
面向OLAP应用的OceanBase模式设计
2014-10-31 06:54翁海星胡华梁
华东师范大学学报(自然科学版) 2014年5期
顾 伶, 翁海星, 胡华梁,2, 赵 琼
(1.华东师范大学 软件学院,上海 200062;2.浙江理工大学 经济管理学院,浙江 310018;3.交通银行 软件研发中心,上海 201201)
0 引 言
在当前的大数据时代,数据量已经达到了PB级,但是人们对于查询的要求越来越高,希望能在毫秒级时间内得到想要的结果.传统的数据库存储方式过于简单,当数据量很大时,大量数据的堆积会导致服务器回应速率下降甚至崩溃,对企业造成很大的经济损失.分布式数据库能够解决这样的问题,现在企业里常用的数据仓库有Oracle、DB2、MySQL、Sybase、MS SQL Server等,但是这些数据库都需要使用高性能的机器,并且扩展性有限,最多只能达到几百台机器,当前数据源多样,并且增长迅速,这样的数据库无法很好的提供大数据的存储以及查询服务.随着经济迅速发展,方便大众的业务也在不断涌现.例如,为了支持淘宝电子商务的业务,淘宝网和各家银行及物流公司都有合作.这就需要淘宝的数据库中存储大量客户信息和交易信息,银行数据库中存储卡的交易信息,物流公司的数据库中存储客户的信息和邮件信息.由于人口众多以及时代发展,无论是电子商务在线交易,还是其他业务的办理,都对数据库产生了极大压力.
OceanBase是一个支持海量数据的高性能分布式数据库系统,能够实现数千亿条记录、数百TB数据上的跨行跨表事务.这是由淘宝研发出来的适用于淘宝业务的数据库,具备高可用性和可靠性.OceanBase能够承受住“双十一”在线交易的巨大压力,在2013年的“双十一”期间,事务量最大能达到68000TPS,一天内的交易值达17亿笔之多.使用OceanBase数据库,只要增加更多的机器,数据会自动迁移到新的机器上.通过这样简单的扩展,淘宝成功渡过了交易量巨大的“双十一”.尽管OceanBase当前适用于淘宝,它处理大数据的能力却是金融行业所急需的.
OceanBase也存在一些缺陷:未能支持DATE、DECIMAL等数据类型;也没有足够的查询优化:能够支持主键索引,未能支持2级索引.金融企业的业务远比淘宝复杂,因此针对功能缺陷以及支持的索引来加快查询速率,OceanBase的模式设计是非常必要的.
本文安排如下:第1节介绍OceanBase的整体框架、OLAP查询的并行执行框架、单表和多表查询的执行计划以及OceanBase的功能缺陷.第2节首先介绍了TPC-H的业务场景,并对其中的查询进行了分类,最后分析OceanBase对于单表和多表查询的模式设计.第3节会通过实验来验证设计模式的有效性.第4节总结全文.
1 OceanBase功能简介
OceanBase是一个既可以支持OLAP应用也可以支持OLTP应用的分布式关系型数据库,可以划分为4个模块[1]:主控服务器RootServer、更新服务器UpdateServer、基准数据服务器ChunkServer以及合并服务器MergeServer.RootServer实现对数据分布和数据副本的管理.UpdateServer存储着增量更新数据,并且只有这个服务器允许写服务.ChunkS-erver存储着OceanBase的基准数据.OceanBase内部按照时间线将数据划分为基准数据和增量数据,基准数据是只读的,而所有的修改都会更新到增量数据中,系统内部会通过合并操作定期将增量数据融合到基准数据中.当查询的时候,会先从ChunkServer取出数据,然后与UpdateServer上的增量数据进行合并,最后由MergeServer返回合并后的结果.因此,为了减少查询时的合并操作,就需要在查询前进行增量数据和基准数据的合并.MergeServer主要负责接受并解析用户的SQL请求,并且负责返回ChunkServer合并的结果集.OceanBase通过自己的容错机制来防止机器故障,以便在任何时候都能给用户提供服务.
