
中文分词技术在社会化媒体分析中的应用*
2014-11-27 12:41孟丽李葆青胡玲芳张跃
中国教育技术装备 2014年16期
◆孟丽 李葆青 胡玲芳 张跃
随着社会的发展,社会化媒体(Social Media)已经在网络化环境中被广泛研究。社会化媒体包含交互式的应用和分享交换用户生成内容的平台创建。在过去的十年,社会化媒体迅速发展。通过对它们的建模分析,从这个超越社会沟通的、拥有大量数据的超集中,可以很好地反映并提炼出交往互动者之间的思想动态、行为倾向,甚至某一社交群体的集体策略。因而,本文主要是对社会化媒体分析系统采集的数据,应用中文分词技术进行处理分析,最终得到有用的关键词,为可以提前预测社会群体的交往意向和可能发生的行为结果(比如判定投资或营销群体的兴趣方向、旅游公司和游客动态、特定人群的行为意向、学生群体的思维模式和动机等)提供一定的依据,为后续研究加以干预,或进行行为控制,为达到所希望达到的经济社会运行模式、群体和个人行为以及提高教育教学的可控性奠定一定的基础。
1 社会化媒体
社会化媒体包括平台创建和交换用户生成内容,通常社会化媒体也被称为消费者产生的媒体(CGM)。社会化媒体和传统的媒体有所不同,比如报纸、书本、电视等任何一种媒体印刷成本较高,而社会化媒体在印刷出版方面的成本却很低,但社会化媒体并不是完全不同于传统媒体,它与传统的媒体存在密切的联系。
社会化媒体的形式很多,包括博客、社交网站、虚拟社区等。社会化媒体有七个方面是大家一直关注的:身份、交谈、分享、存在、友谊、名誉及成员。不同的社会化媒体有不同的关注点,像维基百科等合作项目经常关注的是共享及信誉,而在虚拟社区中身份、存在、信誉等备受关注。总之,社会化媒体在人们的生活中发挥着举足轻重的重要。因此,对社会化媒体的分析更具有研究价值。
社会化媒体的定义 学者Andreas Kaplan和Michael Haenlein认为社会化媒体是一组建立在Web2.0技术基础上,允许创建和交换用户自创内容的互联网应用[1],它包含交互式的应用和平台创建,分享和交换用户生成内容,是允许人们撰写、分享、评价、讨论、相互沟通的网站和技术。所谓社交媒体应该是广大网民自发分享、提取、创造新闻资讯,然后传播的过程。社交媒体的产生依赖的是Web2.0的发展,现阶段主要包括社交网站、微博、微信、博客、论坛、播客等。类似的,Toni Ahlqvist等人认为社会化媒体概念包含三个关键元素,即:Web2.0技术、用户自创内容(UserGenerated Content,UGC)以及所产生的人际关系网[2]。
