
基于面向服务架构的遗留系统集成研究与实现
2014-11-15 02:08王靖娜张建华
电子测试 2014年4期
王靖娜,张建华
(1.陕西广播电视大学,西安,710119;2.西安科技大学,西安,710054)
0 引言
企业在构建新的信息统时,如何有效重用遗留系统(Legacy System,LS)是一个必须考虑的问题,然而由于遗留系统自身存在的一些问题,传统的重用机制并不能很好应对这些情况。近年来随着SOA技术迅速发展,业界普遍将这种思想引入遗留系统的集成领域。
面向服务架构(Service-oriented architecture,SOA)是基于请求/响应模式的分布式设计范型的一种演化,一个应用程序的业务逻辑(Business logic)或某些单独的功能被模块化并作为服务呈现给消费者或客户端。SOA思想实现的关键在于如何建立一套程序到程序的通信模型,而Web Service用现有的和新兴的一组协议建立了一套平台无关、语言无关、通用的通信模型,成为目前最为流行的SOA实现。目前,包括IBM,Microsoft,Sun,Oracle和BEA等在内的各大公司纷纷宣布在他们的产品中支持Web服务。现有的Web Servic Platforme平台主要有IBM WebSphere,HP Web Services,Sun ONE,Microsoft Dot NET。然而这些产品更适合开发新的服务而非集成遗留系统,所以从一个实际项目的需求出发,结合遗留子系统较多且松散分布及对系统安全稳定性能的要求,本文提出了基于SOA的系统信息集成框架,较好地解决了传统信息集成技术构建的集成系统不易维护、缺乏扩展性及动态调整性以及应用范围狭窄等方面的缺陷。
1 遗留系统集成技术分析
如何将遗留系统迁移到新的企业应用平并不是一个新鲜的问题,在过去几十年间人们尝试了很多方法来提高遗留系统集成效率,归纳起来主要有以下几种:
重新开发(Redevelopment):利用新的硬件平台、架构、工具、数据库等从头开始实现遗留系统所提供的服务。
包装(Wrapping):围绕已有数据、独立程序、应用系统及接口用新接口进行包装以便于其它系统访问。
迁移(Migration):在保留原有系统的数据和功能的前提下,利用新技术将遗留系统移植到新的平台中。
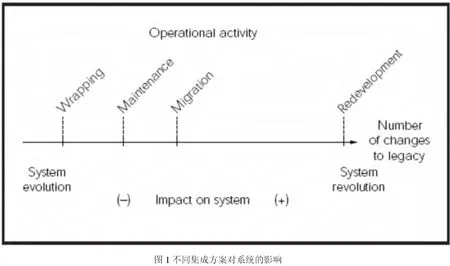
图1显示了常用的遗留系统集成方法。由于维护(Maintenance)也是软件生命周期中的一部分,所以出于完整性考虑将其加入其中。这当然不影响上文的分类,因为如果一个软件系统的在可接受的预算范围内被维护,它也不能被称为遗留系统。如图所示每种方法的风险和代价是不同的,其中重新开发代价最大,而包装对遗留系统最小,在实际的应用中重新开发的策略也很少被用于遗留系统的集成。
