
如何客观评测内存数据库的性能
2014-10-31 06:54:34康强强金澈清胡华梁周傲英
华东师范大学学报(自然科学版) 2014年5期
康强强, 金澈清, 张 召, 胡华梁,2, 周傲英
(1.华东师范大学 软件学院 数据科学与工程研究院,上海 200062;2.浙江理工大学 经济管理学院,杭州 310033)
0 引 言
在过去的10年间,随着硬件迅速发展,内存价格显著降低,一个典型的计算机系统往往会布置大容量内存.数据库产品提供商于是投入大量资源来开发内存数据库,以提高数据处理吞吐量,其中包括SAP公司的 HANA[1],Oracle公司的 TimesTen[2],还有开源的 MonetDB[3]等等.内存数据库需要预先将数据装载到内存中,从而避免了后续的数据管理阶段的I/O开销.随着诸多内存数据库产品的问世,如何公平、客观地评测这些内存数据库的性能也变得愈发重要.
数据库基准旨在客观、公正地评测数据库产品的性能,以激励数据库厂商优化其产品.自从威斯康星评测基准被提出以来,数据库评测基准已在过去30年里取得了巨大的成功[18].事务处理性能委员会(Transaction Processing Performance Council,TPC)提出了一系列基准来评测关系型数据库,包括TPC-C、TPC-H、TPC-E、TPC-DS等,得到学术界和工业界的广泛认可.其他典型基准包括混合了TPC-C和TPC-H工作负载的CH-Benchmark[4]和针对决策支持系统的星型模式评测基准(Star Schema Benchmark,SSB)[5].此外,针对非关系型数据库的评测基准包括针对NoSQL数据库的YCSB测试基准[6]和针对面向对象数据库的Bucky测试基准[7]等.传统数据库系统将数据存储于磁盘之中,再通过大量I/O操作执行数据管理任务,现有基准均力求反映这一重要特性.然而,与传统数据库相比,内存数据库具有以下重要性质:(1)启动时加载:内存数据库需要将数据预先加载到内存中.(2)数据组织:内存数据库并不局限于采用行存储方式,也可采用列存储方式,或者同时支持两种数据存储方式.(3)数据压缩:内存数据库系统广泛采用数据压缩技术,以在内存之中存储更多数据.总之,现有数据库基准并不适合评测内存数据库,亟需设计新基准进行评测,以充分反映以上若干特性.
本文设计了一个新的数据库基准(InMemBench)来评测内存数据库系统.该评测标准的数据库模式包含8张表:2张大表和6张小表.大表的字段较多,分别超过100列和200列;小表的列数较少,不超过30个.该基准还包括一个并行数据生成工具COLGen,以产生模拟数据.该基准拥有4个新颖的度量:启动消耗(Startup Cost)、压缩率(Compression Ratio)、每小时执行查询个数(Query per hour),和列扩展性(Column Scalability).在工作负载方面,该基准包括2种类型,分别聚焦读操作和写操作.
本文第1节描述相关工作,第2节介绍数据库模式,第3节介绍度量指标,第4节介绍工作负载和执行计划,第5节报告实验结果,并在最后一节总结全文.
1 相关工作
随着数据库技术不断发展,数据库评测基准也获得较大提高.从20世纪80年代开始,学术界和工业界已经研发出多款数据库评测基准,包括针对关系型数据库的威斯康星测试基准(Wisconsin)和TPC系列,针对面向对象数据库的 OO7[8]和bucky[7]评测基准,针对XML数据的 XMark[9]和 EXRT[10]评测基准,还有针对于大数据应用的 YCSB[6]和 Big-Bench[11]评测基准等.
