
改进的FSVM结合语义特征的甲状腺图像分类方法
2014-11-20 08:18万丹丹门国尊
电视技术 2014年5期
赵 杰,万丹丹,门国尊
(河北大学a.电子信息工程学院;b.河北大学经济学院,河北保定071000)
甲状腺结节[1]在临床中具有很高的发病率,且随着年龄的增长不断增加,甲状腺癌[2]只有通过尽早发现确诊,才能提高治愈率。当前,甲状腺的临床分析主要通过医生对图像的主观判别来完成。由于甲状腺癌生物学特性多变,与良性病变难以区分,而医生的临床经验差别很大,造成许多病人被误诊,因此计算机辅助判别甲状腺图像良恶性的方法研究具有广泛的应用前景。许多学者进行了相关研究[3],如基于粗糙集的方法[4]、基于马尔可夫模型的方法[5-6]等。对这些方法分析发现,它们总体上还处于理论探讨阶段,离实际应用还有一定距离。还有一些文献以神经网络、贝叶斯分类器[7-8]对这些图像进行分类[9-10]。神经网络建立在经验风险最小化基础上,只有存在足够多的训练样本才能保证分类效果,而训练样本往往很有限。贝叶斯分类器也同样面临无限样本集问题。支持向量机(SVM)[11-12]建立在统计学习理论的基础上,其目标是在有限的样本下得到现有信息的最优解。与神经网络相比,支持向量机结构简单且泛化能力强。模糊支持向量机(FSVM)不仅具有SVM的优点,同时可以克服孤立点和噪声,从而使形成的分类面更优。关键在构造目标函数时,根据样本的重要程度,分配相应的隶属度。本文同时考虑样本到类中心的距离和数据样本紧致度的关系,结合欧氏距离方法,提出了一种新的模糊隶属度函数。
由于甲状腺图像良恶性特征不同尺度下的相似性,本文根据有经验的医师用确诊的甲状腺图像训练分类器,通过图像底层特征提取语义特征[13-14],利用FSVM的模糊隶属度对较大可能性的语义特征进行标签标注,最后通过分类器集成,使用多数投票方式产生正确结果。
1 模糊支持向量机简介
考虑给定训练样本集
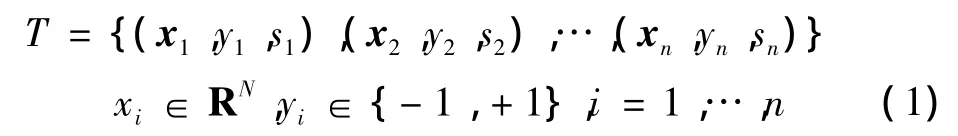
式中:si为训练点 (xn,yn,sn)的输出yi=+1(正类)或yi=-1(负类)模糊隶属度;σ≤si≤1;Rn为n维欧氏空间。
最优分类面问题转化为求式(2)目标函数的最优解

约束条件为
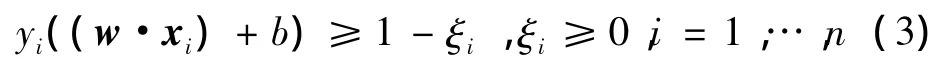
式中:C>0是惩罚参数。近似线性可分时,w是分类超平面间距离的倒数;ξi用来度量样本的错分程度;si是模糊隶属度,表示xi对分类贡献的程度;siξi是带不同权重的样本错分性的度量,从而使样本点在分类中的作用不同。
为了求解二次优化最优解,采用拉格朗日方法,构造拉格朗日函数
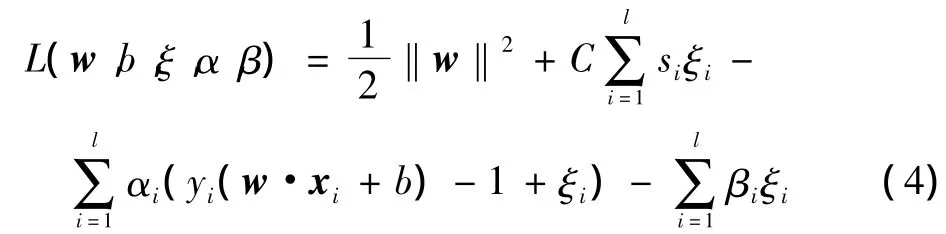
式中:σ ≤si≤1 ,αi≥0,βi≥0,j=1,…,l。σ 为一个任意小的正数αi和βj是支持向量对应的拉格朗日乘子。
化为二次规划的对偶形式为