在业界的实际应用中,先后出现了基于公共请求代理体系(CORBA),远程方法调用(RMI),分布式组件对象(DCOM)以及Agent等分布式对象技术。由于这些技术自身的一些缺点,导致它们在遗留系统的现代化领域均未流行开来。RMI的实现要求通信的两端都具有Java环境,从根本上阻止了它的推广;CORBA虽然定义了一种语言无关的通信方式,但企业防火墙通常会阻止对象请求代理(Object RequestBroker,ORB)的通信;基于COM,DCOM遗留系统的集成要求集成环境中的计算机节点都支持Windows系统;基于Agent的遗留系统信息集成充分考虑了遗留系统的特点,但对于一个拥有众多遗留系统的企业,要实现各个遗留子系统Agent之间的互相通信和协同操作,困难很大。与此同时,作为一种松散藕合及可复用的分布式计算模型,面向服务的架构也越来越多地被用于遗留系统集成。已有的方法都从重用的角度不同程度的实现了遗留系统的服务集成,但就其方法的实质来说,都没有超出上文所述的三种形式,尤其是包装和迁移。
2 集成框架
2.1 遗留系统集成的基本要求
考虑到遗留系统自身的特点,实现遗留系统信息集成会受到多方面的限制,在实现技术方面应满足以下基本要求:①遗留系统的信息集成应该是遗留系统具体应用的集成,应支持业务正常运转所需信息的正常交互,而不是遗留系统简单的互连及信息交换。②集成是动态的,能根据企业经营策略及需求变化来及时调整集成方式;③应充分考虑新业务对安全稳定运行的要求,保证遗留子系统在集成后仍能保持单独运行时的安全稳定性;④遗留系统的信息集成应该是对原有遗留子系统功能的扩展和延伸,而不是推倒遗留子系统原有的所有功能。
2.2 体系结构
基于遗留系统集成的基本要求和SOA架构的思想,考虑将遗留系统中需要暴露的功能包装成Web服务,这样遗留系统间既可以Web服务的形式进行信息交互,又保证了遗留系统的功能、安全性、稳定性不受影响。
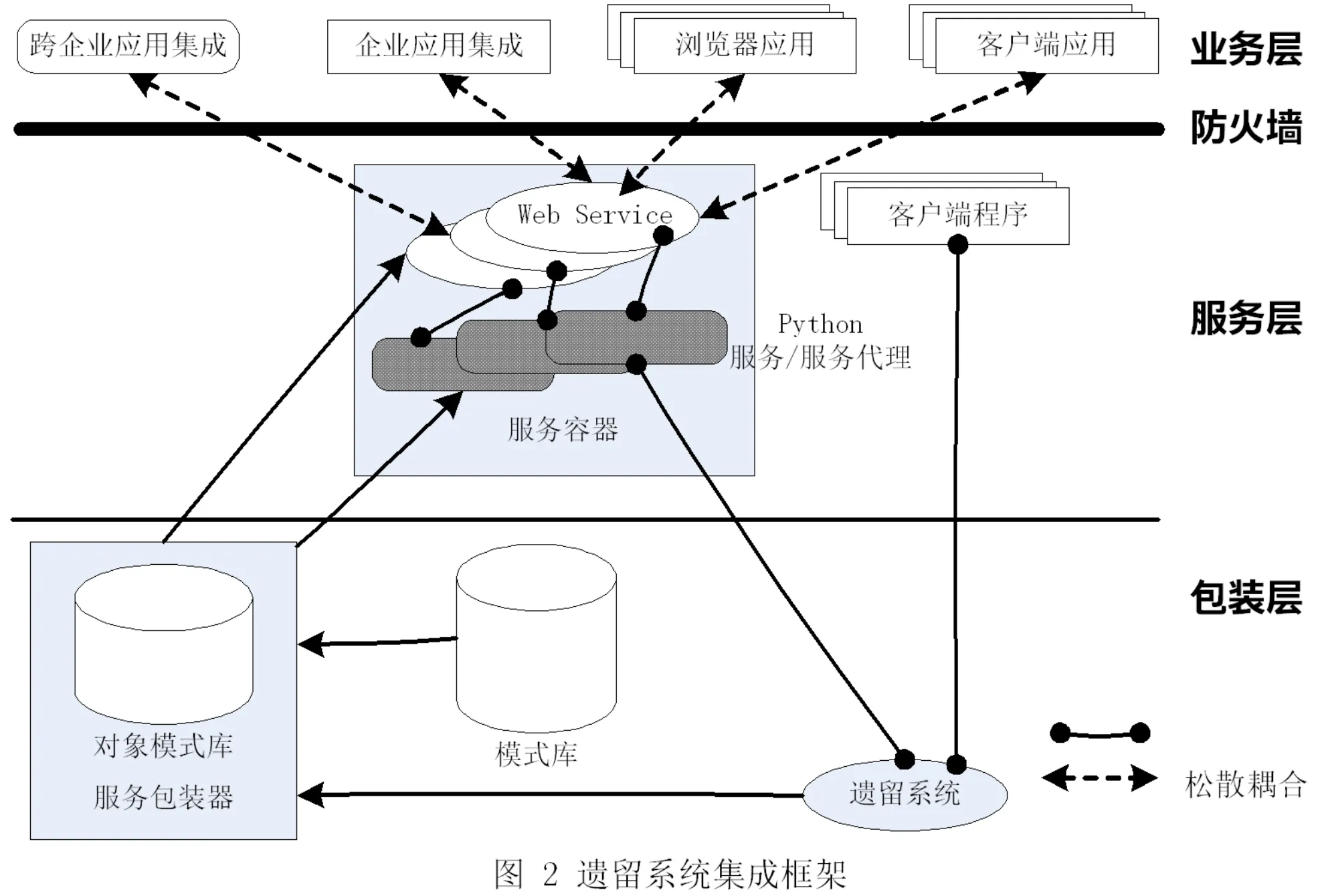
图2所示的笔者提出的遗留系统服务集成分层体系结构,其主要由业务层、服务层、包装层三个层次组成。业务层是服务的使用者或客户,它与服务层以服务的WSDL作为交互契约,通过SOAP消息进行交互。服务层主要负责处理来自业务层的各种服务调用请求以及服务提供者的响应,该层主要包括:服务容器和服务代理。处于最下层的是包装层,它为各种遗留系统生成服务代理,其主要由服务包装器组成。
服务容器:服务提供者与服务使用者之间的桥梁,它监听服务请求端口,处理所有来自于客户的服务调用请求以及服务运行结果的发送。
服务代理:屏蔽不同遗留系统所提供服务由于实现技术上的不同而造成的服务调用上的差异,完成实际服务的转调工作。主要有两种形式的服务代理:①Python脚本,它可以是对遗留系统服务的转调代码,也可以是实际的服务。②Python扩展,它是用C/C++写成的一种特殊的动态链接库,在某些情况下Python对所需服务不能直接支持或效率方面不能达到业务需求就要通过效率更高C/C++提供支持,而Python扩展恰好在二者之间架起了桥梁。
服务包装器:负责生成遗留系统的服务代理,遗留系统的提供服务并不直接进入SOA体系,而是经过包装也即生成代理及WSDL文件后成为Web服务才融入到整个企业的业务流程中。它中要由以下模块组成:①包装对象模式库即一组针对基于不同实现技术的遗留系统服务包装的内置对象,它是遗留系统服务包装的控制器。②服务元信息模型,遗留系统服务信息的内存模型,它主要包括:遗留系统对外所提供服务的接口定义、服务实现技术类型的描述信息、以及服务的运行时信息。③代码生成器,根据服务元信息为包装器生成产生服务代理的各种中间代码。④make文件生成器,为包装器生成编译Python扩展所需的make文件。
