
改进混合特征模型聚类的文本情感分类算法研究*
2014-11-22 02:03邢玉娟李恒杰胡建军王万军
中北大学学报(自然科学版) 2014年1期
邢玉娟,李恒杰,胡建军,王万军
(甘肃联合大学 电子信息工程学院,甘肃 兰州 730000)
0 引言
随着互联网技术的飞速发展,用户通过博客、微博、论坛等方式参与网络信息的交流与传递,导致信息媒体的数量越来越大,网络在线资源数量不断增多.如何在如此庞大的网络数据中快速地提取情感信息并及时对其观点(肯定、否定)进行判定,成为越来越多研究者的研究热点.文本情感分类[1-2]是文本倾向性分析的一个重要分支,它对用户的评论文本的观点进行挖掘,提取出相关信息的情感关键词,然后根据关键词采用一定的判决技术判断出文本所表达的观点(肯定、否定).
G.Salton[3]1975年提出将文档表示为一个向量矩阵,即向量空间模型,该模型将文档数据化,从而可以应用各种机器学习方法对文本进行情感分类.具有出色分类性能的支持向量机(Support Vector Machine,SVM)算法被广泛地应用于文本情感分类领域.Pang Bo[4]以电影评论数据作为仿真实验语料库,对朴素贝叶斯、最大熵和SVM 的分类性能进行了分析比较,实验结果表明SVM 的分类性能优于朴素贝叶斯、最大熵.国内研究方面,周杰[5]等人采用SVM,KNN,RBF 网络等方法,对网络新闻评论数据进行了情感分析,验证了SVM 出色的分类性能.
然而,向量空间模型中的数据包含较多的对分类没有贡献的零值,是一个稀疏矩阵,随着文档长度的增加,VSM 的维度会急剧增大.同时,标准SVM 的训练方法随着样本维度和样本数量的增加,会消耗大量的时间和存储量[6-8].针对这些问题,本文提出了一种混合特征VSM 模型聚类算法,将信息增益(Information Gain,IG)和互信息(Mutual Information,MI)与文档的不同词性特征相结合提取混合特征向量.该方法在对文档特征空间降维的同时,以期提高文本情感分析的效率.根据文档VSM 模型之间的差异度对相似文档进行聚类,从而减少样本的数量,解决SVM 训练速度慢的问题,发挥其出色的分类性能.
1 混合特征提取
文本的词性特征具有出色的多义词汇消岐[9-10]特点,在情感分析和观点挖掘中获得了广泛的应用.基本的词性包括名词(N)、动词(V)、形容词(A)、副词(D)、代词(R)、介词(P)、成语(I)、习惯语(L)和连词(C)等.本文由于考虑到向量空间模型维数的问题,因此只选择情感色彩较强的名词(N)、动词(V)、形容词(A)、副词(D)[11].我们将词性组合“N+D+A”定义为一类特征,“D+A”定义为二类特征,“A”定义为三类特征.由于这三类特征在文档中出现的次数较多,导致特征空间高纬度,因此选取信息增益(Information Gain,IG)和互信息(Mutual Information,MI)方法对文档特征进行选择,这样在保证选择有效特征的同时,对高维特征降维.
1.1 基于信息增益(IG)和词性的混合特征
信息增益(IG)是基于特征在文档中出现的频率衡量该特征为分类所提供的平均信息量的方法,同时也是一种有效的特征降维方法.假设特征项为t,其信息增益IG(t)[12]可定义为

式中:d为文档类别;D表示文档集;H(D)为系统熵;H(D|t)表示在选择特征的情况下系统的条件熵;表示特征t不出现的概率.由式(1)可知,特征t的信息增益量表明该特征对分类的贡献程度,二者成正比例关系.分别对名词(N)、动词(V)、形容词(A)、副词(D)这4 类词性计算其信息增益量,按照由大到小的顺序排列,选择信息增益量最大的前q个特征作为最终特征.将经过IG 处理的特征再次组合,分别构成三类混合特征.
