
数据驱动决策系统:大数据时代美国学校改进的有力工具 *
2014-11-28 07:57:51傅泽禄
中国电化教育 2014年7期
王 萍,傅泽禄
(1.华南师范大学 文学院,广东 广州 510631;2.广东科学中心,广东 广州 510006)
数据驱动决策系统:大数据时代美国学校改进的有力工具*
王 萍1,傅泽禄2
(1.华南师范大学 文学院,广东 广州 510631;2.广东科学中心,广东 广州 510006)
大数据时代如何有效地利用数据形成决策的洞察力是当今教育研究领域倍受关注的话题。随着信息技术的发展和对学生学习评价的需求不断增加,美国各学区已逐渐接受了数据驱动决策系统,并将其作为支持学校改进的工具。为了让我国教育工作者全面了解这一新型工具,该研究在明确数据驱动决策的概念及其产生背景的基础上,对数据驱动决策系统的基本要素、实施步骤进行了说明,并以美国纽约教育局为例分析了该系统在实践中的应用和面临的挑战。研究表明,数据驱动决策系统有助于学区和学校领导利用数据制定一个用于持续改进的蓝图。了解这一工具并反思我国的教育现状,对推动我国利用数据提升学校教育质量的研究具有重要意义。
大数据;数据驱动决策系统;学校改进
自计算机和网络进入教育应用以来,以信息化技术对数据进行分析来驱动决策的努力就已开始。决策可以由三种方式分别或混合驱动:直觉、经验和逻辑。虽然有时直觉和经验在决策过程中是无可替代的,但通过逻辑方式做出决策通常被认为具有高确定性的特点,更易于被接受。数据是填充逻辑过程的基石,大数据正在改变决策的驱动方式,由直觉和经验驱动决策开始向数据驱动决策(Data-Driven Decision Making, DDDM)转化。数据驱动决策在当今美国教育研究领域倍受关注。2010年美国国家教育统计中心指出,近5.16亿美元的联邦资金用于发展各州的技术基础设施,其中包括通过州级纵向数据系统(the Statewide Longitudinal Data System, SLD)资助项目来支持学区基于数据驱动决策的信息技术基础设施[1]。当前数据驱动决策系统已成为美国各学区利用数据支持学校改进的有力工具。那么什么是数据驱动决策?它是怎样产生的?数据驱动决策系统包括哪些基本要素?其实施步骤是什么?在实践中是如何应用的?利用数据驱动决策系统改进学校会面临怎样的挑战?这些正是本文所要探讨的问题。
一、数据驱动决策及其产生的背景
2013年,福斯特·普罗沃斯特(Foster Provost)和汤姆·福塞特(Tom Fawcett)在《数据科学与大数据、数据驱动决策的关系》一文中将数据驱动决策定义为“基于对数据的分析,而不是仅仅依靠直觉进行决策的实践”[2]。在教育领域中应用数据驱动决策这一概念是模仿工业和制造业的全面质量管理、组织学习和持续改进等成功做法。这些做法强调组织改进是通过对不同类型的数据作出迅速反应而得以提升的。这些数据包括诸如材料成本之类的输入数据,诸如生产速率之类的过程数据,诸如缺陷率之类的结果数据以及包含员工和顾客意见的满意度数据[3]。数据驱动决策在教育中是指收集、分析、报告和使用数据用于学校改进的过程[4]。在对学区利用数据驱动决策系统作为学校改进工具的报告中,美国学习点协会(Learning Points Associates)强调“在利用数据改进决策之前,重要的是理解数据究竟是什么?”数据的操作性定义是指学区和学校领导使用的多种信息和知识资源,例如有关学生年级水平、人口、语言熟练度、国家标准评价、真实性评价、教师自编测验、教学实践、作业和年级平均成绩等[5]。
在美国,学校收集数据已经几十年,然而许多学区或学校管理者直到最近才发现数据在学校改进方面的力量。近期大家对数据的关注是由“不让一个孩子掉队”(NCLB)法案所引发的。随着技术的最新进步和对学生学习评价的需求不断增加,许多学区或学校管理者发现数据的作用已远远超出了NCLB的报告要求。如今全国各地具有超前意识的学区开始采用数据驱动决策系统,不仅要分析测试分数和学生成就,还要分析如何缩小学生之间的成绩差距,提升教师素质,改进课程,分享学校和学区的最佳实践,与关键利益相关者更有效地沟通教育问题,促进家长在教育过程中的参与以及加强与教育团体的对话。无论人们是否同意立法的范围和意图,NCLB已将全国各地对教育数据的重视提升到了一个新水平。
