
面向社交数据流连续查询的基准评测
2014-10-31 06:54:34钱卫宁
华东师范大学学报(自然科学版) 2014年5期
李 叶, 夏 帆, 钱卫宁
(华东师范大学 数据科学与工程研究院,上海 200062)
0 引 言
社交媒体服务被广泛应用于记录和分享用户的所见所闻所想,已经成为现实世界中感知事件发生的重要手段.如今,社交媒体数据正迅速成为最热门的市场研究资料,被数据科学家视为金矿,其在集群行为感知与监控、在线广告、意见挖掘等方面的应用层出不穷;而这些应用的成功,正是依赖于对社交媒体数据的有效分析.社交数据流指元素间具有联系的数据流,常被用于对社交媒体数据进行建模.不仅如此,它还能被用来表示科技文献和科学观测的数据.
社交数据流上的连续查询处理是基于实时的社交数据应用的关键.传统数据库处理持久存储的数据处理模式已不能适应现在大量的实时在线应用需求:数据到达过程是连续的,数据的查询处理要求是单步处理,既来不及储存也无法存储流数据.流数据管理系统可实现连续查询、实时查询、适应的数据及数据量的变化等功能,是存储和管理社交媒体数据的最佳选择.流数据管理系统早在10年前就已经成为数据库领域的研究热点,比较成熟的流数据管理系统包括麻省理工学院的Aurora和Medusa项目[1],伯克利大学的TelegraphCQ项目[2],斯坦福大学的STREAM项目[3].文献[4]提出的Linear Road是最早的针对流数据库管理系统的评测基准,该基准模拟了高速公路收费的应用场景,数据集较为简单是该基准的一个特点.
社交媒体数据分析型的应用具有以下特征:首先,不同于传统的流数据,社交媒体数据流中的各条数据相互交织,组成了图结构的数据;例如,用户之间关系的构成了在线社交网络图数据流,信息的分享则构成了消息的传播图,而用户与消息之间的关联则将两个数据流联通起来;其次,社交媒体数据在数据分布和数据到达模式上与传统数据流均有不同,具有动态、高度数据倾斜的特点;例如少部分微博在短时间内被大量转发.然而,已有的基准测试在流数据集上并未能很好地覆盖这些特征[5].与此同时,社交媒体流数据上的查询也因为数据模型以及实际应用的不同而与传统流数据查询存在差别.综上所述,目前缺乏一个基准测试用于衡量社交数据流处理系统的整体性能.
考虑这样一个问题:在面向社交数据流的连续查询中,不同的流数据管理系统其各自的优势在哪里?不同系统在执行不同类型的查询时效果如何?针对这些问题,我们提出了一套面向社交数据流上连续查询的基准评测.
本文余下章节将作如下安排:第1节对社交数据流上的连续查询问题进行建模,介绍该基准评测中所用到的数据集,包括数据的收集及预处理,数据特征的定义.接下来第2节中介绍该基准评测的负载类型与分布,以及性能测度.最后在第3节中进行总结.
1 数据集
本节首先介绍社交媒体流数据的数据模型,然后介绍对本评测所使用的数据集.
1.1 数据流模型
在社交媒体应用中,在线社交网络是信息传播的基石,用户通过订阅好友、娱乐明星和公知等的信息流,实时地获取感兴趣的信息.随着关系亲密度的改变或者用户兴趣的迁移,用户会订阅新的用户,也会取消对已关注用户的订阅.另一方面,社交网络服务成功地降低了用户创建和发布信息的成本.每个用户既可以发布个人原创信息,也可以分享好友的观点,这些发布与分享行为产生的数据构成了社交媒体的信息流,同时所有用户的信息流按照时间序合并之后,又构成了全局的信息流.因此,本文的数据流模型将主要基于社交网络的图数据流和用户生成数据流.
图1描述了4个用户的个人社交媒体流以及每个流之间的交互关系,所有消息从左到右,从上到下就构成了全局的社交媒体流.图中左端用户间的连线表示在消息m1,1发布之时用户之间的订阅关系;如用户2和用户3均订阅了用户1,同时用户4订阅了用户3.在右端的信息流中,空心的菱形表示用户发出的消息,而实心的菱形则表示用户分享他人的消息;如图中用户1发布了3条原创消息,用户2和用户3都分享了用户1的第一条原创消息.另外,星形表示的是用户间的订阅关系,空心表示订阅,实心则表示取消订阅;如图中用户3订阅了用户1,用户4对用户1取消订阅.