OceanBase对于OLAP应用能够实现并发查询功能,很大地提高了查询速率.当用户进行查询时,MergeServer首先进行SQL的解析,然后将大请求拆分为多个小请求,将小请求发送到有相应数据的ChunkServer,然后由各个ChunkServer并发执行查询.OceanBase会尽量实现SQL执行本地化,包括Filter、Project、子请求部分的GroupBy、OrderBy等.每个ChunkServer执行完查询,将结果返回给MergeServer.如果有ChunkServer上的查询执行失败,MergeServer会将让存有副本的其他ChunkServer执行,当所有的查询都执行完,MergeServer会对全部数据进行排序、分组等操作.
OceanBase目前不支持的数据类型有DECIMAL、DATE、CLOB、BLOB和NUMERIC,当要使用这几个类型的时候,可以根据具体场景用其他的类型替换.OceanBase也不支持EXISTS的子句.单表和多表查询的物理查询计划和其他数据库类似,但是OceanBase只是支持主键索引.根据图1的单表查询的物理查询计划,由于OceanBase只支持主键索引,以对于t1表,可以将c3作为第一主键,加快了扫描的速度.图2显示的是两表连接的一个查询.对于连接的查询,on后面的过滤项是没有索引作用的,所以需要将左边的SQL转换为中间的SQL形式.对于左外连接的数据查询,OceanBase中过滤条件位于on和where后面的过滤效果与传统数据库不一致,因而在实际业务中将其他数据库的左外连接的查询迁移到OceanBase中时,过滤条件的位置会影响结果的正确性.例如下面2个SQL,右表的条件写在on后面和where后面,当写在on后面的时候,数据库应该进行的操作是,先按照B.c2=1的条件进行了过滤,然后和A表进行连接,连接的结果是B表可以带着NULL的情况.当条件写在where后面,就是A和B表做完left join,然后将最后的结果根据B.c2=1进行过滤,这时候的效果与INNER JOIN相同.另外,OceanBase不支持非等值连接,也就是连接的SQL中一定要带有等值的连接.
(1)SELECT A.c1,B.c1 FROM A LEFT JOIN B ON A.c2=B.c2 and B.c2=1;
(2)SELECT A.c1,B.c1 FROM A LEFT JOIN B ON A.c2=B.c2 WHERE B.c2=1.
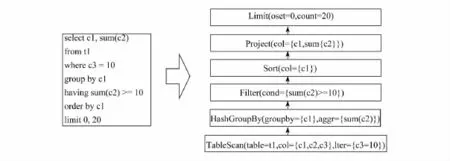
图1 单表查询的物理查询计划Fig.1 Physical query plan of single table's query

图2 多表查询的物理查询计划Fig.2 Physical query plan of multiple tables'query
OceanBase对in的使用有特别要求,以加快查询速率.如果一张表有多个主键,那么当in语句中包含全部的主键的时候,这张表的查询会用上主键索引.例如A表有主键k1、k2,需要 WHERE(k1,k2)in(v1,v2).最后,OceanBase对 where后面的子查询是不支持的,当出现这种情况,需要将子查询拆分出来,用中间查询结果集替换子查询.
2 OceanBase下TPC-H案例研究
2.1 TPC-H
TPC Benchmark H是一个决策支持的基准[5],它由一系列面向商务应用的查询和并行数据修改组成.基准里选择的查询和组成数据库的数据在商业上都具有广泛的代表性并且易于实现.目前TPC-H是OLAP领域常用的评测标准.