由于NCLB,现在学校管理者需要负责监控并改善学生的表现,提高教师的教学效率。这种报告通常需要一个用于数据收集和分析的复杂系统。为了推进NCLB,各州和大部分学区都需要安装某种形式的数据管理系统。然而,普通的系统通常是由一部分通过各种接口松散连接的电子表格、数据库和纸质报告组成的,难以全面、综合地对数据进行检索和分析。今天许多学区都将NCLB作为推进数据驱动决策的催化剂。这些学区使用数据驱动决策完善其技术基础设施,使数据收集和分析程序正规化,并且要求基于数据,而非假设做出明智的决策。例如,许多学区都面临着紧张的预算和有限的资源,不得不作出削减项目的艰难决定。因为安置了数据驱动决策系统,管理者可以快速、轻松地分析出学生参加这些项目与其他诸如学生出勤、纪律事件和学生成绩等指标之间的相关性,从而清晰地了解每个项目的有效性。当被迫要削减这些项目时,管理者就可以根据实时的事实和数字,而不是情感或假设来淘汰某些无效的项目[6]。
总之,如果没有一个正式的数据分析系统,各个学区往往无法发现和解决发生在学校层面的关键问题。由数据引发的反馈可以帮助学校确认是否在正确的轨道上行进,以提高学生成绩,同时了解进展的快慢。数据驱动决策为学校提供了学区、教师、学生和家长可以访问大量信息的路径。今天学校可让关键决策者利用数据作出更明智的决策,从而提升学校的整体性能,提高学生成绩。
二、数据驱动决策系统的基本要素
随着数据仓库技术和数据挖掘技术的发展,进一步有效地利用数据形成决策的洞察力成为可能,数据驱动决策系统得以发展。一个全面、综合的数据驱动决策系统是通过数据提取、转换和加载(Extraction, Transformation and Loading Tool, ETL)工具将来自不同数据源的数据合并到数据仓库里的。然后利用数据分析工具进行分析和处理,将数据转化为知识,最后利用决策支持工具和诸如需求评估、专业发展和培训之类的咨询支持服务,帮助相关人员基于数据作出决策,如下图所示。学区可以根据自己的具体需要和预算考虑,选择实施这个系统的全部或部分,用以支持学校改进。下面对这个系统的基本要素进行具体介绍。
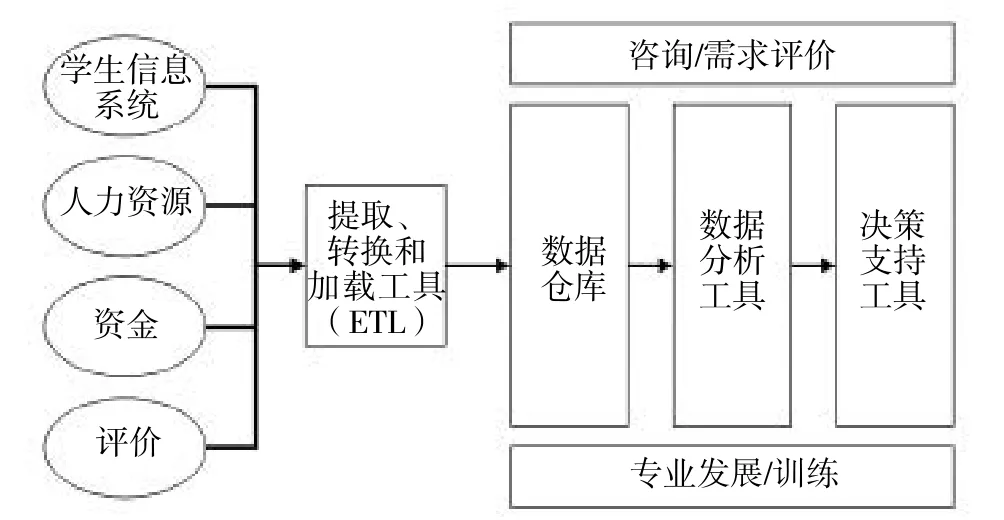
数据驱动决策系统的基本要素[7]
(一)多样化的数据来源
决策支持多样化的数据来源。这些多样化数据来自学生信息系统(Student Information Systems,SIS)、人力资源(Human Resources,HR)、资金以及评价等不同功能的数据库。其中,评价数据库中涵盖了从国家测验、基准评价到基于学校或课堂层面开发的专业测验的所有测试数据。
(二)数据提取、转换和加载工具
数据提取、转换和加载工具(ETL)是数据库和数据仓库之间的接口。该工具将从各种异构数据源中抽取数据,并按照预先设计好的规则进行转化清洗,处理一些属性难以统一规范的数据、冗余数据、错误数据或者是异常数据,目的是让用户对问题进行补救并维护数据质量,最后再将数据加载到目标数据仓库中。这是建立数据仓库的必要基础。
(三)数据仓库
数据仓库是在数据库已大量存在的情况下,为进一步挖掘数据资源、为决策需要而产生的,它并不是所谓的“大型数据库”。数据仓库是一个专门的中央储存器(Central Repository),用来保存从多个数据库经ETL工具选取的已有数据,并为上层应用提供统一的用户接口,用以完成数据查询和分析[8]。一个精心设计的数据仓库可用作一个强大的数据驱动决策系统的基础层。数据仓库主要是研究和解决从数据库中获取信息的问题。
(四)数据分析工具
数据分析工具是推动数据驱动决策系统的“引擎”。这是一个用户界面友好、非隐秘的报告分析工具,其职责是对驻留在各种数据源或数据仓库中的信息进行挖掘、预测和分析。它通常提供一个集成报告工具,让用户能实时地、预先格式化地定制报告,从而让那些最需要利用其加快分析和改进工作的人得到数据。工作人员可以在短短几分钟内对一个主题进行详细分析,调查其他原因或相互关系,从各个角度分析结果。
(五)决策支持工具
