
采用子带长时信号变化特征的VAD检测
2014-09-18 00:16龙志军
电视技术 2014年19期
蔡 铁,唐 飞,龙志军
(1.深圳市可视媒体处理与传输重点实验室,广东深圳518172;2.深圳信息职业技术学院,广东深圳518172;3.中兴通讯股份有限公司,广东 深圳518057)
语音活动检测(Voice Activity Detection,VAD)技术的目标是要确定语音开始和结束的位置,其应用十分广泛,可作为前端处理,提高语音识别系统的识别率,改善语音增强的效果,提升语音编码和传输的效率。传统的语音活动检测算法主要基于能量特征[1],在高信噪比条件下十分简单有效,但在信噪比较低的情况下性能很差,有时甚至无法工作。因此,提高噪声条件下语音活动检测的稳健性是此领域研究工作关注的重点,如负熵[2]、长时谱散度[3]、自相关特征[4]等,虽然提高了 VAD算法在低信噪比环境下的稳健性,但在不同的噪声条件下还不能取得一致的好效果。近年来,一些研究者提出了一些新的时长在150 ms以上的长时特征,例如长时信号变化(Long-term Signal Variability,LTSV)特征[5]以及(Long-term Spectral Flatness Measure,LSFM)特征[6],这些长时特征能在多种噪声条件下取得不错的效果,但大多采用传统的门限比较法,在噪声变化条件下表现不佳,检测准确率大幅降低。
此外,为提高VAD算法在低信噪比下检测的准确率,一些研究者对基于统计模型的VAD进行了深入研究[7-8],更关注数学统计模型的选取,其中,高斯混合模型(Gaussian Mixture Models,GMM)由于在噪声环境下性能较好,近年来常用作VAD算法的统计模型[9-10]。
由于目前提出的长时特征都是从二维时频窗口中提取信息,没有引入语音的听觉谱特性。对人耳听觉功能的研究表明,人耳对语音信号的处理首先是将信号在不同频率子带进行分解,经各频率子带的处理后再综合处理结果。由于各子带的频率分布不同,人的听觉系统对不同频段信号的感应也大不相同。此外,不同种类的噪声也具有不同的频率分布。因此,本文提出了一种采用子带长时信号变化特征的稳健语音活动检测算法,在频域将语音信号分解为几个不重复的子频带,分别提取这些子频带的长时信号变化特征,然后采用GMM在线建立语音和非语音模型进行VAD处理。实验结果表明,本文算法可有效提高VAD在低信噪比环境及不同噪声条件下的性能,且算法的计算复杂度不高,具有良好的实时性。
1 子带长时信号变化特征的提取
根据文献[5],语音信号的长时信号变化特征是由每个频带的长时谱熵取平均值计算获得的,它能使VAD算法在低信噪比情况下具有良好的稳健性。但在脉冲噪声的影响下,LTSV特征的性能将会明显降低。为了使特征参数包含各个频段的动态信息,获取语音信号在不同频带的变化特性,本文采用子带处理方法,提取子带长时信号变化特征组成特征向量,进一步提高VAD算法的性能。