近期,内存数据库技术得到了较大发展,典型代表包括SAP的HANA、Oracle的TimesTen,微软的Hekaton,还有开源的HyperSql、SQLite、MemSql和 MonetDB等,这些数据库均采用关系数据模型.威斯康星基准是一款较早的评测基准,其数据库模式较为简单,较好地评测了当时的数据库产品.TPC开发了一系列数据库基准来评测数据库,包括针对于在线事务处理(Online Transaction Processing,OLTP)的TPC-C和 TPC-E,针对在线分析处理(Online Analytical Processing,OLAP)的 TPC-H 和 TPC-DS.CH-Benchmark则混合TPC-C和TPC-H的特点,可同时评测数据库OLTP和OLAP功能.Set query基准[12]使用一组基本的查询语句,从文档查询、市场决策支持的角度来评估数据库的性能.星型测试基准SSB使用星型数据模型来测试数据库的性能,这样做主要是为了支持传统的数据仓库的应用.
然而,以上评测基准并未充分考虑内存数据库的特性,因此并不适合内存数据库.研究人员尝试采用现评测基准来评估内存数据库的性能,但是在度量选取等方面并未全面地契合内存数据库的特性[13-17].本文所提出的新基准则尝试更加全面地解决了以上问题.
2 数据模型
本节先描述数据库模式及其特点,再介绍数据生成器COLGen.
2.1 数据库模式
图1描述了InMemBench的数据库模式.该模式使用了8张表来描述一个零售产品供应的应用场景.PART表描述销售的零件,SUPPLIER表和CUSTOMER表描述零件的提供商和所有客户,NATION表和REGION表描述供应商和客户来自的国家和地区.由于一个零件可能有不止一个提供商,因此使用PARTSUPP表来描述此依赖关系.最后,ORDERS表描述客户的所有订单,每个订单的详细信息存储在LINEITEM表中.这个模式源于TPC-H数据库模式,但为了适应内存数据库而进行了若干调整.

图1 数据库模式Fig.1 Database schema
主要的扩展包括两处.第一,向LINEITEM表中添加200个字段,名为:COLUMN1,…,COLUMN200,分属3种数据类型:字符型char、数值型decimal(13,2)和日期类型date.在这新添的200个字段中,规定20%的字段使用数值型,剩下的20%和60%分别使用日期类型和字符类型.第二,向ORDERS这张表中添加100个字段,这100个字段也是有数值型、字符型和日期型3种类型组成,分别命名为抽象字段COLUMN1,…,COLUMN100.在这新添的100个字段中,他们的类型分布和LINEITEM这张表是一样的.这样设计的想法最初来自于真实的销售场景中,有些大型企业,例如淘宝和亚马逊,它们的销售表往往是超过16个字段的(TPC-H最大的表字段个数是16).因此,这需要对维护销售明细的字段进行一个扩展.其实,这两张表中所有新加的字段在实际的销售场景中也有明确的含义,例如,LINEITEM这张表就有表示物品毛重和净重的新增字段.考虑到空间的限制,这里没有列出其他198个字段的介绍.这样设计的另外一个想法是,足够多的字段给我们评测行存储数据库和列存储数据库提供了一个可能途径.
本数据库模式的一个主要特点是“动态可适应性”:即LINEITEM和ORDERS表中的字段个数会改变.该动态模型主要包含6张小表(SUPPLIER,PARTSUPP,PART,REGION,NATION和CUSTOMER)和2张大表(LINEITEM和ORDERS).模型的动态变化主要是2张大表中新增字段个数的变化.例如,在模型的5次动态变化过程中,每一个状态下2张大表新增的字段数目分别占新增总字段的20%、40%、60%、80%和100%.这样设计是为了评测行存储和列存储2种不同存储方式的列可扩展性.
2.2 数据生成器
通过扩展DataGen(TPC-H的数据生成工具),我们研发了一个并行数据生成工具(COLGen)来产生模拟数据.该数据生成器需要使用数据字典和产生规则(如图2所示).数据字典包括了3类单词,这些单词均可通过RNG的随机选取填充到对应字段中;数据产生规则定义了各字段之间的依赖关系、单个字段值的填充形式和取值范围等.