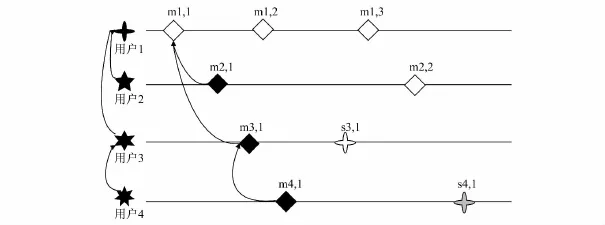
图1 社交媒体流数据Fig.1 Social stream
新浪微博将用户之间的关系定义为关注关系:若用户1订阅了用户2,则表示用户1关注了用户2,相反则为取消关注.用户发布的内容以微博的形式存在,微博可以用特定的标记来关联用户和话题,并且可以被其他用户转发.本基准评测完全基于新浪微博数据,其标准的输入主要由以下6个流组成:
(1)Tweet(type=Tweet,uid,mid,time,location,content):构成该数据流的元素是用户uid发出的一条标识符为mid的微博.其中time为该微博发出时间,location为用户所在地域,content为微博内容.
(2)Retweet(type=Retweet,uid,mid,remid,recontent,time):该数据流表示用户uid转发一条标识符为mid的微博,被转发的原始微博的标识符为remid.其中time为转发的时间,recontent为转发内容.
(3)Topic(type=Topic,topicname,mid,uid,time):该数据流表示用户uid通过发布微博mid参与了话题topicname的讨论,其中time为uid参与话题讨论的时间.
(4)Follow (type=Follow,uid1,uid2,time):该数据流记录了用户的关注行为,本条记录表示用户uid1在时间time关注了用户uid2.
(5)UnFollow(type=UnFollow,uid1,uid2,time):该数据流记录表示用户uid1在时间time取消了对用户uid2的关注.
(6)Login(type=Login,uid,time):该数据流表示用户uid在时间time登录了新浪微博.
为了方便查询的定义,我们额外定义了一张关系表followship(见表1),它用于表示某个时刻用户之间的关注网络.

表1 用户关系表Tab.1 The schema of social network
尽管数据模型中包含流数据和关系数据表,本基准不限制系统采用的数据模型和数据管理系统,即,该基准可用于探测流数据管理系统.关系数据库系统以及基于其他专用系统.
1.2 数据的爬取及预处理
爬虫程序运用新浪提供的API,用以爬取社交网络信息、微博信息及微博用户信息.图2为数据爬取过程示意图,其中种子用户中包含了32个热点用户,爬虫采用宽度优先遍历的方式,从种子用户出发沿着关注边遍历3层.图示中前3层用户共包含约170万个用户,被称为核心用户;在核心用户确定之后,程度开始爬取这批用户的在线社交网络以及发布的微博数据[6].
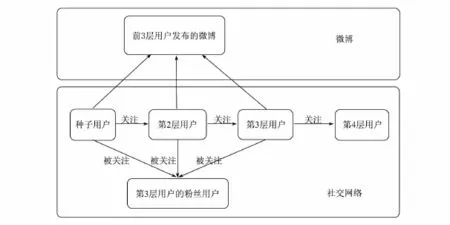
图2 数据爬取流程示意图Fig.2 Figure of data crawling process
随后爬虫程序周期性地更新整个数据集,爬取核心用户的社交网络关系变更以及发表的微博.在最终爬取的社交网络数据集中包含了大约12亿条关注关系,含从2009年8月至2012年12月时间内用户发布的微博数量约6亿4千万条.
数据集以文本形式保存,其中每行数据对应一条社交媒体流中的一条记录,数据记录按照时间增序排列.数据集基于爬取的微博数据执行了以下的预处理数据操作:
(1)转发链重构:由于微博API返回的微博数据只显示被转发的原始微博信息,而从原始微博到当前微博的转发关系则体现在当前微博的内容当中.因此,通过一个基于Map Reduce框架的分布式数据转发程序,以原始微博为键值,在reduce过程中对转发同一条微博的微博数据重构出转发链.