1.2 基于互信息(MI)和词性的混合特征
互信息(MI)是一种根据随机变量间相关性来度量特征信息量的方法.假定文档类别为d,特征t和类别d之间的互信息[12]定义为
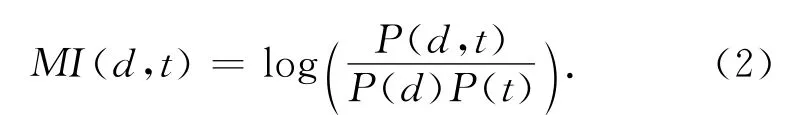
当特征项t与当前文档c无关时,MI(d,t)=0.将特征t和所有类别的互信息平均值MIavg(t)=作为衡量互信息的阈值,同样从式(2)可知MI值和该特征与类别的相关性成正比,因此选择MI值较大的候选特征归入最终混合特征集.
2 向量空间模型聚类
向量空间模型(Vector Space Model,VSM)是一种有效的文档数据化的方法[13],其基本原理就是将文档中的每一个特征项与高维空间向量的每一维相对应,而特征项的权重表示其对文本分类的贡献量.因此,在高维空间中每一个向量对应一篇文档,其中向量的维数表示文档的词条数,各个维的坐标值就是词的权重wji.
假设文档数目为N,聚类数目为K.文档Di采用VSM可以将其表示为di=(w1,i,w2,i,…,Wn,i),i=1,…,N,其中wji表示文档Di中出现词wj的权重.文档聚类中心向量可表示为,c=1,…,K,其 中,r=1,…,s,表示当前类别c中所有文档中出现词wj的平均权重,s表示当前类别c中文档的数目.
两文档间的距离可以通过计算两个文本向量的夹角得到,因此两个文档间的差异度可表示为
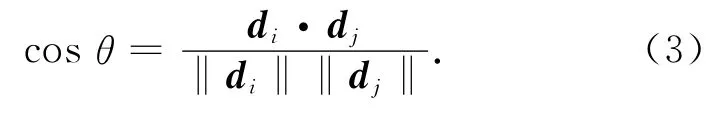
将文档差异度作为文档聚类的阈值,本文提出的文档聚类算法如下:
Step 1.设定聚类数K,随机指定K个文档初始化聚类中心,tc=0(c=1,…,K)用于记录当前类别c中聚类的文档数目;
Step 2.根据式(3)计算文档向量di(i=1,…,N)和聚类中心向量d(c)(c=1,…,K)之间的差异度;
Step 3.将与当前聚类中心差异度最小的文档向量划分到当前的类中,tc=tc+1,重新计算文档聚类中心的向量d(c);
Step 4.重复执行步骤2和步骤3,直到聚类中心向量不再变化为止.
3 基于文档聚类的SVM 文本情感分类
采用IG 和MI对文档特征向量降维的同时生成高效的混合特征向量,紧接着利用文档聚类算法减少训练样本的数量,在样本纬度和数量上加快SVM 的训练.根据最终的聚类中心,重新构造文档集的向量空间模型,最终由SVM 判断出文档的观点(肯定/否定).
SVM 通过样本在原空间映射到高维特征空间中构造最优分类超平面,将给定的属于两个不同类别的样本分开,构造超平面的依据是两类样本与超平面的距离最大化.SVM 的决策分类函数是
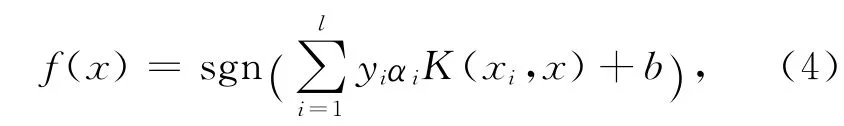
式中:xi∈Rn,i=1,2,…,l是用于训练的约简文档混合向量集;yi∈{-1,1}是类别标号;αi>0是Lagrange系数,对应于支持向量(SV)的αi取值非零,其余取值为零;b是分类的域值,可以由任意一个线性支持向量求得.在本文中选择类似于GMM 的径向基核函数[14]
4 仿真实验结果及分析
仿真实验采用中国科学院计算技术研究所谭松波博士提供的中文文本情感分析语料库.该语料库包含酒店评论、笔记本电脑评论和书籍评论三种语料集,每种语料集的正负类文本各2 000篇.仿真实验基于酒店评论数据,随机选取数据中正面和负面各1 200 篇用于模型的训练,而剩余文本用于性能的测试.采用ICTCLAS 汉语分析系统对酒店评论语料集中的文本进行分词、标记词性等预处理,不考虑标点符号和助词如“的”对语料情感的影响.实验中特征权重的计算选用TF-IDF 函数[15].实验样本信息如表1 所示.