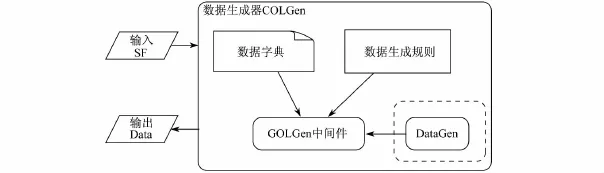
图2 COLGen的架构Fig.2 The architecture of COLGen
此外,还定义了扩展因子(Scale Factor,SF)来控制模拟数据库的规模.不同SF值对应不同的数据库规模.例如,当SF=1时,COLGen会生成10 GB数据;若SF=2,则生成20 GB数据;依次类推.
3 度量指标
本文定义了4个度量指标来评测内存数据库的性能,即:启动消耗(Startup Cost,SC@SF)、压缩率(Compression Ratio,CR@SF)、每小时查询个数(Query per hour,Qph@SF)和列处理能力(Column Scalability,CS@SF).
· 启动消耗SC@SF.启动消耗描述将数据从磁盘装载到内存所耗费的时间.各内存数据库都需要预先将数据装载入内存中以进行管理.
· 压缩率CR@SF.数据的压缩率描述内存数据库压缩数据的能力.如前所述,内存数据库会对数据进行压缩之后再存储到内存之中,以提升空间利用率.令Sdisk表示数据在磁盘上的空间容量,Smem表示数据在内存中的占用量,以下公式计算压缩率:
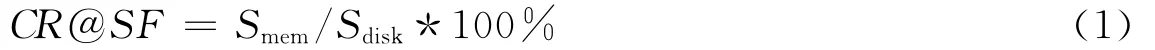
· 每小时查询个数Qph@SF.每小时查询个数描述评测任务的执行性能,执行时间包括:数据从磁盘文件装载到数据库的时间(TL)、数据从磁盘加载到内存中的时间(TS)、执行两次查询负载的时间(TQR1和TQR2)和执行更新任务的时间(TR),具体流程如图3所示:

图3 度量指标Qph@SF的执行过程Fig.3 The execution of Metric Qph@SF
从图3中可以看出,整个流程包括2次查询负载,首次执行查询负载的目的是评测数据库在装载数据之后该系统执行查询的能力,再次执行查询负载的目的是评测数据库在执行完更新操作之后该系统执行查询的能力.为了提高可读性,TL、TS、TQR1、TQR2和TR的具体执行过程会放在第4节执行计划中介绍.
公式(2)定义了Qph@SF的计算方法,其中S是执行测试计划的并发用户个数,共有16个查询任务(执行2次查询负载,每个查询负载种包括8个查询),0.01是装载时间可并入总的消耗时间的比例,指的是进行一次该执行过程可算入在内的有效装载时间.该权重值较小的原因是数据装载仅在数据库启动时运行一次,而查询则会经常执行.因为上述过程都是以秒(s)为单位进行记时,因此需要在公式中乘以3600进行单位换算.文献[19-20]使用一个相似公式计算每小时的查询个数.
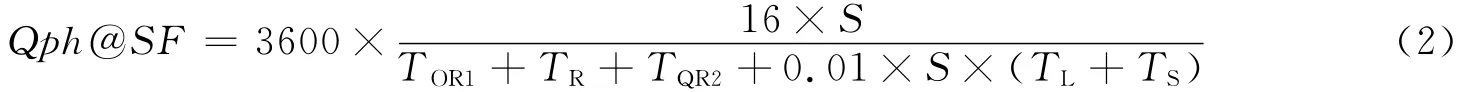
· 列扩展性CS@SF.这个指标描述内存数据库系统的列扩张能力.如前所述,内存数据库中存在2种数据组织方式:列存储和行存储.一般说来,当需要执行某个分析任务时,只有一张表中的少部分字段是需要处理的[17].CS@SF的设计目标就是测量某个内存数据库在字段个数不断变化情况下的性能.正如第3节数据模型介绍的那样,2张大表LINEITEM和ORDERS的字段个数不是固定的,会随着数据库模式动态适应而不断改变.那么就记录了不同数据模式下数据库系统完成图3中的执行过程所需要的时间.公式(3)形式化地定义了CS@SF.其中T1,…,T5分别表示不同模型下数据库的执行时间.具体的测试过程会在第5节执行计划中介绍.