约束条件为

式中:0≤αi≤si C,i=1,2,…,l;K(xi,xj)是核函数。求解式(5)可得最优解α*,最终的决策函数为

模糊支持向量机的隶属度方法与传统的支持向量机方法相比,在约束条件(1)中增加了隶属度si。
2 改进FSVM结合特征语义的甲状腺图像分类
2.1 FSVM隶属度确定
在FSVM理论中,隶属度函数的设计是一个关键问题,本文同时考虑样本到类中心的距离和数据样本紧致度的关系,结合欧氏距离方法,提出了一种新的模糊隶属度函数。
1)基于样本到类中心的距离的隶属度。
距离模糊隶属度定义为
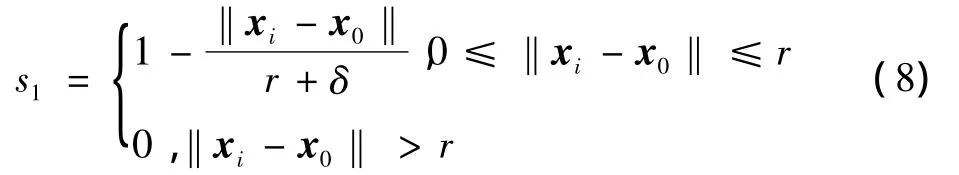
式中:x0为类中心;r为到类中心最远的样本点的距离;δ为很小的一个正数,为了避免s1为0,‖xi-x0‖大于r,则判断肯定不属于该类。
图1中,左右两图中xi点到类中心的距离相等。但左图样本点相对松散,xi点很可能是支持向量,而右图中样本点则相对紧密,xi点就更可能为野点。因此,仅用式(8)定模糊隶属度有不足之处。
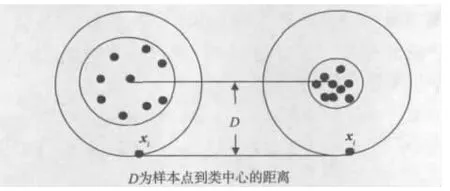
图1 不同紧致度的样本点
2)本文在此基础上,考虑到数据样本紧致度的关系,结合欧氏距离,提出了一种新的模糊隶属度函数。
定义样本点与点间的欧氏距离为
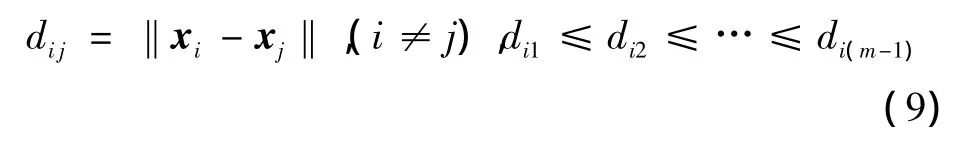
则紧致度的模糊隶属度定义为
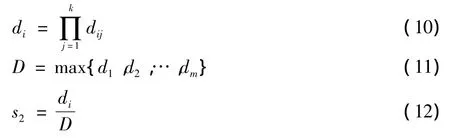
式中:dij是两个样本点xi与xj的距离;k为离样本点最近的k个点。如果样本点越密集,s2值越大,反之则越小。
则最终的隶属度为

2.2 PLSA 模型
概率潜在语义分析(PLSA)是刻画文档与词汇间隐含语义关系的混合生成模型,为了将文本分析中的PLSA模型用于甲状腺图像分析,将图像转换成视觉词汇组合的文档。表1为图像与文本分析的对应关系。

表1 甲状腺图像与文本分析的对应关系
本文将传统文本分析思想引用到图像中,将图像中的区域比作文档,而区域特征作为视觉词汇,即文本中的单词。根据单词出现次数潜在反映图像主题。
为了构造视觉词汇,将甲状腺结节图像划分成D个区域,记为D=(d1,d2,…,dN)。这些区域被量化为包含M个视觉词汇的词汇表w,W=(w1,w2,…,wm)。量化过程是采用改进的LBP提取甲状腺图像区域纹理特征,然后利用k均值聚类算法对提取的特征进行聚类。每个聚类中心作为PLSA中的一个单词。如果聚成R类,则视觉词汇表中就有R个视觉单词。之后建立共生矩阵,甲状腺图像包含D个区域,统计每个区域中各个视觉单词的频率,形成视觉词汇直方图,根据每个区域的视觉词汇直方图拼接成一个大小为D×R的区域—视觉词汇矩阵,对应文本分析中文档词汇共生矩阵
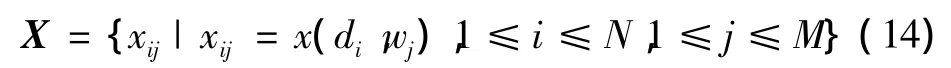
式中:xij=x(di,wj)表示词汇wj在区域di中出现的次数。
则视觉词汇和区域的联合概率分布为
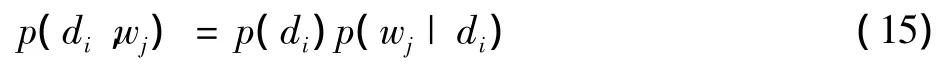
PLSA引入k个量Z=(z1,z2,…,zk)来解除文档与词汇间关系,隐变量Z的引入使di与wj条件独立。这个额外的隐变量Z未增加模型的复杂性,反而使di和wj的依赖性降低。本文中zk表示区域潜在类别,假设其在区域和词上分布是条件独立的。在PLSA中,di与wj之间的依赖关系描述为