社会化媒体发展 目前,社会化媒体的发展越来越迅速。社会化媒体已经在整个互联网中占据主流地位,根据Alexa网站名称统计数据,当前世界访问量排名前十大网站中,有五个是社会化媒体网站,像Facebook、Twitter、YouTube等社会化媒体网站更可谓风靡全球,家喻户晓[3]。截至2014年5月,Facebook有近13亿的活跃用户,其中包括超过10亿移动活跃用户。目前已经有专门关注娱乐、运动、金融和政治的社会化媒体。
2 中文分词技术
中文分词的概念 中文分词就是将一段或一句中文字序列分成相对独立的词序列的过程[4]。通过分词,可以使句子以单个词语的形式出现,从而使整个句子的语义简单化。
常用的中文分词算法 目前,常用的中文分词算法有基于字符串匹配的分词算法、基于词的频度统计的分词算法、基于知识理解的分词算法,其中,基于字符串匹配的分词算法主要包括最大正向匹配法和最大逆向匹配法。在对社会化媒体进行分析时,笔者所采用的主要是基于字符串匹配的分词算法,所用本文主要对基本字符串匹配的分词算法进行详细的介绍。
基于字符串匹配的分词算法是按照一定的策略将待切分的汉字字符串与一个“充分大”的机器词典中的词进行匹配[5],也就是按照一定的策略在词典中进行对比查找。目前,基于字符串的分词算法主要有正向最大匹配算法及逆向最大匹配算法。
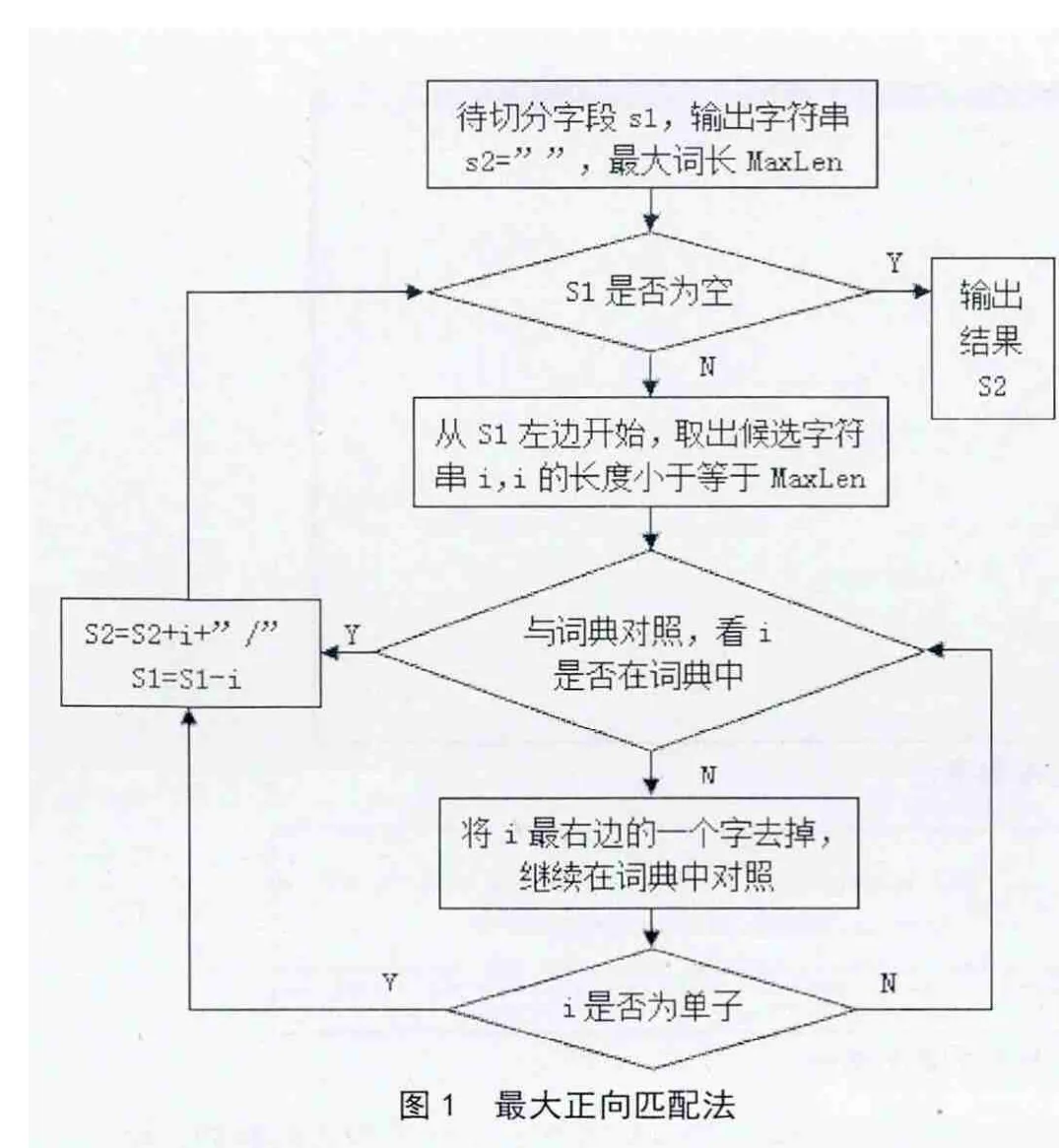
1)最大正向匹配法(Forward Maixmum Matching Method),通常简称FMM,其思想是假定分词词典中的最长词条有s个汉字字符,则用待切分文档的当前字串中的前i个字作为匹配字段,在词典中进行查找。整个算法的思路如图1所示。
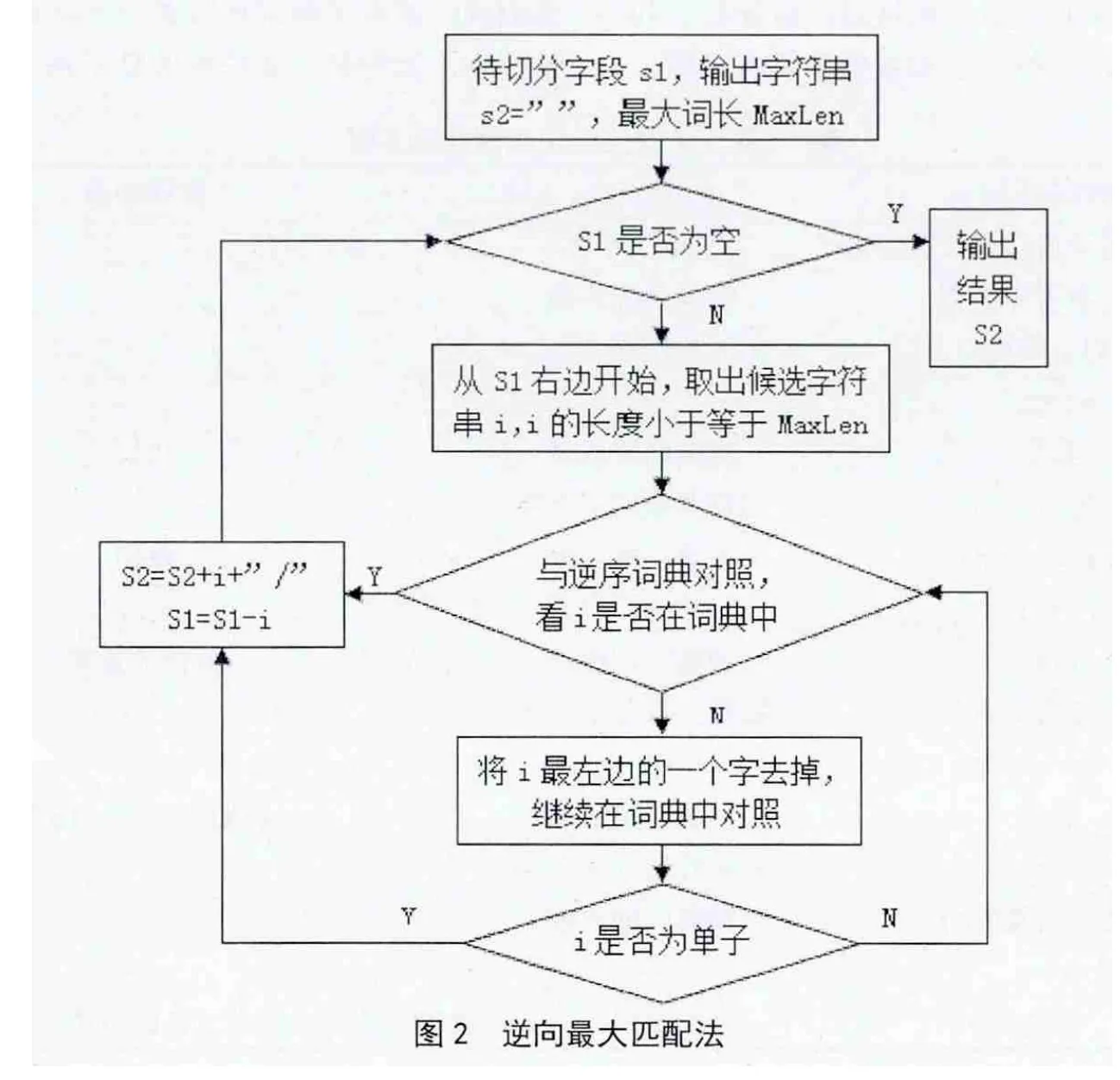
2)逆向最大匹配法(Reverse Maximum Matching Method),通常简称为RMM法,其基本原理与FMM法相同,不同的是分词切分的方向与FMM法相反,一个是从左至右的切分,另一个是从右至左的切分,并且它们使用的分词辞典排序方式也有所不同。其算法如图2所示。