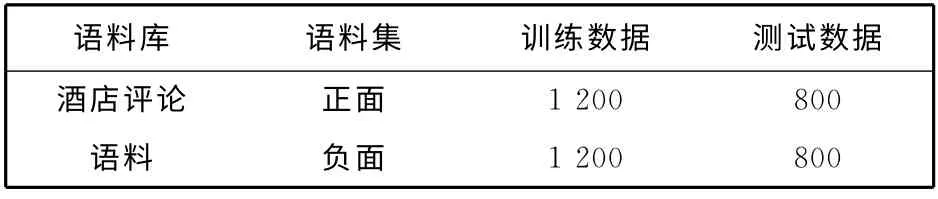
表1 实验样本信息Tab.1 Experimental example information
实验1 不同词性特征组合分析比较
本实验主要是测试不同词性组合特征对传统SVM,经典朴素贝叶斯(NB)和最大熵(ME)分类算法的影响.实验结果如表2 所示.
由表2 可知:
1)“D+A”词性特征组合的分类准确率最高.其中“D+A”特征的维数远远小于“N+D+A”特征的维数,但其分类性能优于“N+D+A”特征,在SVM 中识别准确率达到了88.7%.而形容词由于其特征数量太少,且其与不同名词组合具有不同的语义倾向,因此导致其分类准确率较低.
2)在三种不同的词性组合特征中,SVM 的性能都是最优的.在“N+D+A”特征中,SVM 的分类准确率比NB 高出将近6%,而比ME 高出2.8%;在“D+A”特征中,SVM 比NB 高出7.4%,比ME 高出4.2%;在“A”特征中,SVM的分类准确率高于NB3.6%,高于ME1.7%.

表2 不同词性组合性能比较Tab.2 Performance comparison of different part of speech combination
实验2 混合特征分析比较
分别采用IG 和MI与各类词性特征组合成混合特征,将基于IG 的三类混合特征称为:IG 一类混合特征(hfIG(1)),IG 二类混合特征(hfIG(2)),IG 三类混合特征(hfIG(3)).相应地,基于MI的混合特征为:MI一类混合特征(hfMI(1)),MI二类混合特征(hfMI(2)),MI三类混合特征(hfMI(3)).以正面查准率(PP)、正面召回率(RP)、负面查准率(PN)、负面召回率(RN)和综合准确率F为评价指标,实验结果如表3 所示.
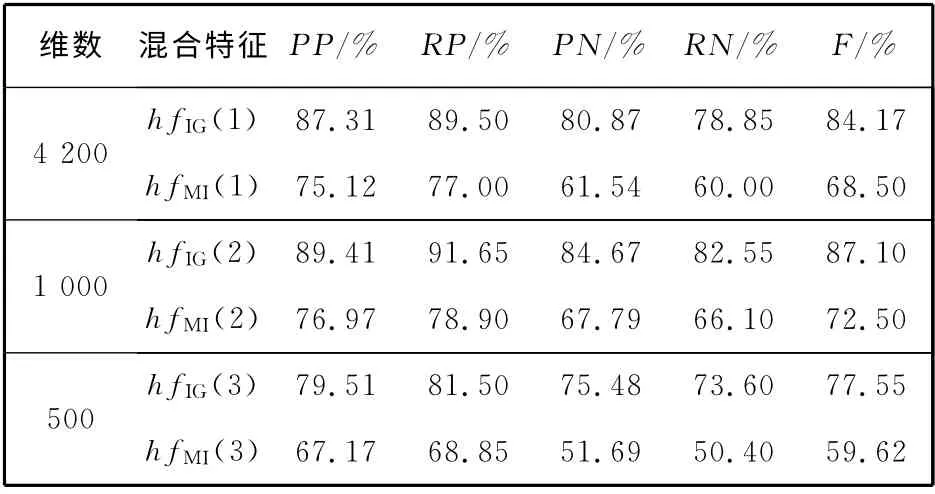
表3 混合特征性能比较Tab.3 Performance comparison of mixed feature
由表3 可知,
1)在两种特征选择方法中,IG 性能优于MI.在第一类混合特征中,系统的维度较高,hfIG(1)的各项性能指标高于hfMI(1);在第二类混合特征中,hfIG(2)的性能达到最优,其综合准确率F为87.1%,而hfMI(2)的 综 合 准 确 率F仅 为72.5%;在第三类混合特征中,MI的特征选择性能最差,其F为59.62%.IG 的情感特征提取性能高于MI,主要是由于MI只考虑特征在某一类文档中出现的情况,而不考虑此特征在另外一类文档中没有出现的情况.