Ei(m,ωi(k))反映了R帧信号在子频带i中频率ωi(k)处的长时谱熵,它由R帧长度时间分析窗的归一化能量谱(n,ωi(k))计算得到,(n,ωi(k))的计算公式如式(4)和式(5)所示。
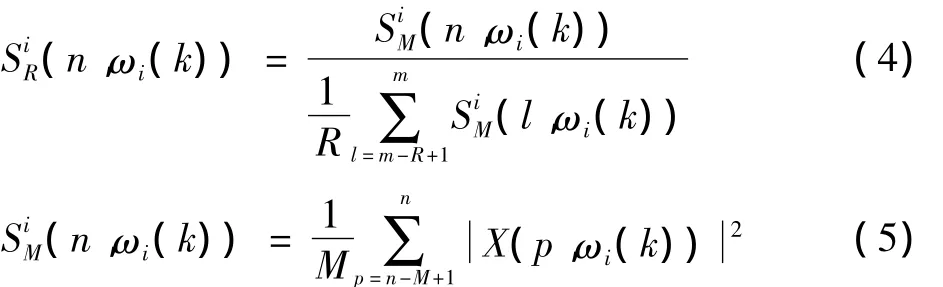
式中:(n,ωi(k))是子频带i最近M帧信号的平均能量谱;X(p,ωi(k))为第p帧信号在子频带i中频率ωi(k)处的短时傅里叶变换系数。
计算出每个子频带的LTSV特征Lix(m)后,可以将这些特征参数组合为一个N维的特征向量Lm,用于第m帧语音信号的VAD处理。作为提取子带LTSV特征的参数,子频带数量N与参数K,R,M都会影响所提特征的性能,从而获得不同的VAD结果。根据文献[5]的实验研究,本文选取参数R=30,M=10,并设置子频带数量N=16(参数K可由N计算得到)。
图1为文献[5]中LTSV特征曲线图,图1中a为带噪语音信号(SNR=-10 dB),b为干净语音信号。从图1可以看出,LTSV特征具有较好的稳健性,但在信号的局部区域,LTSV特征值较小,难以区分出语音帧,可能导致VAD错误。图2为相同带噪语音信号的子带LTSV特征曲线,图2中(a)~(h)分别对应子带1~8。从图2可以看出,各子带LTSV特征都在一定程度上反映了语音信号的活动情况,具有LTSV特征所缺乏的信息。例如图1中c的LTSV特征在信号1.5~2 s区间中取值较小,难以检测出语音活动情况,但图2中(b),(c),(g),(h)中相同区间的子带LTSV特征取值较大,区别明显,可以检测出语音活动情况。

2 语音活动检测
基于子带LTSV特征,可以建立语音模型和非语音模型(Non-speech Model),然后利用这两个模型对提取的子带LTSV特征向量进行判决,获得VAD结果。本文算法采用了混合高斯模型(GMM)建立语音模型和非语音模型,利用两个模型的概率比作VAD判决,算法的示意图如图3所示。其中,两个GMM模型一般采用离线方式由已标注数据预先训练得到,但本文算法采用了在线训练方式,由每一句话(A Utterance)的部分数据在VAD判决前实时训练获得。

图3 本文VAD算法示意图
本文所提VAD算法的处理步骤如下:
1)从输入的带噪语音信号s(n)中提取所有帧的子带LTSV特征向量,组成特征向量集合Lx,其中每一帧的子带LTSV特征向量为xm(xm∈Lx)。
2)采用谱减算法[11]为输入的语音信号s(n)降噪,获得增强语音信号xclean。
3)利用增强语音信号xclean,计算每一帧的短时能量Em,并将部分最大短时能量对应的信号帧作为语音帧(固定百分比,本文取10%最大短时能量帧为语音帧),将输入信号的初始20帧作为非语音帧,分别用于训练语音GMM和非语音GMM两个模型。
4)对于带噪语音信号的每一信号帧,计算两个
GMM模型的概率输出,取概率比值用于VAD判决,即lg(p(xm|GMMspeech))≥lg(p(xm|GMMnon-speech))且Em≥θmin时,为语音帧,VAD 结果标注为1。其中,θmin为预先设置的最小能量约束。
5)考虑到相邻帧之间的关联性对于检测语音的存在非常重要,对步骤4)的VAD结果加以修正,将两语音段间的非语音段(VAD标注为0的相邻帧)小于500 ms的转化为语音帧。

本文VAD算法在不同噪声条件下的实验结果如图4~图7所示,子带LTSV特征具有较好的稳健性,算法在信噪比为-10 dB的嘈杂环境中仍能较准确地检测出语音的活动情况,并不同信噪比条件下以及白噪声、Pink噪声、Car噪声及Babble噪声等多种噪声条件下均能取得不错的效果。与本文VAD算法相比,基于短时能量的VAD算法[1]在低信噪比情况下将完全失效。