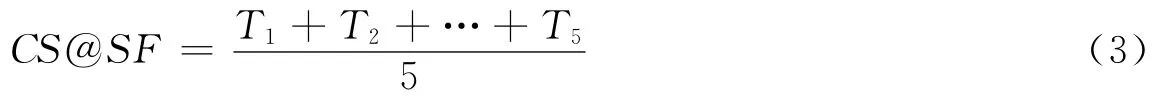
表1总结了InMemBench和其它现有评测基准的差异.和现有基准类似,InMemBench也可评测数据库系统的常用特性,例如吞吐量和多用户模式.此外,新基准还能评测内存数据库的若干特性,而现有基准并未考虑到这些因素.
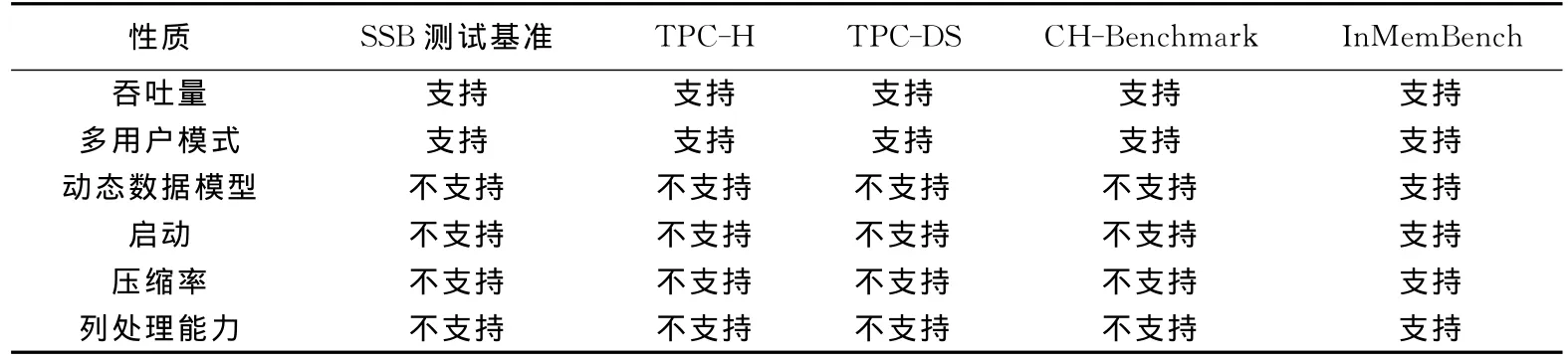
表1 InMemBench和其他评测基准的比较Tab.1 The comparison of InMemBench and other benchmarks
4 工作负载和执行计划
本节首先描述了查询和更新负载,然后提出两个执行计划.
4.1 查询负载
查询负载共包括3组查询,每组分别包括3、3和2个查询.以下详细描述各查询组.
· 查询组1:主要是针对表LINEITEM,有sum、avg和count等聚集函数.根据过滤条件(where子句)划分,共有3个查询,如查询组1所示,其中DELTA1和DELTA2是2个输入参数.

查询组1的查询
查询1.1 DELTA1=1992-01-01 and DELTA2=1992-12-01
查询1.2 DELTA1=1992-12-01 and DELTA2=1994-12-01
查询1.3 DELTA1=1994-12-01 and DELTA2=1995-12-01
· 查询组2:主要是针对LINEITEM和ORDERS 2张表,包括3个查询.因为是对2张表进行连接操作,所以这个查询组消耗的内存空间比第一个查询组要大.如查询组2所示,SHIPMODE1、SHIPMODE2和DELTA是输入参数.