(2)数据匿名化:由于微博数据使用的限制以及可能存在的个人隐私保护问题,所有数据均做了匿名化处理.这一步主要包括对用户信息和微博内容的匿名化,对于微博内容,保留了微博话题信息以及话题相关的词条.
2 连续查询负载与评测标准
本节基于上节提出的数据模型,根据实际应用场景抽象一组查询,并提出相应的性能评测标准.
2.1 连续查询负载
社交媒体数据本质上由多个流数据构成,因而能够很好地支持许多社交媒体上的应用.例如,针对个人用户,常用的应用包括未读微博、热门微博及热门话题的提醒功能;基于微博管理系统维护的角度,发现发布微博行为异常的用户.此外,基于已有的数据流被转换之后,可以为更复杂的任务生成流数据作为输入.例如,在基于图数据流的实时在线社区或者事件发现应用中,需要获取用户的交互流,流中每条元素由某段时间内用户交互频率超过某个阈值的用户交互边构成.本基准测试从实际应用出发定义了一组查询,它们涵盖了参与到流数据中的各个角色,以及各种实际应用场景.
由于流数据引入了时间维度,关系数据查询语言SQL无法直接用于表示流数据上的查询,文献[7-9]通过扩展SQL语言的语义来定义流数据上的查询语言.其中Standford针对流数据处理缺乏明确语义的统一的查询语言,提出了用于连续查询的抽象语义,并且设计了CQL[7](continous query languange)来实现这些抽象语义.CQL定义了关系到关系、关系到数据流以及数据流到关系间的转换.它通过使用查询窗口的概念,将流数据映射成相应的关系数据.通过引入Istream,Dstream,Rstream3个操作,CQL能将关系数据转换成流数据.最后,通过重用关系查询语言SQL中对关系操作的语义,它能够表示不同关系之间的查询,例如聚合查询、子查询以及连接等.
为了表达准确的语义,本基准测试将主要使用CQL语言表示基准测试中使用的查询,但不强制被测试的流数据管理系统支持CQL语言,用户只需要针对每条查询提供正确的实现.基准测试中包含的查询主要分为3类:热点查询,实时查询,混合查询,接下来将详细介绍这3类查询.
(1)热点查询
在新浪微博中,热点指的是在某个特定的时间范围内微博平台中满足某些过滤条件且统计值最大的某类元素集合.这里的元素可以是用户、微博或话题,这些分别称为热点用户、热门微博或热门话题.
热点查询(Hot Spot Query,HSQ)是查询当前时间点Ta到之前的一个时间点Tb间具体元素的内容.在连续查询中,这样一个时间段被称为一个窗口(WINDOW),窗口的大小即是时间段的长短.一个热点查询可以用来回答类似“近期内微博被大量转发的用户”等类似的问题.
举一个简单的实例,查询“上海地区1小时内被转发的微博数量前十名的用户”,用CQL语言描述如下:
Select Count(Tweet.uid)From Tweet[Range 1 Hour]
Where Tweet.location=“上海”
Order by Count(Tweet.uid)Desc
Limit 10
上述查询只截取Tweet一个数据流,过滤Tweet流的Location属性,为数据流Tweet开了一个时长为1小时的窗口,并从这个窗口中查询最活跃的Top10的用户,即返回数据流到达的时间点往前一个小时内最活跃的Top10的用户.
该热点查询为单属性的热点查询,仅包含一个过滤条件.在更复杂的热点查询中,过滤的属性往往不止一个,且数据流之间需要进行连接,同时也可以包含子查询.对多属性的热
点查询举例如下:查询“一小时内上海用户对‘爸爸去哪儿第二季收视率’讨论的热烈程度”.该查询用CQL语言可以描述如下:
Select Count(Tweet.uid)
From Tweet[Range 1 Hour],Topic[Range 1 Hour]
Where Tweet.location=“上海”and Tweet.mid=Topic.mid
and Topic.topicname=“爸爸去哪儿第二季收视率”
上述查询同时截取Tweet和Topic两条数据流,过滤多个属性并返回Tweet流中用户的总数来反应对“爸爸去哪儿第二季”收视率讨论的热烈程度.
(2)实时查询
实时查询(Realtime Query,RQ)关注的是当前时间点的信息,查询的是当前时间点微博平台中满足某些过滤条件的元素.不同于热点查询是,实时查询是绝对连续的,查询当前时间点的内容.实时查询一般用来回答“当前正在讨论某话题的用户”等类似的问题.
