
一种基于白像素增量比的字幕图像分割算法
2014-11-20 08:18程江华库锡树
电视技术 2014年5期
任 通,程江华,金 阳,库锡树
(国防科技大学电子科学与工程学院,湖南长沙410073)
随着信息时代的到来,信息量爆炸式增长,视频节目数量剧增,由曾经全国的几十路频道,发展到如今国、省、市、县各级单位都有多路频道,而且每天都在不间断地播出,面对如此庞大的视频数据量,必然出现对海量视频数据进行监控的困难,其中字幕作为视频画面重要的组成部分,包含大量关键的客观信息,所以对字幕的检索是一项必要的工作。为实现对视频字幕的机器自动检索,必须检测定位出视频流中的字幕图像,然后将字幕图像进行分割,即把字符像素与本底背景像素分离,二值化为可供OCR软件识别的字幕图像。
对于字幕图像分割算法的研究,由于一般视频字幕都有本底背景复杂、对比度低的特点,全局阈值的方法会使得二值图像出现大量断笔的现象和与本底像素粘连的现象,很难得到理想的分割效果。目前最常见的解决方法是局部自适应的阈值分割算法,比如Lyu等的算法[1]和Bernsen算法[2]会使得二值字幕图像在离字符笔划像素较远的本底区域产生大量的噪声,而Niblack算法[3]和Sauvola等的算法[4]会使得二值字幕图像在本底背景与字符笔划灰度相近时出现断笔的现象。高华提出了一个基于形态学的字幕分割方法[5],先将字幕按线性插值的方法对字幕图像增强,获得高分辨率,然后对字幕进行灰度阈值分割,最后利用字符笔划的形态学规律对本底背景像素滤除,此算法适合笔划简单的英文字符,对汉文等笔划繁杂的字符分割效果差。王一丁等人[6]提出了一种基于梯度增强的字幕分割算法,即使用图像多方向梯度的加权之和替代图像的方差,通过对各方向上权值的调节以加强某些方向的边缘信息,与一些自适应阈值分割算法相比,该算法不仅可以保留大部分笔划,也能有效地减少断笔像素问题,但此算法的效果严重依赖于加权的调节作用,而且对不同字幕有不同要求。基于字幕中字符笔划颜色一致且能产生高密度边缘的假设,宋砚等人[7]采用基于边缘点密度与颜色加权的方法对字幕图像进行改进的K均值聚类分割,获得了品质较好的二值字幕,但此方法是将颜色域的三维向量与边缘点密度等比例的加权,对于笔划稀疏的字符(如汉字的“人”、“一”、“二”和英文字母的“f”、“l”等),不可能产生局部的高边缘点密度,也就不能被正确聚类了。同时,对于在复杂背景的情况下,分割效果也不太明显,因为复杂的本底像素也能产生高密度点边缘,加权后会导致复杂背景像素被误分类为字符笔划像素。
为了克服字幕图像分割中容易出现的过分割及欠分割现象,本文提出一种基于字幕区域和外扩区域“白像素”数量增量比判决的分割算法,该算法通过逐步改变图像分割阈值,并对结果进行综合分析,以分析结果作为反馈来判决当前分割效果的好坏,从而确定最优分割阈值。
1 算法原理
首先,给出字幕区域及外扩区域的概念:字幕区域是指图像中同一行或紧邻的若干行字幕像素的最大外接矩形区域;外扩区域定义为仅包括背景而不包括字幕区域的矩形框。根据上述定义,若待处理的图像区域用Ω表示,字幕区域和外扩区域分别用Ωtext和Ωbck表示,则它们满足

