
LTE系统DVRB和DPRB映射的研究与实现
2014-11-20 08:18李小文贾海峰
电视技术 2014年5期
罗 佳,李小文,贾海峰
(重庆邮电大学通信与信息工程学院,重庆400065)
在宽带无线通信系统中,特别是正交频分复用(Orthogonal Frequency Division Multiplexing,OFDM)的宽带无线通信系统中,资源块的划分是从时域和频域两个方向进行的[1-2],资源块用于对某些特定信道到资源粒子映射的描述[3]。对于物理层,看到的资源是物理资源块,物理信道直接映射到物理资源块上。高层给用户配置的资源是虚拟的资源,即虚拟资源块。eNodeB(Evolved Node B)端可以根据虚拟资源块同物理资源块的映射关系,计算出虚拟资源块对应的物理资源块,将用户的数据映射到分配给它的物理资源上。虚拟资源块映射到物理资源块,不连续地占用子载波,可以使干扰随机化,抵抗由于某一段频率持续的深衰落造成的性能恶化,可获得频率分集增益。PDCCH(Physical Downlink Control Channel,物理下行控制信道)中有一个资源分配域定义了相应的PDSCH(Physical Downlink Shared Channel,物理下行共享信道)使用的VRB(PRB)资源[4]。PDSCH 的资源分配类型有0,1和2三种[5]。UE(User Equipment,终端)根据检测到的 DCI(Downlink Control Information)格式对PDCCH中的资源分配域进行解析。类型0是以RBG(Resource Block Group,资源块组)为单位,比较简单,但对于小数据量业务,容易造成资源浪费;类型1是以RB(Resource Block,资源块)为单位,资源分配相对灵活,可获得更好的频率分集增益,但每次最多只能分配一个RBG子集中的部分RB。对于类型0,1,只采用集中式虚拟资源块分布方式。类型2中,可采用集中式或分布式,有1 bit的标志位来指示[4-5]。
1 物理资源块和虚拟资源块
1.1 物理资源

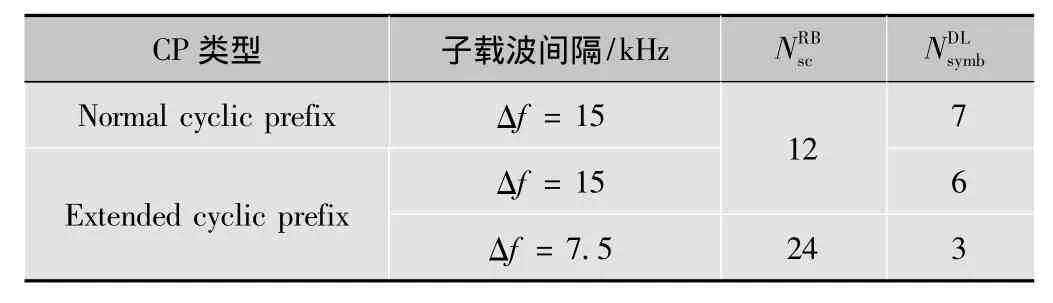
表1 物理资源块参数
1.2 虚拟资源块
虚拟资源块用来描述TD-LTE系统下行传输所支持的两种资源映射方式:集中式分配和分布式分配[2],如图1所示。由图2可看出,集中式分配方式将若干连续子载波分配给一个用户,这种分配方式的优点是信道估计的难度较低,而且系统可通过频域调度选择较优的子载波组进行传输,从而获得频域上的调度增益和时域上的多用户分集增益。但缺点是获得的频率分集增益较小,用户平均性能略差。分布式分配方式将分配给一个用户的子载波分散到整个系统带宽,从而获得频率分集增益。但这种方式下的信道估计较为复杂。
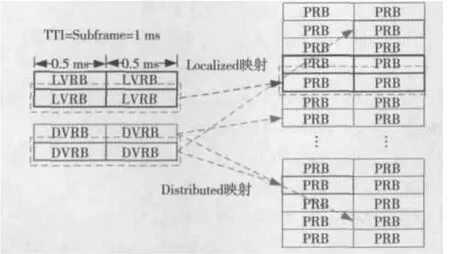
图1 虚拟资源块的两种资源映射方式
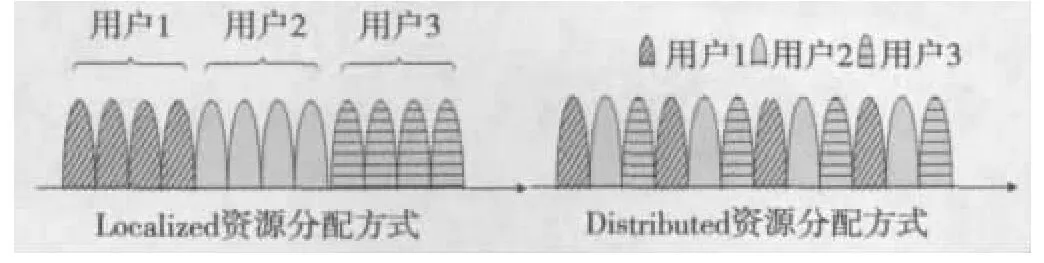
图2 两种OFDMA资源分配方式
2 VRB 到 PRB 的映射实现[3-5]
对两种类型的虚拟资源块,一个子帧中2个时隙上的成对虚拟资源块共同分配到一个独立虚拟资源块号nVRB。集中式虚拟资源块直接映射到物理资源块上,使得虚拟资源块nVRB与物理资源块nPRB一一对应,即nPRB=nVRB。虚拟资源块号从0到-1,其中=[3]。