下面给出一个实时查询的具体实例.查询“微博内容包含了‘爸爸去哪儿第二季’的微博内容”,用CQL语言描述如下:
Select Istream(Tweet.content)
From Tweet[Now]
Where contains(Tweet.content,“爸爸去哪儿第二季”)上述查询中,查询实时截取Tweet流中content元素,并对其进行过滤,Now标签是实时查询的特征,表示查询的窗口为当前时间,而不再是一个给定的范围,Istream(Tweet.content)则表示返回查询结果也是一个数据流.
(3)混合查询
混合查询(Mix Query,MQ)同时包括热点查询和实时查询,查询的元素既包含当前时间点满足过滤内容的元素,同时也包含当前时间点的前一个时间段内满足过滤条件的元素.
混合查询可以用来回答更多更复杂的问题,下面给出一个混合查询的具体实例.查询“在1小时内上海地区转发内容包含‘爸爸去哪儿第二季’的微博”.该查询用CQL描述如下:
Select Istream(Retweet.*)
From Retweet[Now],Tweet[Range 1 Hour]
Where contains(Tweet.content.,“爸爸去哪儿第二季”)
and Retweet.remid=Tweet.mid and Tweet.location=“上海”上述查询中,对Retweet流,关注的是实时的信息,而对Tweet流,关注的是一个小时内的所有信息.返回的数据是一个符合所有过滤条件的Retweet流.
(4)具体查询描述
综合考虑6种输入流及3种查询,基准评测共提供了10个查询,查询的CQL语言表述见附录.表2描述了这些查询的查询编号、查询描述和查询类型.
上述查询中,查询1,2,3,4,8,9,10为热点查询,查询5为实时查询,查询6,7为混合查询.

表2 查询描述Tab.2 Description of queries
热点查询在微博应用中运用较为广泛,查询结果可用作微博数据的统计,也可实现对热点微博的监控.其中查询1,2,3,4为简单的微博热点监控查询,其查询逻辑较为简单,查询1是对单个数据流进行查询,查询2,3,4分别是对不同的数据流进行交叉的查询,其过滤条件也有多个.查询8,9,10为的微博热点监控查询,查询针对数据流中的所有用户,逻辑较为复杂.其中查询8,9是针对个人用户的查询,查询8为用户的未读微博提醒功能,查询了用户上次登录之后新发布的微博数,在实际应用系统中,若未读微博数超过一定阈值,则向用户发出未读微博提醒.同样,查询9查询用户上次登录之后好友圈内讨论数量超过阈值的话题.查询10查询近期交互频繁的用户组,可用于基于图数据流的实时事件发现.
实时查询主要用于对微博的实时监控.通过实时查询,可以过滤数据流中不感兴趣的信息,仅获取想要监控的数据.如查询5即为从所有Tweet流中过滤出参与话题T讨论的微博.由于实时查询原理类似,这里仅给出一条多数据流交叉的实时查询.
混合查询同样主要用于对微博的实时监控,但其过滤条件更为复杂,过滤时要和当前数据流的前一个时间段的所有数据进行交叉过滤.查询6是普通的混合查询,监控的是Retweet流,查询一段时间之内被转发的由用户A原创的微博.查询7为嵌套的混合查询.
(5)查询参数说明
查询中共有以下4个可变参数:用户、话题、地区和时间.下面对这4个参数的取值做详细说明.
(1)用户:根据用户当前的好友数成正比的概率作选择,即每个用户被选择的概率与其好友个数成正比.
(2)话题:根据测试点之前的24小时内话题的讨论微博数来作选择.
(3)地区:根据数据集中每个地区所发布的微博数来作选择.
(4)时间:查询中的时间在每条查询相应的时间区间内随机选择.
2.2 性能测试配置
性能测试的配置主要包含以下3个参数:测试点、操作数和查询比.
(1)测试点:测试点设置的是在测试过程中开始执行测试时流的位置,用户可以设置多个测试点.例如它的默认设置包含100 000,1 000 000,10 000 000等,即当第100 000,1 000 000,10 000 000个流元素到来时开始执行测试.
(2)操作数:操作数设置的是在所有测试点的测试过程中执行查询的总条数,默认设置为1 000.
(3)查询比:查询比设置的是在测试过程中10个查询执行次数的占比情况,默认设置下所有查询的占比情况是相等的.
