
一种改进的特定人语音识别系统及算法研究
2014-09-25 10:19赵智琦房建东
电子设计工程 2014年16期
赵智琦,房建东
(内蒙古工业大学 内蒙古 呼和浩特 010080)
一种改进的特定人语音识别系统及算法研究
赵智琦,房建东
(内蒙古工业大学 内蒙古 呼和浩特 010080)
针对传统特定人语音识别过程中存在的算法复杂、所占存储空间大等问题,提出了一种改进的基于动态时间规整算法(DTW)的特定人语音识别系统。在对参数提取方法进行详细对比之后,提取美尔频率倒谱系数(MFCC)作为本系统的语音识别参数,有效的解决了人耳响应不同信号灵敏度不同的问题。利用MATLAB环境下语音工具箱Voice Box实现了对若干数字的孤立词识别,识别速度提高了约30%,识别成功率达到95%以上。仿真结果证明,该系统在算法简单,识别成功率高,是一种简单有效的语音识别方法。
语音识别;动态时间规整算法;美尔频率倒谱系数;孤立词
语音识别技术 (Automatic Speech Recognition,ASR),又称为自动语音识别,其目标是将人类的语音中的词汇内容转换为计算机可读的输入,也就是让计算机听懂的语言。它是语音信号处理的一个重要研究方向,是模式识别的一个分支,涉及生理学、心理学、语言学、计算机科学、信号处理等诸多领域,其最终目标是实现人与机器进行自然语言的通信。近年来,语音识别技术在高速发展的同时已从实验室研究走向市场化,在通信、家电、医疗等高科技领域得到了广泛的应用。本文通过理论分析及研究,提出一种改进的基于动态时间规整算法(DTW)的特定人语音识别系统,并通过仿真实验论证了此方法的可靠性及正确性。
1 基于DTW特定人语音识别系统设计结构
1.1 识别流程
系统基于改进的动态时间规整算法DTW(Dynamic Time Warping)研究特定人语音识别,并以MATLAB软件为平台,主要实现的功能有原始语音提取、预处理、特征参数提取和语音识别。系统的开发流程图如图1所示。

1.2 预处理
由于提取的原始语音信号一般不能满足实际的需要,处理起来很复杂或者根本无法处理,所以在进行语音识别之前都要对原始语音信号进行预处理[2],这样做不仅是后续顺利进行语音识别的前提,而且对于提高处理精确度有十分重要的意义。
模拟信号的预处理环节主要包括预滤波、采样和量化、加窗、端点检测、预加重等。下文将对具体处理步骤做进一步介绍。
1)预滤波
预滤波的目的有两个:
①抑制输入信号各频域分量中频率超出fS/2的所有分量(fS为采样频率),以防止混叠干扰[5]。
②抑制50 Hz的电源工频干扰。所以,预滤波器则必须是一个上、下截止频率分别是fH和fL的带通滤波器。对于绝大多数语音编译码器来说,fH=3 400 Hz,fL=60~100 Hz,fS=8 kHz。
2)采样和量化
因为原始的语音信号是一系列的模拟信号,计算机在处理其之前必须将其转换为计算机能识别的数字信号,即对原始语音信号进行数字化处理,数字化处理包括采样和量化两个步骤。采样是把模拟信号在时间域上进行间隔取样,其中两个取样点之间的间隔称为采样周期,其倒数为采样频率。量化的目的是将信号波形的幅度值离散化。量化不可避免地会产生误差[10]。
3)加窗
语音信号的时变性决定了其不可能在整个时间域上被处理,这也是语音信号处理的一个难点。但是经过大量实验验证,在较短的时间(如:10~30 ms)之内其特性可以认为是基本不变的,这就是语音信号的短时平稳特性。利用这个特性,截取具有短时平稳特性的一段语音信号来对其进行处理分析,就是对语音信号进行分帧。分帧是通过对语音信号加入窗函数来实现的,即 sw(n)=s(n)*w(n),其中 s(n)为加窗前的语音信号,sw(n)加窗后的信号,w(n)为窗函数。
常见的窗函数有矩形窗、汉明窗、汉宁窗,设计采用汉明窗来对语音信号进行分帧。究其原因,窗函数的形状在语音信号的时域分析中十分重要,矩形窗函数具有谱平滑性较好的优点,但波形细节丢失和常常产生遗漏现象对其应用造成了局限性。而汉明窗可以有效的克服频谱泄漏现象,应用范围最广泛[6]。
4)端点检测
在语音识别系统中,找到语音信号的起点和终点是在训练阶段和建模阶段中都十分重要的环节,这一环节即为语音信号的端点检测。通常的端点检测的方法有短时能量、短时平均过零率和短时平均幅度。短时能量是基于在信噪比较高的情况下,一般无语音信号的噪声能量很小,而有语音信号的能量则显著增大,因此,定义为一帧样点的加权平方和。短时平均过零率则以一帧语音信号波形穿过横轴 (零电平)的次数作为检测的基础。设计采用以上两种方法结合(双门限端点检测法)的端点检测方法,确保端点检测结果的理想性。
下面以数字“4”为例,在MATLAB中将“4”的原始语音信号、短时能量和过零率绘制了出来[7],仿真结果如图2所示。

