一部分是固有电容,其可以通过时序表查表得到,而另一部分是端口相邻的信号线寄生效应产生的耦合电容。如果端口的尺寸很小,这种耦合电容是很小的,外在耦合电容的影响可以忽略不计。然而,如果pin的图形很大,耦合电容将变得不可忽略。这种情况在端口图形被走线指引覆盖时表现得更为显著,如图2所示。
由于走线指引代表隐藏的某层金属走线,在寄生参数提取时,自动布局布线工具将自动识别这些“虚拟信号线”,整条走线指引将被视为较粗的金属走线。因此,在宏模块端口上将产生一个较大的耦合寄生电容。相对于宏模块端口的固有电容,这个耦合电容必须考虑,但大多数情况下,走线指引区域的金属走线密度不是特别高,这种寄生模型提取的寄生电容耦合电容值偏大。这种高估的耦合电容会导致较长的时钟延时。自动布局布线工具综合时钟树时会插入缓冲器去修复如大电容、最大过渡及大扇出错误,这些额外插入的缓冲器会增加时钟延时。而时钟自动综合工具会去平衡各个分支的时钟,从而导致整个时钟延时变大。

图1 OSC时序特性
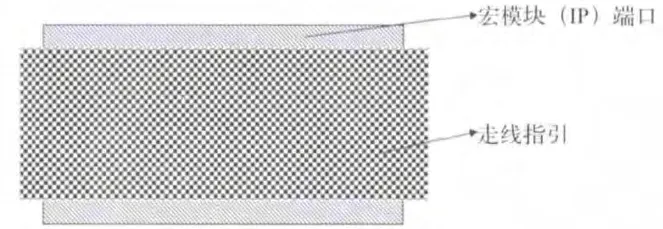
图2 宏模块端口和走线指引示意图
合理的解决方案是根据时序报告在宏模块端口附近插入一个合适驱动能力的缓冲器,将宏模块端口从整个时钟网络分离出来,根据这个缓冲器的真正延时得到一个比较准确的时钟延时。
4 来自不同时钟域的时钟网络
4.1 多时钟域设计
在现代嵌入式芯片设计时,多时钟域是很常见的,不同时钟域是相互独立的,但有可能时钟源又存在着某种联系,如图3所示,CK1、CK2…CKn是相互独立的时钟域,不需要同步,而对于各个时钟所管的各功能模块则需要同步,这种设计的好处是能提供各种不同频率的时钟使芯片的各功能模块工作在最佳状态。

图3 时钟网络图
4.2 同步时钟域的时钟网络
不同时钟域的时钟网络可能是由相同的时钟源衍生出来的,自动布局布线工具时钟树自动生成时会去插入缓冲器/反相器以平衡整个时钟网络,但实际情况可能是这些衍生的时钟群之间没有任何数据交流,没必要去整体全局同步。
如图4所示,有两个时钟域,xclk和pll_clk,在xclk时钟域,adc_clk和sscg_clk之间没有数据交流,所以adc_clk和sscg_clk没必要同步,而对应pll_clk时钟域,vd_mem_clk、lvds_mem_clk和pll_clk、sys_clk、cpu_clk、afe_clk、video_clk、vd_clk、lvds_clk及lvds_ip_clk之间也没有数据交流,即vd_mem_clk、lvds_mem_clk和pll_clk域别的时钟群是异步的,不需要去整体平衡。建议处理方式是在编写时钟树定义文件时将vd_mem_clk和lvds_mem_clk从pll_clk域独立出来,用去除pll_clk时钟域来去掉自动生成的时钟树。
从上面的分析中可以看出,对于多时钟域的同步一定要分析清楚电路结构,清晰地分解各个时钟树模块的数据交流情况,划分出各个时钟的边界,准确地定义出时钟树文件,将不需要同步的时钟从时钟源域独立出来才能自动综合出较小延时的时钟网络。

图4 时钟结构图
4.3 时钟域重叠
在某些设计中,不同的时钟域有一些共同的路径,即时钟域重叠。如图5所示,cpu_clk域的分支和test_clk域的分支有重合部分,时钟到达不同时钟分支的延时分别为1.1 ns、1.2 ns和2.5 ns,为了平衡各个时钟分支,自动时钟树综合时插入相应的延时单元,可能产生如图6的时钟网络,这样的结果一般不是设计者想要的结果,因为在cpu_clk分支分别插入了0.9 ns和0.8 ns的延时,是一个有较大时钟延时的时钟网络。
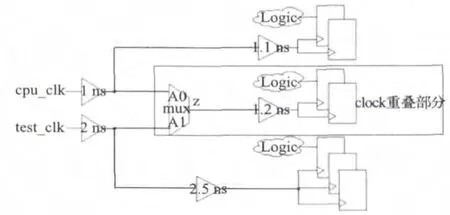
图5 不同时钟域重叠