2.3 性能测试指标
对流数据的查询都是连续的,因此,基于关系数据库的性能评测指标,如“查询完成时间”等指标则不适用于流数据管理系统.为了测试不同的流数据管理系统对社交媒体数据流的性能,基准测试制定了如下性能测试指标.
数据延迟时间:假定在t1时间到达的数据,而被查询到的时间为t2,数据延迟时间t=t2-t1.该属性越小,则说明系统性能越好.
数据处理吞吐量:在满足指定的数据延迟时间约束的要求下,系统处理数据流的速度定义为数据处理吞吐量.该属性越大,则说明系统性能越好.
数据可扩展性:被测系统在不同的测试点已处理的数据量不同,对由数据量和吞吐值构成的点计算其斜率.该斜率表示为数据可扩展性,该属性越大,则说明系统受数据量的影响越小.
其中,数据延迟时间反映的是系统对查询处理的速度,不同的系统在处理不同的社交数据流查询时,对查询结果的响应时间都不相同,数据延迟时间通过计算查询结果到达时间与数据流输入时间的差值,来体现系统的延迟,该时间差值越小,则系统对查询的响应数据越快,数据延迟度越低,系统对该查询的处理性能则更好.
数据处理吞吐量反映的是系统在固定时间内处理的流数据量的多少,针对一个具体的查询,该值越大,则说明在给定的时间内,系统能成功处理越多量的输入流,系统对该查询的处理性能越好.在这里,成功的处理指系统接收输入流并在满足数据延迟时间约束的前提下返回查询结果.因此数据处理吞吐量能够体现系统在满足服务要求的前提下,系统抗击数据流到达峰值的能力,例如平缓地处理突发事件导致的短时间内发布的大量微博.
数据处理吞吐量可用下述值表示:
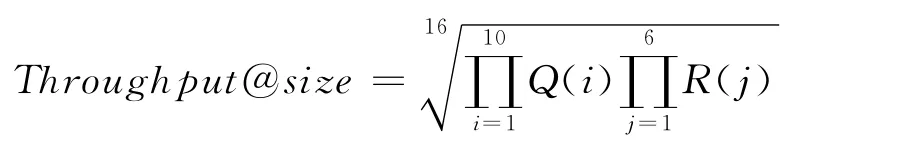
其中,size为基准测试发出的数据流元素的个数;Q(i)为查询i在大小为size时发起的测试获得的吞吐量;R(j)为第j个流的更新速率,即执行一次测试操作的时间内更新的元素个数.
数据可扩展性反映的是系统对数据量的适应程度,它是由以数据量和吞吐量构成的点的斜率来表示.根据该值能够体现系统随着被处理数据集的规模增大的情况下,系统性能的变化趋势.
3 总 结
本文提出了一个面向社交数据流连续查询的基准评测.本基准测试是基于新浪微博的数据构建而成,首先介绍数据的爬取及预处理,定义了最终的输入数据流模型.其次基于输入数据流的特点,定义了基准评测的连续查询负载,定义了3类查询.最后,制定了性能测试指标,用以测试不同的流数据管理系统在社交数据流连续查询上的表现.本文的工作对社交数据流处理应用的系统选型、相关查询处理技术性能比较具有重要意义.未来工作将进一步补充各类查询,尤其是基于社交流数据上的数据挖掘类查询.
[1] ABADI D,CARNEY D,CETINTEMEL U,et al.Aurora:A new model and architecture for data stream management[J].VLDB Journal,2003,12(3):120-139.
[2] CHANDRASEKARAN S,COOPER O,DESHPANDE A,et al.Telegraphcq:Continuous dataflow processing for an uncertain world[C]//Proceedings of the 1st Biennial Conference on Innovative Database Research(CIDR).Asilomar,CA:[s.n.],2003.
[3] MOTWANI R,WIDOM J,ARASU A,et al.Query processing,resource management,and approximation in a data stream management system[C]//Proceedings of the 1st Biennial Conference on Innovative Database Research(CIDR).Asilomar,CA:[s.n.],2003.
[4] ARASU A,CHERNIACK M,GALVEZ E,et al.Linear road:a stream data management benchmark[C]//Proceedings of the Thirtieth International Conference on Very Large Data Bases.VLDB Endowment,2004,30:480-491.