在数据处理方面,最大的难度就是对信息处理的不完全和不规范化。而且这些数据有时会有一些不肯定的性质,使得人们很难做出判断。决策支持工具的作用就是对大量数据进行深入、详细的了解和分析,然后进行推测。决策支持工具需要通过建议并描述正确的措施来进一步推动分析,以帮助管理者和教育者重视数据分析工具所强调的问题。该工具通过为管理者、教师和工作人员提供建议、实时警报和自动化行动,创建了一种持续改进的文化氛围。
(六)咨询支持服务
许多提供数据驱动决策系统的供应商还提供诸如需求评价(Needs Assessment)、专业发展和培训之类的咨询支持服务。有了需求评价,供应商就可直接与学区一起对技术、基础设施、数据、前期的教育组织目标进行确认,并提供一个虚拟的实施路线图。实施过程开始时,重要的是确保系统用户能学会运用合适有效的策略,以利用数据支持并促进学生学习,从而实现更高的运营效率。有些供应商还会提供专业发展和培训服务,将其作为数据驱动决策包的一部分。起初寻找这些可提供数据驱动决策系统的供应商看起来很困难。美国研究中心发表了一份名为《学生正处于危险之中的教育》(the Education of Students Placed At Risk)的报告。这份报告概述了一个学生数据分析系统应具备的所有特征,同时指出尽管没有一个单独的供应商能提供具备所有这些特征的系统,但管理员还是应确认那些对学区而言最重要的特征,然后基于这些所确认的需求来选择一个供应商[9]。
三、数据驱动决策系统的实施步骤
就最基本的形式而言,数据驱动决策主要是收集合适的数据,以有意义的方式分析数据,让有需要的人能获取数据,利用数据提高学校效能和学生成绩,最后与关键利益相关者沟通数据驱动决策。虽然各学区的需求和资源可能会有所不同,但一般来说实施一个数据驱动决策系统需要以下五个基本步骤。
(一)数据收集与审核
在实施数据驱动决策系统之前,学区或学校领导应具有收集数据的广阔视野,收集多种类型的数据,而不是仅仅收集高利害测验数据,用以满足接受联邦资金或达成NCLB所需的年度进步(Annual Yearly Progress, AYP)的管理要求。因为当涉及到学生的学习问题时,任何单一的测验都无法完全显示国家或地方标准及课程所规定的有关学生能理解什么,能做什么的全景。一旦学区确定好了收集数据的范围,下一步就是进行审核,确认已收集的数据并判断不同的数据源能否兼容。如果无法兼容,学区应查找影响数据兼容的因素。随后,学区有必要确认所需的额外数据。为了确认额外数据,可以采取数据收集的多维方法。可以进行创造性思考,超越传统的事务型数据库的范围,同时收集量化数据和质性数据。其中,质性数据源包括对教师、学生、家长的访谈和问卷调查、教师日志、另类评价(Alternative Assessments)等。最后,学区还要决定数据收集的频率,是以每天、每周、每月、每年的频率,还是数年才收集一次?[10]
(二)数据标准化管理
数据收集与审核之后,接着就需要先将数据标准化,再利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。就最简单的形式而言,数据驱动决策就是将数据元素(Data Element)相互关联,并探索影响学生和教师表现的积极因素和消极因素。数据元素是计算机科学术语,它是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。如果收集数据元素的过程还没有被标准化,将数据元素相互关联几乎是不可能的。因此,首先要考虑开发一套适用于整个组织的数据标准。这些基本的标准包括消除用纸系统(Eliminating Paper Systems)、直接向可兼容的计算机系统输入所有数据、用通用键(Universal Keys)来组织数据等。其中,通用键是指全球唯一标识符(Globally Unique Identifiers, GUIDs),在 Windows 系统中称之为 Class ID,缩写为CLSID。对于不同的应用程序、文件类型、OLE对象、特殊文件夹以及各种系统组件,Windows 都会分配一个唯一表示它的ID代码。因此,通用键主要用于数据集成。数据、元数据以及其合成数据都需要具有标识。