将式(16)代入式(15)得

PLSA模型的目标函数就是根据已知训练数据寻求最优参数估计p(wj|zk)(隐主题zk中词汇wj出现的概率)和p(zk|di)(区域di的类别是zk的概率)。隐变量Z是具有某种语义属性的“隐主题”,式(16)可直观解释为一个先根据文档di决定隐主题zk,再根据隐主题zk生成词wj。
根据散射参数曲线的物理意义和特征,散射参数的均值代表液体在测试频段内对微波吸收的整体情况.散射曲线平滑程度反映了液体受外界影响产生的不稳定性,主要和液体的粘稠度等物理性质有关.因此将散射参数的均值和散射参数曲线平滑程度作为感知机的输入参数,即可以达到降维的目的,也便于观察超平面的物理意义.
EM(Expectation Maximization)算法估计参数的最大值。经过两个步骤交替计算,第一步(E)是计算隐藏变量的后验概率的期望值;另外一步(M)是最大化在E步上找到的最大似然的期望值,从而计算参数的最大似然估计。
似然函数为

M步上找到的参数然后用于另外一个E步计算,如此交替实施E步和M步迭代计算,进而计算出PLSA模型的参数。
在E步中,用当前估计的参数值计算隐含变量zk的后验概率

在M步中,利用E步中得到的期望来最大化当前的参数估计,即更新参数值

图像分类的目标是根据其包含的主题类别分类。在训练过程中,由于选择的都是已经由专家确诊的病例图像,因此把这些图像加上类标签,其特征就拥有一定的属性,用这些特征训练分类器,并且采用分类器集成,以求达到更好的分类训练效果。
为了更好地理解分类器集成,假设给出一幅测试图像分别输入3个独立的分类器中,当第1个分类器给出错误答案时,第2个和第3个也许是正确的,如图2所示,因此采用多数投票集成的方法就容易产生正确结果。