图2 数码“4”的端点检测Fig.2 The endpoint detection of“4”
从图中可以看出,声母s的短时能量明显比较低,即便是用手工标注也很容易将其误认为是噪声而切除,但是从过零率图可以看出,该段的过零率是很高的,接近50,所以能很准确的区分静音和声母,这样就很准确的保证了端点检测的准确性。
5)预加重
预加重的目的是通过提升语音信号中的高频部分频谱来增加语音高频部分的分辨率,便于语音参数的分析。首先将语音信号通过一个称之为预加重滤波器的一阶高通滤波器(1-az-1),其传递函数为:H(z)=1-az-1。 若预加重前 n时刻的语音信号为S(n),经过预加重滤波器后得到的信号为Y(n),则:Y(n) =S(n)-aS(n-1),在一般情况下 a 的取值在 0.9-1.0之间,而比较常见的取值是0.9375[3]。
以上的步骤即为语音信号的预处理,之后就要提取语音信号的特征参数。提取的特征参数应满足如下要求:
①有效地代表语音特征,并且 具有很好的区分性。
②参数间应有良好的独立性。
③语音识别的实时实现非常重要,所以提取的特征参数要计算方便。
特征提取就是找到不同语音的内在特征,并由此判别出未知语音。常见的特征提取方法有以下两类:由LPC系数所推出的线性预测倒谱系数 (Linear Prediction Cepstrum Coefficient)及 Mel频率倒谱系数 (Mel Frequency Cepstrum Coefficient)[4]。本系统提取的特征参数是MFCC参数。
选择MFCC参数的原因是该参数充分利用了人耳的听觉特性。从生物学角度来讲,人耳的听觉系统是一个随着信号灵敏度不同而响应不同的非线性系统,事实上人耳对不同频率的信号有着不同的感知能力。大量的实验证明[4],人耳对于1 000 Hz以下的信号感知能力与频率是线性关系,而当信号的频率为1 000 Hz以上时则为对数关系。而基于发音模型建立的lPC模型以及基于合成的LPCC参数都没有很好的利用人耳的这种听觉特性[9],所以对于本系统来说,提取MFCC参数能提高系统的识别性能与识别成功率,是个很好的选择。
跟语音信号的加窗类似,MFCC参数也是按帧计算的,其提取及计算过程如图3所示。

