
数据驱动学习模式应用于英语写作教学的实效研究
2014-09-20 07:58:16熊薇薇
河北职业教育 2014年7期
熊薇薇
(深圳信息职业技术学院,广东 深圳 518172)
数据驱动学习模式(data-driven learning缩写为DDL)是Tim Johns在1991年提出的一种基于语料库的,利用数据来分析和发现语言规律的一种外语学习方法。他将语言学习者描述成“语言侦探”,将学习者暴露在数据中,让其从例句以及语境共现行(concordance lines)中找出语言规律。尽管诸多研究表明,学习者能够受益于DDL,但并不是所有的研究都证明了DDL比传统方法更有效(Cresswell,2007)。Boulton(2009)指出需要更多针对不同条件的实验研究,如不同程度的学习者、不同的语料库资源、不同的语言点等。
本研究依托美国当代英语语料库(Corpus of Contemporary American English COCA)进行。COCA由美国杨伯翰大学Mark Davies教授开发,是当今世界上最大的免费在线语料库,库容达4.5亿,平均分配到口语、小说、流行杂志、报纸及学术文章几个子库,每月有近10万人使用。该语料库具有免费、规模大、速度快、词性标注易于理解,且时效性强的特点。
本研究将引导学生利用COCA语料库对其作文进行修改,然后对比修改前后作文的结果,探讨DDL模式对学生写作的作用。
一、关于DDL的争论
(一)真实性
DDL支持者认为真实的语料可以使学生自然地学习语法结构、单词的用法、语用特征等等。真实语料的使用避免了教师为了教某一语法规则或词汇现象而生造例句。语法大家Randolf Quirk等人在《综合英语语法》中阐释形容词和副词比较级用法时就曾编造过这样的例句(卫乃兴,2005):
a. Walter played the piano more often in Chicago than his brother conducted concerts in the rest of the States. (引自Francis,1993:138)
b. I never seen a dog more obviously friendly than your cat.(引自Francis,1993:138)
通过Cobuild语料库检索发现,这是两个生造的句子,与真实的英语使用相差甚远,英语母语者不会说出那样的句子。生造的句子的确有助于学生掌握语言学家提出的理论规则,但掌握规则知识是一回事,实际运用是另一回事,后者只能通过处理大量真实数据而发展。正确的选择只能是真实输入,包括真实的教学材料、真实的课堂语言等等(卫乃兴,2005)。
反对者则认为DDL专注于某个单词或语法结构的出现频率及在语境中的共现,它只关注与目标词临近的几个单词,给出的上下文太少,并不能揭示出关键词是如何与语境相互作用的。它不能说明语用意思是如何在语境中实现的,所以DDL的真实性有限。
(二)自主学习
支持者认为这种学习模式更少地依赖老师,而是采用归纳和演绎的推理方法,有利于学生认知能力的发展(Boulton,2009)。DDL的发现式学习方法与传统英语学习方法有较大区别,为那些不适应传统英语学习方法的学生提供了另一种解决方式。他们有更大的自主性,可以利用DDL来解决自己的问题,并逐渐成为一名独立的语言学习者(Hunston,2002)。
反对者则指出,DDL假设学习者通过观察、归纳找出的语言规律,其效果会比传统的“老师教、学生学”的模式更好,而且学生通过学习例句及大量的语料,他们将会发现到之前没关注的语言规律,但是这个假设尚未证实(Hunson,2002)。
其实DDL并不是要取代传统教学方法,而是对传统教学方法的补充,“它只是老师装着诸多学习方法的箭袋中的用来帮助学生的一支箭”(Boulton,2009)。
二、研究设计
(一)研究目的
本研究试图探讨数据驱动学习模式在学生写作方面的效果,通过对比学生作文修改前后在流利性、复杂性和准确性方面的数据,以及学生对数据驱动学习模式的问卷调查结果,来检验数据驱动学习模式的实效。
(二)研究问题
通过COCA语料库修改作文,学生的作文水平能否得到提高?如果能,主要体现在作文的哪些方面?