同样重要的还有为特定数据元素分配所有权。一个明确的责任链会提高数据质量及其完整性。这也是一个理想的介入时机,在这个过程中对学区的信息系统进行评价,以确定其是否能胜任数据收集和分析。第一选择应是最大限度地利用现有的信息系统。如果不行,那么可能只有去寻找能兼容数据管理的供应商。
需要注意的是,教育机构的技术供应商拥有越来越多的教育数据,因此必须划出一条清晰的底线,明确供应商可以怎样利用这些数据。例如,美国的《家庭教育权利和隐私法案》(FERPA)和《健康保险流通与责任法案》(HIPAA),就有了很清晰的限制,包括禁止将客户的数据用于商业用途。教育客户也声明,不能让供应商获取学生数据用于广告和市场推广中[11]。
(三)数据分析
在美国,教育改革一直都是媒体、政治家和社区利益相关者多年来审查的重点。由于学校改进在教育改革中备受关注,因此对所有收集到的数据进行准确、毫无偏见的解释则显得尤为重要。在进行数据分析时,需要采取一些措施。
1.为系统用户提供在职培训
数据驱动决策需要新的知识和技能。系统用户不仅要了解基本的电子表格和诸如过滤、排序之类的数据库技术,同时还要熟悉诸如因果关系、相关性和数据分解(Data Disaggregation)之类的基本的数据分析概念。系统用户要确保自己选择的供应商能提供这些培训,将其作为数据决策包的一部分。
2.采取一个收集数据的长期策略
当解释数据时,对单一的测验分数做出反应容易出现最常见的错误。为了正确地测量进步和变化,有必要进行纵向测量(Longitudinal Measurement)。纵向测量每年都坚持进行,测量学生在不同时期的在校学习是否取得相对意义上的进步,收集的是纵向数据集(Longitudinal Data)。纵向数据集将学生个体在不同时间的测试成绩联系起来,以供学校和政府用来分析它们在何种程度上有效提高了学生成绩。结合学生的先前成绩,学校和政府将提供“增值”措施。因此,这种方法也经常被称为“增值方法”。
3.进行“下钻”的数据挖掘以寻找实情
数据很丰富,而信息往往很匮乏,数据挖掘的目的是从数据库里挖掘到信息、知识。多维数据挖掘中有“上卷”(Roll Up)和“下钻”(Drill Down)两种方式。其中,“下钻”的数据挖掘过程是一种分解数据的有效方法。它从一般性问题开始,然后将问题“由上而下”地挖掘成更小的部分。这样挖掘得到的数据可能是有益的,但也可能会造成误导。例如,当你将一组数据挖得越深,可以应用的样本就越小,最后得出的结论反而越不准确。因此,要注意不要将数据组挖掘到太小以至于难以得出令人信服的结论的程度[12]。
4.当数据可以应用时就应解释和分享结果
没必要等到收集了所有数据,才开始进行分析。在这个过程的早期,一旦所有信息都可以应用了,学区就可以开始观察可能导致更明智的决策的重要趋势。美国东密歇根大学教育领导学的教授罗恩·威廉姆森(Ron Williamson)曾指出,“数据本身对校长和教师将其用于学校改进目标而言,并不是很有用。只有当数据转化成了信息,这些信息被用来激发有关学校未来方向的对话,数据利用在学校改革中才具有重要意义。”[13]数据分析的实践方面还包括帮助教师和管理人员学会如何解释数据,并在实施中使用最佳资源和策略。
(四)致力于持续改进
越来越多的学校、学区开始使用数据驱动决策系统以保证持续改进。学区如果确认了数据中的关系或差距,就可以采取最重要的一步,即做出改变和解释新策略。无论用于改变的决策是大还是小,做出最明智的决策的关键都是考虑数据的可用性。数据分析没有尽头,学区工作人员只要理解了如何有效地使用数据,那么确认收集、分析数据的新机会就变得越来越容易。学区应继续寻找旧问题的答案,包括新信息,因为还可利用并做出新的、更明智的决策。一旦做出这些决策,确认关系并实施补救措施的过程就又重新开始了。
具有远见的学区会将自己学校的表现与全国其他名列前茅的学校进行对比,在明确差距的基础上,通过借鉴顶尖学校的成功方法或其他改进措施,从而提出行动方法,以弥补自身的不足。这是基准化分析法(Benchmarking, BMK)的体现。若做得好的话,基准化分析法有助于学区了解什么才是有效的,他们使用的关键策略效果如何,哪些改进是可能的或有必要的,以及如何借鉴其他成功学区的最佳实践。
(五)交流结果