表2 资源块间隔值

表3 RBG大小与系统带宽的对应关系
VRB序号按矩阵按行写入,按列读出。Nnull空值插入第2和第4列的最后Nnull/2行,其中Nnull=4Nrow-。读出时忽略空值。包裹交织处理的VRB序号到PRB序号的映射过程如下。
对偶时隙号ns满足


根据偶时隙得到奇时隙号ns满足
对所有ns有

根据上面的映射过程可以计算出在整个带宽下VRB与PRB的映射关系。目前常规的映射算法是按照3GPP协议给出的公式首先计算出整个带宽下VRB与PRB的映射关系,然后根据这个映射关系和用户分配的VRB计算出其对应的物理资源块索引向量,这个PRB索引向量内包含的PRB的索引是乱序的,在进行资源映射时需将这个PRB索引向量进行排序,然后根据从小到大的顺序进行资源块的映射,该算法较复杂,计算量大。
3 改进算法分析
基于现有算法实现的缺点,本文提出一种改进算法,简化了将分布式虚拟资源块映射到物理资源块的实现过程,且便于FPGA或DSP实现。
3.1 算法描述
假设由3GPP协议的资源分配RIV值等计算得到的偶时隙nVRB序号[4]为nVRB=(16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39),并根据协议计算得到交织单元的行数Nrow=12,空比特数Nnull=2及空比特所存放的位置。按行写入,构建交织单元如图3a所示,阴影部分表示nVRB序号。接着按列依次写入交织单元如图3b所示,由图可直观地得到序号,如相应的阴影部分所示。即(ns)=(4,16,27,39,5,17,28,40,6,18,29,41,7,19,30,42,8,20,31,43,9,21,32,44)。
根据式(6)可得Ngap-/2=4 ,即(ns)要右移4 位,得到最终的nPRB序号为nPRB=(4,16,31,43,5,17,32,44,6,18,33,45,7,19,34,46,8,20,35,47,9,21,36,48)。3种序号的对应关系如图4所示。
3.2 算法实现
1)首先根据3GPP协议分3种情况计算RBstart和LCRBs[4-5],得到偶时隙nVRB序号。