查询组2的查询
查询2.1 SHIPMODE1=FOB,SHIPMODE2=TRUCK and DELTA=1996-12-01
查询2.2 SHIPMODE1=TRUCK,SHIPMODE2=SHIP and DELTA=1997-06-01
查询2.3 SHIPMODE1=SHIP,SHIPMODE2=AIR and DELTA=1997-12-01
· 查询组3:对所有8张表进行连接操作,其内存消耗量最大.该查询组包括两个查询,由参数DELTA1和DELTA2决定,如查询组3所示.

查询组3的查询
查询3.1 DELTA1=1994-01-01 and DELTA2=1996-01-01
查询3.2 DELTA1=1992-01-01 and DELTA2=1998-12-01
在上面查询组中,可以看到查询组1的每个查询获取的数据是没有交集的,然而查询组2和查询组3获取的数据是有重复的.因此在执行查询组1时,缓存(caching)没有起到加速的作用.当执行查询组2和查询组3时,缓存会重复利用前面的查询结果,于是会加速执行过程.同时需要注意的是,查询组2中的每个查询获取的数据和查询组1是没有交集的,而查询组3和查询组1是有交集的,于是当查询组3放在查询组1后面执行的时候,缓存会加速执行过程.实际上,3个查询组按照数值生序顺序依次执行,缓存会在数据有重复的两个查询中加速执行过程.
4.2 更新负载
该负载主要用于图3中的更新负载执行过程,它主要在查询负载1和查询负载2之间执行.它主要包括两个部分:插入操作和删除操作.首先,测试系统会向表LINEITEM和ORDERS插入占原始记录为0.1%的新记录.随后,所有新增加的记录会被删除.需要注意的是,所有的更新数据都是由数据生成器COLGen预先生成,数据记录大小和SF的比例是1500∶1.
4.3 执行计划
本文前面提出了4个度量标准从不同的角度测试内存数据库系统的性能.然而,这4个指标并不能在一次执行过程中全部完成测试.因此设计了2个执行计划来完成这一目标.第1个计划(计划1)旨在测试启动消耗(SC@SF),压缩率(CR@SF)和每小时的查询个数(Qph@SF),通过执行图3的过程,可以计算出上述的3个度量指标.第2个测试计划(计划2)来评估某个数据库的列扩展性(CS@SF),这个测试需要不断改变数据库模式中的字段个数.
计划1:测量启动消耗、压缩率和每小时查询个数
执行这个测试计划之前,需要预先设置SF的值来确定数据库的大小.为了支持多用户的模式,S的值也需要预先指定.这个值表示查询流的数目,每个查询流表示一个用户.整个执行过程如图3所示,首先,启动数据库将测试数据从磁盘文件装载到数据库中,然后,数据库将所需的数据从磁盘装载到内存中,依次执行查询负载1,更新负载和查询负载2.查询负载1和查询负载2是相同的,包括8条查询语句.
在上面的执行过程结束之后,可以记录TL、TS、TQR1、TQR2和TR.接着,启动消耗SC@SF和每小时查询数Qph@SF可以直接计算得到.为了测量压缩率,可以分别记录数据在磁盘和内存中的大小,然后用公式(1)计算求出.
计划2:测量列扩展性
这个测试是一个迭代的过程,因为需要不断改变数据库模式中字段的个数.通过改变LINEITEM和ORDERS这两张表新增字段的数目.例如,在LINEITEM(ORDERS)这张表中,用所有新增200(100)个字段中的20%、40%、60%、80%和100%来构建每次迭代过程中的不同数据库模式.对该测试计划来说,需要预先指定SF的值来确定数据的大小.在每次迭代开始前,要重启数据库,执行图3中的每个过程,记录相应的时间T1,…,T5,最后用公式(3)计算得出CS@SF.