图1给出了图像中字幕区域与外扩区域划分的示意。

图1 字幕区域与外扩区域示意图
为了简化算法描述过程同时又不失一般性,假设待处理的视频字幕图像呈现“亮字暗底”的现象,绝大多数字符像素的灰度值比背景像素的灰度值高,当然,在实际应用中如果出现“暗字亮底”的情况,可以对图像灰度进行翻转即可转化为“亮字暗底”的情况。
在图像分割中,随着分割阈值的变化,分割结果中字幕区域“白像素”的个数Ntext(是指分割的二值图像中字幕区域像素值为1的像素的总数目)以及外扩区域“白像素”的个数Nbck(是指分割结果中外扩区域像素值为1的像素的总数目)都在发生变化,这里假设分割阈值由高到低逐渐变化,且图像满足“亮字暗底”条件,那么随着阈值的变化,字幕区域“白像素”的个数Ntext以及外扩区域“白像素”的个数Nbck都会增加,但是它们增加的速度存在很大差异,在阈值变化的初始阶段,字幕区域“白像素”个数Ntext的增加速度明显快于外扩区域“白像素”个数Nbck的增加速度,随着阈值的进一步降低,Nbck的增加速度会越来越快(这是由于在低阈值下会有大量背景像素被分割出来),而Ntext的增加速度会逐渐降低(这是由于在高阈值下大部分字符像素已经被分割出来,阈值再降低对字符像素的影响也会逐步减弱)。
图2a给出了一幅典型的检测定位到的视频字幕图像,该图像中除了字幕区域外,还包括外扩区域。图2b为该字幕图像的灰度图像,图2c~图2l为在不同阈值(Thr)下的分割结果。显然,随着分割阈值的逐步降低,字符像素逐步被分割出来,但随着分割阈值的进一步降低,除了字符像素被分割出来以外,外扩区域中的背景像素也被分割出来,如图2f~图2l所示。

图2 分割结果随分割阈值的变化情况
图3给出了字幕区域和外扩区域“白像素”的数量随分割阈值变化的曲线,从曲线中可以看出,无论是字幕区域还是外扩区域,随着分割阈值的降低,其“白像素”数量都在增加,但显然在不同的阈值范围内它们增加的速度是不一致的:阈值较高时,字幕区域白像素增加迅速,而外扩区域“白像素”增加比较缓慢,表明大部分字符像素还未被分割出来,需要进一步降低阈值;随着阈值的降低,字幕区域白像素增加趋于缓慢,而外扩区域“白像素”数量快速增加,表明在此阈值下大部分字符像素已经被分割出来了,再降低阈值只会导致大部分背景像素被分割出来,从而导致欠分割现象的出现。

3 字幕区域及外扩区域白像素数量随分割阈值的变化情况
以上分析表明:字幕区域和外扩区域“白像素”增量的变化情况可以反映出在不同分割阈值下图像分割效果的优劣。这也意味着可以通过分析白像素增量的相对变化情况来获取图像分割的最优阈值。
为了定量表达“白像素”增量的变化情况,本文定义了“白像素”增量比的概念:给定字幕图像I(x,y),其字幕区域和外扩区域分别用Ωtext和Ωbck表示,对该图像分别采用阈值T1,T2进行分割,得到2个分割结果B1,B2,分别统计B1,B2中字幕区域和外扩区域的“白像素”数量,其中B1中字幕区域和外扩区域“白像素”数量分别用和表示,而B2区域中字幕区域和外扩区域“白像素”数量分别用和表示,则“白像素”增量比r定义为

式中:ΔNtext和ΔNbck分别称为字幕区域“白像素”增量和外扩区域“白像素”增量。
图4a给出了图2中的样本字幕区域“白像素”增量和外扩区域“白像素”增量随分割阈值的变化情况,图4b给出了相应的“白像素”增量比随分割阈值的变化情况,在实际应用中,为了克服噪声影响,使得算法更加鲁棒,可以对“白像素”增量比进行平滑处理,图4b中实线表示的即为“白像素”增量比平滑的结果。

图4 “白像素”增量比的变化
2 算法实现步骤
基于以上算法原理,下面给出本算法的具体实现步骤:
1)确定图像I(x,y)的字幕区域Ωtext以及外扩区域Ωbck;
2)设定阈值搜索范围[Tmin,Tmax]、搜索步长ΔT,以及白像素增量比阈值rT;
3)令初始阈值T(0)=Tmax,采用该阈值对图像I(x,y)进行初始分割;
4)更新阈值

5)采用新阈值T(i+1)对图像I(x,y)进行分割,分割结果用B(x,y|i+1)表示
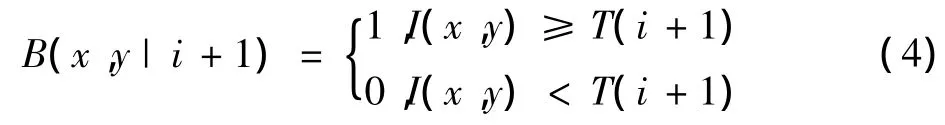
6)在分割结果B(x,y|i+1)中,分别统计字幕区域Ωtext与外扩区域Ωbck的“白像素”的个数Ntext(i+1)和Nbck(i+1),并分别计算字幕区域和外扩区域“白像素”增量