TPCH一共有8张表:订单表(ORDERS),记录着每个客户的订单状态和总额;订单详情表(LINEITEM),记录着每个订单下的每个货品的状态;客户表(CUSTOMER),记录着客户信息;国家表(NATION),记录着国家的信息;地域表(REGION),记录着地域的信息;供应商表(SUPPLIER),记录着供应商的信息;供应货品表(PARTSUPP),记录着供应商提供的商品;货品表(PART),记录着货品信息.表之间的关系如图3所示:
TPC-H有22个复杂的查询,所选择的查询为各类商业分析提供定价和促销、供货和需求管理、利润和收入管理、顾客满意度研究、市场份额研究和运输管理.根据OceanBase功能特点将TPC-H的查询进行了分类:
· 单表有复杂运算的查询:Q1,Q6
· 多表并且带有exists和not exists的查询:Q4,Q21,Q22
· 多表并且带有not like或者not in的查询:Q13,Q16
· where或者in中有子句的查询:Q11,Q15,Q17,Q18,Q20
· 多表的有or条件:Q19
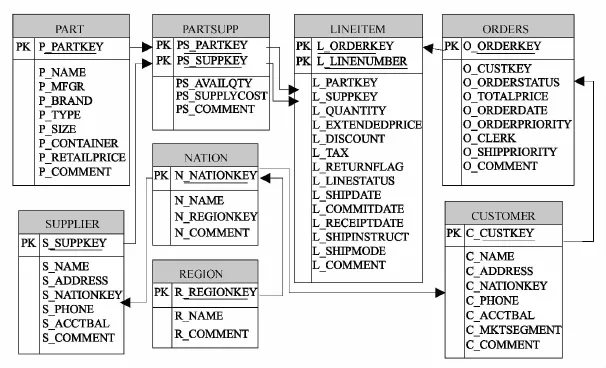
图3 TPC-H的模式Fig.3 The schema of TPC-H
· 简单的多表连接:Q2,Q3,Q5,Q7,Q8,Q9,Q10,Q12,Q14.
下面的章节会考虑OceanBase当前的架构,将此TPC-H的案例应用到OceanBase,并且让每个查询的效率在OceanBase中达到最高,还会将TPC-H的查询分为单表查询和多表查询来进行研究.
2.2 单表查询的用例研究
OceanBase只支持主键索引,若想加快单表查询的查询速率,就需要设置输入的属性为第1主键.本节主要描述在单表查询下,TPC-H模式的重新设计,使得单表查询的效率提高.
在实际生产中,OLTP的数据在业务量少的时候会迁移到数据仓库中,为了保证OLAP的高效率查询,需要重新设计模式,并在数据传送时进行模式的变化.OceanBase由UpdateServer、ChunkServer和RootServer组成,UpdateServer存储的是增量数据,ChunkS-erver存储的基准数据,RootServer相当于1个master或者1个索引.当进行查询时,OceanBase会查询ChunkServer上的基准数据,然后与UpdateServer上的增量数据合并,最后返回给用户.由于需要合并,查询速度受到了影响,所以在查询前需要对每天的数据进行合并,将UpdateServer上的数据合并到ChunkServer上.
由分类可以知道,单表查询只有Q1和Q6.Q1查询的是运送日期在60~120天内已经付款、已运送的和已返回的总金额.Q6查询一年中在指定的百分比内的订单金额.这两个查询都是使用了表LINEITEM,但是表LINEITEM的主键是L_ORDERKEY、LINENUMBER.OceanBase支持主键索引,所以若使用原来的主键,则无法运用OceanBase的主键索引,查询速率低.设置LINEITEM以L_SHIPDATE为第1主键,并且将原主键也作为主键以便确定唯一性,就能使用上主键索引,从而加快了查询速率.
2.3 多表查询的用例研究
该小节主要讨论多表连接的案例,统计了TPC-H中多表连接的案例并且列于下方.OceanBase会将操作下推到各个服务器端,先对各个表进行过滤,然后将数据取到查询的mergeserver上,最后进行排序合并连接[2],因此需要尽量减少连接.事实上,OceanBase对连接没有优化,而且只是支持主键索引,所以需要在外部程序的帮助下,求出做连接的表的主键值,对每个表增加了主键索引,加快了查询速率.首先列出TPC-H中连接的各种情况,然后分析对TPC-H的雪花状模型[3,4,6]的改变,以减少连接.最后将以连接最多的Q8为案例,讲解在新的模型下的查询变化.