图6 CTS后clock时序图
更合理的解决方法是先自动综合cpu_clk,然后再自动综合test_clk。一般cpu_clk的时钟频率比test_clock的时钟频率高很多,cpu_clock路径延时较小,需要优先去平衡。如图6所示,在cpu_clk上面一条时钟分支插入0.1 ns就可以平衡整个cpu_clk域,自动布局布线工具在时钟树自动综合完cpu_clk后再去自动综合test_clk,自动布局布线工具会发现时钟重叠部分已经做过时钟树而对公共部分不做任何延时处理,为了同步test_clk,在test_clk上面时钟分支插入1.3 ns的延时,如图7所示,这样产生的时钟网络才是更优化的时钟网络。
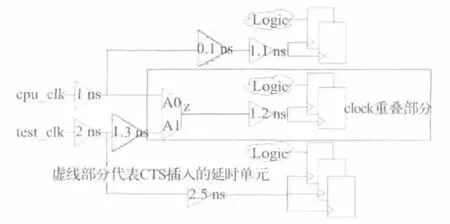
图7 优化的时钟网络
4.4 时钟树自动综合前已经存在的延时单元
在做时钟树自动综合之前,可能时钟网络已经存在一些不必要的缓冲器或反相器,延长了整个时钟网络,对于这些单元最好的方法是找到它们并删除掉。
4.5 缓冲器时钟网络和反相器时钟网络
在时钟树自动综合时,选择合适的延时单元也很重要,合理的延时单元能有效减少时钟延时。时钟树的构建主要有两种形式,一种是基于缓冲器的时钟网络,而另一种是基于反相器的时钟网络。如图8所示,缓冲器是由两级反相器产生的,而且一般前一级晶体管的宽长比小于后一级的宽长比,所以对于相同输出驱动能力的缓冲器延时单元和反相器延时单元,缓冲器的输入负载电容比反相器的输入负载电容小一些,相对应前级时钟延时单元影响较小,更容易修复大电容问题。另外,反相器需要成对使用,相对于缓冲器时钟网络会增加时钟网络的级数。
另一方面,对于缓冲器时钟网络,由于缓冲器的两级反相器是直接相连,且两级反相器组成的缓冲器前后级的驱动能力是不一致的,这样会导致整个时钟网络的延时单元驱动不一致,使时钟网络的占空比变化。而反相器时钟网络在这一方面有更大的优势,所以一般在选择时钟树类型时需权衡电路特性,看哪种时钟网络结构特性更容易满足电路设计的需要,一般推荐使用反相器时钟网络。
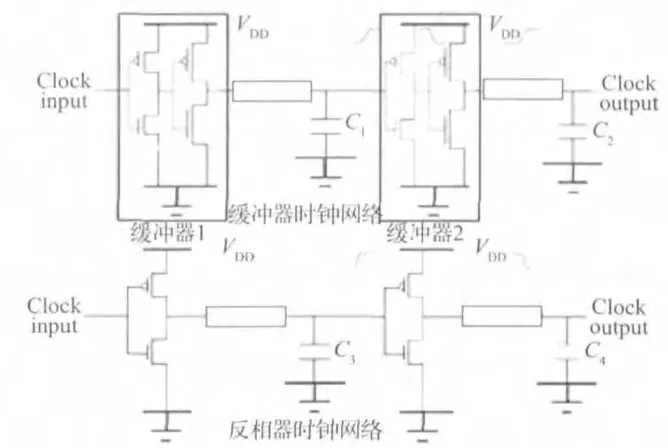
图8 缓冲器时钟网络和反相器时钟网络
5 结论
在现代高速嵌入式芯片的后端实现过程中,尽量减小时钟延时,有助于快速实现时序收敛,有助于设计出更高时钟频率的芯片。本文提到了几种在集成电路时钟树自动综合过程中很可能经常碰到的情形及常用的解决方法,通过这些手段可以使自动布局布线工具自动综合出时钟延时比较小的时钟网络,如不采用以上常用方法让工具自动去综合时钟树,一个实际可以达到800 MHz频率的时钟网络可能由于时钟树的延时不当而只能工作在630 MHz。采用以上方法可以自动综合出达到设计要求时钟频率的时钟网络。
[1] 拉贝. 数字集成电路设计透视[Z]. 清华大学,2007.
[2] 沃尔夫. 现代VLSI系统[Z]. 美国,2005.
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
轻兵器(2022年3期)2022-03-21 08:37:28
中国农业信息(2021年3期)2021-11-22 06:44:48
铁道车辆(2021年4期)2021-08-30 02:07:14
塑料包装(2019年6期)2020-01-15 07:55:46
电子制作(2016年15期)2017-01-15 13:39:08
中国公共安全(2015年15期)2015-12-24 09:15:14
印制电路信息(2015年11期)2015-10-24 01:28:12
河南科技(2014年15期)2014-02-27 14:12:36
电子设计工程(2014年19期)2014-02-27 12:00:54