3 实验仿真与分析
3.1 VAD算法的性能评估

为验证算法的有效性,在不同噪声类型和信噪比的条件下,实验采用本文算法(SBLTSV_VAD)与基于短时能量的VAD算法(Eng_VAD)[1]、基于MFCC特征参数的VAD算法(MFCC_VAD)[12]、基于 LTSV特征的 VAD算法(LTSV_VAD)[5]进行了比较。实验所用的干净语音数据为美国德克萨斯大学达拉斯分校的NOIZEUS数据库[13]。该数据库的clean数据集采集在安静实验室环境下,采样频率为8 kHz,由6名说话人(包括3名男性和3名女性)录制的30句英文短语组成。这些数据集的语音信号起始点和终止点进行了人工标注,以作为VAD实验的参考值。实验中语音信号被分为30 ms的帧,相邻帧有2/3重叠,即帧移为10 ms。实验所用的带噪语音是由人工加入噪声到干净语音中产生,信噪比范围从-10~20 dB,噪声类型包括有白噪声、Pink噪声、Car(汽车车厢内)噪声、Babble噪声等。实验比较了不同信噪比(-10 dB,0 dB,10 dB)下,叠加各种噪声后的带噪语音信号采用VAD算法后,其VAD结果的误检率(即错误率),实验结果如表1所示。
由于语音的起止点在连续语音情况下不能完全准确地检测出,例如背景噪声的误检以及语音中辅音的漏检,因此不能依据一句语音或一个错误来判定VAD检测性能,需要按如下评价参数进行了VAD算法的性能评比

式中:Total_Num为总的语音帧数;Miss_Num表示语音帧被误检为非语音帧的帧数;False_Num表示非语音帧被误检为语音帧的帧数。本文将总误检率作为VAD算法性能比较的依据。
从表1中的实验结果可以看到,本文提出的SB LTSV_VAD算法与文献[5]的 LTSV_VAD在SNR=-10dB的环境下依然有效,其误检率明显低于传统的Eng_VAD算法以及采用MFCC特征的MFCC_VAD算法,说明LTSV特征对各种类型噪声具有较好的稳健性。对比LTSV_VAD与本文SBLTSV_VAD算法的实验数据可知,本文算法提取并综合利用了各子频带的长时特征信息,可取得更优的检测性能。

表1 不同噪声环境下VAD算法性能比较
3.2 VAD算法对语音识别性能的影响
为进一步评估VAD算法的性能,本文将SBLTSV_VAD算法应用于语音识别系统。语音识别实验的数据集采用的是英文数字串,这些数字串的长度从1~8不等,为连续语音。实验数据集分为4类,采集自4种不同速度(空档、30 m/h、55 m/h和变速)的汽车车厢内,采样率为8 kHz(16 bit),分别标识为SET01~SET04,每类数据集包含有数字串约5 000个。语音识别系统采用了HMM模型,其特征维数为26维,特征包括MFCC参数和短时能量,HMM模型由大量真实环境下的语音数据训练得到。本文实验比较了无VAD、采用Eng_VAD算法[1]和本文SBLTSV_VAD算法情况下数字串集的识别性能,实验结果如表2所示。