5 实 验
这一节通过一系列的实验去评测内存数据库系统.我们以数据库X,Y,Z和MonetDB作为实际例子.内存数据库X和MonetDB支持列存储组织方式,内存数据库Y和Z支持行存储组织方式.被测试平台有1 TB的内存容量和8个CPU.在默认情况下,每个内存数据库可以使用的最大内存容量为0.8 TB.
(1)压缩率实验
图4(a)描述了随着SF的变化,4个系统压缩能力的改变.可以看到,系统X和Monet-DB有更好的压缩能力,基本可压缩原始文件的80%,对于系统Y和Z,数据在压缩之前和压缩之后基本没有发生太大的变化.这是因为X和MonetDB都是以列存储方式为主,这种存储方式可以把同一个字段的数据在物理上组织到一起.
(2)启动消耗实验
图4(b)描述启动消耗随SF增大而变化的趋势,从图中可以看到系统X和系统Y的启动消耗都是随着SF不断增大的.然而,在同等数据量的情况下,系统X需要更少的启动消耗,这是因为系统X有着更好的压缩能力.
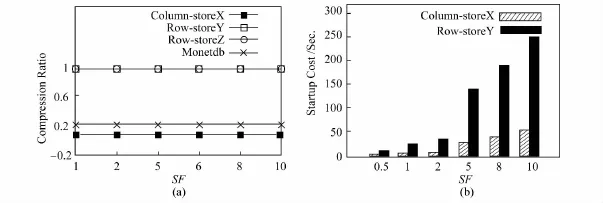
图4 压缩率和启动消耗的评估Fig.4 Testing and evaluation for the compression ratio and startup cost
(3)每小时查询数实验
图5(a)描述了当SF为5时,每个查询和更新操作的执行时间.在执行前6条查询的时候,列存储系统表现的性能更好,这是因为它只需要获取部分字段为将来的操作.而且前6条查询主要是涉及到两张表,进行连接操作中间产生的数据量也比较少.在执行后面2个查询时,行存储系统Y表现出了更好的性能,这是因为后面2个查询涉及到8张表的连接操作,中间会产生很多的数据,而且列存储系统需要执行更多额外的解压缩的操作.对于更新操作来说,行存储比列存储的性能要好,这是因为记录本身是按照行存储的物理组织方式进行插入的.图5(b)显示了随着SF的增长,所有查询的时间也随之增长,使用公式(2)计算每小时的查询个数(Qph@SF).
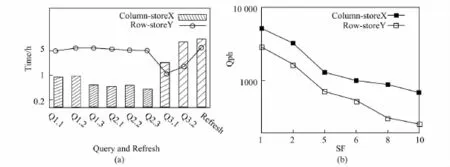
图5 每小时查询数的评估Fig.5 Testing and evaluation for query per hour
(4)列扩展性实验
在这一部分,图6(a)描述了当SF设置为5时每个模型执行图3的过程所需要的时间(单位为s),可以看到系统X随着模型的不断改变基本不发生太大的变化,然而系统Y却随着模型中字段个数的增加执行时间也不断变大.这是因为列组织方式的数据库只需要查询将需要处理的字段,而行存储的组织方式则需要读取全部的字段.随着列数的降低,系统Y的性能超过系统X,这是因为在数据量相差不大的情况下,使用索引可以很好地加快行存储组织的数据库,对于列存储组织的数据库,索引一般没有任何作用.随后,图6(b)表明,系统X和系统Y随着SF的增加,整体执行时间也不断增大.

图6 列扩展性的评估Fig.6 Testing and evaluation for column scalability
6 总 结
本文提出了针对内存数据库的测试基准InMemBench.这个测试基准充分考虑了内存数据库的主要特性,与之相应地,提出了4个度量去客观公正地评估内存数据库的性能.除此之外,该测试基准还包括自适应动态数据库模式、测试计划、查询和更新的工作负载.最后,对4个内存数据库进行了大量的实验来验证所提测试基准的有效性和执行效率.在未来的研究工作中,我们会设计更为复杂的查询以及对更多的内存数据库进行实验验证.