表1 多表连接的分类情况Tab.1 Classification of joins
TPC-H模式是一个雪花状模型,适合于维度分析,但是从表1中可以总结出来,查询基本上是指标分析,都会进行连接.为了减少连接,需要根据这几种连接来合并表结构.由于当前的雪花状模型,当进行连接的时候会涉及好几张表.分析经常出现的表连接有:(1)LINEITEM和ORDERS连接,例如LINEITEM存有供应商的序号,ORDERS表存有顾客的序号,如果一个查询中需要供应商和顾客的信息,那么就需要将LINEITEM,ORDERS,SUPPLIER,CUSTOMER进行连接,涉及到的查询有 Q3,Q5,Q7,Q8,Q9,Q10,Q12,Q18,Q21;(2)SUPPLIER,NATION和REGION,例如查询某个区域的售货商情况,涉及的查询有Q2,Q5,Q7,Q8,Q11,Q21;3、CUSTOMER,NATION和 REGION,例如查询某个区域的客户情况,涉及的查询有Q5,Q7,Q10,Q21.
如果需要查询供应商国家与顾客国家之间的货物情况,就需要LINEITEM,ORDERS,SUPPLIER,CUSTOMER,PART,NATION,REGION的连接,下面就以连接最多的查询Q8为例来看一下两表合并后的SQL的变化:
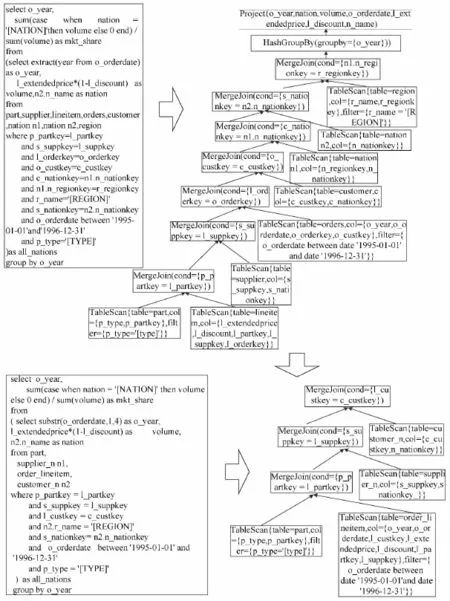
图4 连接的案例Fig.4 The example of join
Q8能够显示过去两年中一个给定的零件类型在某国某地区的市场份额的改变.市场份额定义为某国某地区供应商供应特定种类的产品收入的百分比,是l_extendedprice*(1-ldiscount)的和.因为需要限定供应商和顾客的国家,时间需要用ORDERS的订单时间,这就需要将这么多的表进行连接.由查询看,只有PART表有p_type有限定条件,ORDERS表有o_orderdate有限定.TPC-H中最大的两个表为ORDERS和LINEITEM,所以两表的连接用时最长,通过将ORDERS和LINEITEM两表合并为ORDER_LINEITEM的操作将两表查询改为单表查询.其次,只有CUSTOMER和SUPPLIER两表有nation和region,所以可以让CUSTOMER和 NATION、REGION通过C_NATIONKEY=N_NATIONKEY,N_REGIONKEY=R_REGIONKEY做连接,插入到新的表CUSTOMER_N中.表SUPPLIER和NATION、REGION也通过相同的方法插入到SUPPLIER_N中,这样就减少了三表连接.
例1显示了在新表下的查询,整个变化后的模式在图5中显示.

图5 改变后的TPC-H的模式Fig.5 The altered schema of TPC-H
OceanBase中对于TPC-H的模式与原来的模式不同之处有:将CUSTOMER和NATION,REGION合为CUSTOMER_N;将SUPPLIER和 NATION,REGION合为SUPPLIER_N;将LINEITEM和ORDERS合为ORDER_LINEITEM;新的模式中仍然保留ORDERS,不保留SUPPLIER和CUSTOMER,因为有些SQL会使用表ORDERS,如果以ORDER_LINEITEM代替,那么扫描的数据量会增大;PART_N的第1主键为P_TYPE,SUPPLIER_N的第1主键为R_NAME,PARTSUPP_N的第1主键为PS_SUPPLYCOST,ORDER_LINEITEM的第1主键为O_ORDERDATE,CUSTOMER_N的第1主键为N_NAME.通过表结构的合并减少了表的连接,并且重新设置第1主键,从而提高了查询速率.
3 实 验
本节以TPC-H的前20个SQL为案例,根据上节所描述的对单表和多表的改写方式进行改写.通过对比OceanBase上TPC-H的模式改变前后的查询效率,验证OceanBase上模式设计的有效性.