图3 交织单元
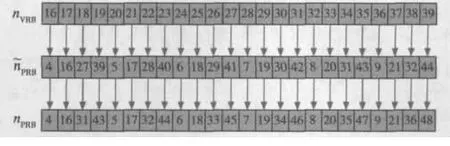
图4 3种序号的对应关系
(2)若DCI1A,DCI1B,DCI1D用C-RNTI加扰,要判断若大小为50 ~110 RB,则令LCRBs=16[5]。
(3)若DCI格式为DCI 1C,则根据协议相应公式计算得到RBstart和LCRBs。
2)若DCI_gap_value=0,即选择Ngap,1或当DCI_gap_value=1 即选择Ngap,2,并且RBstart+LCRBs≤,只需一个交织单元,通过下面的步骤得到物理资源块序号:
(1)交织单元中的虚拟资源的起始序号为start=RBstart,结束序号end=RBstart+LCRBs-1。
(2)计算交织单元的行数Nrow和空比特个数Nnull,从而得到交织单元中未插入NULL的行数d1=Nrow-Nnull/2;需要插入NULL的行数d2=Nnull/2;总行数d=d1+d2。
(3)设交织器的行序号从0开始,分配的虚拟资源块在交织器中的起始行序号为r1,结束行序号为r2,将交织器分为上下两部分,不包含NULL的行称为交织器上部,包含NULL的行称为交织器下部。根据start和end计算r1和r2。
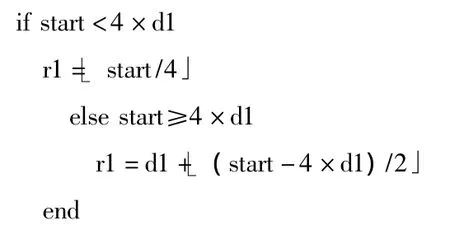
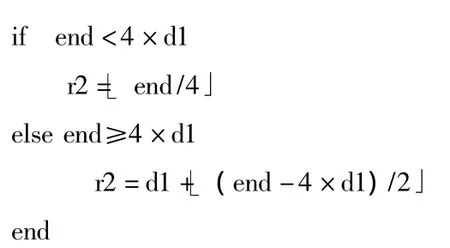
(4)设虚拟资源块对应的物理资源块在交织器中的列向量的索引向量为A1、A2、A3、A4,根据r1和r2确定A1、A2、A3、A4的值。
首先通过起始行序号r1和r2确定A1和A3的值:A1=[r1,r1+1,…,r2];A3= [d+d1+r1,d+d1+r1+1,…,d+d1+r2]。
通过r1,r2和d1的关系确定A2、A4:

(5)根据r1,d1和start对向量A1、A2、A3、A4进行处理,判断方式如下:
if r1<d1
ifmod(start,4)==0
向量A1A2A3A4保持不变
elseifmod(start,4)==1
去掉中A1的第一个数据,其他A2A3A4保持不变
elseifmod(start,4)==2
去掉中A1和A2中的第一个数据,其他A3A4保持不变
elseifmod(start,4)==3
去掉中A1,A2和A3和中的第一个数据,其他A4保持不变
end
else r1≥d1
ifmod(start,2)==0
向量A1A2A3A4保持不变
elseifmod(start,2)==1
去掉中A1的第一个数据,其他A2A3A4保持不变
end
end
(6)根据r2,d1和end对向量A1,A2,A3,A4进行处理,判断方式如下:
if r2<d1
ifmod(end,4)==0
去掉中A2和A3,A4和中的最后一个数据,其他A1保持不变
elseifmod(end,4)==1
去掉中A3和A4中的最后一个数据,其他A1A2保持不变
elseifmod(end,4)==2
去掉A4中的最后一个数据,其他A1A2A3保持不变
elseifmod(end,4)==3
向量A1A2A3A4保持不变
end
else r2≥d1
ifmod(end,2)==0
去掉中A3的第一个数据,其他A1A2A4保持不变
elseifmod(end,2)==1
向量A1A2A3A4保持不变
end
end
(7)将A1、A2、A3、A4进行级联,得到物理资源块序号索引A=[A1A2A3A4],即A0= [A1A2A3A4]。
3)若DCI_gap_value=1,即选择Ngap,2并且RBstart+LCRBs>,则有两个交织单元。对于第一个交织单元的计算,start=RBstart,end=-1参照步骤2),得到A;对于第二个交织单元的计算,则按照下面的步骤:
(1)虚拟资源的起始序号为start=0,结束序号为:end=RBstart+LCRBs-1-。
(2)从上面第3步开始重复同样操作得到第二个向量B=[B1B2B3B4],将得到的向量B中的值都加上得到最终向量,即

(3)将得到的两个向量级联得到最后的物理资源块索引结果,即

4)至此,得到偶时隙的物理资源块分配情况(并非最终结果,还要根据判断条件进行相应的偏移)根据式5)得到奇时隙的PRB分配情况。
5)根据式(6)进行判断,并完成将奇偶时隙物理资源块PRB进行相应的偏移,得到最终的PRB序号。
算法的具体实现流程如图5所示。
改进算法首先将实现过程分为一个或两个VRB映射模块,每个VRB映射模块的实现过程都是通过计算出分配的VRB的起始和终止在交织矩阵中的位置,然后根据起始和终止的位置按照交织矩阵的性质直接计算出已排好序的物理资源块索引,最后将多个VRB映射模块的结果进行级联得到所需的PRB的索引,算法简单,计算量小,且便于硬件实现。