要让数据对教师和校长有用,数据必须是可信的。利益相关者必须对数据有信心,相信数据反映了自己学校的实际情况。为了建立公众支持,提升团队信心,一个有效方法是为关键利益相关者展示学校和学区是如何为结果负责的。共享数据时应采用易于阅读的图表和简短、没有术语的报告形式,这样不仅可以让团队成员知道学校是基于数据做出明智的决策,还可以创建团队对公立教育所面临的问题有更深层次的理解。
学区不应仅依靠媒体来传达信息。有限的时间和空间,加上缺乏对完整信息的了解,往往会导致媒体只报告基本事实,而这通常因为没有提供数据背后的细节而产生误解。许多成功的学区直接向其团队报告信息。这种做法是使用一个学校报告卡或年度表现报告。该报告用来指导在不同学校的论坛以及家长、工作人员和学校董事会的会议上有关学生表现和教育优先权(Education Priorities)的讨论。培训教师和校长促进这些协商,以确保每个人都关注数据,关注数据所反映的有关学生表现以及如何改进课堂教学的信息。
四、数据驱动决策系统的应用
那么在实践中人们如何应用数据驱动决策系统?下面以美国纽约教育局(New York City Department of Education,NYCDOE)为例进行具体介绍。
纽约市教育局是美国最大的教育系统,拥有超过100万的学生和8万名教师。长期以来,纽约市面临着一系列阻碍学生成绩提高的影响因素,例如学生总人数中有423694名是由公共资金援助支持的,153134名学生接受了特殊教育服务。其他影响因素还包括高度集中的贫穷、无家可归、种族隔离和药物成瘾、教师和学校领导的高流动频率以及文化断裂、缺乏技术支持等。2001年,纽约市教育局在卡耐基公司的资助下与“成长网络”(the Grow Network)公司签订了为3-8年级开发数据驱动决策工具的协议[14]。该协议涉及到的教师有3万人,学区和学校的教学领导有5千人,以及1200所学校近40万的学生。这展示了纽约市教育局为了提高学校系统多层面的教育决策质量,在将标准化评价数据与支持性的教学资源相链接方面作出了前所未有的努力。
“成长网络”负责发布NYCDOE数据报告,即采用纸质和在线报告的形式向校长、教师和家长出示相关的标准化测试结果,并附有反应行动(Responsive Action)的具体建议。“成长网络”以3-8年级的学生为主体,其目标是使用标准化评价数据,再加上支持性资源和专业发展,用以提高教学实践的质量和学生的学习成绩。“成长网络”最后将提交四种不同的数据报告,这些报告反映的是针对不同目标群的不同观点,如下表所示。
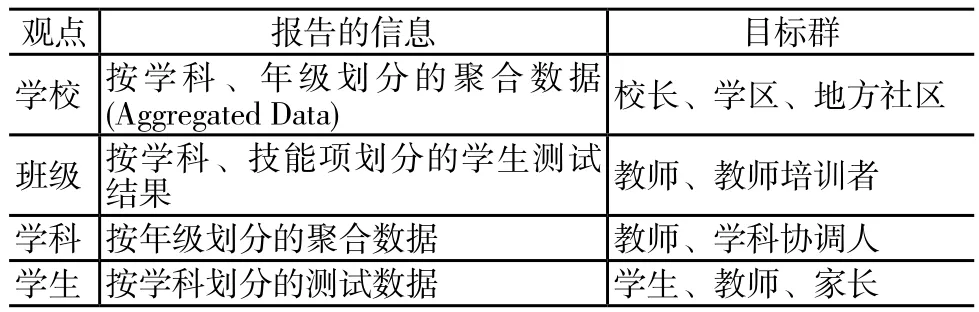
“成长网络”数据报告的观点
“成长网络”为了给最终的报告准备数据,做了大量的数据清洗(Data Cleaning)和处理工作。该系统最终将学生的标准化测试数据组织在为教师、学校领导和家长定制的报告中。对于管理者,报告提供的是有关学校的概述,并展示了班级、教师层面的数据。对于教师,报告提供的是有关班级范围重点(Class-Wide Priorities)的概述,同时将学生按照州立表现标准进行分组,支持教师对学生个体的强项和弱项的关注。对于家长,报告则解释了测试目标,他们孩子的表现以及父母可在哪些方面帮助孩子提高成绩。报告按照分数将数据进行汇总并排名,同时还根据纽约州的表现等级进行分组。表现等级从“远低于标准”(1级)到“远高于标准”(4级)分为四级。
在开学后不久,教育者还会收到一份关于当前学生的分类数据(Disaggregated Data)的纸质报告。由于这些学生的数据被测试区(Test Areas)分解了,教育者同时会获得一个受密码保护的在线帐户,用以访问完整的测试数据。教师可以利用在线信息系统查找并比较学生个体的数据。学生的分类是按照单项测试和技能项来排名并分组的。
除了测试报告之外,及“成长网络”网站还具有两项附加功能,即支持教师的分析和教学决策。首先,网站会提供有关州立标准的信息,及测试技能和概念的定义。管理者和教师经常引用这些资料作为所提供信息的一个重要组成部分。其次,所报告的数据链接了一些为教师、管理者提供的教学材料和资源。为了在课堂层面促进基于标准的学习,这些教学材料和资源提出了一些有关活动和教学策略的建议。报告还链接了经纽约市教育局批准的外部资源,目的在于帮助教师收集更多的课程材料并反思自己的课堂组织。尽管此数据决策系统大部分依靠来自其他资源的现有数据,但是系统的分析组成部分还是提供了按学科、技能项聚集的数据。此外,系统提出了课堂组织的不同模型,例如异构分组、同构分组等[15]。