2.3 服务包装流程分析
服务集成的一个关键步骤就是将遗留系统所提供服务包装为Web服务,在集成框架中这一过程由服务包装器来完成。服务包装器包装服务的典型过程分为五个阶段:元信息获取、产生代理代码、生成临时工程、生成make文件、生成服务代理。
元信息获取:集成人员通过用户界面将遗留系统服务元信息送入元信息文档对象,输入内容形式有两种:一种是详细的服务元信息;另一种包含服务元信息的数据文件。
产生代理代码:接着将包含有服务信息的元信息文档对象传入相应类型的服务集成对象,包装器为不同类型的遗留系统提供了不同包装对象。有了服务的元信息,包装对象就为该遗留系统生成代理代码并将之填入元信息文档对象的适当子对象。
生成临时工程:包装对象以元信息文档对象作为基础调用代码生成器生成用于编译的服务代理临时工程及其配置文件,临时工程包含了生成最终Python扩展的所有文件,而配置文件包含的对于编译器有价值的配置信息。
生成make文件:包装对象将临时工程配置文件送入make文件生成器为临时工程生成用于自动编译的make文件。
生成服务代理:包装器将make文件作为输入,调用编译器提供的make工具编译临时工程生成服务代理。
3 关键技术
服务元信息模型
服务元信息是集成框架进行包装的信息基础,集成框架用一组内建的元信息模型来存储这些信息供包装的不同阶段使用。而元信息模型提供一组接口供客户程序操作元信息,通过这组接口所有服务元信息就可以被添加到元信息模型中,反之亦可取出。元信息模型主要包含两信息:服务包装信息、接口信息。服务包装信息中包含了一些关于服务实现的描述信息,接口信息则给出了服务接口定义。
服务包装信息大体分为两类:服务类型无关信息和服务类型相关信息。服务类型无关信息是各种不同类型遗留系统服务所共有的,如服务的名字、目标存放位置等。服务类型相关信息则由于各遗留系统服务实现技术的不同而不同,例如当遗留系统以COM组件形式提供服务时要对其进行包装就需知道该组件的ProgID。包装器根据这些信息为服务的接口生成不同的代理代码。
接口描述信息是遗留系统对外提供服务的详细接口定义,集成框架以这些定义为基础,生成接口的服务的代理接口及WSDL文件。
3.1 Python扩展
虽然Python是一种功能强大的脚本语言,但是对于某些系统调用或库函数,其语言本身是无能为力的,Python通过一种称之为扩展(Extension)的机制来达到这一目的。它提供了一系列的C函数接口、宏、变量来暴露其运行时系统,结合待调用的库函数或系统调用生成扩展动态链接库就可以就可以将所需功能引入到Python环境之中,象普通模块一样调用。然而直接通过这些接口函数手动生成Python扩展是一种复杂易于出且重复性高的过程,因此在生成扩展模块时,使用了Boost.Python库。Boost.Python 库是Python和C++之间的一个接口框架,它使用了先进的元编程技术来简化用户使用的语法,这样用户可以使用类似描述性的定义语言来快速、无缝的将C++中的函数和对象暴露给Python,反之亦然。它采用一种无侵入的设计方法,这样包装时就可以不对待包装代码做任何修改,这也使得Boost.Python成为一种理想的用于C++和Python接口的第三方库。其使用的基本步骤如下:
3.2 引入Boost.Python所需头文件及名字空间
将模块的名字作为参数送入BOOST_PYTHON_MODULE宏定义扩展模块。
将函数名字及函数指针传入def宏定义要暴露的C++函数。
以类名作为参数使用class宏定义要导出的C++类。
3.3 make文件产生器
当包装获取到足够的关于服务元信息后,集成人员就应该不需要再介入包装过程,而实现这一目标的关键步骤就是Python扩展的自动编译。生成Python扩展主要元素:代理接口定义、代理接口实现和Boost.Python扩展定义通过代码生成器都可以产生,这时只要使用编译器对由以上元素组成的工程编译即可生成Python扩展,而此时自动编译的关键就是生成make工具所需的make文件。
对make文件研究发现,其配置信息可抽取为两类:Python扩展所需的特定工程配置及特定编译器针对不同配置具体参数。工程配置信息由包装产生,而编译器配置参数则只要一次写入文件后就可以重复利用。
4 总结
在研究了以往工作的基础之上,本文提出了一种基于SOA的遗留系统的集成方案。它考虑了遗留系统的特点给出了特定类型服务的代理代码自动生成模式,给合SOA的通用通信模型解决了服务之间的松耦合的互操作问题,吸取了动态语言Python的优点简化了服务容器的设计,提高了服务集成的扩展性,很好的满足了实际项目需求。
[1]Jesus Bisbal,Deirdre Lawless,Bing Wu,and Jane Grimson.Legacy Information Systems:Issues and Directions.IEEE Software,September/October 1999.
[2]Eric Newcomer,Greg Lomow.Understanding SOA with Web Services.Addison Wesley Professional,2004-12.
[3]Mark Endrei,Jenny Ang,Ali Arsanjani,Sook Chua,Philippe Comte,Pal Krogdahl,Min Luo,Tony Newling.Patterns:Service-Oriented Architecture and Web Services.IBM 2004-04,33.
[4]Jack Herrington.Code Generation in Action.Manning Publications Co.2003,28-34.
[5]Ethan Cerami.Web Services Essentials.O'Reilly,February 2002.
猜你喜欢
美与时代·美术学刊(2021年1期)2021-03-19
商品与质量(2019年34期)2019-11-29
趣味(数学)(2018年12期)2018-12-29
测控技术(2018年5期)2018-12-09
现代营销(创富信息版)(2018年8期)2018-09-08
电子制作(2018年11期)2018-08-04
信息安全研究(2016年4期)2016-12-01
岁月(2016年5期)2016-08-13
乡村地理(2016年2期)2016-06-15
中国火炬(2014年1期)2014-07-24