Fitzgerald(1987)指出修改是指在写作过程中对文章的任意方面做出的改变。任意一篇文章都能够通过反复地修改而不断完善。Faigley和Witte(1981:400-414),将修改分为表层修改和意义修改两类。表层修改是指在文字水平上的修改,错误限于表层结构,主要包括错误拼写、错误搭配、时态误用、主谓或代词不一致等;意义修改是指在文章结构与主题上进行的修改,主要包括逻辑顺序混乱、前后观点不一致、因果关系不明确、错误的说明或解释等。本研究主要涉及到表层修改。
(三)受试
受试为30名某高职高专大二英语专业学生,均通过了英语应用能力A级考试,最高分78,最低分60,平均分70.7。
笔者在上课时间以及课后对受试进行了语料库知识培训,约15课时。包括语料检索、如何观察语境共现行、通配符检索,重点介绍了如何利用COCA改正作文中的词性错误、选词错误、固定搭配错误以及同义词辨析的问题。
(四)研究工具
1.学生作文
为了解学生在实验前后作文的流利性、复杂性和准确性是否有所变化,学生被要求在40分钟内完成题目为《The Value of School Exams》的短文,字数在250左右。之后,学生应用COCA语料库对自己的作文进行修改,作文修改不限定时间。本研究参考陈慧媛(2010)的写作测量指标,采用以下几个指标进行这三方面的数据分析①本研究中的S节采用Crookes(1990)的定义,在任意一个基本的语言单位中所出现的限定性或非限定性动词,即每出现一个动词记为一个S节。Hunt(1997)将T单位定义为,一个句子能够缩成的最小单位,包含了所有从属分句及词组的一个主句。语言错误统计参照CLEC的分类及标注方法进行,常见的错误类型包括拼写错误fm1、选词错误wd3、时态错误vp6、句子结构错误sn8等。。
(1)流利性T-unit length每T单位的长度
(2)复杂性
A. type/token型/次比来衡量词汇复杂性
B. S/T每一个T单位中的S节数量比衡量语法复杂性
(3)准确性
A. E语言错误总数量
B. E/W语言错误与总词汇数量之比
数据的获取有些是通过电脑计算,比如文本的长度,词汇的型/次比是通过Readability Analyzer 1.0软件直接得出。有些数据则通过手工分析得到,比如T单位、S节的判断、语言错误的统计。所有手工计算部分的数据均经过3名教师的校对,以保证数据的准确性。把每位学生作文修改前后的所有数据输入电脑,运用SPSS19.0进行配对样本t检验,分析以上三个指标的变化情况。
2.问卷调查
针对学生对COCA及DDL的使用情况以及学生的态度进行了一次问卷调查,该问卷采用5级里克特量表形式设计(非常不同意、不同意、不确定、同意、非常同意)。
三、研究结果
(一)总体数据情况
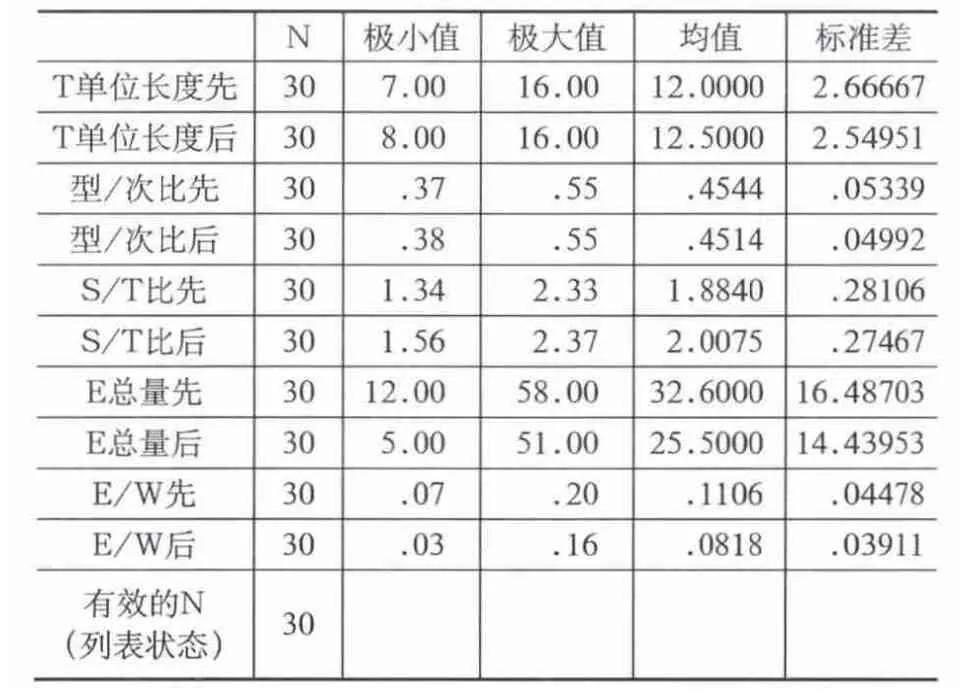
表1 总体情况描述统计表
从上表可以看到大部分数据修改后的结果要优于修改前,不过词汇复杂性指标(型/次比)从0.4544下降到0.4514。通过观察作文修改前后的类符和形符发现,两者的数量都增加了,但是形符的增加幅度要大于类符的增加幅度,从而导致了型/次比有细微的下降。