总的来说,美国纽约教育局这一案例让我们看到了技术和报告功能的进步为学校创造了在教育系统的多层面使用测试数据用于决策的新机遇。在调查中,大部分教师表明及时获得显示学生个体表现的数据,有助于做出因材施教的决策,或者是基于学生在朝向目标专项技能的具体表现进行分组。管理者也指出,“成长网络”有助于他们确认班级层面、年级层面和学校层面的长处和弱项,然后在此基础上做出有关学校计划、教师专业发展活动等方面的决策[16]。
五、数据驱动决策系统面临的挑战
当今实施数据驱动决策系统面临着一系列挑战。这些利用数据驱动决策系统改进学校有待解决的难题也是未来研究的方向。
(一)如何启动数据驱动决策?
万事开头难。学区实施数据驱动决策系统,以支持学校改进所面临的最大挑战之一就是要明确从哪里开始。要克服启动的困难,办法之一是找到整个组织的“数据领军人物”(Data Champions)。许多学区选择了在一个特定学校、项目或学生小组中较小规模地试行数据驱动决策系统。通过展示数据驱动决策系统的成功,让人们能够建立信任,并培养“数据信徒”(Data Believers)。这些信徒应来自系统的各个层面,并表现出对数据驱动决策的热情。他们的热情会迅速蔓延,感染其他同事,营造势头,从而增加学区购买数据驱动决策系统的可能性。这可能需要一定的时间,但对于管理者和其他学区领导人在一起确保全员参与此过程而言是至关重要的。
成功启动数据驱动决策系统还需要以团队的方式,特别是教育局和督学之间的合作。学区的期望应是明确的、可衡量的、可达到的,同时还必须明确个人的作用。在实施数据驱动决策系统的早期阶段,要求学区领导先指出可行之路。督学和学校董事会则必须发挥重要但不同的作用。督学一般扮演的角色是:首先是将学校董事会对学校的愿景转化为基于数据的可测量的目标;然后与学区教师、职员、家长和其他团队的利益相关者一起工作,在规定日期之前完成计划目标;接着收集数据,并显示清晰、稳定的进展;最后在庆祝成功的同时又指出不足,与学校董事会一起修改基于数据的改进计划。学校董事会一般扮演的角色是:首先是建立一个基于数据的学校愿景,显示到目前为止所实现的哪些进步是必要的;然后向管理者、其他员工以及利益相关者阐述如何评价学区的表现;接着通过综述相关数据以评价学区朝向具体目标的进展;最后修正目标和基于数据的改进计划。
(二)如何克服来自数据质量和数据能力的挑战?
对致力于支持所在学区的数据驱动决策系统的领导人而言,还需要克服来自数据质量和数据能力(Data Capacity)的挑战。
对学区和学校而言,提出措施来保证数据质量是至关重要的。数据质量包括:(1)使用多种措施确保相关性,以及从多个数据集进行三角测量的能力;(2)确保数据是很好地组织在一起,并且以一种容易解释的数据来显示;(3)使用已经标准化和净化的准确数据;(4)在数据“保质期”过期之前,让数据对于利益相关者群体而言是有效的;(5)为了分析多个因素,对数据进行分解。没有高质量的数据,利益相关者群体会失去对数据价值的信任,甚至会产生失望。最糟糕的是,教育工作者会使用质量差的数据,即旧的、没有分解的,或是以混乱、错误的方法呈现的数据,然后得出有关学区、学校所需的错误结论。这可能会导致实际上会造成伤害的“数据驱动”行为的发生。
同样,与数据质量紧密相连的数据能力也一样重要。没有访问、理解和使用可利用的数据的能力,不管数据质量的高低,都不会导致有意义的数据使用。事实上没有数据能力,一个组织拥有的数据越多,对数据的处理就越少。如果数据质量是燃料的话,那么数据能力是把燃料转化为能源的“发动机”。数据能力包括:(1)组织性因素,诸如支持数据使用的团队结构、合作规范、明确的角色和职责等;(2)从多个数据源整合数据的技术;(3)以容易解释的形式,让多个用户获取数据的数据访问;(4)数据素养和评价素养技能,这样数据用户就知道如何分析多种类型的数据,并正确地解释结果。
(三)如何创建数据驱动文化?