则白像素增量比r(i+1)为

7)对白像素增量比r的大小进行判决,如果r(i+1)<rT,则重复步骤4)~6),直到白像素增量比满足r(i+1)≥rT或分割阈值满足T(i+1)≤Tmin,此时,T(i+1)即为最优分割阈值,而B(x,y|i+1)即为最终分割结果。
3 实验结果及分析
为了验证算法性能,本文选取5幅典型视频字幕图像样本进行分割实验演示。由于简单背景的字幕图像分割难度不大,无法体现出不同算法之间的差异,因此,本文所选样本均为有一定难度的字幕图像,分别为:
1)高对比度但背景复杂的字幕图像,如图5和图6所示。

图5 高对比度复杂背景字幕分割实验一

图6 高对比度复杂背景字幕分割实验二
2)背景较复杂、且分辨率较低的字幕图像,如图7和图8所示。

图7 低分辨率字幕分割实验一
3)背景复杂的英文字幕图像,存在与字符像素颜色非常相近的背景,如图9所示。

图9 复杂背景的英文字幕分割实验
实验中,给出采用OTSU算法、K均值聚类算法的分割结果进行对比。采用基于白像素增量比的算法分割时,参数设置为:阈值搜索范围为[50,255],搜索步长ΔT=5,白像素增量比阈值rT=0.1。分析图5~图9中的实验结果,可得出如下结论:
1)OTSU算法对大多数字幕图像分割有效,但是当字幕中存在与字符像素颜色或灰度相近的背景时,分割效果不佳,当字符笔划比较复杂时,容易出现字符笔划粘连的情况,这给后续的OCR识别带来很大困难。
2)K均值算法的性能在很大程度上与OTSU算法相差无几,这是由于本质上讲,K均值也是一种使得类间方差最大化而类内方差最小化的算法。另外,K均值聚类由于没有利用字符像素灰度的先验知识(比如“亮字暗底”),往往会出现分割结果“反相”的问题(也即分割结果中字符像素为黑色,而背景像素为白色),对此问题,只需要在后处理中做相应调整即可。
3)本文提出的基于白像素增量比的算法,其性能要优于前述算法,从分割结果可以看出,该算法有2个显著的优势:第一,它能很好地剔除背景像素,无论是复杂背景下的字幕图像还是低分辨率的图像,该算法都能将背景像素很好地剔除,尤其从图9d可以看出,其他几种方法都无法将字幕图像中的英文“We’ll”分割出来,而只有基于白像素增量比的算法可以将该英文从背景中提取出来,这显示了该算法良好的分割性能;第二,该算法较好地解决了复杂笔划的粘连问题。
4 小结
视频字幕包含大量关键的客观信息,对视频内容有最直接的描述与解释,因此从视频中提取字幕是实现视频内容检索与理解的基础,研究字幕分割具有重要意义。为了克服字幕图像分割中容易出现的过分割及欠分割现象,本文提出一种基于字幕区域和外扩区域“白像素”数量增量比判决的分割算法。该算法的新颖之处在于采用一种闭环反馈及“白像素”增量比的方式来解决图像分割中最优阈值的选取问题,有效克服了字幕图像分割中容易出现的过分割及欠分割现象,实验结果表明此算法综合性能要优于传统的OTSU以及K均值聚类算法,说明了它在解决字幕图像分割的问题上是可行的、有效的。
[1] LYU M R,SONG JQ,CAIM.Comprehensive method for multilingual video textdetection,localization,and extraction[J].IEEE Trans.Circuit and Systems for Video Technology,2005,15(2):243-255.
[2] BERNSEN J.Dynamic thresholding of grey-level images[C]//Proc.the 8th International Conference on Pattern Recognition.Paris,France:[s.n.],1986:1251-1255.
[3] NIBLACK W.An introduction to digital image processing[M].New Jersey:Prentice-Hall Press,1985.
[4] SAUVOLA J,PIETIKAINEN M.Adaptive document image binarization[J].Pattern Recognition,2000,33(2):225-236.
[5]高华.基于边缘和灰度的视频文字提取方法的研究与应用[D].北京:北方工业大学,2011.
[6]王一丁,蒋小森.基于梯度增强的新闻字幕分割算法[J].计算机辅助设计与图形学学报,2009,21(8):1170-1174.
[7]宋砚,刘安安,张勇东,等.基于聚类的视频字幕提取方法[J].通信学报,2009,30(2):136-140.
猜你喜欢
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
数字通信世界(2019年3期)2019-04-19
北京广播电视报(2019年8期)2019-03-27
小学阅读指南·低年级版(2016年10期)2016-09-10
唐山文学(2016年11期)2016-03-20
人间(2015年22期)2016-01-04
科技创新与品牌(2015年10期)2015-10-27
语言与翻译(2015年4期)2015-07-18