图5 算法流程图
4 性能分析与总结
根据算法实现流程,搭建仿真链路平台,进行MATLAB算法验证和CCS算法实现。在DSP实现中,通过执行并行指令优化程序循环体,充分利用“NOP”指令减小循环周期,使程序最优化[6-7]。改进前后虚拟资源块到物理资源块映射的运算cycles数统计如表4,通过表4可看出,该算法大大减少了执行周期,降低了计算复杂度。当运用TMS320C64x DSP芯片实现时,完全可以满足实时性的信号处理,非常适合TD-LTE系统实时性的要求,可以较好地应用于TD-LTE系统的实现。

表4 算法改进前后计算复杂度对比
图6示出了本文算法压缩时间的百分比。由于随着资源块RB数的增加,算法复杂度增大,仿真时间会明显增大,但当采用本文的实现方案,算法复杂度有明显的改善,使得当RB很大时高效地实现映射。由图可看出,随着RB数的增加,本文算法的优势越明显,两种算法的仿真时间比值越小。本文算法相对于传统算法仿真时间减少为原来的53.3% ~37.3%,整个仿真系统平均仿真时间减少为原来的44.6%。从仿真结果可以看出,本文算法不但可以保证VRB到PRB映射结果的正确,还可以节省大量的仿真时间。
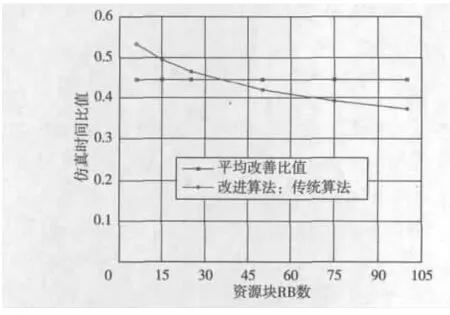
图6 仿真时间百分比随资源块个数变化图
本文从理论分析出发,结合TD-LTE系统特性,分析了目前常规的映射算法,提出了一种改进算法,详细讲述了在DSP中的实现方法,并在TMS320C64x DSP上加以实现。程序运行结果表明,改进后算法能够满足TD-LTE系统的需求[8],具有可行性和高效性。该实现方案已应用于TD-LTE射频一致性测试系统的开发中。
[1]王映民,孙韶辉.TD-LTE技术原理与系统设计[M].北京:人民邮电出版社,2010.
[2]沈嘉,索士强,全海洋,等.3GPP长期演进(LTE)技术原理与系统设计[M].北京:人民邮电出版社,2008:280-315.
[3] 3GPP TS 36.211 v9.1.0,3rd generation partnership project;technical specification group radio access network;evolved universal terrestrial radio access(E-UTRA);physical channels and modulation(Release 9)[S].2010.
[4] 3GPP TS 36.212 v9.1.0,3rd generation partnership project;technical specification group radio access network;evolved universal terrestrial radio access(E-UTRA);multiplexing and channel coding(Release 9)[S].2010.
[5] 3GPP TS 36.213 v9.0.0,3rd generation partnership project;technical specification group radio access network;evolved universal terrestrial radio access(E-UTRA);physical layer procedures(Release9)[S].2009.
[6] Texas Instruments Incorporated.TMS320C64x/C6-4x+DSPCPU and Instruction Set Reference Guide[EB/OL].[2013-04-10].http://www.ti.com.cn.
[7]Texas Instruments Incorporated.TMS320C6000系列DSP编程工具与指南[M].田黎育,何佩琨,朱梦宇,译.北京:清华大学出版社,2006:32-50.
[8] 3GPP TS 36.141 v9.1.0,3rd generation partnership project;technical specification group radio access network;evolved universal terrestrial radio access(E-UTRA);base station(BS)conformance testing(Release 9)[S].2010.
猜你喜欢
美食(2022年2期)2022-04-19
舰船电子对抗(2020年2期)2020-06-23
女报(2019年3期)2019-09-10
铁道通信信号(2018年9期)2018-11-10
成都信息工程大学学报(2018年6期)2018-03-21
舰船电子对抗(2016年3期)2016-12-13
广西大学学报(自然科学版)(2016年5期)2016-11-12
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年13期)2016-10-17
股市动态分析(2016年10期)2016-09-30