3 中文分词技术在社会化媒体分析中的应用
本文主要是对社会化媒体分析系统采集的数据,采用一定的分词算法进行处理,提炼出关键词,为后期预测社会群体的交往意向和可能发生的行为结果,以及学生群体的思维模式和行为动机等提供一定的依据。
数据采集 本文所用的数据来自项目组成员设计出来的社会化媒体分析系统,采集的是南京大学论坛数据。在该数据采集平台中,数据采集分为网址采集和内容采集两部分。


1)网址采集。先进行网址采集,根据采集到的网址,再采集相应的帖子内容。网址采集最多可分为四级采集,以南京大学论坛为例,南京大学论坛使用二级采集就可以采集到论坛帖子的网址,所有采集都是按照正则表达式来采集。在论坛中有精华帖、分页贴,精华帖需要单独处理,分页贴主要是针对帖子有多页的问题,如上一页、下一页。
2)内容采集。采集到论坛的网址后,根据帖子的网址就可以采集帖子内容。采集到论坛的网址后,根据帖子的网址就可以采集帖子论坛,一般关注的数据主要有标题、帖子内容、发帖以及回帖用户名、帖子存在的时间、帖子的关注度、讨论区等。该数据采集平台如图3所示,采集的数据如图4所示。
分词处理 通过最大正向匹配算法和最大逆向匹配算法,对所采集的数据进行分词处理,为提炼关键词奠定一定的基础。在分词处理的过程中存在近义词和停用词,是近义词的进行合并,是停用词的把它过滤掉,最后只留下关键词,这些关键词通常是名词和动词。在整个数据整理过程中,因为很多论坛中的帖子语言很不规范,语法结构很乱,新词多,所以分词也存在一定困难。

表1 最大正向匹配法实例匹配步骤

表2 最大逆向匹配法实例匹配步骤
1)最大正向匹配法处理实例。从采集的数据中,抽取了部分数据进行分词实验,例如:待切分语句“我们急需提高英语口语及听力水平”,如果在词典中匹配,只要匹配成功就切分出来,那么这一句话切分的结果可能为“我们/急需/提高/英语口语/及/听力/水平”。如果事先知道词典的最长词长,那么将减少很多步骤,从而提高分词速度。此处假设词典中最长词长为7,整个匹配过程如表1所示。