2)在使用IG 进行特征选择时,hfIG(2)的正面查准率(PP)、正面召回率(RP)、负面查准率(PN)、负面召回率(RN)和综合准确率F最高.hfIG(2)的维数比hfIG(1)大大地降低,但其综合准确率F有所提高,主要是因为hfIG(1)是基于“A+D+N”,其中N(名词)在文档中所占比重较大,但是其所带感情色彩较轻,对情感分类的影响较小.而hfIG(2)基于“A+D”,A(形容词)和D(副词)对情感倾向性的影响较大,是有效的情感分类特征.
综上所述,在文本情感分类中,特征选择算法以及特征词性的选择对系统的分类准确率影响较大.
实验3 聚类算法性能分析比较
本实验主要测试本文提出的聚类算法的性能,分类算法采用性能最优的SVM.由实验2 可知,hfIG(2)特征性能最好,因此在本实验中采用该混合特征.实验结果如表4 和图1 所示.
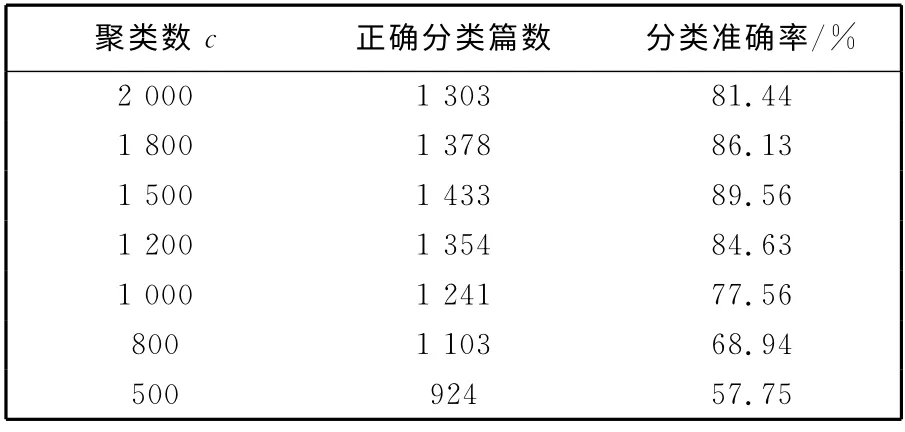
表4 VSM 文档聚类性能比较Tab.4 Performance comparison of VSM clustering
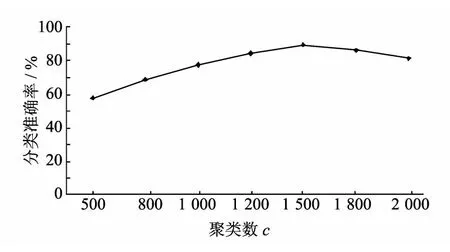
图1 VSM 文档聚类曲线Fig.1 Curve of VSM clustering
由表4 可知,本文的算法在聚类数目c=1 500 时,文本情感分类的准确率为89.56%,达到最佳值.随着c值的减少,用于训练SVM 的特征向量的数目也随之减少,使得SVM 模型的识别准确率受到影响.2 400 篇训练文档经过VSM聚类算法,训练样本数目减少到1 500,减少了37.5%,既减少了向量的存储空间,也降低了SVM 训练的计算复杂度,势必会提高文本情感分类系统的分类速度.其分类准确率曲线如图1 所示.