数据驱动决策对当今的决策管理模式提出了挑战。在数据缺乏的时候,组织内核心管理人员的直觉和经验在决策过程中发挥重要作用。从直觉和经验驱动决策向数据驱动决策转化的过程可能并不顺畅,那些没有足够灵活性来适应大数据趋势、创造数据驱动决策模式和文化的学区也可能会在竞争中失败。信息化系统在大数据分析中可能会强调协作分析和过程公开,这就需要学区创造适宜的数据驱动文化,并把握好直觉和经验驱动决策与数据驱动决策的关系。
数据驱动文化只有在数据质量和数据能力得以保证的情况下才能发展。当组织相信持续改进,并定期把信念付诸实践,就会产生强大的数据驱动文化。具有强大数据驱动文化的学校和学区强调合作是获取成功的基石,同时准许教师和管理者为其所负责的事做出决策。强大的数据驱动文化元素包括:所有利益相关者群体承诺更好地利用数据;清晰界定数据使用的愿景;对教学的效用以及数据在提高教学和学习方面的价值持有信心;通过学校和学区领导调整对数据使用建模;要求教师为教学变化的结果负责;所有层级形成合作文化;致力于教学和项目改进。
当评价学校和学区在何种程度上呈现了数据驱动文化时,需思考的一系列问题包括:是否所有关键的利益相关者承诺为了持续改进而使用数据?人们是否要对数据在学校和课堂层面的使用负责?工作人员之间的合作是否得到了高度重视?学校领导是否将数据驱动决策建模作为其角色和责任的一个重要方面?教师是否相信数据可以而且应该用来告知教学?教师对利用与学生学习有关的数据来改变教学是否持有开放的态度?[17]
六、结语
最近几年,人们对“大数据”的关注越来越多。利用以数据为基础的决策来解决诸多领域问题成为大数据时代的显著特征。对于学校管理者,通过数据驱动决策系统可以查看年级、全校乃至整个学区的学生的学习情况。如果发现低效的课堂和学习表现不佳的学生群体(根据性别、收入情况等划分),管理者会依据学习分析结果决定是否给予特定的干预。对于更大范围的异常表现,管理者会依据学习分析数据调整管理策略,以适应教师更好的教和学生更好的学。美国的实践案例表明,数据驱动决策系统在帮助学区和学校领导利用数据制定一个用于持续改进的蓝图方面表现出其积极的作用。
面对大数据时代的到来,我们的教育工作者如何利用大数据来服务教育,如何把这些大数据信息转化成知识,改革传统教育教学,这将是一个很大的挑战。我国教育大数据的现状是数据流失比较严重。作为学校的信息管理部门,网站的信息数据,学生学籍信息数据,学生每次考试的数据……可以说是扑面而来,但问题是基本上用过就废。虽然教师和学生的许多教育行为数据都可能构成大数据,但是目前我国学校较少采集这些数据,以及对数据进行建模和挖掘。目前学校比较关注的是考试数据,然而即使是考试数据,也没有得到充分利用。在学校考试长期只用考试总分作为甄别学生标准的情况下,客观上就不存在关注详实考试数据的需求。当前学校对校内考试工作的处理,一般都较少收集详实的考试数据,也较少对考试数据作统计分析。由于放弃了通过考试数据的统计关系去发掘考试和考生水平的相关信息,考试基本上也无法发挥对学生学业的诊断作用,教学就缺乏针对性。这种使考试对教学的反馈作用徘徊在低层次、低水平的状态,构成了制约学校教育质量提高的重要因素。因此,如何从学生和教师的教育行为中随时采集数据,如何借鉴国外经验,最大化地利用数据提升学校教育质量成了当务之急。
[1] Ellen B.Mandinach, Edith S.Gummer, Robert D.Muller.The complexities of integrating data-driven decision making into professional preparation in schools of education: It’s harder than you think[EB/OL].http://educationnorthwest.org/webfm_send/1133,2014-02-12.
[2] Irving Wladawsky-Berger.Data-driven decision making: promises and limits[EB/OL].http://blogs.wsj.com/cio/2013/09/27/data-drivendecision-making-promises-and-limits/,2014-02-12.