图3 Mel频率倒谱系数提取过程Fig.3 The extraction process ofMel frequency cepstral
从图3可以看出,原始语音信号s(n)在经过一系列的预处理后得到每个语音帧的时域信号x(n),此后在x(n)后补0以形成长为N(通常情况下N=512)的序列,此后对其进行离散傅里叶变换,得到线性频谱X(k),其中转换公式为:
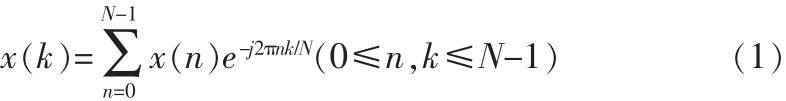
而在实际应用中,通常通过快速傅里叶变换(FFT)过程加以计算,其中N的一半称之为DFT(FFT)窗宽。 接下来将之前得到的线性频谱X(k)通过Mel频率滤波器得到Mel频谱之后将其通过对数能量处理得到对数频谱S(m)。其中,Me频率滤波器由若干个具有三角形滤波特性的带通滤波器Hm(k)组成(0≤m<M,M 为滤波器的个数),每个带通滤波器的传递函数为:


上式中,fh和fl分别分别表示为频率应用范围的最高频率和最低频率。N为DFT(或FFT)窗宽。Fs为采样频率,而B-1为B的逆函数:

前面提到,线性频谱X(k)通过Mel频率滤波器得到Mel频谱之后将其通过对数能量处理,这样做的目的是为了使结果对噪声和谱估计误差有更好的鲁棒性,则由线性频谱X(k)到对数频谱S(m)的总的总传递函数为:

f(m)可以如下方法加以定义:
最后,将对数频谱S(m)经过离散余弦变换(DCT)变换到倒谱频谱,即可得到Mel频率倒谱系数(MFCC参数)c(n):
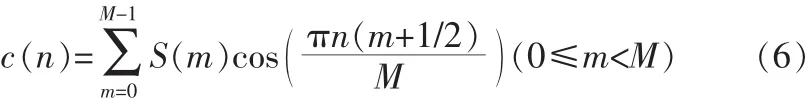
1.3 模板匹配
选择合适的模板匹配算法在整个语音识别系统中占有举足轻重的作用,传统的DTW算法在路径描述方面为了使路径不至于过分倾斜,人为的将路径的斜率控制在了0.5-2的范围之内,这样做大大的增加了计算量,浪费了很多存储空间,设计提出了改进的DTW算法,有效的解决了以上两个问题。
用端点检测算法确定语音信号的起点和终点是语音识别各个阶段(训练模板阶段、识别阶段)都不可缺少的步骤,这样可以去除不必要的信息,提高识别效率。模板匹配即为参考模板与测试模板的匹配,其中,参考模板是已经存入模板库中的各个词条,可表示为{R(1),R(2)...R(m),R(M)}(m 为训练语音帧的时序标号,m=1为起点语音帧,m=M为终点语音帧);测试模板则为系统所要识别的输入词条语音,将其表示为{T(1),T(2)…T(n),T(N)}(n 为测试语帧的时序标号,n=1 为起点语音帧,n=N为终点语音帧)。需要注意的是,为了保证识别的效果,参考模板与测试模板一般采用相同类型的特征矢量。
将参考模板用R表示,测试模板用T表示,它们时间的距离大小 D(T,R)代表了相似度的大小,显然,D(T,R)越小,则相似度越高。为了计算D(T,R),设计一个网络,网格在二维坐标系中表示,横轴坐标为测试模板的帧号n=l~N,纵轴坐标为参考模板的各个帧号m=l~M,将这些表示帧号的整数坐标画出一条条纵横线即形成了一个网格,测试模板中某一帧与训练模板中某一帧的交汇点即为网格中的交叉点。改进的DTW算法可归结为寻找一条从网格的左下角出发,在右上角结束的路径,路径通过的格点即为测试模板和参考模板中进行距离计算的帧号。
在网络中, 将路径实际的动态弯折分为三段,(1,Xa)、(Xa+1,Xb)和(Xb+1,N),其中:
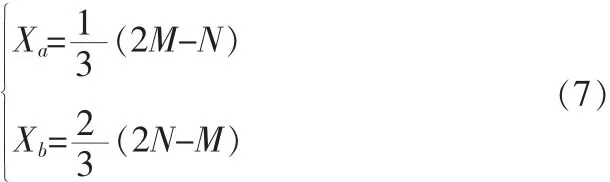
Xa和Xb都是最相近的整数。M和N长度的限制条件为:

不满足限制条件的情况下则认为两者的差别太大以致于无法进行动态弯折匹配。
相比于传统的DTW算法,此时X轴上的每一帧不再组要与Y轴上的每一帧进行比较,而只是与Y轴上[ymin,ymax]间的帧进行比较,ymin和ymax的计算式为:

当出现 Xa>Xb的情况时,弯折匹配的三段为(1,Xb)、(Xb+1,Xa)和(Xa+1,N)。X轴上每前进一帧时虽然所要比较的Y轴上的帧数不同,但弯折的特性一样,所以积累矩阵的更新公式为:

改进的DTW算法X轴上每前进一帧只需要用到前一列的积累距离,所以只需要两个列矢量D和d分别保存前一列的积累距离和计算当前列的积累距离,而不用保存整个距离矩阵。每前进一帧都要根据式(11)利用前一列的积累距离D和当前列的所有帧匹配距离d(x,y)求出当前帧的积累距离,并将结果保存于矢量d中,并将新的距离d赋值给D,作为新的积累距离供下一列使用。这样一直前进道X轴上最后一列,矢量D的第M个元素即为两个模板的动态弯折距离。
根据以上描述,本设计使用MATLAB进行仿真实现,首先在程序中申请两个n*m的矩阵D和d,分别为积累距离和帧匹配距离,n和m分别为测试模板与参考模板的帧数。 接下俩对两个模板的长度进行比较,如果长度差别太大将返回一个很大的数realmax,表示匹配失效。接下来计算xa和xb,根据两者大小的比较,将匹配区域划分为二段或者是三段。对每一帧分别计算出y_min和y_max。调用函数warp进行匹配,最后的结果保存在D中,而D(m)就是整个模板匹配的总积累距离。
2 仿真结果分析
2.1 MATLAB仿真
1)获取语音模板
本系统的语音模板录制为普通女声的一组声音,录制‘0’、‘7’、‘4’ 为实验对象, 分别命名为 ‘0a.wav’、‘7a.wav’、‘4a.wav’。对这3个语音经过预处理之后提取其MFCC参数,经过模板训练作为模板存入数据库建立参考模型库。
2)获取待测语音
类似的,录制另外一组普通女声的声音,同样为‘0’、‘7’、‘4’3个声音,作为3个待测语音信号。分别命名为‘0b.wav’、‘7b.wav’、‘4b.wav’。
3)语音识别
用本系统设计的方法对前述3个语音进行识别需用function定义3个函数。首先是vad函数,作用为对信号进行端点检测。其次编写mfcc函数提取信号的MFCC参数c(n)。再次是dtw函数,作用为计算整个模板匹配的总积累距离D(m)。上述3个函数定义好之后便可在主程序中调用,进行语音识别。主程序命名为testdtw,具体步骤为:首先用wavread函数将原始语音信号读入,其次用vad函数对信号进行端点检测,再次用mfcc函数提取信号的MFCC参数c(n),并将所有的的参数存入到参考模板的结构数组中。最后,调用dtw函数计算整个模板匹配的总积累距离D(m),创建dist矩阵将用来存储结果。
2.2 仿真结果及分析
Matlab仿真结果如图4所示。
从测试结果可以看出,语音模板中的语音‘1’、‘7’、‘4’分别对应了测试模板的语音‘1’、‘7’、‘4’,由此得出仿真实验达到了预期的结果,并且与传统的DTW特定人语音识别进行了比较,识别速度提高了30%,由此证明设计方法在特定人孤立词语音识别方面得到了很好的应用。为了进一步验证识别效果的正确率,图5为匹配距离矩阵dist的数据:

图4 Matlab仿真结果Fig.4 Matlab simulation results

图5 匹配距离矩阵Fig.5 Matching distance matrix
匹配距离矩阵的对角线上对应的数据是正确的匹配模板对应的分数,从结果来看,对角线上对应的3个数据都是本行中最小的,由此验证了识别的正确性。
3 结束语
文中较为详细的介绍了利用MATLAB仿真环境,基于改进的DTW(Dynamic Time Warping)算法设计实现特定人孤立词识别的一种基本方法,解决了传统的DTW算法在语音识别方法存在算法复杂,占用存储空间大等等问题。并通过仿真结果验证了该语音识别系统的正确性与可靠性。
[1]付丽辉.语音识别关键性技术的MATLAB仿真实现[J].仪器仪表用户,2010,117(3):50-52.
FU LI-hui.MATLAB simulation of critical voice recognition technology[J].Instrumentation Users,2010,117(3):50-52.
[2]武同宝,赵徐彤.基于MATLAB的语音信号识别及矢量模式匹配[J].工业控制计算机,2012,25(9):1-2.
WU Tong-bao,ZHAO Xu-tong.Matching MATLAB-based speech recognition and signal vector mode[J].Industrial Control Computer,2012,25(9):1-2.
[3]何强,何英.MATLAB扩展编程[M].北京:清华大学出版社,2002.
[4]Rabiner L,Juang B H.The basic principle of speech recognition[M].北京:清华大学出版社,1999.
[5]韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004.
[6]杨述斌,李永全.数字信号处理实践教程[M].武汉:华中科技大学出版社,2007.
[7]张德丰,丁伟雄,雷晓平.MATLAB程序设计与综合应用[M].北京:清华大学出版社,2012.
[8]彭辉,魏玮,陆建华.特定人孤立词的语音识别系统研究[J].控制工程,2011,18(7):398-399.
PENG Hui,WEI Wei,LU Jian-hua.Specific people isolated word speech recognition system[J].Control Engineering,2011,18(7):398-399.
[9]刘丽媛,严家明.一种孤立词语音识别的实现方法及改进[J].计算机应用技术,2010,16(327):110-111.
LIU Li-yuan,YAN Jia-ming.Implementation and improvement of isolated word speech recognition[J].Applied Computer Technology,2010,16(327):110-111.
[10]赵力.语音信号处理[M].北京:机械工业出版社,2009.
An improved speaker-dependent speech recognition systems and algorithms
ZHAO Zhi-qi,FANG Jian-dong
(Inner Mongolia University of Technology, Huhhot 010080, China)
In speech recognition of the traditional process, there exists the problem of complexity, large storage space, and so on.Aiming at these problems,proposed an improved algorithm based on dynamic time warping (DTW)speech recognition system for specific people.After a detailed comparison on the parameter extraction method,extraction of Mel frequency cepstrum coefficient (MFCC)as the speech recognition of the system parameters,to effectively solve the ear response signals with different sensitivity to different problems.Using MATLAB environment the Voice toolkit Voice Box to realize the isolated word recognition of several Numbers,the recognition speed by about 30%and the success rate of 95%or more.The simulation results show that, the algorithm is simple, the recognition success rate is high, is a simple and effective method for speech recognition.
speech recognition; dynamic time warping; mel frequency cepstrum coefficient; isolate word
10.14022/j.cnki.dzsjgc.2014.16.010
TN602
A
1674-6236(2014)16-0031-04
2014-03-10 稿件编号:201403094
内蒙古自治区科技计划项目(20120304);内蒙古自治区科学基金项目(2009MS0913)
赵智琦(1988—),女,山西阳泉人,硕士研究生。研究方向:智能信息处理及决策。
猜你喜欢
数学物理学报(2022年2期)2022-04-26
空间科学学报(2021年6期)2021-03-09
中学生数理化·教与学(2019年8期)2019-09-18
电子制作(2019年11期)2019-07-04
测控技术(2018年7期)2018-12-09
电子制作(2018年16期)2018-09-26
人民音乐(2016年3期)2016-11-07
系统工程与电子技术(2016年7期)2016-08-21
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
火控雷达技术(2016年2期)2016-02-06