表2 数字串识别性能比较
从表2中的实验结果可以看出,语音识别系统使用VAD算法后数字串的识别率都有一定程度的提高,但与采用短时能量的VAD算法相比,本文算法性能更优,使识别率的提高更为明显。尤其对于SET04数据集,背景噪声的影响使采用短时能量的VAD算法出现了严重的错误,反而导致识别率下降,而本文算法则在噪声环境下具有更好的稳健性,在SET04数据集下的识别率仍有一定的提高。由于SET01,SET02与SET03的信噪比相对比较稳定,因此本文算法在前3种条件下效果更好,SET04的背景噪声存在变化,本文算法仅取得了4.81%的误识率下降。
4 结论
本文提出了一种采用子带长时信号变化特征的稳健语音活动检测算法,在频域将语音信号分解为几个不重复的子频带,分别提取这些子频带的长时信号变化特征,然后在线建立语音和非语音模型进行VAD处理。实验结果表明,本文算法可有效提高低信噪比环境下语音活动检测的性能,且对不同的噪声均具有很好的鲁棒性,适用性很强。在语音识别系统中的实验表明,本文算法能有效提高噪声环境下的语音识别率。在下一步的研究工作中,短时特征与长时特征的综合应用,以及各类机器学习算法的引入将是研究的重点。
:
[1] GANAPATHIRAJU A,WEBSTER L,TRIMBLE J,et al.Comparison of energy-based endpoint detection for speech signal processing[C]∥Proc.IEEE Southeastcon'96 Bringing Together Education,Science and Technology.Tampa,FL:IEEE Press,1996:500-503.
[2] PRASAD R,SARUWATARI H,SHIKANO K.Noise estimation using negentropy based voice-activity detector[C]∥Proc.47th Midwest Symposium on Circuits System.[S.l.]:IEEE Press,2004(2):149-152.
[3] RAMIREZ J,SEGURA J C,BENITEZ C,et al.Efficient voice activity detection algorithms using long-term speech information[J].Speech Communication,2004,42(3):271-287.
[4] SHUYIN Z,YING G,BUHONG W.Auto-correlation property of speech and its application in voice activity detection[C]∥Proc.First International Workshop on Education Technology and Computer Science(ETCS’09).Wuhan:IEEE Press,2009(3):265-268.
[5] GHOSH P K,TSIARTAS A,NARAYANAN S.Robust voice activity detection using long-term signal variability[J].IEEE Tran.Audio,Speech,and Language,2011,19(3):600-613.
[6] YANNA M,AKINORI N.Efficient voice activity detection algorithm using long-term spectral flatness measure[J].EURASIP Journal on Audio,Speech,and Music Processing,2013(21):1-18.
[7] SOHN J,KIM N S,SUNG W.A statistical model-based voice activity detection[J].IEEE Signal Processing Letter,1999,6(1):1-3.
[8]蔡黎.一种基于本原多项式的LDPC码构建新算法[J].电讯技术,2011(12):51-54.
[9] FUJIMOTO M,ISHIZUKA K,NAKATANI T.Study of integration of statistical model-based voice activity detection and noise suppression[C]∥Proc.9th Annual Conferene of the lnternational Speech Communication Asso ciatim.Brisbane,Australia:[s.n.],2008:2008-2011.
[10] FUKUDA T,ICHIKAWA O,NISHIMURA M.Long-term spectrotemporal and static harmonic features for voice activity detection [J].IEEE Journal of Selected Topics in Signal Processing,2010,4(5):834-844.
[11] GERKMANN T,HENDRIKS R C.Unbiased MMSE-based noise power estimation with low complexity and low tracking delay[J].IEEE Trans.Audio,Speech,Language Processing,2012(20):1383-1393.
[12]吴愚,方元.基于语音存在概率的语音活动检测方法[J].电声技术,2009,33(8):25-32.
[13] LOIZOU P C.Speech enhancement:theory and practice[M].Boca Raton,FL:CRC,2007.
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
空间电子技术(2021年4期)2021-11-10
电脑知识与技术·经验技巧(2020年5期)2020-06-22
中国医学物理学杂志(2020年3期)2020-04-06
电子制作(2019年22期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
航天电子对抗(2019年4期)2019-06-02
雷达学报(2017年3期)2018-01-19
系统工程与电子技术(2016年2期)2016-04-16
西南石油大学学报(自然科学版)(2015年5期)2015-04-16