所有数据都经过了Kolmogorov-Smirnova正态性检验,结果显示其显著性都大于0.05,符合配对样本t检验的要求。通过下表可以看出,修改后的作文在流利性(T单位长度)和复杂性(型/次比,S/T)两方面不存在显著差异(P大于0.05),也就是说,利用COCA修改作文的方法对提高学生作文的流利性和复杂性方面没有明显优势。这可能与学生的英语水平、COCA使用的熟练程度或研究设计有关。
不过在作文的准确性方面E错误总量以及E/W语言错误与总词汇数量比,其显著性分别是0.001及0,说明两者存在显著差异。配对样本t检验结果显示该方法可以显著提高学生作文的准确性。
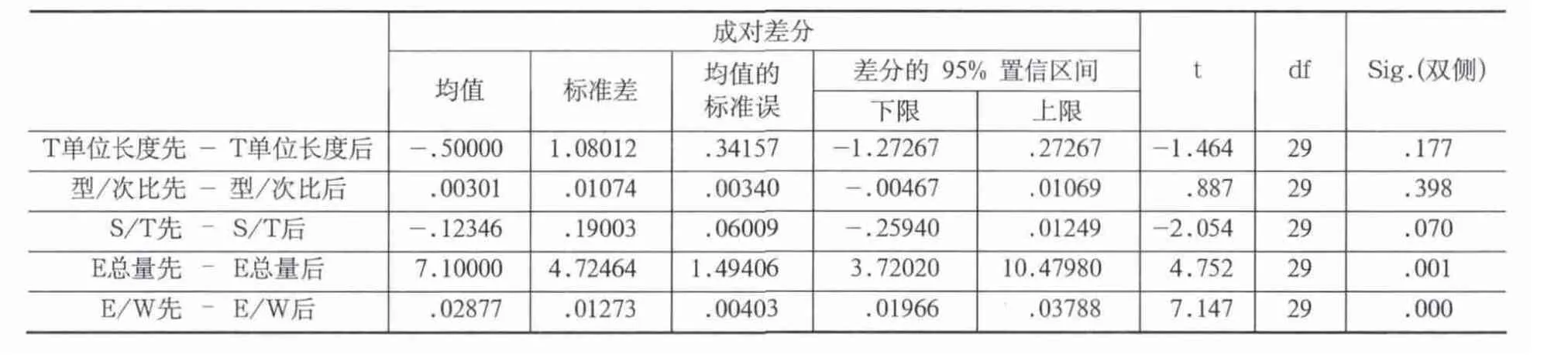
表2 流利性、复杂性、准确性配对样本t检验结果
(二)错误分析
表3列出了修改前排名前10位的错误类型,以及这10种错误类型修改后的情况。统计显示,修改前词汇错误占错误总量的63.8%,修改后词汇错误占错误总量的61.18%。wd3(替代)和vp6(时态错误)在修改前后都是居于前两位的,分别占了所有错误的27.3%和26.67%。在本次实验中,vp6居高不下的原因可能与作文内容有关。这篇作文要求学生描述某一次考试的经历,大部分时态错误都是由于学生在描述过去的经历时没有变更时态,而且时态错误的修改率很低,学生不能发现并修改时态错误。不过,wd3修改后的错误率下降了1.78%。
通过对比常见错误修改前后的情况,可以发现:第一,修改后的错误绝对值都是低于修改前的,只是与错误总量的比例发生了变化。第二,fm1、wd3、sn2、pp1、vp2、np6与错误总量的比例有所下降。第三,vp6、wd2、wd4、wd5的比例较之前更高。
由此可见,DDL对作文准确性的提高主要体现在拼写错误、选词错误、动词固定搭配、名词的可数性等方面,而对于时态错误、词的缺少和冗余、词性错误的帮助有限。
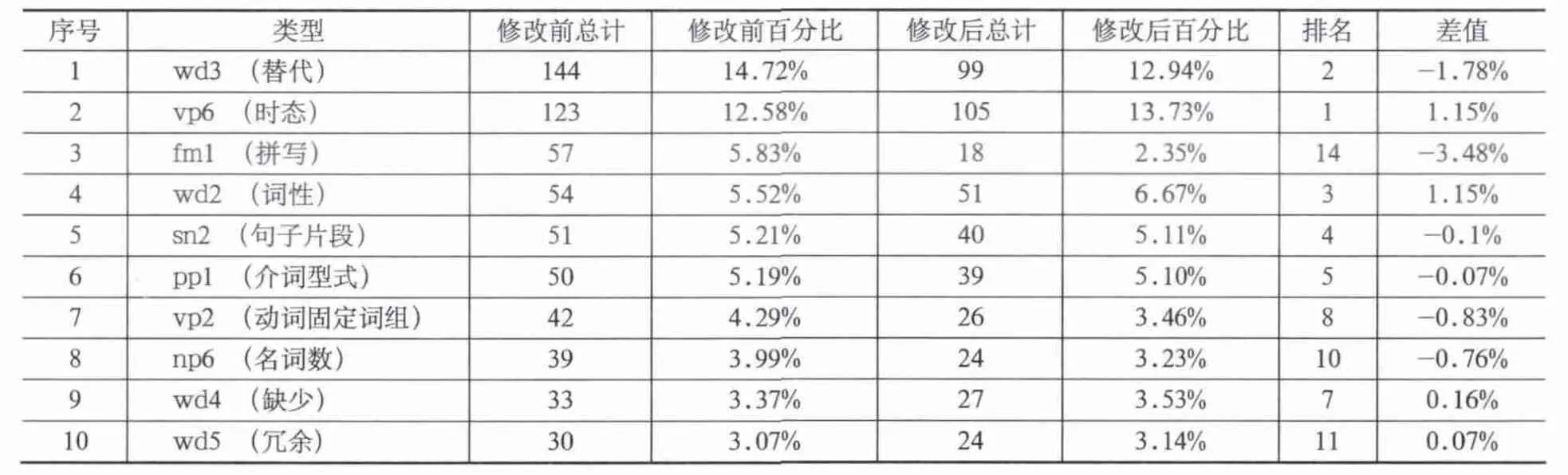
表3 学生作文修改前后错误排列表
(三)问卷调查结果
结果显示,学生对DDL学习模式以及它对写作的作用是比较肯定的,也愿意使用COCA语料库修改作文。“我认为COCA可以减少作文中的错误”,均值4.3077;“我会用COCA去检测作文中介词等固定搭配的用法是否正确”,均值4.0769。“COCA能够使我作文的词汇量更丰富”,均值3.7692;“遇到作文中重复出现的某个单词时,我会想着用COCA去找它的同义词代替”,均值3.8462。不过调查发现,学生还不能熟练地使用DDL模式以及COCA语料库。“学习时间太短,我没能熟练使用COCA的各种用法”,均值4.2308;“我能够利用KWIC的功能,观察同义词在语境中的差别,并选出合适的单词”,均值2.9231。
四、结 语