3.1 硬件配置及数据集
实验的硬件配置:
· CPU:Intel Xeon cpu e7-4870@2.4 GHZ8核
· 内存:50 G
· 硬盘:100 G
· 操作系统:Redhat 6.2
· 数据库:加上了DECIMAL运算的OceanBase 0.4.2.8
实验所用的数据集:TPC-H的数据生成器DBgen,生成了1 G的数据,其中各个表的行数为:
· LINEITEM:6 001 215
· ORDERS:1 500 000
· CUSTOMER:150 000
· SUPPLIER:10 000
· PART:200 000
· PARTSUPP:800 000
· NATION:25
· REGION:5
3.2 模式改变前后效率对比
以TPC-H的前20个查询为案例,由于最后2个查询有exists,所以未使用Q21和Q22查询.首先,将TPC-H的SQL改为OceanBase能够支持的,使用原来的模式,记录在OceanBase中运行的总时间.然后,将TPC-H的SQL改为新的模式下的SQL,在Ocean-Base中运行后也记录下时间.实验结果列于表2,时间以秒为单位.
单表查询有Q1和Q6,Q6的效果很明显,因为Q1是对LINEITEM的查询,过滤项只是L_SHIPDATE小于某个时间,主键索引没有太大的作用,过滤出的数据集大于Q6的数据集,所以导致效果不是那么明显.从Q6可以看出,在OceanBase中第1主键的改变能够使得查询速率提高4倍多.
多表连接的查询中有14个SQL运行时间是更少的.剩余的4个多表查询运行时间长的原因是查询中没有直接对于ORDER_LINEITEM的过滤项,并且没有构建索引表.对于多表查询,在没有构建索引表的情况下,大部分的SQL运行时间更短,因此表的合并使得查询效率提高.
从实验结果可以看出,在OceanBase中对于TPC-H模式的第1主键的改变以及表的合并使得查询效率提高了许多.

表2 TPC-H的查询时间对比表Tab.2 The running time comparison of TPC-H queries s
4 总 结
本文讲述了面向OLAP应用的OceanBase的模式设计,并将TPC-H作为案例研究,通过对比实验,说明了模式设计的有效性.OceanBase支持主键索引,但是对于连接操作还没有并行处理机制,并且在左外连接上有缺陷,会影响结果的正确性.根据OceanBase的特点,在模式设计的过程中,需要根据查询的过滤项来改变表的第1主键.如果表的数据量小于10 000行,可以不需要主键索引.其次,OceanBase支持排序合并连接,所以OceanBase需要尽可能减少连接.在模式设计过程中,可以根据业务场景来减少连接,将多个表合为1张表,将多表查询转换为单表查询,再通过第1主键的设置,可以加快查询速率.
[1] 杨传辉.大规模分布式存储系统:原理解析与架构实战[M].北京:机械工业出版社,2013.
[2] 莫利纳H,厄尔曼J,怀德姆J.数据库系统实现[M].杨冬青,吴愈青,包小源,等译.2版.北京:机械工业出版社,2010.
[3] 袁霖,康慕宁,李建良,等.一个面向OLAP应用的多维数据查询语言及其在对象关系数据库中的实现[J/OL].计算机工程与应用,2004,13:182-218.
[4] IMHOFF C,NICHOLAS.Mastering data warehouse design:relational and dimensional techniques[M].John Wiley &sons,2004.
[5] Transaction Processing Performance Council(TPC).TPC BENCHMARKTM H [EB/OL].(1993)[2013-01-02].http://www.tpc.org/tpch/spec/tpch2.17.0.pdf.
[6] 王珊,萨师煊.数据库系统概论[M].4版.北京:高等教育出版社,2006.
猜你喜欢
无线互联科技(2022年15期)2022-11-03
中学生数理化·高一版(2020年6期)2020-07-25
教育界·中旬(2019年7期)2019-11-24
劳动保护(2018年8期)2018-09-12
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
信息安全与通信保密(2016年3期)2016-08-23
公民与法治(2016年19期)2016-05-17
读者·校园版(2015年7期)2015-05-14
食品工业科技(2014年23期)2014-03-11
电子设计工程(2014年6期)2014-02-27