[3] Marsh, J.A., Pane, J.F., Hamilton, L.S.Making sense of data-driven decision making in education[EB/OL].http://www.rand.org/content/dam/rand/pubs/occasional.../RAND_OP170.pdf,2014-02-12.
[4] University of New Mexico College of Education.Data-based decision making for student success[EB/OL].http://coe.unm.edu/uploads/docs/ipd/issue3.pdf,2014-02-12.
[5][10] Guadalupe H.Simpson.School leaders’use of data-driven decision-making for school improvement: A study of promising practices in two California charter schools[D].Los Angeles:the Falculty of the USC Rossier School of Edcucation Doctor dissertation,2011.
[6][7] John Messelt.Data-Driven Decision Making: A powerful tool for school improvement[R].Sagebrush Corporation, 2004.
[8] 何永.一种元数据驱动数据仓库设计与应用[J].科技创新与应用,2014,(2):13-14.
[9] Jeffrey C.Wayman, Sam Stringfield, Mary Yakimowski.Software enabling school improvement through analysis of student data[EB/OL].http://www.csos.jhu.edu/systemics/datause.htm,2014-02-12.
[11] 朱秋蓉.专题:大数据给教育带来了什么[J].广东教育(综合版),2013,(9):68-69.
[12] Jiawei Han, Micheline Kamber, Jian Pei.数据挖掘:概念与技术[M].北京:机械工业出版社,2012.
[13] Union Pacific Foundation.Using data for school improvement[EB/OL].http://www.principalspartnership.com/,2014-02-12.
[14] Light D, Wexler D, Heinze J.How practitioners interpret and link data to instruction: Research findings on New York City Schools’ implementation of the Grow Network[DB/OL].http://www.cct.edc.org/sites/cct.edc.org/files/publications/Grow_AERA04_fin.pdf, 2014-02-12.
[15] Breiter, A., Light, D.Data for school improvement: Factors for designing effective information systems to support decision-making in schools[J].Educational Technology& Society, 2006,9 (3) :206-217.
[16] Light, D., Honey, M., Heinze, J., Brunner, C., Wexlar, D., Mandinach,E., Fasca, C.Linking data and learning-the Grow Network study-Summary report[R].New York: EDC’s Center for Children and Technology,2005.
[17] David Ronka, Robb Geier, Malgorzata Marciniak.A practical framework for building a data-driven district or school[EB/OL].http://www.pcgeducation.com,2014-2-12.
王萍:博士,讲师,研究方向为教育评价、语文课程与教学论(2007kecheng@163.com)。
傅泽禄:硕士,讲师,研究方向为科学教育、教育评价(11318462@qq.com)。
2014年3月30日
责任编辑:马小强
Data-Driven Decision Making System: A Powerful Tool for American School Improvement in Big Data Age
Wang Ping, Fu Zelu
(1.School of Liberal Arts, South China Normal University, Guangzhou Guangdong 510631;2.Guangdong Science Center, Guangzhou Guangdong 510006)
In the age of big data, How to use data effectively to form an insight into decision-making is a more concerned problem in the fi eld of educational research.With the development of technology and the increased demand for assessing student learning,American districts have been gradually accepted DDDM system, and make it as a powerful tool for school improvement.In order to make educators in our country comprehensively understand this new tool, this paper outlines the background of DDDM, the basic elements and steps involved in implementing a DDDM system, and takes NYCDOE as an example to analyze the practical use of a DDDM system and challeges that a DDDM system has faced.Research shows that a DDDM system can help district and school leaders develop a solid blueprint with data for continuous improvement.It will promote the research on elevating educational quality by using data if we understand the tool and re fl ect on the status of education in our country.
Big Data; Data-Driven Decision Making System; School Improvement
G434
A
1006—9860(2014)07—0105—08
* 本文系2011年教育部人文社会科学研究规划基金项目“中学教师课程价值取向及对教学行为的影响研究”(项目编号:11YJA880051)和2012年“solo分类学在构建中小学生学业质量检测体系中的应用”(项目编号:2012ZJK014)项目阶段性成果。
猜你喜欢
汽车实用技术(2022年7期)2022-04-20 11:45:04
纺织科学研究(2021年9期)2021-10-14 08:52:10
房地产导刊(2020年11期)2020-12-28 01:32:30
甘肃教育(2020年14期)2020-09-11 07:57:16
甘肃教育(2020年8期)2020-06-11 06:09:38
铁道通信信号(2019年4期)2019-10-10 03:42:56
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34
读书文摘·经典(2018年7期)2018-07-11 08:09:38
杂文月刊(2017年19期)2017-11-11 07:57:42
通信电源技术(2016年1期)2016-04-16 04:57:31