本文对DDL模式对学生写作的作用进行了实证研究。结果证明,利用COCA语料库修改作文可以显著提高学生作文的准确率,尤其在拼写、选词、动词固定搭配、名词的可数性方面,但是对提高学生作文的流利性和复杂性方面没有明显优势。由于本研究设计是通过对比学生利用COCA语料库修改作文前后的质量来考察在作文中引入数据驱动学习模式的作用,这种实验模式可能是学生作文流利性、复杂性变化不大的原因,这也是本次研究的局限性。后续可以对DDL对学生写作水平的影响进行动态研究,比如学生经过一段时间的DDL学习之后,在同等应试条件、同等题目难度的情况下,他们的写作水平的变化情况。
[1]Cresswell. Getting to 'know' connectors?Evaluating data-driven learning in a writing skills course[A],In E. Hidalgo,L.Quereda & J. Santana (Eds.),Corpora in the foreign lan guage classroom(pp.267-287).Amsterdam:Rodopi,2007.
[2]Boulton. Testing the limits of data-driven learning:language proficiency and training[M]. ReCALL,21,37. doi:10.1017/s0958344009000068,2009.
[3]卫乃兴,李文中,濮建忠.语料库应用研究[M].上海:上海教育出版社,2005:3-4.
[4]Hunston,Corpora in applied linguistics[M].Cambridge:Cambridge University Press,2002.
[5]Fitzgerald. Research on revision in writing[J].Review of Edu cational Research,1987,(57):481-506.
[6]Faigley,L & S Witte Analyzing revision[J].College Composition and Communication,1981,(32):400-414.
[7]陈慧媛.英语写作表现测量指标的类别及特性[J].现代外语,2010,(1).
猜你喜欢
家庭影院技术(2021年2期)2021-03-29 07:18:22
中华养生保健(2020年2期)2020-11-16 00:49:16
科学(2020年1期)2020-08-24 08:07:56
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
疯狂英语·新策略(2019年12期)2020-01-04 02:48:06
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
中国卫生(2016年9期)2016-11-12 13:27:58
肿瘤影像学(2015年3期)2015-12-09 02:38:52
语言与翻译(2015年4期)2015-07-18 11:07:45
海外英语(2013年4期)2013-08-27 09:38:00