2)最大逆向匹配法处理实例。在对社会化媒体分析平台采用的数据进行分词处理的过程中,除了采用最大正向匹配算法外,还采用最大逆向匹配算法进行处理。例如:待切分句子“求兼职新概念英语老师”,如果在词典中匹配,只要匹配成功就切分出来,那么这一句话切分的结果可能为“求/兼职/新/概念/英语/老师”。在进行匹配时,采用的是逆序词典,假设词典中最常词长为7,整个匹配过程如表2所示。
在分词的过程中,本文主要采用最大正向匹配和最大逆向匹配相结合,但是仍然存在一些问题,如在对歧义词和未登录词进行处理时存在一定的瑕疵。在以后的研究中,笔者会进一步着重处理歧义词和未登录词。
4 结论
通过中文分词技术,对社会化媒体分析系统采集的数据进行处理,为后续关键词检索奠定一定的基础。今后笔者的努力方向是进行关键词检索,对关键词进行统计分析;同时,对分词之后的文本进行特征挖掘及分析,为进一步预测社会群体的交往意向和可能发生的行为结果,以及学生群体的思维模式和行为动机等提供依据。
[1]Kaplan A M, Haenlein M. Users of the world, unite! The challenges and opportunities of Social Media[J].Business Horizons,2010(3):59-68.
[2]World Wide Web[EB/OL].http://www.springer.com/computer/database+management+%26+information+retrieval/journal/11280.
[3]王明会,丁焰,白良.社会化媒体发展现状及其趋势分析[J].信息通信技术,2011(5):10.
[4]曹卫峰.中文分词关键技术研究[D].南京:南京理工大学,2009(6):5.
[5]曹聪聪.中文分词算法研究[D].海口:海南大学,2007(5):15.
猜你喜欢
家庭影院技术(2023年7期)2023-07-14
中华肩肘外科电子杂志(2021年2期)2021-11-30
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
小雪花·成长指南(2016年11期)2016-12-07
地震科学进展(2015年11期)2015-03-28
介入放射学杂志(2014年1期)2014-04-15
外语学刊(2011年3期)2011-01-22
小品文选刊(2009年7期)2009-05-25