[5] MA H,WEI J,QIAN W,et al.On benchmarking online social media analytical queries[C]//First International Workshop on Graph Data Management Experiences and Systems.ACM,2013:10.
[6] MA H,QIAN W,XIA F,et al.Towards modeling popularity of microblogs[J].Frontiers of Computer Science,2013,7(2):171-184.
[7] ARASU A,BABU S,WIDOM J.CQL:A language for continuous queries over streams and relations[C]//Database Programming Languages.Berlin:Springer,2004:1-19.
[8] JAIN N,MISHRA S,SRINIVASAN A,et al.Towards a streaming SQL standard[J].Proceedings of the VLDB Endowment,2008,1(2):1379-1390.
[9] ARMBRUST M,CURTIS K,KRASKA T,et al.PIQL:success-tolerant query processing in the cloud[J].Proc VLDB Endow,2011,5(3):181-192.
附 录
连续查询
· 查询1.最近一段时间的热门话题
selectInstream(topicname)from
topic[range MYMHMYM hour]
group by topicname
having count(*)>10000;
· 查询2.最近一段时间微博被大量转发的用户:
Select tweet.uid,count(*)as num
from retweet[Range MYMHMYM Hour],tweet[Range MYMHMYM Hour]whereretweet.remid=tweet.mid
group by tweet.uid
order by numdesc;
· 查询3.用户A的好友圈内最近一段时间的热门话题:
Select topicname,count(*)as num
from topic[range MYMHMYM hour],followship
wherefollowship.uid=“A”and topic.uid=followship.foluid
order by numdesc;
· 查询4.最近一段时间对地区L话题T的讨论的热烈程度:
Select Count(Tweet.uid)
From Tweet[Range MYMHMYM Hour],Topic[Range MYMHMYM Hour]
Where Tweet.location=L and Tweet.mid=Topic.mid
andTopic.topicname=“T”
· 查询5.参与话题T讨论的微博
Select Istream(Tweet)
From Tweet[Now],Topic
Where Tweet.mid=Topic.mid and Topic.name=“T”
· 查询6.用户A一段时间内被转发的微博
Select Istream(Retweet.*)
From Retweet[Now],Tweet[Range MYMHMYM Hour]
Where Tweet.uid=“A”andRetweet.remid=Tweet.mid
· 查询7.用户A一段时间内关注的好友中,查询参与话题T讨论的微博
Select Istream(Tweet)
From Tweet[Now]
Where Tweet.mid=Topic.mid and Topic.name=“T”
andTweet.uidin(Select Follow.uid2
From Follow[Range MYMHMYM Hour]Where Follow.uid1=“A”)
· 查询8.所有用户的未读微博提醒查询
Select Istream(Login.uid),count(*)as unread
From friendlist,Tweet[Range MYMHMYM Hour],Login[Partition By uid Rows 1]as unlogin
Where friendlist.uid=unlogin.uid and friendlist.followee=tweet.uid
Group by Login.uid
Having unread>N
· 查询9.所有用户的热门话题提醒查询
Select Istream(Login.uid),count(*)as unread
From friendlist,Topic[Range MYMHMYM Hour],Login[Partition By uid Rows 1]as unlogin
Where friendlist.uid=unlogin.uid and friendlist.followee=Topic.uid
Group by Login.uid
Having unread>N
· 查询10.交互频率超过某个阈值的用户组
Select Instream(Retweet.uid,Tweet.uid),count(*)as Interact
From Retweet[Range MYMHMYM Hour],Tweet[Range 48 Hour]
Where Retweet.remid=Tweet.mid
Gourp by(Retweet.uid,Tweet.uid)
Having Interact>N
猜你喜欢
加油站服务指南(2022年6期)2022-07-28 06:07:02
汽车维修与保养(2020年11期)2020-06-09 05:42:22
车迷(2019年10期)2019-06-24 05:43:28
快乐语文(2018年7期)2018-05-25 02:32:00
电脑与电信(2018年12期)2018-03-23 02:37:36
公民与法治(2016年19期)2016-05-17 04:18:15
西北工业大学学报(2015年3期)2015-12-14 13:08:48
读者·校园版(2015年7期)2015-05-14 13:11:40
中国卫生(2014年7期)2014-11-10 02:32:54
中国记者(2014年6期)2014-03-01 01:39:53