5 结论
本文提出了一种基于混合特征向量空间模型聚类算法.采用信息增益(IG)和互信息(MI)两种特征提取方法,与文档的不同词性特征相结合,生成文档的混合特征向量;根据文档向量空间模型之间的差异度,对相似文档进行聚类.减少了样本维度和数量,解决了SVM 在大规模数据下训练速度慢的问题,在保证系统分类准确率的前提下,可以有效地提高系统的分类速度,取得了较为理想的实验结果.不同词性特征和混合特征的实验结果表明,特征选择算法以及词性的选择对系统的分类准确率影响较大;聚类算法实验结果表明,当c=500 时,系统的分类准确率达到了最佳值,此时训练样本的数目有效地减少.因此,本文提出的算法是一种行之有效的方法,为加快文档情感分类提供了一种新途径.
[1]赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848.Zhao Yanyan,Qin Bing,Liu Ting.Sentiment analysis[J].Journal of Software,2010,21(8):1834-1848.(in Chinese)
[2]Duric A,Song F.Feature selection for sentiment analysis based on content and syntax models[J].Decision Support Systems,2012,53(4):704-711.
[3]Salton G,Wang A.Yang C S.A vector space model for automatic indexing[J].Communication of the ACM,1975,18(11):613-620.
[4]Pang B,Lee L,Vaithyanathan S.Thumbs up sentiment classification using machine learning techniques[C].Proceedings of the 2002Conference on Empirical Methods in Natural Language Processing,2002:79-86.
[5]周杰,林琛,李弼程.基于机器学习的网络新闻评论情感分类研究[J].计算机应用,2010,30(4):1011-1014.Zhou Jie,Lin Chen,Li Bicheng.Research of sentiment classification for netnews comments by machine learning[J].Journal of Computer Applications,2010,30(4):1011-1014.(in Chinese)
[6]Wang Suge,Li Deyu,Song Xiaolei,et al.A feature selection method based on improved fisher's discriminant ratio for text sentiment classification[J].Expert Systems with Application,2011,38(7):8696-8702.
[7]Xia Huosong,Tao Min,Wang Yi.Sentiment text classification of customers reviews on the web based on SVM[C].Proceedings of the 2010Conference on Natural Computation,2010,3633-3637.
[8]Moraes R.Document-level sentiment classification:An empirical comparison between SVM and ANN[J].Expert Systems with Applications,2012,40(2):621-633.
[9]Prabowo R,Thelwall M.Sentiment analysis:A combined approach[J].Journal of Informetrics,2009,3(2):143-157.
[10]王秀娟,郑康锋.基于文档空间向量距离的查询扩展[J].计算机工程,2009,35(18):54-56.Wang Xiujuan,Zheng Kangfeng.Query expansion based on vector distance in documents space[J].Computer Engineering,2009,35(18):54-56.(in Chinese)
[11]徐淑坦.基于改进RBF 神经网络文本情感分类研究[D].长春:吉林大学,2011.
[12]汪正中.基于英文博客空间文本的情感分析研究[D].温州:温州大学,2011.
[13]Li Xinwu.A new text clustering algorithm based on improvedK-means[J].Journal of Software,2012,7(1):95-101.
[14]Yang Shu,Yan Shuicheng,Zhang Chao.Bilinear analysis for kernel selection and nonlinear feature extraction[J].Neural Networks,2007,18(5):1442-1452.
[15]昝红英,郭明,柴玉梅,等.新闻报道文本的情感倾向性研究[J].计算机工程,2010,36(15):20-22.Zan Hongying,Guo Ming,Chai Yumei,et al.Research on news report text sentiment tendency[J].Computer Engineering,2010,36(15):20-22.(in Chinese)
猜你喜欢
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
铁道通信信号(2019年6期)2019-10-08
电脑爱好者(2017年7期)2017-05-06
雷达学报(2017年6期)2017-03-26
高中生学习·高三版(2016年9期)2016-05-14
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