图2 集成分类得到的正确结果
3 实验结果及分析
为正确评价B超的检查结果,提高判断甲状腺结节良恶性的准确率,本文分析了秦皇岛第一医院、河北大学附属医院和体检中心在2009年至2012年间因甲状腺结节进行手术治疗患者的B超资料,数据集中包含210幅甲状腺结节图像,其中良性130幅,恶性80幅。所用的超声诊断仪为Philips iU22及HDI5000 Sono彩色超声诊断仪,探头频率为7~12 MHz,图像尺寸为768×576,压缩成为112×92。
3.1 参数对分类性能的影响
本节考察算法中视觉词汇表的大小对图像分类精度的影响。图3是平均分类精度的变化曲线。从总体上看,取20~40变化不明显,取更大的词汇数目不能提高分类精度,只会增加聚类时间。
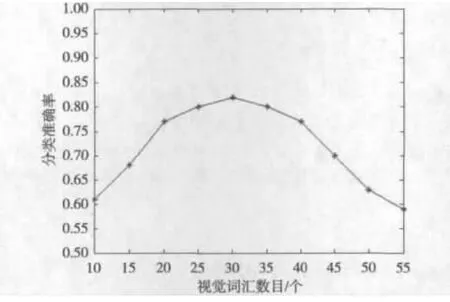
图3 分类精度在不同视觉词汇数目的变化曲线
为了确定使用何种核函数,将样本集分为两组,分别用3种核函数对训练样本进行学习分类。3种不同的核函数的分类识别结果见表2。
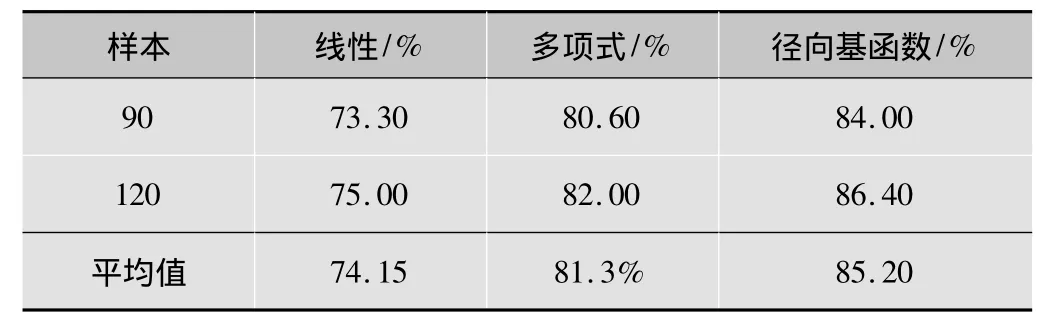
表2 使用不同核函数的分类结果
从表2可以看出,多项式核函数或径向基函数核函数具有较高的准确率,线性的分类器结果稍差。其中径向基函数的识别准确率最高。本文中,选择径向基函数作为核函数进行分类。
3.2 分类精度比较
为了证明本文算法的有效性,通过与传统的算法进行比较,结果见表3。
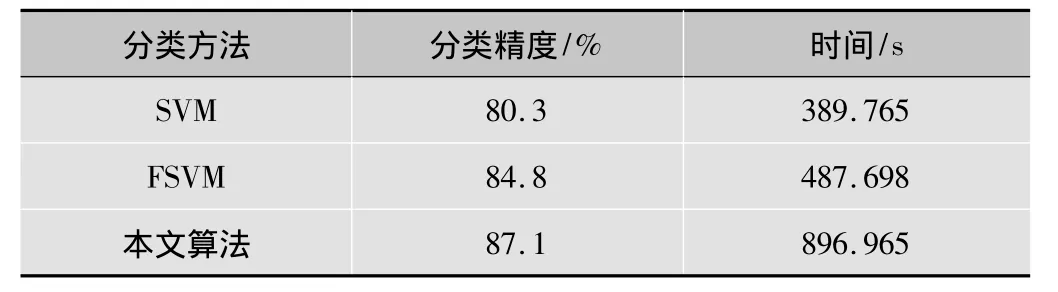
表3 本文算法与传统分类算法分类精度对照表
从表中可以看出,由于甲状腺图像中许多特征为良恶性所共有,因此难以分辨,传统的算法已经不具有很好的分类性能,本文算法充分考虑到甲状腺图像的特点,通过改良图像特征,并且进行多分类器集成方法使分类精度有了一定的提高。但是由于添加了更多的步骤,导致耗时更多。
4 总结
本文采用改进FSVM结合语义特征的甲状腺图像分类方法,通过提取图像语义特征训练分类器,并采用多分类器集成的方法,对甲状腺图像进行智能分类来判别甲状腺结节良、恶性,帮助临床医生更好地做出甲状腺癌的术前诊断。由于设备的原因,要对采集的图像进行压缩,造成图像信息的部分流失。对此今后要进一步研究,以求达到更好的分类性能,并希望本分类方法可以用于其他医学图像的分类。
[1] CHANG C,TSAIM,CHEN S.Classification of the thyroid nodules using support vector machines[C]//Proc.IJCNN 2008.Hong Kong,China:IEEE Press,2008:3093-3098.
[2]滕卫平.甲状腺癌规范化诊治及医源性甲减研讨会纪要[J].中华内分泌代谢杂志,2007(23):571.
[3]李莉,木拉提·哈米提.医学影像数据分类方法研究综述[J].中国医学物理学杂志,2011,28(6):35-38.
[4] BRAZOKOVICD.NESKOVICM.Mammogram screening usingmultiresolution based image segmentation[J].International Journal of Pattern Recognition and Artificial Intelligence,2001,7(6):1437-1460.
[5] LIH.Markov random field for tumor detection in digital mammography[J].IEEE Trans.Medical Imaging,2000,14(3):565-576.
[6] BOTTIGLIU.GOLOSIO B.Feature extraction from mammographic images using fastmatching methods[J].Nuclear Instruments and Methods in Physics Research,2002(487):209-215.
[7]王凯芸.孟丽莉.基于影像数据系统的人工神经网络模型研究——乳腺癌的早期诊断模型[J].中国数字医学,2010,5(4):45-49.
[8]陈健美,宋顺林,朱玉全,等.一种基于贝叶斯和神经网络的医学图像组合分类方法[J].计算机科学,2008,35(3):244-246.
[9]宋余庆,谢从华,朱玉全.基于近似密度函数的医学图像聚类分析研究[J].计算机研究与发展,2006(11):1947-1953.
[10]张壮暑,蔡晓东,张学敏.监控视频中运动目标识别分类系统研究[J].电视技术,2012,36(23):165-167.
[11]张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32-41.
[12]张建飞,陈树越,刘会明,等.基于支持向量机的交通视频人车识别研究[J].电视技术,2011,35(15):1-3.
[13] ZHUANG L,SHE L,JIANG Y,et al.Image classification via semi-superuisen PlSA[C]//Proc.Fifth International Conference on Image and Graphics,ICIG 2009.Xi’an:[s.n.],2009:205-208.
[14] CHEN B.Exploring the use of latent topical information for statistical Chinese spoken document retrieval[J].Pattern Recognition Letters,2006,27(1):9-18.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