[1] FÄRBER F,CHA S K,PRIMSCH J,et al.SAP HANA database:data management for modern business applications[J].SIGMOD Record,2011,8:45-51.
[2] lAHIRI T,NEIMAT M A,FOLKMAN S.Oracle TimesTen:an in-memory database for enterprise applications[J].IEEE Data Eng Bull,2013:6-13.
[3] BONCZ P A,KERSTEN M L,MANEGOLD S.Breaking the memory wall in MonetDB[J].Commun ACM,2008,51(12):77-85.
[4] COLE R,FUNKE F,GIAKOUMAKIS L,et al.The mixed workload CH-benCHmark[C].DBTest,2011,8:1-8:6.
[5] RABL T,POESS M,JACOBSEN H A,et al.Variations of the star schema benchmark to test the effects of data skew on query performance[C].ICPE,2013:361-372.
[6] COOPER B F,SILBERSTEIN A,TAM E,et al.Benchmarking cloud serving systems with YCSB[J].SoCC,2010:143-154.
[7] CAREY M J,DEWITT D J,NAUGHTON J F,et al.The BUCKY object-relational benchmark(Experience Paper)[C]//SIGMOD Conference,1997:135-146.
[8] CAREY M J,DEWITT D J,NAUGHTON J F.The 007 Benchmark[C]//SIGMOD Conference,1993:12-21.
[9] SCHMIDT A,WAAS F,KERSTEN M,et al.XMark:A benchmark for XML data management[C]//Proceedings of the 28th international conference on Very Large Data Bases,2002:974-985.
[10] CAREY M J,LING L,NICOLA M,et al.EXRT:towards a simple benchmark for XML readiness testing[C]//TPCTC,2010:93-109.
[11] GHAZAL A,RABL T,HU M,et al.BigBench:towards an industry standard benchmark for big data analytics[C]//SIGMOD Conference,2013:1197-1208.
[12] PATRICK E,NEIL O.A set query benchmark for large databases[C]//Int CMG Conference,1989:710-721.
[13] LIU D,LUAN H,WANG S,et al.Main memory database TPC-H workload characterization on modern process[J].Journal of Software,2008,19(10):2573-2584.
[15] TÖZÜN P,PANDIS I,KAYNAK C,et al.From A to E:analyzing TPC’s OLTP benchmarks:the obsolete,the ubiquitous,the unexplored[C]//EDBT,2013:17-28.
[16] PLATTNER H.A common database approach for OLTP and OLAP using an in-memory column database[C]//SIGMOD Conference,2009:1-2.
[17] ABADI D J,MADDEN S,HACHEM N.Column-stores vs.row-stores:how different are they really[C]//SIGMOD Conference,2008:967-980.
[18] GRAY J.Benchmark Handbook:For Database and Transaction Processing Systems[J].San Francisco:Morgan Kaufmann Publishers Inc,1992.
[19] NAMBIAR R O,POESS M.The making of TPC-DS[C]//VLDB,2006:1049-1058.
[20] POESS M,NAMBIAR R O,WALRATH D.Why you should run TPC-DS:a workload analysis[C]//VLDB,2007:1138-1149.
猜你喜欢
江苏科技信息(2022年16期)2022-07-17 09:07:36
家庭影院技术(2021年2期)2021-03-29 07:19:02
家庭影院技术(2021年1期)2021-03-19 05:14:58
中国自行车(2018年11期)2018-12-03 08:20:30
科学与财富(2018年26期)2018-10-24 15:31:44
科技信息·中旬刊(2018年4期)2018-10-21 03:34:14
中国自行车(2017年1期)2017-04-16 02:54:06
滁州学院学报(2016年5期)2016-12-16 07:41:46
科教导刊·电子版(2016年23期)2016-10-31 21:27:33
图书馆建设(2015年10期)2015-02-13 03:48:27
